datax的架构原理
Posted byc笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了datax的架构原理相关的知识,希望对你有一定的参考价值。
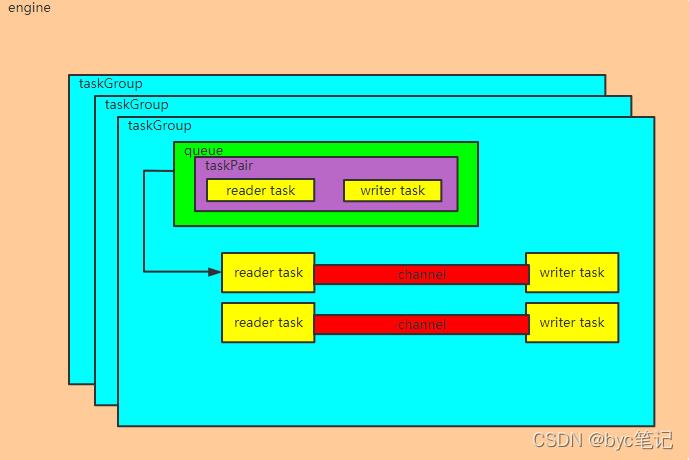
我们会预先确定好:channel的数量,factor 数量,切分主键,每个taskGroup的最大channel数量
engine是一个主线程,会根据reader设置切分的规则对读取任务进行切分成多个task,writertask的数量会和reader task数量保持一致,我们姑且理解这个为 task对。
然后他会根据我们确定好的channel数量去确定taskGroup的数量,例如 taskGroup的实际数量 = channel数/单个task的最大channel数。
再确定每个task的channel数量,每个task的channel数量 = channel数/ taskGroup的实际数量。
再把task对平均分配到这些taskGroup的队列里面去,启动taskGroup线程,从task队列中取出task对,启动reader线程,启动writer线程,两个线程通过channel管道进行数据传输速度限制。因为channel的数量可能小于task对的数量,channel不够时,其他task对就会等待,等在执行的task对执行完了,再运行。
例如:我们设定 6 channel,factor = 2,那么总task对的数量就是 6*2+1 = 13,有13对reader和writer,我们设置taskGroup的channel最大数量为5,那么taskGroup的数量就是 6/5=2,每个taskGroup有 3个channel,1个taskGroup有6个task对,一个taskGroup有7个task对。
二、全局core配置和每个job的配置
core.json
"entry":
"jvm": "-Xms1G -Xmx1G",
"environment":
,
"common":
"column":
"datetimeFormat": "yyyy-MM-dd HH:mm:ss",## 这些都是时间格式化参数,用来做时间格式化的,这些不用管
"timeFormat": "HH:mm:ss",
"dateFormat": "yyyy-MM-dd",
"extraFormats":["yyyyMMdd"],
"timeZone": "GMT+8",
"encoding": "utf-8"
,
"core":
"dataXServer":
"address": "http://localhost:7001/api",
"timeout": 10000,
"reportDataxLog": false,
"reportPerfLog": false
,
"transport":
"channel":
"class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",#指定用哪个channel,目前只有MemmoryChannel可以用
"speed":
"byte": -1, # 当设置成 -1的时候表示,不支持byte限速模式,如果要使用则必须让此参数>0
"record": -1 # 当设置成 -1的时候表示,不支持record限速模式,如果要使用则必须让此参数>0
,
"flowControlInterval": 20, # 20ms,表示当现在的速度比预期速度快了20ms就要调整速度
"capacity": 512, # channel的阻塞队列最大record数
"byteCapacity": 67108864 # channel的阻塞队列最大byte数
,
"exchanger":
"class": "com.alibaba.datax.core.plugin.BufferedRecordExchanger", # buffer的Class
"bufferSize": 32 # buffer的大小,每次都是一个buffer一个buffer的往阻塞队列里面推数据的
,
"container":
"job":
"reportInterval": 10000
,
"taskGroup":
"channel": 5 # 每个taskGroup的最大channel数
,
"trace":
"enable": "false"
,
"statistics": # 统计类,用于输出统计结果的,也一般不用管
"collector":
"plugin":
"taskClass": "com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector",
"maxDirtyNumber": 10
job.json
"job":
"content": [
"reader":
"name": "mysqlreader", #设置reader名称
"parameter":
"column": ["id","machine_id", "devname", "shop_id", "shop_name", "province", "city", "city_level", "region", "agent_id", "agent_name", "second_agent_id", "second_agent_name", "shop_type", "sell_date"], # 插入那些字段
"connection": [
"jdbcUrl": ["jdbc:mysql://47.112.238.105:8003/data_recommend?useUnicode=true&characterEncoding=UTF-8"],
"table": ["test_datax"] # 插入哪些表
],
"username": "test_user",
"password": "Vi5P$1oX4j%",
"splitPk":"id", #用于切分任务的主键
"splitFactor":5 #切分task的factor
"fetchSize":1024 #jdbc的fetchSize参数,一般都需要设置,如果任务切分不合理,读取了大表容易内存溢出
,
"writer":
"name": "clickhousewriter", #设置writer名称
"parameter":
"username": "default",
"password": "bbkeebbk123",
"column": ["id","machine_id", "devname", "shop_id", "shop_name", "province", "city", "city_level", "region", "agent_id", "agent_name", "second_agent_id", "second_agent_name", "shop_type", "sell_date"],
"connection": [
"jdbcUrl": ["jdbc:clickhouse://172.28.199.146:8123/bbk"],
"table": ["test_datax"]
],
"preSql": [],
"postSql": [],
"batchSize": 65536,
"batchByteSize": 134217728,
"dryRun": false,
"writeMode": "insert"
],
"setting":
"speed":
"channel":"2"
三、rdbms通过设置主键来切分
mysql的reader和clickhouse的reader都是基于rdbmsUtils来执行的,主键只支持两种类型,一种是整型,一种是String类型(目前只支持asii码,别的不支持)
1、整型,会去获得其最大最小值,然后等分成 channel * splitFactor的个数,再补一个 就是 主键为空的情况,也就是 channel * splitFactor+1个
2、字符串类型,先去获取其字符串的最大值和最小值,然后将最大值最小值,转换为128进制的bigInt,再将bigInt切分成多个bigInt数字,再把128进制的bigInt转换为字符串,相当于将这个字符串等分,最后得到的也是 channel * splitFactor+1个task对
四、task,task对个数,taskGroup,taskGroup的channel分配和计算
1、我们手动设置needChannel和factor,factor默认是5
2、task对的个数 = needChannel * splitFactor+ 1
3、一个reader对应一个writer
4、core.container.taskGroup.channel = 5 意味着,一个taskGroup应该有5个channel
5、程序会根据task的个数算出需要多少个taskGroup,再根据taskGroup算出每个taskGroup里面需要有多少个channel。
例如:
我设置了6个channel,factor 为 2,那么我就会生成 14个task,其中7对reader和writer,一个reader和writer共用一个channel。
1个taskGroup是5个channel,那么6个channel就需要2个taskGroup,每个taskGroup平均分配3个channel。
五、线程的对应关系
一个jobContainer线程,多个taskGroup线程,每个taskGroup线程里面又会启动channel数量这么多的writer和reader线程。
六、数据的传输
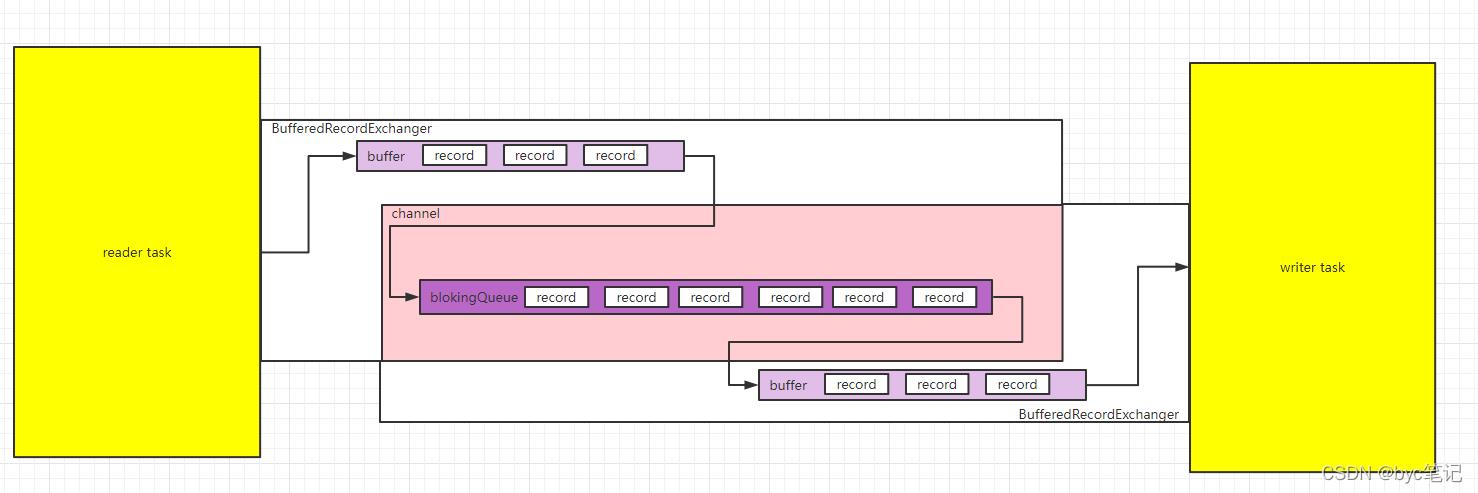
reader参数:fetchSize,这个参数会决定让jdbc从数据库取数据的数据每次只取fetchSize个数据,当result.next消费完了,再继续fetch下一个批次
writer参数:batchSize和batchByteSize,batchSize决定了一个批次只batchInsert这么多条数据,或者batchInsert的数据量>batchByteSize的时候就insert,决定了一次insert的数据量
一个task对,reader里面有一个BufferedRecordExchanger,writer里面有一个BufferedRecordExchanger,这两个BufferedRecordExchanger共用一个MemmeryChannel,MemeryChannel里面是阻塞队列,buffer是普通的ArrayList。
buffer的参数:
bufferSize = core.transport.exchanger.bufferSize 最大记录数,默认是32个
channel的参数:
channelByteCapacity = core.transport.channel.byteCapacity 最大字节数,默认是67108864,64k
channelSize = core.transport.channel.capacity 最大记录数,默认是512个
交互:
reader先读数据,往buffer里面放,当buffer满了,或者buffer的字节数>channelByteCapacity ,就把buffer的数据刷到channel里面去,如果channel的有数据了,那么就会唤醒writertask去消费,当channel满了,则reader休息。
writer线程每次都会把他自己的buffer填满,然后去插入数据,满batchSize或者batchByteSize就插入一次,满batchSize或者batchByteSize就插入一次,当阻塞队列的数据被消费了,就又会通知reader channel不为空,可以生产数据,唤醒reader线程,如果channel为空,则writer休息。如此循环往复
七、数据速度控制和channel数量的指定
datax里面有3种限速模式:
byte限制模式:
globalLimitedByteSpeed = job.setting.speed.byte 总的byte限制
channelLimitedByteSpeed = core.transport.channel.speed.byte 每个channel的byte限制
needChannelNumberByByte = globalLimitedByteSpeed / channelLimitedByteSpeed
在这个模式下,我们手动指定的channel不生效,通过needChannelNumberByByte 来计算出需要的channel数,如果设置了这个globalLimitedByteSpeed ,则必须设置 channelLimitedByteSpeed ,不然会异常
record限制模式:
globalLimitedRecordSpeed = job.setting.speed.record 总的record限制
channelLimitedRecordSpeed = job.setting.speed.record 每个channel的record的限制
needChannelNumberByRecord = globalLimitedRecordSpeed / channelLimitedRecordSpeed
在这个模式下,我们手动指定的channel不生效,通过needChannelNumberByByte 来计算出需要的channel数,如果设置了job.setting.speed.record则channelLimitedRecordSpeed则必须设置,不然会异常
如果 byte模式和record都设置了,那么channel就会取里面的最小值,
channel模式:
如果前面两个都没有设置,并且手动指定了 job.setting.speed.channel,那么channel模式生效,channel数 = job.setting.speed.channel,channel模式不限速
byte限速实现原理:
如果速度太快则需要限速,如果速度慢则不管
push某次buffer的数据前,获取当前已经push的总数据量和等待时间,speed = pushByte / watiTime ,得到当前的速度,如果速度 > 一个阈值core.transport.channel.flowControlInterval,那么就要去调整速度,通过reader线程休眠几秒来降低,推送速度。
休眠的秒数 = (上一次push时间 - 这次push的时间) * speed / 应该的speed - (上一次push时间 - 这次push的时间)
而record限速同理,如果两个模式都配置了,则取休眠时间的最大值。
休眠一下再继续推数据,直到速度和预期速度一样
DataX 原理解析和性能优化
datax简介
datax是阿里开源的用于异构数据源之间的同步工具,由于其精巧的设计和抽象,数据同步效率极高,在很多公司数据部门都有广泛的使用。本司基于datax在阿里云普通版的rds服务器上实现了通过公网,从阿里云杭州到美国西部俄勒冈aws emr集群峰值30M以上带宽的传输效率。全量传输上亿条记录、大小30G的数据,最快不到30分钟。要知道如果拉跨洋专线的话,1M带宽每个月至少需要1千大洋呢。走公网照样能达到类似的稳定性,本文通过原理设计来阐述我们是如何基于datax做到的。
datax工作原理
在讲解datax原理之前,需要明确一些概念:
-
Job: Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到hive的一个表的特定分区。
-
Task: Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,若干个任务并发执行。或者将一个大表按照id拆分成1024个分片,若干个分片任务并发执行。
-
TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroup。
-
JobContainer: Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。
-
TaskGroupContainer: TaskGroup执行器,负责执行一组Task的工作单元。
job和task是datax两种维度的抽象,后面源码分析中还会涉及到。
datax的处理过程可描述为:
-
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
-
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
-
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
-
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
-
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
上述流程可图像化描述为:

其中Channel是连接Reader和Writer的数据交换通道,所有的数据都会经由Channel进行传输,一个channel代表一个并发传输通道,通过该通道实现传输速率控制。接下来我们通过源码的角度,在抽取其核心逻辑,以mysql到hdfs的传输为例分析其工作流程。通过分析源码将会有以下几点收获:
-
datax 工作流程
-
datax 插件机制
-
datax 同步实现
datax源码分析
datax 工作流程
public class Engine
private static final Logger LOG = LoggerFactory.getLogger(Engine.class);
private static String RUNTIME_MODE;
public void start(Configuration allConf)
boolean isJob = !("taskGroup".equalsIgnoreCase(allConf.getString(CoreConstant.DATAX_CORE_CONTAINER_MODEL)));
//JobContainer会在schedule后再行进行设置和调整值
int channelNumber =0;
AbstractContainer container;
long instanceId;
int taskGroupId = -1;
if (isJob)
allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, RUNTIME_MODE);
container = new JobContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);
else
container = new TaskGroupContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
taskGroupId = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);
channelNumber = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);
container.start();
job实例运行在jobContainer容器中,它是所有任务的master,负责初始化、拆分、调度、运行、回收、监控和汇报,但它并不做实际的数据同步操作
public class JobContainer extends AbstractContainer
private static final Logger LOG = LoggerFactory
.getLogger(JobContainer.class);
public JobContainer(Configuration configuration)
super(configuration);
/**
* jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、scheduler以及destroy和statistics
*/
@Override
public void start()
LOG.info("DataX jobContainer starts job.");
try
userConf = configuration.clone();
this.init();
this.prepare();
this.totalStage = this.split();
this.schedule();
catch (Throwable e)
Communication communication = super.getContainerCommunicator().collect();
// 汇报前的状态,不需要手动进行设置
// communication.setState(State.FAILED);
communication.setThrowable(e);
communication.setTimestamp(this.endTimeStamp);
Communication tempComm = new Communication();
tempComm.setTimestamp(this.startTransferTimeStamp);
Communication reportCommunication = CommunicationTool.getReportCommunication(communication, tempComm, this.totalStage);
super.getContainerCommunicator().report(reportCommunication);
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
/**
* reader和writer的初始化
*/
private void init()
Thread.currentThread().setName("job-" + this.jobId);
JobPluginCollector jobPluginCollector = new DefaultJobPluginCollector(
this.getContainerCommunicator());
//必须先Reader ,后Writer
this.jobReader = this.initJobReader(jobPluginCollector);
this.jobWriter = this.initJobWriter(jobPluginCollector);
/**
*schedule首先完成的工作是把上一步reader和writer split的结果整合到具体taskGroupContainer中,
* 同时不同的执行模式调用不同的调度策略,将所有任务调度起来
*/
private void schedule()
/**
* 这里的全局speed和每个channel的速度设置为B/s
*/
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务。
会考虑 task 中对资源负载作的 load 标识进行更均衡的作业分配操作。
*/
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
LOG.info("Scheduler starts [] taskGroups.", taskGroupConfigs.size());
AbstractScheduler scheduler;
try
scheduler = initStandaloneScheduler(this.configuration);
this.startTransferTimeStamp = System.currentTimeMillis();
scheduler.schedule(taskGroupConfigs);
this.endTransferTimeStamp = System.currentTimeMillis();
catch (Exception e)
LOG.error("运行scheduler出错.");
this.endTransferTimeStamp = System.currentTimeMillis();
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
private AbstractScheduler initStandaloneScheduler(Configuration configuration)
AbstractContainerCommunicator containerCommunicator = new StandAloneJobContainerCommunicator(configuration);
super.setContainerCommunicator(containerCommunicator);
return new StandAloneScheduler(containerCommunicator);
public abstract class AbstractScheduler
private static final Logger LOG = LoggerFactory
.getLogger(AbstractScheduler.class);
public void schedule(List<Configuration> configurations)
/**
* 给 taskGroupContainer 的 Communication 注册
*/
this.containerCommunicator.registerCommunication(configurations);
int totalTasks = calculateTaskCount(configurations);
startAllTaskGroup(configurations);
try
while (true)
Communication nowJobContainerCommunication = this.containerCommunicator.collect();
//汇报周期
long now = System.currentTimeMillis();
if (now - lastReportTimeStamp > jobReportIntervalInMillSec)
Communication reportCommunication = CommunicationTool
.getReportCommunication(nowJobContainerCommunication, lastJobContainerCommunication, totalTasks);
this.containerCommunicator.report(reportCommunication);
if (nowJobContainerCommunication.getState() == State.SUCCEEDED)
LOG.info("Scheduler accomplished all tasks.");
break;
if (nowJobContainerCommunication.getState() == State.FAILED)
dealFailedStat(this.containerCommunicator, nowJobContainerCommunication.getThrowable());
Thread.sleep(jobSleepIntervalInMillSec);
catch (InterruptedException e)
// 以 failed 状态退出
LOG.error("捕获到InterruptedException异常!", e);
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
@Override
public void startAllTaskGroup(List<Configuration> configurations)
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations)
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
this.taskGroupContainerExecutorService.shutdown();
@Override
public void dealFailedStat(AbstractContainerCommunicator frameworkCollector, Throwable throwable)
this.taskGroupContainerExecutorService.shutdownNow();
public class TaskGroupContainer extends AbstractContainer
private static final Logger LOG = LoggerFactory
.getLogger(TaskGroupContainer.class);
@Override
public void start()
try
while (true)
//1.判断task状态
boolean failedOrKilled = false;
Map<Integer, Communication> communicationMap = containerCommunicator.getCommunicationMap();
for(Map.Entry<Integer, Communication> entry : communicationMap.entrySet())
Integer taskId = entry.getKey();
Communication taskCommunication = entry.getValue();
if(!taskCommunication.isFinished())
continue;
TaskExecutor taskExecutor = removeTask(runTasks, taskId);
if(taskCommunication.getState() == State.FAILED)
failedOrKilled = true;
break;
else if(taskCommunication.getState() == State.SUCCEEDED)
Long taskStartTime = taskStartTimeMap.get(taskId);
if(taskStartTime != null)
Long usedTime = System.currentTimeMillis() - taskStartTime;
LOG.info("taskGroup[] taskId[] is successed, used[]ms",
this.taskGroupId, taskId, usedTime);
//usedTime*1000*1000
taskStartTimeMap.remove(taskId);
taskConfigMap.remove(taskId);
// 2.发现该taskGroup下taskExecutor的总状态失败则汇报错误
if (failedOrKilled)
lastTaskGroupContainerCommunication = reportTaskGroupCommunication(
lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_RUNTIME_ERROR, lastTaskGroupContainerCommunication.getThrowable());
//3.有任务未执行,且正在运行的任务数小于最大通道限制
Iterator<Configuration> iterator = taskQueue.iterator();
while(iterator.hasNext() && runTasks.size() < channelNumber)
Configuration taskConfig = iterator.next();
Integer taskId = taskConfig.getInt(CoreConstant.TASK_ID);
Configuration taskConfigForRun =taskConfig.clone()
TaskExecutor taskExecutor = new TaskExecutor(taskConfigForRun);
taskStartTimeMap.put(taskId, System.currentTimeMillis());
taskExecutor.doStart();
terator.remove();
runTasks.add(taskExecutor);
LOG.info("taskGroup[] taskId[] is started",
this.taskGroupId, taskId);
//4.任务列表为空,executor已结束, 搜集状态为success--->成功
if (taskQueue.isEmpty() && isAllTaskDone(runTasks) && containerCommunicator.collectState() == State.SUCCEEDED)
// 成功的情况下,也需要汇报一次。否则在任务结束非常快的情况下,采集的信息将会不准确
lastTaskGroupContainerCommunication = reportTaskGroupCommunication(
lastTaskGroupContainerCommunication, taskCountInThisTaskGroup);
LOG.info("taskGroup[] completed it's tasks.", this.taskGroupId);
break;
catch (Throwable e)
Communication nowTaskGroupContainerCommunication = this.containerCommunicator.collect();
if (nowTaskGroupContainerCommunication.getThrowable() == null)
nowTaskGroupContainerCommunication.setThrowable(e);
nowTaskGroupContainerCommunication.setState(State.FAILED);
this.containerCommunicator.report(nowTaskGroupContainerCommunication);
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
/**
* TaskExecutor是一个完整task的执行器
* 其中包括1:1的reader和writer
*/
class TaskExecutor
private Thread readerThread;
private Thread writerThread;
private ReaderRunner readerRunner;
private WriterRunner writerRunner;
public TaskExecutor(Configuration taskConf, int attemptCount)
writerRunner = (WriterRunner) generateRunner(PluginType.WRITER);
//生成writerThread
this.writerThread = new Thread(writerRunner,
String.format("%d-%d-%d-writer",
jobId, taskGroupId, this.taskId));
//生成readerThread
readerRunner = (ReaderRunner) generateRunner(PluginType.READER,transformerInfoExecs);
this.readerThread = new Thread(readerRunner,
String.format("%d-%d-%d-reader",
jobId, taskGroupId, this.taskId));
public void doStart()
this.writerThread.start();
// reader没有起来,writer不可能结束
if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED)
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
this.readerThread.start();
// 这里reader可能很快结束
if (!this.readerThread.isAlive() && this.taskCommunication.getState() == State.FAILED)
// 这里有可能出现Reader线上启动即挂情况 对于这类情况 需要立刻抛出异常
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
从上面总体流程中可以看到JobContainer通过线程池调度起所有的TaskGroupContainer,然后轮训TaskGroupContainer的运行状态。每个TaskGroupContainer则是根据分配的chanel并发数量依次执行分配的Task实例。
插件机制
在工作流程中的init步骤,我们看到的jobReader和jobWriter的实现就是通过插件动态生成的。jobReader和jobWriter就对应datax中的Job概念模型。而在TaskExecutor中初始化的readerRunner和writerRunner对应的是Task模型。通过插件datax插件机制支持了数十种不同的数据源之间的读写同步,同时也很方便的支持新的数据源接入。
Job初始化过程
public class JobContainer extends AbstractContainer
//reader job的初始化,返回Reader.Job
private Reader.Job initJobReader(
JobPluginCollector jobPluginCollector)
this.readerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME);
Reader.Job jobReader = (Reader.Job) LoadUtil.loadJobPlugin(
PluginType.READER, this.readerPluginName);
// 设置reader的jobConfig
jobReader.setPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_READER_PARAMETER));
// 设置reader的readerConfig
jobReader.setPeerPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_WRITER_PARAMETER));
jobReader.setJobPluginCollector(jobPluginCollector);
jobReader.init();
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobReader;
插件加载器,大体上分reader、transformer(还未实现)和writer三中插件类型,
reader和writer在执行时又可能出现Job和Task两种运行时(加载的类不同)
public class LoadUtil
//加载JobPlugin,reader、writer都可能要加载
public static AbstractJobPlugin loadJobPlugin(PluginType pluginType,
String pluginName)
Class<? extends AbstractPlugin> clazz = LoadUtil.loadPluginClass(
pluginType, pluginName, ContainerType.Job);
try
AbstractJobPlugin jobPlugin = (AbstractJobPlugin) clazz
.newInstance();
jobPlugin.setPluginConf(getPluginConf(pluginType, pluginName));
return jobPlugin;
catch (Exception e)
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
String.format("DataX找到plugin[%s]的Job配置.",
pluginName), e);
//反射出具体plugin实例
private static synchronized Class<? extends AbstractPlugin> loadPluginClass(
PluginType pluginType, String pluginName,
ContainerType pluginRunType)
Configuration pluginConf = getPluginConf(pluginType, pluginName);
JarLoader jarLoader = LoadUtil.getJarLoader(pluginType, pluginName);
try
return (Class<? extends AbstractPlugin>) jarLoader
.loadClass(pluginConf.getString("class") + "$"
+ pluginRunType.value());
catch (Exception e)
throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR, e);
public static synchronized JarLoader getJarLoader(PluginType pluginType,
String pluginName)
Configuration pluginConf = getPluginConf(pluginType, pluginName);
JarLoader jarLoader = jarLoaderCenter.get(generatePluginKey(pluginType,
pluginName));
if (null == jarLoader)
String pluginPath = pluginConf.getString("path");
if (StringUtils.isBlank(pluginPath))
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
String.format(
"%s插件[%s]路径非法!",
pluginType, pluginName));
jarLoader = new JarLoader(new String[]pluginPath);
jarLoaderCenter.put(generatePluginKey(pluginType, pluginName),
jarLoader);
return jarLoader;
//提供Jar隔离的加载机制,会把传入的路径、及其子路径、以及路径中的jar文件加入到class path。
public class JarLoader extends URLClassLoader
public JarLoader(String[] paths)
this(paths, JarLoader.class.getClassLoader());
public JarLoader(String[] paths, ClassLoader parent)
super(getURLs(paths), parent);
private static URL[] getURLs(String[] paths)
Validate.isTrue(null != paths && 0 != paths.length,
"jar包路径不能为空.");
List<String> dirs = new ArrayList<String>();
for (String path : paths)
dirs.add(path);
JarLoader.collectDirs(path, dirs);
List<URL> urls = new ArrayList<URL>();
for (String path : dirs)
urls.addAll(doGetURLs(path));
return urls.toArray(new URL[0]);
private static void collectDirs(String path, List<String> collector)
if (null == path || StringUtils.isBlank(path))
return;
File current = new File(path);
if (!current.exists() || !current.isDirectory())
return;
for (File child : current.listFiles())
if (!child.isDirectory())
continue;
collector.add(child.getAbsolutePath());
collectDirs(child.getAbsolutePath(), collector);
Task 初始化过程
class TaskExecutor
private AbstractRunner generateRunner(PluginType pluginType)
return generateRunner(pluginType, null);
private AbstractRunner generateRunner(PluginType pluginType, List<TransformerExecution> transformerInfoExecs)
AbstractRunner newRunner = null;
TaskPluginCollector pluginCollector;
switch (pluginType)
case READER:
newRunner = LoadUtil.loadPluginRunner(pluginType,
this.taskConfig.getString(CoreConstant.JOB_READER_NAME));
newRunner.setJobConf(this.taskConfig.getConfiguration(
CoreConstant.JOB_READER_PARAMETER));
pluginCollector = ClassUtil.instantiate(
taskCollectorClass, AbstractTaskPluginCollector.class,
configuration, this.taskCommunication,
PluginType.READER);
RecordSender recordSender;
if (transformerInfoExecs != null && transformerInfoExecs.size() > 0)
recordSender = new BufferedRecordTransformerExchanger(taskGroupId, this.taskId, this.channel,this.taskCommunication ,pluginCollector, transformerInfoExecs);
else
recordSender = new BufferedRecordExchanger(this.channel, pluginCollector);
((ReaderRunner) newRunner).setRecordSender(recordSender);
/**
* 设置taskPlugin的collector,用来处理脏数据和job/task通信
*/
newRunner.setTaskPluginCollector(pluginCollector);
break;
case WRITER:
newRunner = LoadUtil.loadPluginRunner(pluginType,
this.taskConfig.getString(CoreConstant.JOB_WRITER_NAME));
newRunner.setJobConf(this.taskConfig
.getConfiguration(CoreConstant.JOB_WRITER_PARAMETER));
pluginCollector = ClassUtil.instantiate(
taskCollectorClass, AbstractTaskPluginCollector.class,
configuration, this.taskCommunication,
PluginType.WRITER);
((WriterRunner) newRunner).setRecordReceiver(new BufferedRecordExchanger(
this.channel, pluginCollector));
/**
* 设置taskPlugin的collector,用来处理脏数据和job/task通信
*/
newRunner.setTaskPluginCollector(pluginCollector);
break;
default:
throw DataXException.asDataXException(FrameworkErrorCode.ARGUMENT_ERROR, "Cant generateRunner for:" + pluginType);
newRunner.setTaskGroupId(taskGroupId);
newRunner.setTaskId(this.taskId);
newRunner.setRunnerCommunication(this.taskCommunication);
return newRunner;
public class LoadUtil
/**
* 根据插件类型、名字和执行时taskGroupId加载对应运行器
*
* @param pluginType
* @param pluginName
* @return
*/
public static AbstractRunner loadPluginRunner(PluginType pluginType, String pluginName)
AbstractTaskPlugin taskPlugin = LoadUtil.loadTaskPlugin(pluginType,
pluginName);
switch (pluginType)
case READER:
return new ReaderRunner(taskPlugin);
case WRITER:
return new WriterRunner(taskPlugin);
default:
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
String.format("插件[%s]的类型必须是[reader]或[writer]!",
pluginName));
同步实现
这部分就是经过split后的具体的Task的执行逻辑。Task的划分逻辑如下:
public class JobContainer extends AbstractContainer
private static final Logger LOG = LoggerFactory
.getLogger(JobContainer.class);
/**
* 执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,
* 达到切分后数目相等,才能满足1:1的通道模型,所以这里可以将reader和writer的配置整合到一起,
* 然后,为避免顺序给读写端带来长尾影响,将整合的结果shuffler掉
*/
private int split()
this.adjustChannelNumber();
if (this.needChannelNumber <= 0)
this.needChannelNumber = 1;
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSFORMER);
LOG.debug("transformer configuration: "+ JSON.toJSONString(transformerList));
/**
* 输入是reader和writer的parameter list,输出是content下面元素的list
*/
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);
LOG.debug("contentConfig configuration: "+ JSON.toJSONString(contentConfig));
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);
return contentConfig.size();
每个Task都执行相同的逻辑和流程,下面以读mysql和写hdfs为例,展示其读写过程。
//单个slice的reader执行调用
public class ReaderRunner extends AbstractRunner implements Runnable
@Override
public void run()
Reader.Task taskReader = (Reader.Task) this.getPlugin();
taskReader.init();
taskReader.prepare();
taskReader.startRead(recordSender);
recordSender.terminate();
public class MysqlReader extends Reader
@Override
public void startRead(RecordSender recordSender)
int fetchSize = this.readerSliceConfig.getInt(Constant.FETCH_SIZE);
this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,
super.getTaskPluginCollector(), fetchSize);
public class CommonRdbmsReader
public static class Task
private static final Logger LOG = LoggerFactory
.getLogger(Task.class);
public void startRead(Configuration readerSliceConfig,
RecordSender recordSender,
TaskPluginCollector taskPluginCollector, int fetchSize)
String querySql = readerSliceConfig.getString(Key.QUERY_SQL);
String table = readerSliceConfig.getString(Key.TABLE);
PerfTrace.getInstance().addTaskDetails(taskId, table + "," + basicMsg);
LOG.info("Begin to read record by Sql: [\\n] .",
querySql, basicMsg);
Connection conn = DBUtil.getConnection(this.dataBaseType, jdbcUrl,
username, password);
int columnNumber = 0;
ResultSet rs = null;
try
rs = DBUtil.query(conn, querySql, fetchSize);
while (rs.next())
//将数据记录放入channel通道,writer从中获取写数据
this.transportOneRecord(recordSender, rs,
metaData, columnNumber, mandatoryEncoding, taskPluginCollector);
catch (Exception e)
throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);
finally
DBUtil.closeDBResources(null, conn);
//单个slice的writer执行调用
public class WriterRunner extends AbstractRunner implements Runnable
@Override
public void run()
Writer.Task taskWriter = (Writer.Task) this.getPlugin();
taskWriter.init();
taskWriter.prepare();
taskWriter.startWrite(recordReceiver);
public class HdfsWriter extends Writer
public static class Task extends Writer.Task
private static final Logger LOG = LoggerFactory.getLogger(Task.class);
@Override
public void startWrite(RecordReceiver lineReceiver)
LOG.info("begin do write...");
LOG.info(String.format("write to file : [%s]", this.fileName));
if(fileType.equalsIgnoreCase("TEXT"))
//写TEXT FILE
hdfsHelper.textFileStartWrite(lineReceiver,this.writerSliceConfig, this.fileName,
this.getTaskPluginCollector());
else if(fileType.equalsIgnoreCase("ORC"))
//写ORC FILE
hdfsHelper.orcFileStartWrite(lineReceiver,this.writerSliceConfig, this.fileName,
this.getTaskPluginCollector());
LOG.info("end do write");
public class HdfsHelper
public void textFileStartWrite(RecordReceiver lineReceiver, Configuration config, String fileName,TaskPluginCollector taskPluginCollector)
try
RecordWriter writer = outFormat.getRecordWriter(fileSystem, conf, outputPath.toString(), Reporter.NULL);
Record record = null;
while ((record = lineReceiver.getFromReader()) != null)
MutablePair<Text, Boolean> transportResult = transportOneRecord(record, fieldDelimiter, columns, taskPluginCollector);
if (!transportResult.getRight())
writer.write(NullWritable.get(),transportResult.getLeft());
writer.close(Reporter.NULL);
catch (Exception e)
String message = String.format("写文件文件[%s]时发生IO异常,请检查您的网络是否正常!", fileName);
LOG.error(message);
Path path = new Path(fileName);
deleteDir(path.getParent());
throw DataXException.asDataXException(HdfsWriterErrorCode.Write_FILE_IO_ERROR, e);
reader和writer通过BufferedRecordExchanger建立联系,在其内部实现了基于ArrayBlockingQueue的MemoryChannel。
public class BufferedRecordExchanger implements RecordSender, RecordReceiver
@Override
public void sendToWriter(Record record)
if(shutdown)
throw DataXException.asDataXException(CommonErrorCode.SHUT_DOWN_TASK, "");
Validate.notNull(record, "record不能为空.");
if (record.getMemorySize() > this.byteCapacity)
this.pluginCollector.collectDirtyRecord(record, new Exception(String.format("单条记录超过大小限制,当前限制为:%s", this.byteCapacity)));
return;
boolean isFull = (this.bufferIndex >= this.bufferSize || this.memoryBytes.get() + record.getMemorySize() > this.byteCapacity);
if (isFull)
flush();
this.buffer.add(record);
this.bufferIndex++;
memoryBytes.addAndGet(record.getMemorySize());
@Override
public void flush()
if(shutdown)
throw DataXException.asDataXException(CommonErrorCode.SHUT_DOWN_TASK, "");
this.channel.pushAll(this.buffer);
this.buffer.clear();
this.bufferIndex = 0;
this.memoryBytes.set(0);
@Override
public Record getFromReader()
if(shutdown)
throw DataXException.asDataXException(CommonErrorCode.SHUT_DOWN_TASK, "");
boolean isEmpty = (this.bufferIndex >= this.buffer.size());
if (isEmpty)
receive();
Record record = this.buffer.get(this.bufferIndex++);
if (record instanceof TerminateRecord)
record = null;
return record;
datax性能优化
通过datax原理和实现的理解,自然可以知道如何提升datax的同步效率。以mysql同步hdfs为例,自然最直接的方式就是提高mysql和hdfs的硬件性能如cpu、内存、IOPS、网络带宽等。当硬件资源受限的情况下,可以有如下几种办法:
-
将不同的集群划分到同一个网络或者区域内,减少跨网络的不稳定性,如将阿里云集群迁移到amazon集群,或者同一个amazon集群中不同区域划分到同一个子网络内。
-
对数据库按照主键划分。datax对单个表默认一个通道,如果指定拆分主键,将会大大提升同步并发数和吞吐量。
-
在cpu、内存以及mysql负载满足的情况下,提升通道并发数。通道并发数意味着更多的内存开销,jvm调优是重中之重。
-
当无法提升通道数量时,而且每个拆分依然很大的时候,可以考虑对每个拆分再次拆分。
-
设定合适的参数,如mysql超时等。
总结
本文通过原理介绍和源码分析,逐步理清datax的工作流程和实现原理,并结合实际经验给出几点优化建议。然而在实际中涉及到更多的分库分表和特大量级的表,数据库的承载压力也是一大考虑因素,否则遭到dba的吊打肯定会在所难免。尤其是我们涉及到跨大洋数据同步,网络的稳定性也是一大挑战,此时基于增量同步方案或许是更好的选择。
以上是关于datax的架构原理的主要内容,如果未能解决你的问题,请参考以下文章