Mybatis-Plus进阶篇
Posted 程序员小赵OvO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis-Plus进阶篇相关的知识,希望对你有一定的参考价值。
书接上文,讲解完MP的基本知识,我们已经可以独立完成增删改查的功能,本文将讲解一些MP更加深入的知识,让我们开始吧
主键策略
简单来说就是我们该用哪种方式生成主键,这里的主键策略和IdType相关,每一种IdType代表着一种主键生成策略
示例:@TableId(value = “id”, type = IdType.INPUT)
全部的IdType如下:
| 值 | 描述 | 备注 |
|---|---|---|
| AUTO | 数据库 ID 自增 | AUTO自动增长策略,这个配合数据库使用,mysql可以,但是Oracle不行 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) | 在 application.properties 中添加如下配置:mybatis-plus.global-config.db-config.id-type=auto |
| INPUT | insert 前自行 set 主键值 | INPUT进行自己传递主键即可,进行插入工作,但在插入之前一定要检查数据库是否已经存在了该主键Mybatis-Plus 内置了5个数据库主键序列(如果内置支持不满足你的需求,可实现 IKeyGenerator 接口来进行扩展,下面会详细讲解) |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) | 使用雪花算法自动生成主键 ID(雪花算法自行了解) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String,使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) | 自动生成不含中划线的 UUID 作为主键 |
接下来我们分别测试一下吧
测试主键策略-AUTO
@TableId(value = "id", type = IdType.AUTO)
private Long id;
@Test
public void testMPKeyGenerator()
User user = new User();
user.setName("张三");
user.setEmail("123@qq.com");
user.setAge(12);
user.setCreateTime(LocalDateTime.now());
boolean save = userService.save(user);
System.out.println(save);
测试结果:主键ID+1
测试主键策略-NONE
application.properties
mybatis-plus:
global-config:
db-config:
id-type: auto
@TableId(value = "id", type = IdType.NONE)
private Long id;
测试结果:主键ID+1
注意:注解里等于跟随全局,下面是TableId代码
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD, ElementType.ANNOTATION_TYPE)
public @interface TableId
String value() default "";
IdType type() default IdType.NONE;
测试主键策略-INPUT
@TableId(value = "id", type = IdType.INPUT)
private Long id;
@Test
public void testMPKeyGenerator()
User user = new User();
user.setId(100l);
user.setName("张三");
user.setEmail("123@qq.com");
user.setAge(12);
user.setCreateTime(LocalDateTime.now());
boolean save = userService.save(user);
System.out.println(save);
注意:如果在input策略下不自己设置主键值,并且数据库主键不是自动增长就会报错
虽然MP内置了5种5个数据库主键序列:
- DB2KeyGenerator
- H2KeyGenerator
- KingbaseKeyGenerator
- OracleKeyGenerator
- PostgreKeyGenerator
我们可以这样使用(由于作者只有MySQL数据库,所以这里代码参照官方):
实体类
@KeySequence(value = "SEQ_ORACLE_STRING_KEY", clazz = String.class)
public class YourEntity
@TableId(value = "ID_STR", type = IdType.INPUT)
private String idStr;
配置类
@Configuration
public class MPConfig
@Bean
public IKeyGenerator keyGenerator()
return new H2KeyGenerator();
如果内置支持不满足你的需求,可实现 IKeyGenerator 接口来进行扩展
测试主键策略-ASSIGN_ID
@TableId(value = "id", type = IdType.ASSIGN_ID)
private Long id;
测试结果:生成了 1577481548734758914 这样的主键值,并且雪花算法生成的位数在18-19位之间
测试主键策略-ASSIGN_UUID
@TableId(value = "row_guid", type = IdType.ASSIGN_UUID)
private String rowGuid;
测试结果:生成了 469870f6ff62a9608d7f5509031c6cec 这样的主键值
自定义ID生成器
MP自 3.3.0 开始,默认使用雪花算法 或者UUID(不含中划线)
ASSIGN_ID 使用接口 IdentifierGenerator 的方法 nextId (默认实现类为 DefaultIdentifierGenerator )
public Long nextId(Object entity)
return this.sequence.nextId();
Sequence类的nextId
public synchronized long nextId()
long timestamp = this.timeGen();
if (timestamp < this.lastTimestamp)
long offset = this.lastTimestamp - timestamp;
if (offset > 5L)
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));
try
this.wait(offset << 1);
timestamp = this.timeGen();
if (timestamp < this.lastTimestamp)
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));
catch (Exception var6)
throw new RuntimeException(var6);
if (this.lastTimestamp == timestamp)
this.sequence = this.sequence + 1L & 4095L;
if (this.sequence == 0L)
timestamp = this.tilNextMillis(this.lastTimestamp);
else
this.sequence = ThreadLocalRandom.current().nextLong(1L, 3L);
this.lastTimestamp = timestamp;
return timestamp - 1288834974657L << 22 | this.datacenterId << 17 | this.workerId << 12 | this.sequence;
而使用接口 IdentifierGenerator 的方法 nextUUID (默认 default 方法)
default String nextUUID(Object entity)
return IdWorker.get32UUID();
如果这些无法满足你的需求,我们可以实现 IdentifierGenerator
@Component
public class CustomIdGenerator implements IdentifierGenerator
@Override
public Long nextId(Object entity)
//可以将当前传入的class全类名来作为bizKey,或者提取参数来生成bizKey进行分布式Id调用生成.
String bizKey = entity.getClass().getName();
System.out.println("===" + bizKey + "===");
//自定义主键ID生成(这里使用hutool封装的雪花算法)
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
return snowflake.nextId();
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.2.5</version>
</dependency>
测试:控制台输出=mybatisplusdemo.User=,说明传入的类型是当前实体类类型,数据库插入的主键也是类似于 1577494790868701184 的一串数字
逻辑删除
什么是逻辑删除呢?之前也是没有接触过,删除就删除咋还有逻辑删除?接触了公司项目才知道什么是逻辑删除
平时自己在开发的时候可能会把无用的数据直接删除,用户删除数据那就是真在数据库删除,假如用户想找回数据基本不可能。而逻辑删除至少数据还在数据库里存在
其实逻辑删除也很简单就是增加一个字段来作为逻辑删除的标志位,一般都是1为删除 0为未删除。那肯定有人要问了那我们删除和查询的时候不还得自己去判断0,1么?当然不用,这些MP都帮我们做好了,只要我们设置好了,MP就会在删除和查询的时候帮我们自动加上过滤条件,就是这么方便
只对自动注入的 sql 起效:
- 插入: 不作限制
- 查找: 追加 where 条件过滤掉已删除数据,如果使用 wrapper.entity 生成的 where 条件也会自动追加该字段
- 更新: 追加 where 条件防止更新到已删除数据,如果使用 wrapper.entity 生成的 where 条件也会自动追加该字段
- 删除: 转变为 更新
例如:
- 删除: update user set deleted=1 where id = 1 and deleted=0
- 查找: select id,name,deleted from user where deleted=0
字段类型支持说明:
- 支持所有数据类型(推荐使用 Integer,Boolean,LocalDateTime)
- 如果数据库字段使用datetime,逻辑未删除值和已删除值支持配置为字符串null,另一个值支持配置为函数来获取值如now()
附录:
- 逻辑删除是为了方便数据恢复和保护数据本身价值等等的一种方案,但实际就是删除。
- 如果你需要频繁查出来看就不应使用逻辑删除,而是以一个状态去表示。
接下来我们写代码吧
我们需要在配置文件中增加逻辑删除的配置
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2)
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
首先我们需要在原来的实体类上加个deleted字段,官方推荐 Integer,Boolean,LocalDateTime
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(value = "user")
public class User
@TableId(value = "id", type = IdType.AUTO)
private Long id;
@TableField(value = "name")
private String name;
@TableField(value = "age")
private Integer age;
@TableField(value = "email")
private String email;
@TableField(value = "create_time")
private LocalDateTime createTime;
@TableField(value = "deleted")
private Integer deleted;
我们测试一下查询
@Test
public void testLogicDeleteQuery()
List<User> list = userService.list();
System.out.println(list);
结果:只会返回deleted=0的数据
我们再测试一下删除
@Test
public void testLogincDeleteDelete()
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "张三");
boolean remove = userService.remove(queryWrapper);
System.out.println(remove);
结果:所有name="张三"的deleted字段都置为了1
注意:那么该如何插入的时候需要插入deleted字段么?需要,只不过角度不同,这里官方提供了三种方式:
- 字段在数据库定义默认值(推荐)
- insert 前自己 set 值
- 使用自动填充功能(这里下面会讲解到)
自动填充
在以前日常开发中,经常会出现一张表中有多个共用的字段,比如创建时间,创建人,最后更新时间,最后更新人,以及上面提到的逻辑删除标志位等等。这些共用的字段都可以通过MP自动填充来帮助我们填充,我们只需要关注那些特有字段即可,下面是具体代码
@Data
public abstract class BaseModel
@TableField(value = "create_by", fill = FieldFill.INSERT)
private String createBy;
@TableField(value = "update_by", fill = FieldFill.UPDATE)
private String updateBy;
@TableField(value = "deleted", fill = FieldFill.INSERT)
private String deleted;
@TableField(value = "create_time", fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(value = "update_time", fill = FieldFill.UPDATE)
private LocalDateTime updateTime;
因为多个实体类有着共同的字段,所以我们抽取一个基类,里面全是共用的字段。其中有些字段是我们在插入的时候就需要设置,比如:创建人,创建时间,逻辑删除标志位,还有一些是更新时需要更新,比如:更新时间,更新人。这里用FieldFill来标识他们
@Data
@TableName(value = "company")
public class Company extends BaseModel
@TableId(type = IdType.AUTO)
private Integer id;
@TableField(value = "row_guid")
private String rowGuid;
@TableField(value = "company_name")
private String companyName;
Company类中包含特有字段
public enum FieldFill
/**
* 默认不处理
*/
DEFAULT,
/**
* 插入填充字段
*/
INSERT,
/**
* 更新填充字段
*/
UPDATE,
/**
* 插入和更新填充字段
*/
INSERT_UPDATE
@Component
public class MyMetaObjectHandler implements MetaObjectHandler
/**
* 插入时填充
*/
@Override
public void insertFill(MetaObject metaObject)
System.out.println("start insert fill....");
this.strictInsertFill(metaObject, "createBy", String.class, "张三");
this.strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now());
this.strictInsertFill(metaObject, "deleted", String.class, "0");
/**
* 更新时填充
*/
@Override
public void updateFill(MetaObject metaObject)
System.out.println("start update fill....");
this.strictUpdateFill(metaObject, "updateBy", String.class, "王五");
this.strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now());
要想实现自动填充的功能就需要我们自定义一个类去实现 MetaObjectHandler 覆盖其中的 insertFill 和 updateFill 方法,需要在其中给 strictInsertFill和 strictUpdateFill传入4个参数,第一个是源对象(方法中传入的),第二个是数据库字段对应的成员属性名,第三个是成员属性的class对象,第四个是需要插入/更新的值
测试插入
@Test
public void testFill()
Company company = new Company();
company.setRowGuid("123");
company.setCompanyName("华为");
int insert = companyMapper.insert(company);
System.out.println(insert);
结果:创建人,创建时间,逻辑删除字段都自动插入了
测试更新
@Test
public void testUpdateFill()
Company company = new Company();
company.setRowGuid("1234");
company.setCompanyName("华为1");
QueryWrapper<Company> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("company_name", "华为");
int update = companyMapper.update(company, queryWrapper);
System.out.println(update);
结果:更新人,更新时间都自动更新了
注意事项:
- 填充原理是直接给entity的属性设置值!!!
- 注解则是指定该属性在对应情况下必有值,如果无值则入库会是null
- MetaObjectHandler提供的默认方法的策略均为:如果属性有值则不覆盖,如果填充值为null则不填充
- 字段必须声明TableField注解,属性fill选择对应策略,该声明告知Mybatis-Plus需要预留注入SQL字段
- 填充处理器MyMetaObjectHandler在 Spring Boot 中需要声明@Component或@Bean注入
- 要想根据注解FieldFill.xxx和字段名以及字段类型来区分必须使用父类的strictInsertFill或者strictUpdateFill方法
- 不需要根据任何来区分可以使用父类的fillStrategy方法
- update(T t,Wrapper updateWrapper)时t不能为空,否则自动填充失效
执行SQL分析打印
平时开发我都是用日志来查看SQL的,如下:
logging:
level:
mybatisplusdemo: debug
接下来我们看看MP的SQL语句分析打印吧
首先要引入依赖
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>最新版本</version>
</dependency>
修改配置文件
server:
port: 8181
# DataSource Config
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:mysql://127.0.0.1:3306/mybatis_plus?useSSL=false&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF8&autoReconnect=true&failOverReadOnly=false
username: root
password: 123456
编写p6spy配置文件spy.properties
modulelist=com.p6spy.engine.logging.P6LogFactory,com.p6spy.engine.outage.P6OutageFactory
# 自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
# 使用日志系统记录 sql
#appender=com.p6spy.engine.spy.appender.Slf4JLogger
# 设置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前缀
useprefix=true
# 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
# 实际驱动可多个
#driverlist=org.h2.Driver
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 2 秒
outagedetectioninterval=2
测试
@Test
public void testLogicDeleteQuery()
List<User> list = userService.list();
System.out.println(list);
控制台输出
Consume Time一篇朴实无华的MyBatis-Plus小白看完原地进阶的文章CRUD1简单单表查询
⚠⚠⚠自信攻城狮小名又来攻城啦⚠⚠⚠

文章目录
现在越来越多的公司选用MyBatis-Plus,但是呢,以前小名总是习惯使用sql语句写查询说白了就是当MyBatis用,并没有真正体会到MP真正的强大之处。现在在工作中小名慢慢体会到了MP条件构造器的强大之处,所以想着把工作中常用的一些东西分享给大家~🎉🎉🎉大佬请绕行😅

欢迎来到小名的新专栏:通过MyBatis-Plus【CRUD】系列文章的第一篇,本文主要内容是单表查询,下一篇小名计划是写多表查询
1. 什么?mybatis-plus的多表查询,你还在写sql语句?!【CRUD2】多表联查的三种方式
2. 【CRUD】番外篇
3. 此专栏下其他文章
数据表
practice_user:
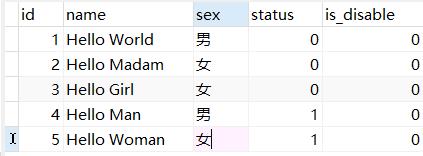
公用:
PracticeUserService.java
/**
* 通过sql模糊查询
* @return
*/
List<PracticeUser> selectUserBySql(PracticeUser practiceUser);
/**
* 通过QueryWapper()模糊查询
* @return
*/
List<PracticeUser> selectUserByQueryWapper(PracticeUser practiceUser);
/**
* 通过stream()过滤查询
* @return
*/
List<PracticeUser> selectUserByStream(PracticeUser practiceUser);
一、SQL
1. PracticeUserMapper.xml
<select id="selectUserBySql" resultType="eamon.daily.practice.user.entity.pojo.PracticeUser">
SELECT
*
FROM `practice_user`
where sex = #{sex}
<if test="name!=null and name!=''">
and `name` like concat('%',#{name},'%')
</if>
</select>
2. PracticeUserMapper.java
/**
* 通过sql模糊查询
* @return
*/
List<PracticeUser> selectUserBySql(PracticeUser practiceUser);
3. PracticeUserServiceImpl.java
@Override
public List<PracticeUser> selectUserBySql(PracticeUser practiceUser) {
return practiceUserMapper.selectUserBySql(practiceUser);
}
4.结果

上面就是小名最常用的sql方式,感觉有点浪费项目里引的
MP依赖了

下面咱们再来看一下
MP尽人皆知的条件构造器
二、QueryWapper()
1. PracticeUserServiceImpl.java
@Override
public List<PracticeUser> selectUserByQueryWapper(PracticeUser practiceUser) {
QueryWrapper<PracticeUser> wrapper = new QueryWrapper<>();
wrapper.eq("sex", practiceUser.getSex());
wrapper.like(StringUtils.isNotBlank(practiceUser.getName()), "name", practiceUser.getName());
return iPracticeUserService.getBaseMapper().selectList(wrapper);
}
2. 结果
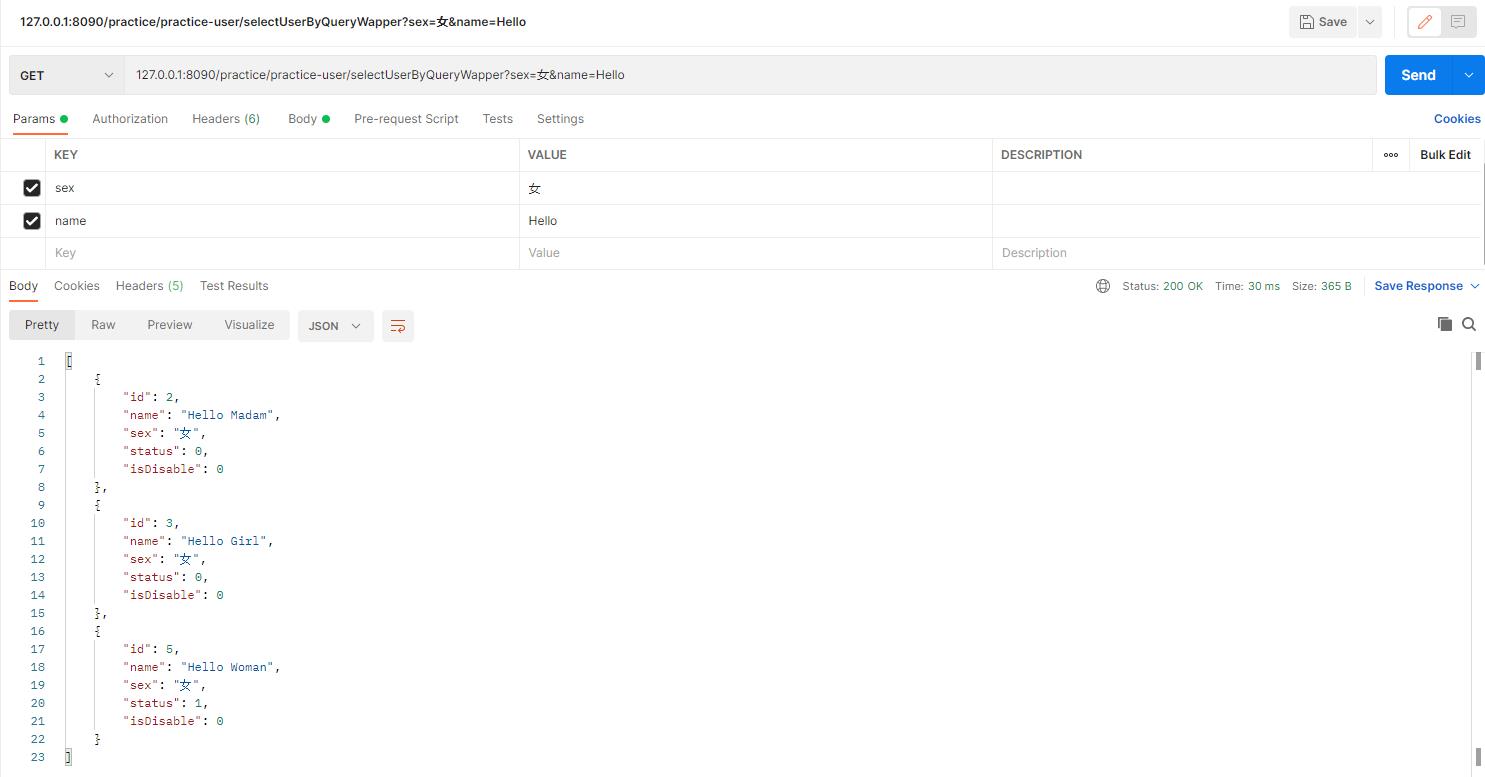
QueryWapper()这种方式官网首推,百度也是漫天遍地的文章,文采都比小名好多了,所以大家自行百度吧

其实就是懒得搬
三、链式调用 lambda 式条件构造器并通过stream()模糊查询
1. PracticeUserServiceImpl.java
//全表查询
List<PracticeUser> AllList = iPracticeUserService.lambdaQuery()
.eq(StringUtils.isNotBlank(practiceUser.getSex()) , PracticeUser::getSex,practiceUser.getSex())
.list();
//模糊查询
List<PracticeUser> collect = AllList.stream()
.filter(o -> null!=practiceUser.getName() && o.getName().contains(practiceUser.getName()))
.collect(Collectors.toList());
return collect;
2.1. 结果一
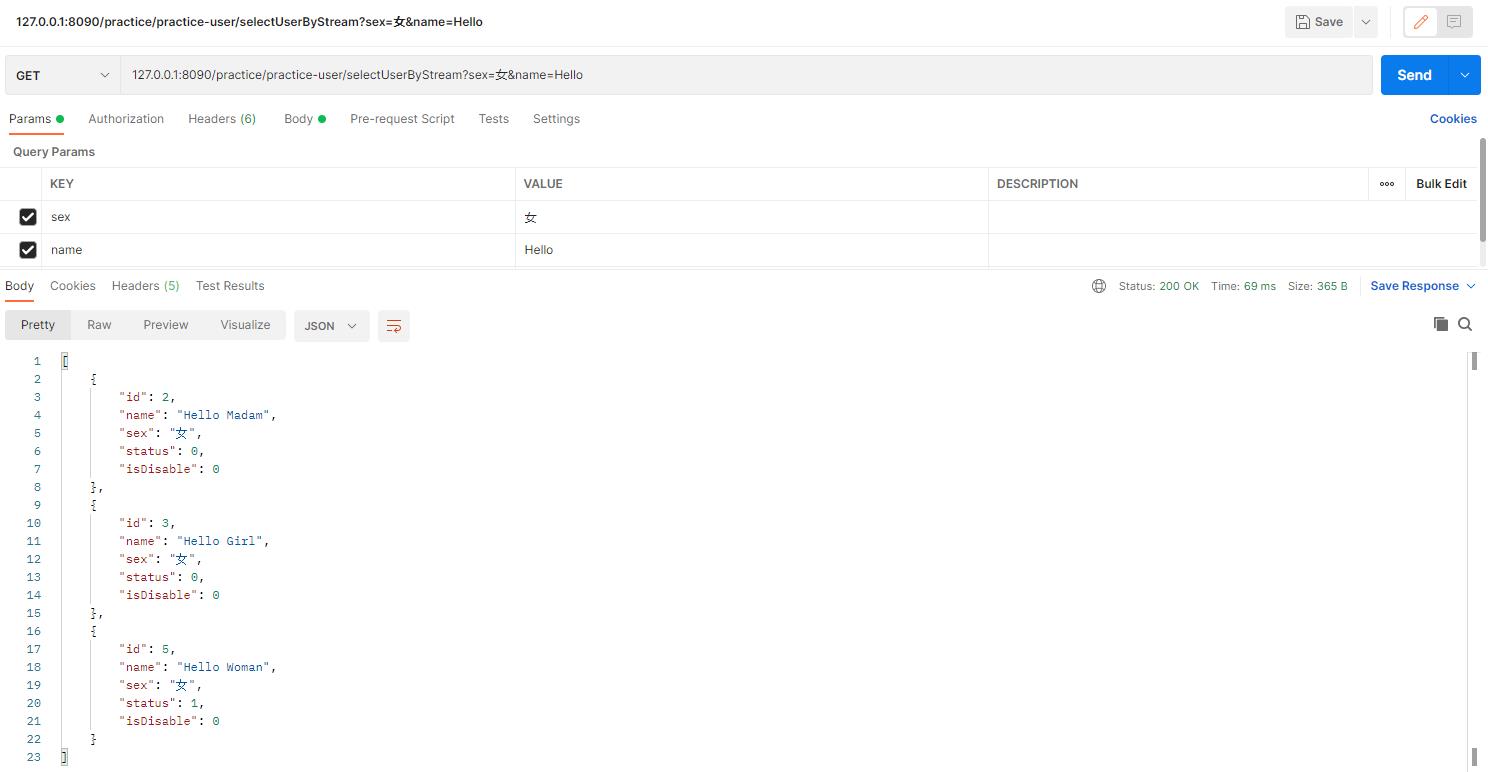
当然你完全可以将
//全表查询
List<PracticeUser> AllList = iPracticeUserService.lambdaQuery().eq(PracticeUser::getSex,practiceUser.getSex()).list();
替换为:
LambdaQueryWrapper<PracticeUser> lambda = new LambdaQueryWrapper<>();
lambda.eq(PracticeUser::getSex,practiceUser.getSex());
List<PracticeUser> AllList = iPracticeUserService.getBaseMapper().selectList(lambda);
第二种虽然看起来代码不如第一种代码简洁,但是它可以完成一些骚操作:
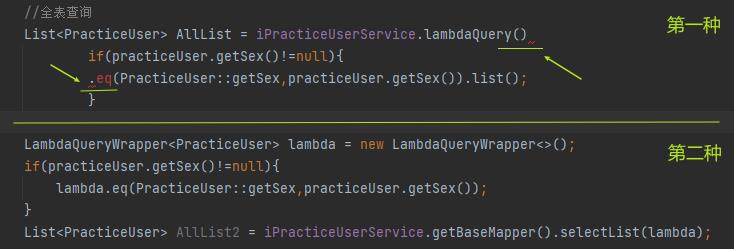
我们可以看出来第一种在编译时就已经报错了,第二种却没有。
所以我们可以利用这个点,做一些骚操作,例如:我们可以把公共的查询条件抽出来放到代码最上面,下面再根据不同代码逻辑,将查询条件加入到条件构造器“lambda”中
LambdaQueryWrapper<PracticeUser> lambda = new LambdaQueryWrapper<>();
lambda.eq(PracticeUser::getSex,practiceUser.getSex());
if(情景一){
if(条件){
lambda.eq(xx::xx,xxxx);
}
}else if(情景二){
if(条件一){
lambda.eq(xx::xx,xxxx);
}
if(条件二){
lambda.eq(xx::xx,xxxx);
}
}
这里查询条件就可以根据不同的情景构造不同的查询条件
这里只是做了抛砖引玉,大家可以想想可以用到项目中的那些地方。
其实第一种也可以判空:

2.2. 结果二
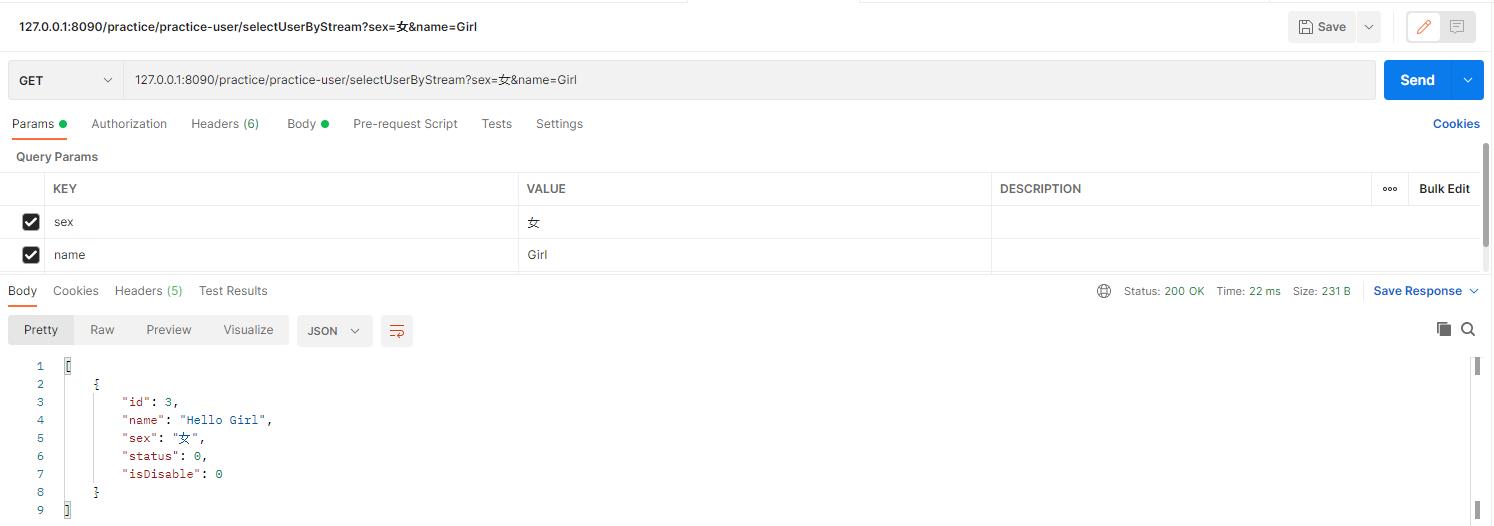

完事儿~收工!
如果觉得小名的文章帮助到了您,请关注小名的新专栏
MyBatis-Plus【CRUD】,支持一下小名😄,给小名的文章点赞👍、评论✍、收藏🤞谢谢大家啦~♥♥♥
以上是关于Mybatis-Plus进阶篇的主要内容,如果未能解决你的问题,请参考以下文章