如何设计性能优良的mysql索引?
Posted 杀手不太冷!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何设计性能优良的mysql索引?相关的知识,希望对你有一定的参考价值。
文章目录
如何设计性能优良的mysql索引?
基本概念
索引使用的数据结构是B+树。
1.索引数据和实际数据都存储在磁盘,因此我们数据库相关的操作是要我们的程序和磁盘进行交互的,因此肯定是会使用到IO的,因为一层其实代表的是一个磁盘块,内存和磁盘块进行交互的时候是需要进行IO操作的。
2.当进行查询的时候,需要将磁盘中的数据读取到内存中。
3.分块进行数据读取。
4.使用什么样的数据结构存储(格式:K-V)
局部性原理:
时间局部性:之前被访问过的数据,有可能很快会被再次访问。
空间局部性:数据和程序都有聚集成群的倾向,具备某些特征的数据可以放在一起。
磁盘预读:内存跟磁盘在进行交互的时候,有一个最基本的逻辑单位称之为页,也叫datapage,大小一般是4k或者8k,我们在进行数据读取的时候,一般读取的是页的整数倍。
为什么我们的mysql数据库的数据结构不用二叉树和红黑树
像我们的二叉树,红黑树等这些树只能有两个分支,那如果我们想要存储更多的数据怎么办,我们只能再增加一个深度,如下图:

如果要在二叉树或者红黑树里面增加数据的话,就需要再增加一个深度,而多一个深度之后会多出很多磁盘块,而磁盘和内存交互的时候需要进行IO,这样的话IO的次数就变多了,而IO操作时非常影响性能的,所以我们的效率会非常的低。
为了解决二叉树,红黑树的问题出现了B树
于是为了解决这个问题就有了B树,如下图:


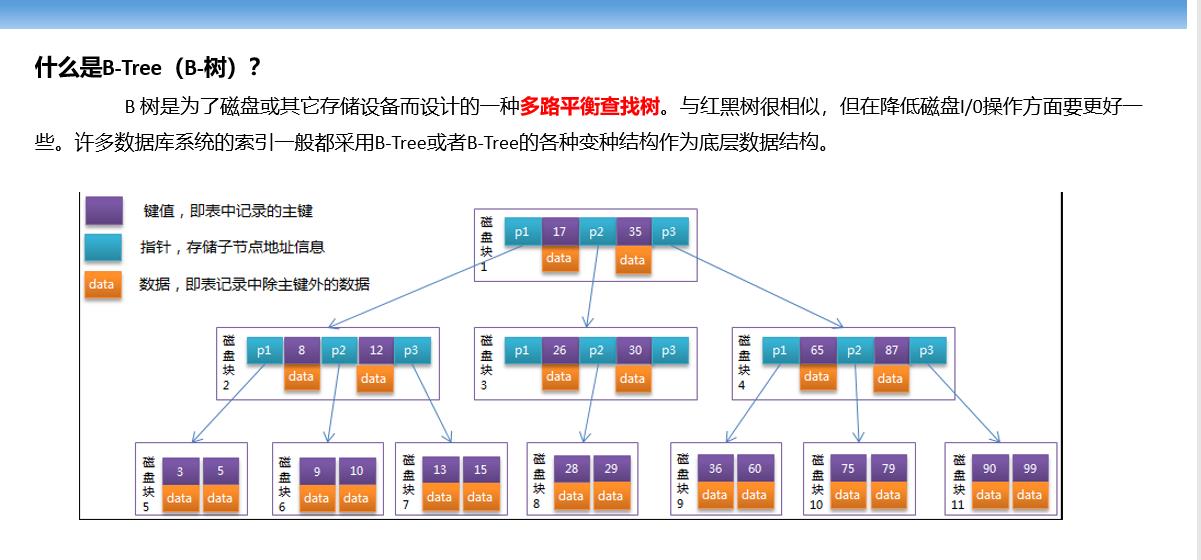
这样我们既保证了有序,平衡,又保证了可以存在多个分支。但是这样也是会出现一个问题的,因为我们的每个磁盘块的空间存储大小是有限的,如果我们在每个磁盘块里面都存储data,也就是表记录中除主键外的数据,那么磁盘块存储的表中记录的主键就会减少,这样我们磁盘块里面存放的总的表数据其实是很少的,那怎么解决这个问题呢?我们又引出了后来的B+树。
为了解决B树的问题引入了B+树
B树虽然也可以当做mysql数据存储的数据结构,但是它因为每个磁盘块中都需要存储data数据,因此它总体来讲,能存放的表记录很少,为了解决这个问题,我们就引入了B+树,在原本的B树的基础上做了一些升级,我们让非叶子节点只存储键值不存储data数据。
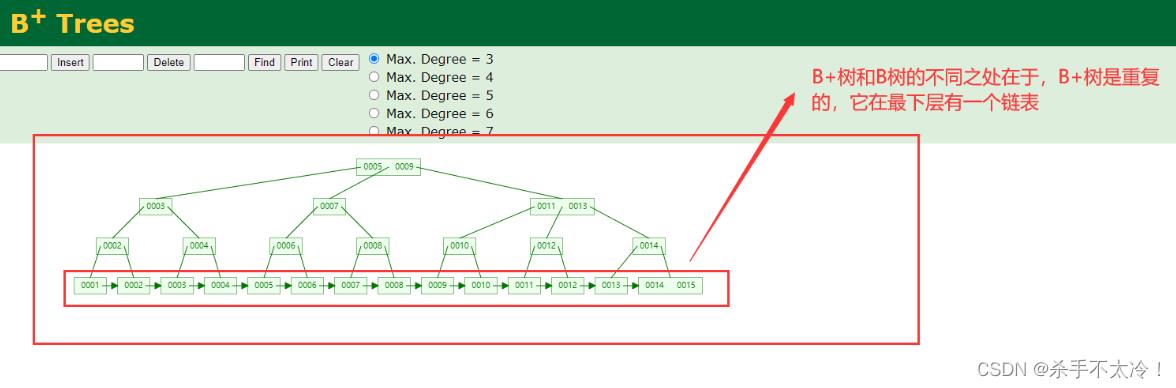
Btree 和B+tree之间的区别在于多了个双向链表,非叶字节点只存储键值,
字节点也就是双向链表是用来存储消息的,里面包含了非页字节点。虽然这样做会冗余但是这样做的好处可以降低我每个盘快的数据空间,盘快的大小是固定的,我不存数据,那么我这个盘块放的数据越大,那么我树的乘积相比btree,二叉树就越小。
B+树结构如下图:
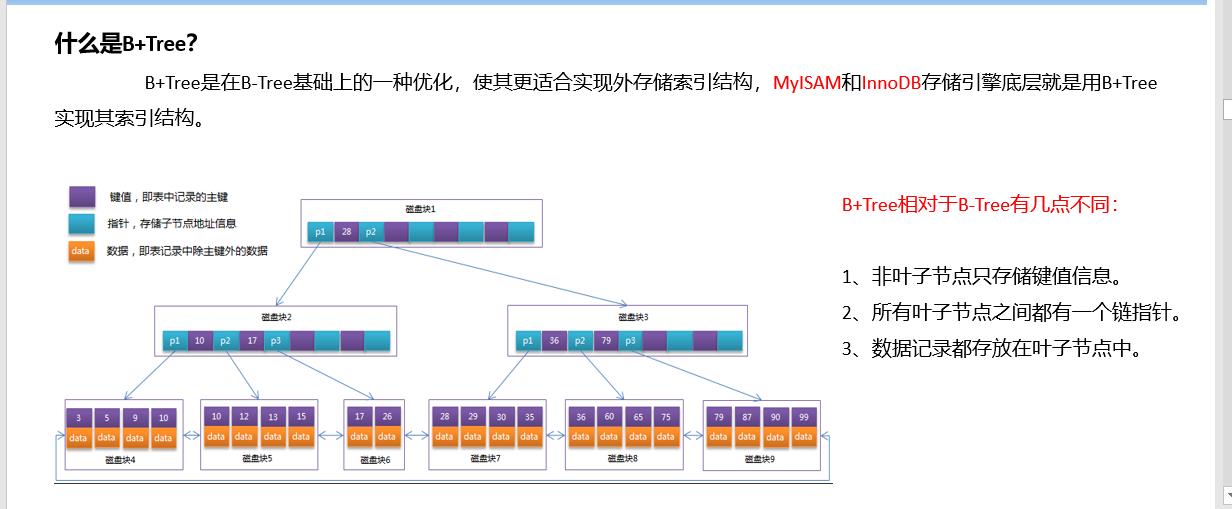
B树和B+树三层能存储的数据条数各自为多少?
如果是B树,三层数据全部都存满可以存储4069条数据,而如果是B+树,三层数据全部都存满可以存储千万条数据。
这里我们做个简单的计算:每个磁盘块16KB大小,假设指针不占用空间,一条数据1KB,每个磁盘块16条数据,三层B树能存储16 * 16 * 16=4096条数据,一个磁盘块代表一次IO,很明显数据量多的情况下,IO次数也会多,会影响查询性能,于是在B树的基础上衍生出了B+树。
此时也做一个简单的数据计算:一个两层的B+树,一个页16KB,假设一条记录1KB,一个叶子节点最多存放16条记录,根节点存放的都是指针和主键,假设主键是8字节,InnoDB指针大小是6字节,一共14字节,根节点可以存放16 * 1024B/14,大概是1170条,存储的数据就是1170 * 16=18720条,那么同理三层B+树能支持18720 * 1170=21902400条数据(千万级别)。相比于B树,B+树能在IO次数相同的情况下存储更多的数据,同时由于叶子节点之间是双向链表形式,能支持范围插叙,因此MySQL选择了B+树作为索引结构;
实际应用
对于B+树来说,三层存满按道理来讲是可以存储千万级别的数据的,但是要求你的key特别的小,如果你的key特别的大,那么我们前两层磁盘块当中存储的key的总的条数就会减少,所以我们整体存放的数据条数其实也就是会减少。**也因此我们设计数据库的时候,主键是该用int类型还是varchar类型呢?**这个就需要看实际情况了,如果我们的主键长度不超过4个字节,我们就是用int类型,如果超过了四个字节,我们就是用varchar类型,因为这个类型是可以指定长度的,我们可以让它的长度变成5或者6个字节,这就比使用long八个字节效率要高,因为它的前两层节点可以存放更多的主键记录了,这样三层里面可以存储更多的记录。
主键要不要自增呢?需要。
因为假如我们现在想要插入一个14,这个时候根据排序可以知道,它一定是插入到磁盘块5里面的,但是如果磁盘块5已经满了,那么怎么办呢?如下图:
这个时候就不得不分裂磁盘块5,并且像磁盘块2添加值,而且也需要改变很多指针,那假如好死不死,这个时候磁盘块2也满了,那么我们这个时候就有需要分裂磁盘块2,然后又要改变很多指针,所以是非常影响效率的,因此我们一定要通过主键自增来管理索引,这样的话我们新加如的索引一定是最大值,根据排序肯定是放到最右边的,就没有太多的磁盘分裂和指针管理,效率比较高。
索引的分类
- 主键索引:如果我们的索引使用的是我们的主键,那么这就叫做主键索引。
- 唯一索引:如果我们的索引使用的是唯一字段,那么我们这个索引就叫做唯一索引。
- 普通索引:如果我们的索引不是主键也不是唯一字段,那么我们的这个索引就叫做普通索引。
- 组合索引:如果我们的索引是表中的多个字段值共同构成的,那么我们的这个索引就叫做组合索引。
索引并不是越多越好,原因:
- 索引的维护会非常麻烦。
- 占用的磁盘空间会增大,这样我们如果要想存储更多的数据,就必须增加一个深度,这样的话我们就需要再进行一次IO,因为增加一个深度的时候牵涉到新增磁盘块,内存和磁盘块进行交互的时候是需要进行IO操作的。
以上是关于如何设计性能优良的mysql索引?的主要内容,如果未能解决你的问题,请参考以下文章