震惊!我竟然在1080Ti上加载了一个35亿参数的模型(ZeRO, Zero Redundancy Optimizer)
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了震惊!我竟然在1080Ti上加载了一个35亿参数的模型(ZeRO, Zero Redundancy Optimizer)相关的知识,希望对你有一定的参考价值。

背景
在最近几年,虽然大规模预训练模型已经越来越普遍,但是关于如何训练这些模型的内容却很少有人关注,一般都是一些财大气粗的企业或实验室来训练大模型并发布,然后中小型企业以及高校来使用。即便如此也有一些门槛,受限于机器配置,可能效果更好的大模型并不能直接加载到显卡中,或者是单机多卡希望可以通过分布式的方法进行微调。
目前训练超大规模语言模型主要有两条技术路线:TPU + XLA + TensorFlow 和 GPU + PyTorch + Megatron-LM + DeepSpeed。前者由Google主导,由于TPU和自家云平台GCP深度绑定,对于非Google开发者来说, 只可远观而不可把玩,后者背后则有NVIDIA、Meta、微软等大厂加持,社区氛围活跃,也更受到群众欢迎。
这篇文章介绍的ZeRO方法,就是可以让大模型变得更加亲民,不管是预训练、微调还是部署,即使没有A100、V100、P100之类的GPU服务器,也可以让加载大模型不是梦。
| 硬件 | 48 * Intel® Xeon® CPU E5-2650 v4 @ 2.20GHz 8 * 1080Ti GPUs(11GB显存) |
|---|---|
| 软件 | DeepSpeed |
| 模型 | GPT2-3.5B-chinese |
本次实验的模型是由IDEA发布的 Wenzhong2.0-GPT2-3.5B-chinese,这是一个基于解码器结构的单向语言模型,使用100G中文常用数据,32个A100训练了28个小时,是目前最大的开源GPT2中文大模型。接下来我们将在8块1080Ti显卡上微调这个大模型。
分布式模型训练
数据并行(Data Parallel, DP)
将模型复制到多张卡上,然后将数据切分到多个GPU上,并行训练,每一轮结束之后进行参数同步。
数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。在反向传播之后,模型的梯度将被全部减少,以便在不同设备上的模型参数能够保持同步。
数据并行由于简单易实现,应用最为广泛,当然这不表示它没有”缺点“,每张卡都存储一个模型,此时显存就成了模型规模的天花板。如果我们能减少模型训练过程中的显存占用,那不就可以训练更大的模型了?一个简单的观察是,如果有2张卡,那么系统中就存在2份模型参数,如果有4张卡,那么系统中就存在4份模型参数,如果有N张卡,系统中就存在N份模型参数,但其实其中N-1份都是冗余的,我们有必要让每张卡都存一个完整的模型吗?系统中能否只有一个完整模型,每张卡都存 1/N 参数,卡数越多,每张卡的显存占用越少,这样越能训练更大规模的模型。
优点:加快训练速度
缺点:模型大小上限为单个GPU显存
模型并行(Model Parallel, MP)
在数据并行训练中,一个明显的特点是每个 GPU 持有整个模型权重的副本。这就带来了冗余问题。另一种并行模式是模型并行,即模型被分割并分布在一个设备阵列上。通常有两种类型的并行:张量并行和流水线并行。张量并行是在一个操作中进行并行计算,如矩阵-矩阵乘法。流水线并行是在各层之间进行并行计算。因此,从另一个角度来看,张量并行可以被看作是层内并行,流水线并行可以被看作是层间并行。
张量并行(Tensor Parallel, TP)
将模型参数切分成分块矩阵,分配到不同的GPU上,参数更新时再进行同步。
张量并行将一个大的张量进行切分,然后分配到不同的GPU上,每个GPU只处理张量的一部分,并且只有在一些需要所有张量计算的时候才进行聚合。
张量并行需要在不同设备之间传递结果,因此不建议在跨节点之间进行张量并行,除非网络速度非常快。
优点:可以不受单张GPU显存限制,训练更大的模型。
缺点:计算/通信效率低。
流水线并行(Pipeline Parallel, PP)
将模型按层进行分组,然后分配到不同的GPU,在GPU之间进行前向传播和反向传播。
原生的流水线并行是指将模型层组划分到到多个GPU上,然后只需要简单地将数据从一个GPU移动到另一个GPU。流水线并行的实现相对比较简单,只需要将不同的层通过.to()方法切换即可。
流水线并行的核心思想是,模型按层分割成若干块,每块都交给一个设备。在前向传递过程中,每个设备将中间的激活传递给下一个阶段。在后向传递过程中,每个设备将输入张量的梯度传回给前一个流水线阶段。这允许设备同时进行计算,并增加了训练的吞吐量。流水线并行训练的一个缺点是,会有一些设备参与计算的冒泡时间,导致计算资源的浪费。
优点:层内计算/通信效率增加
缺点:存在空闲等待时间
数据并行+流水线并行
有了这几种并行方式之后,组合起来才能发挥更好的效果,数据并行和流水线并行相对来说比较简单,先将数据分成两份,放到两个节点上,然后在每个节点的多个GPU上再执行流水线并行。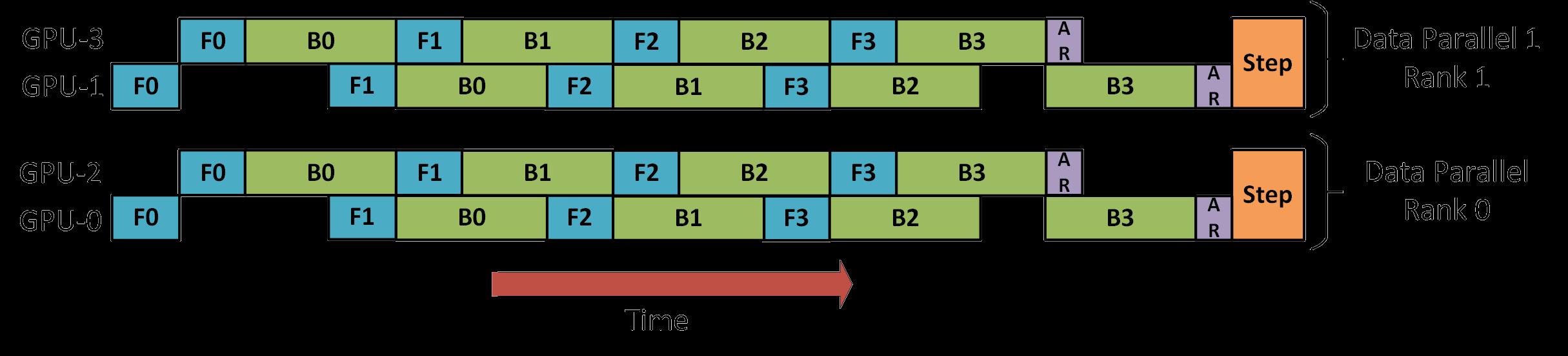
数据并行+流水线并行+模型并行
为了再进一步的提升效率,可以将三种并行方式都结合起来,称之为3D并行,如下图所示。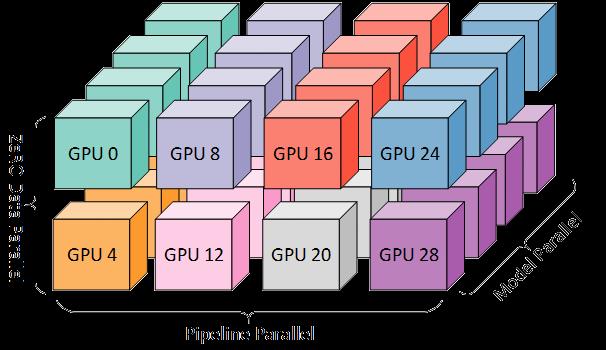
站在三维直角坐标系的角度看,x表示的是同一层内的张量并行,y轴表示的是同一节点内的流水线并行,z轴表示的是不同节点间的数据并行。
DeepSpeed
ZeRO(Zero Redundancy Optimizer)
类似于张量并行进行切分,支持多种offload技术。
目标:优化存储效率的同时还能保持较高的计算和通信效率。
为了能够在比较普通的机器上也能微调大模型,我们首先需要分析一下模型训练过程中都有哪些部分需要消耗存储空间。在进行深度学习训练的时候,有4大部分的显存开销,分别是模型参数(Parameters),模型参数的梯度(Gradients),优化器状态(Optimizer States)以及中间激活值(Intermediate Activations)。
优化模型占用空间
在训练过程中当然模型占用的空间是最大的,但是现有的方法中,不管是数据并行DP还是模型并行MP都不能很好的解决。数据并行有很好的计算/通信效率,但是由于模型复制了多份,导致空间利用率很差,而模型并行虽然内存利用率高,但是由于对模型的进行了很精细的拆分,导致计算/通信效率很低。除此之外,所有这些方法都静态保存了整个训练过程中所需的所有模型参数,但实际上并不是整个训练期间都需要这些内容。
ZeRO-DP
基于上述问题,提出了ZeRO-DP技术,即ZeRO驱动的数据并行,兼顾数据并行的计算/通信效率和模型并行的空间效率。首先ZeRO-DP会对模型状态进行分区,避免了复制模型导致的冗余,然后在训练期间使用动态通信调度保留数据并行的计算粒度和通信量,也能维持一个类似的计算/通信效率。
ZeRO-DP有三个优化阶段:① 优化器状态分区、② 梯度分区、③ 参数分区。
- 优化器状态分区(Optimizer State Partitioning, Pos):在与数据并行保持相同通信的情况下可以降低4倍空间占用;
- ① + 梯度分区(Gradient Partitioning, Pos+g):在与数据并行保持相同通信量的情况下可以降低8倍空间占用;
- ① + ② + 参数分区(Parameter Partitioning, Pos+g+p):空间占用减少量与GPU的个数呈线性关系 ,通信量增加50%。

模型参数(fp16)、模型梯度(fp16)和Adam状态(fp32的模型参数备份,fp32的momentum和fp32的variance)。假设模型参数量 Φ ,则共需要 2Φ+2Φ+(4Φ+4Φ+4Φ)=4Φ+12Φ=16Φ 字节存储。
优化剩余空间
优化了模型的空间利用率之后,接下来就要优化激活值、临时缓冲区和不可用空间碎片。
ZeRO-R
- 对于激活值,需要在前向传播的过程中存储,在反向传播的过程中利用。ZeRO-R激活分区识别和删除模型并行中冗余的激活函数值进行优化,并且在适当的时候会向CPU进行换入换出。
- 模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行AllReduce啥的,ZeRO-R预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要传输的数据较小,则多组数据bucket后再一次性传输,以达到内存和计算效率的平衡。
- 在训练过程中,不同张量的生命周期不同,会导致产生空间碎片,进而可能会导致连续空间分配失败。ZeRO-R根据张量的不同生命周期主动管理空间,防止产生空间碎片。
ZeRO与模型并行
既然ZeRO解决了数据并行中空间利用率低的问题,那么再进一步,怎么与模型并行进行配合使用呢?用了ZeRO之后,模型并行就仅仅被用在训练超大模型,ZeRO-DP在减少每个设备的空间占用方面跟模型并行一样有效,或者当模型并行不能均匀的划分模型时有效。
在分布式模型训练过程中,数据并行非常易于使用,但是模型并行的门槛相对比较高,需要AI工程师手动调整模型,甚至还需要系统开发人员自定义分布式算子,当然也有一些已有的工作,比如Megatron-LM。
混合精度训练(Mixed-Precision Training)
FP16
正常模型所使用的参数是Float浮点数类型,长度为4个字节,也就是32位。在一些不太需要高精度计算的应用中,比如图像处理和神经网络中,32位的空间有一些浪费,因此就又出现了一种新的数据类型,半精度浮点数,使用16位(2字节)来存储浮点值,简称FP16。
FP16的格式包括三部分:① 1 bit的符号位,② 5 bit的指数位宽,③ 11 bit的尾数精度(10位显式存储,1位隐式存储)。
0 01111 0000000000 = 1
0 01111 0000000001 = 1 + 2−10 = 1.0009765625 (1之后的最接近的数)
0 11110 1111111111 = 65504 (max half precision)
0 11111 0000000000 = infinity
1 11111 0000000000 = −infinity
但是在大型语言模型中直接使用FP16会有一些问题,如下图所示,这是huggingface训练一个104B的模型时的loss,可以发现非常的不稳定,除此之外Facebook最近发布的175B的OPT模型也报告了相同的问题。
问题在于FP16的指数位宽只有5 bit,因此可能会出现溢出的问题,它能表示的最大整数就是65504,也就是说一旦权重超过这个值就会溢出。
BF16
为了解决FP16的问题,Google的人工智能研究小组就开发了一种新的浮点数格式——BF16(Brain Floating Point),用于降低存储需求,提高机器学习算法的计算速度。
BF16的格式包括三部分:① 1 bit的符号位,② 8 bit的指数位宽,③ 8 bit的尾数精度(7位显式存储,1位隐式存储)。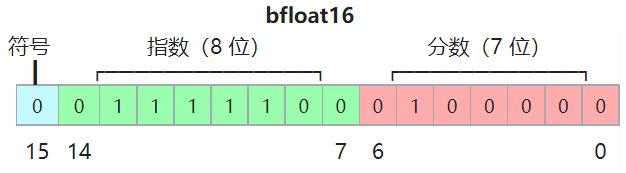
3f80 = 0 01111111 0000000 = 1
c000 = 1 10000000 0000000 = -2
7f7f = 0 11111110 1111111 = (2^8 − 1) × 2^−7 × 2^127 ≈ 3.38953139 × 10^38(bfloat16 精度的最大有限正值)
模型参数不管是使用BF16还是FP16,在优化器中更新的权重参数必须是用FP32的形式保存的,因此16位的浮点数仅用于计算。
ZeRO-Offload
ZeRO说到底是一种数据并行方案,可是很多人只有几张甚至一张卡,显存加起来都不够,那怎么办呢?在操作系统中,当内存不足时,可以选择一些页面进行换入换出,为新的数据腾出空间。类比一下,既然是因为显存不足导致一张卡训练不了大模型,那么ZeRO-Offload的想法就是:显存不足,内存来补。
在一个典型的服务器上,CPU 可以轻松拥有几百GB的内存,而每个 GPU 通常只有16或32GB的内存。相比于昂贵的显存,内存比较廉价,之前的很多工作都是聚焦在内存显存的换入换出,并没有用到CPU的计算能力,也没有考虑到多卡的场景。ZeRO-Offload则是将训练阶段的某些模型状态从GPU和显存卸载到CPU和内存。
当然ZeRO-Offload并不希望为了最小化显存占用而牺牲计算效率, 否则的话还不如直接使用CPU和内存,因为即使将部分GPU的计算和显存卸载到CPU和内存,肯定要涉及到GPU和CPU、显存和内存的通信,而通信成本一般是非常高的,此外GPU的计算效率比CPU的计算效率高了好几个数量积,因此也不能让CPU参与过多的计算。
在ZeRO-Offload的策略中,将模型训练过程看作数据流图,用圆形节点表示模型状态,比如参数、梯度和优化器状态,用矩形节点表示计算操作,比如前向传播、反向传播和参数更新,边表示数据流向。下图是某一层的一次迭代过程(iteration/step),使用了混合精读训练,前向计算(FWD)需要用到上一次的激活值(activation)和本层的参数(parameter),反向传播(BWD)也需要用到激活值和参数计算梯度,
如果用Adam优化器进行参数更新(Param update),边添加权重,物理含义是数据量大小(单位是字节),假设模型参数量是 M ,在混合精度训练的前提下,边的权重要么是2M(fp16),要么是4M(fp32)。
**现在要做的就是沿着边把数据流图切分为两部分,分布对应GPU和CPU,**计算节点(矩形节点)落在哪个设备,哪个设备就执行计算,数据节点(圆形)落在哪个设备,哪个设备就负责存储,将被切分的边权重加起来,就是CPU和GPU的通信数据量。
ZeRO-Offload的切分思路是:图中有四个计算类节点:FWD、BWD、Param update和float2half,前两个计算复杂度大致是 O(MB) , B 是batch size,后两个计算复杂度是 O(M) 。为了不降低计算效率,将前两个节点放在GPU,后两个节点不但计算量小还需要和Adam状态打交道,所以放在CPU上,Adam状态自然也放在内存中,为了简化数据图,将前两个节点融合成一个节点FWD-BWD Super Node,将后两个节点融合成一个节点Update Super Node。如下图右边所示,沿着gradient 16和parameter 16两条边切分。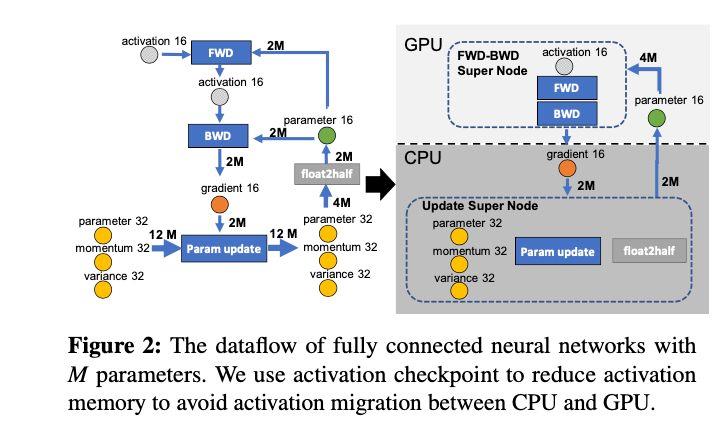
现在的计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket后,一边计算新的梯度一边将bucket传输给CPU,当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示。
到目前为止还都是单卡的场景,在多卡场景中,ZeRO-Offload可以利用ZeRO-2,将优化器状态和梯度进行切分,每张卡只保留
1
N
\\frac1N
N1,结合上ZeRO-Offload同样是将这
1
N
\\frac1N
N1的优化器状态和梯度卸载到内存,在CPU上进行参数更新。在多卡场景,利用CPU多核并行计算,每张卡至少对应一个CPU进程,由这个进程负责进行局部参数更新。
并且CPU和GPU的通信量和 N 无关,因为传输的是fp16 gradient和fp16 parameter,总的传输量是固定的,由于利用多核并行计算,每个CPU进程只负责 1N 的计算,反而随着卡数增加节省了CPU计算时间。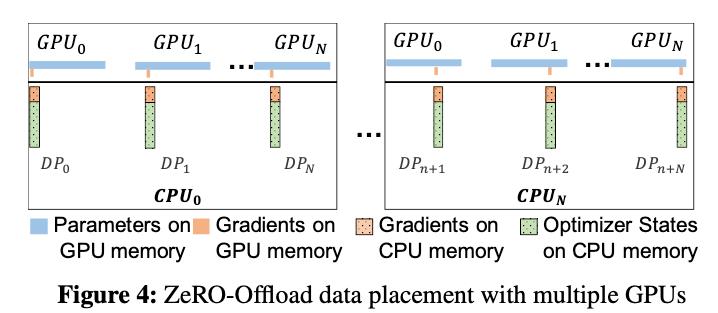
ZeRO-Infinity
从GPT-1到GPT-3,两年时间内模型参数0.1B增加到175B,而同期,NVIDIA的显卡是从V100的32GB显存增加A100的80GB,显然,显寸的提升速度远远赶不上模型模型增长的速度,这就是内存墙问题。
所谓内存墙,其实就是硬件之间的通信会遇到瓶颈,不管是GPU之间还是GPU和CPU之间,通信的效率远低于计算的效率。在过去20年中,硬件的峰值计算能力增加了90,000倍,但是内存/硬件互连带宽却只是提高了30倍。
ZeRO-Infinity这篇论文就是用来解决内存墙的问题,但是它并不是打通了内存墙,而是通过NVMe。NVMe是一种接口规范,最开始是用在SSD固态硬盘上的,之前的SSD用的都是SATA接口规范,数据传输速率最大6Gbps,而NVMe就是一种新的技术,NVMe固态硬盘拥有高达20Gbps的理论传输速度。
ZeRO-Infinity就是依靠 CPU 甚至是 NVMe 磁盘来训练大型模型。主要的想法是,在不使用张量时,将其卸载回 CPU 内存或 NVMe 磁盘。通过使用异构系统架构,有可能在一台机器上容纳一个巨大的模型。
实践
目标:微调 Wenzhong2.0-GPT2-3.5B-chinese

- 估计使用ZeRO-3配置需要的参数、优化器状态和梯度的使用需求
python -c 'from transformers import GPT2Model; \\
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \\
model = GPT2Model.from_pretrained("IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese"); \\
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
Some weights of the model checkpoint at IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese were not used when initializing GPT2Model: ['lm_head.weight']
- This IS expected if you are initializing GPT2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing GPT2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 3556M total params, 154M largest layer params.
per CPU | per GPU | Options
89.42GB | 0.58GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
158.98GB | 0.58GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
79.49GB | 1.40GB | offload_param=none, offload_optimizer=cpu , zero_init=1
158.98GB | 1.40GB | offload_param=none, offload_optimizer=cpu , zero_init=0
6.91GB | 8.03GB | offload_param=none, offload_optimizer=none, zero_init=1
158.98GB | 8.03GB | offload_param=none, offload_optimizer=none, zero_init=0
- 实际训练中每块显卡的占用情况
实验
配置文件
#!/bin/bash
set -x -e
echo "START TIME: $(date)"
MICRO_BATCH_SIZE=1
ROOT_DIR=$(pwd)
ZERO_STAGE=3
config_json="$ROOT_DIR/training_config.json"
cat <<EOT >$config_json
"train_micro_batch_size_per_gpu": $MICRO_BATCH_SIZE,
"steps_per_print": 1000,
"gradient_clipping": 1,
"zero_optimization":
"stage": $ZERO_STAGE,
"allgather_partitions": false,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true,
"offload_optimizer":
"device": "cpu",
"pin_memory": true
,
"offload_param":
"device": "cpu",
"pin_memory": true
,
"stage3_max_live_parameters" : 2e8,
"stage3_max_reuse_distance" : 2e8,
"stage3_prefetch_bucket_size": 2e8,
"stage3_param_persistence_threshold": 2e8,
"sub_group_size" : 2e8,
"round_robin_gradients": true
,
"bf16":
"enabled": true
,
"optimizer":
"type": "Adam",
"params":
"lr": 1e-5,
"betas": [0.9,0.95],
"eps": 1e-8,
"weight_decay": 1e-2
,
"scheduler":
"type": "WarmupLR",
"params":
"warmup_min_lr": 5e-6,
"warmup_max_lr": 1e-5
EOT
export PL_DEEPSPEED_CONFIG_PATH=$config_json
TRAINER_ARGS="
--max_epochs 1 \\
--num_nodes 2 \\
--gpus 8 \\
--strategy deepspeed_stage_$ZERO_STAGE_offload \\
--default_root_dir $ROOT_DIR \\
--dirpath $ROOT_DIR/ckpt \\
--save_top_k 3 \\
--monitor train_loss \\
--mode min \\
--save_last \\
"
DATA_DIR=/home/liuzhaofeng/nlg_pipeline/gpt2/dialog/datasets
DATA_ARGS="
--data_dir $DATA_DIR \\
--max_seq_length 64 \\
--train_batchsize $MICRO_BATCH_SIZE \\
--valid_batchsize $MICRO_BATCH_SIZE \\
--train_data test_train.txt \\
--valid_data test.txt \\
--test_data test.txt
"
PRETRAINED_MODEL_PATH="IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese"
MODEL_ARGS="
--pretrained_model_path $PRETRAINED_MODEL_PATH \\
--output_save_path $ROOT_DIR/predict.json \\
--learning_rate 1e-4 \\
--weight_decay 0.1 \\
--warmup 0.01 \\
"
SCRIPTS_PATH=$ROOT_DIR/finetune_gpt2.py
export CMD=" \\
$SCRIPTS_PATH \\
$TRAINER_ARGS \\
$MODEL_ARGS \\
$DATA_ARGS \\
"
export NCCL_IB_DISABLE=1
export NCCL_DEBUG_SUBSYS=INIT,P2P,SHM,NET,GRAPH,ENV
export NCCL_SOCKET_IFNAME=enp129s0f1
torchrun $CMD
压力测试
| BATCH_SIZE | max_seq_length | 内存占用 | 显存占用 |
|---|---|---|---|
| 1 | 64 | 153G | 5669M |
| 128 | 153G | 6041M | |
| 256 | 154G | 7139M | |
| 512 | 154G | 9383M | |
| 2 | 64 | 153G | 6367M |
| 128 | 153G | 7439M | |
| 256 | 153G | 9651M | |
| 512 | OOM | ||
| 3 | 64 | 167G | 6431M |
| 128 | 166G | 8273M | |
| 256 | 163G | 11103M |
以上是关于震惊!我竟然在1080Ti上加载了一个35亿参数的模型(ZeRO, Zero Redundancy Optimizer)的主要内容,如果未能解决你的问题,请参考以下文章
震惊!我竟然在1080Ti上加载了一个35亿参数的模型(ZeRO, Zero Redundancy Optimizer)
如何在同一个 docker 映像上使用不同类型的 gpus(例如 1080Ti 与 2080Ti)而不需要重新运行“python setup.py develop”?