G.711编码原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了G.711编码原理相关的知识,希望对你有一定的参考价值。
参考技术A 本文目的:
1、熟悉G711a/u两种格式的基本原理
2、熟悉两种压缩算法的实现步骤及提供源码实现
G.711是国际电信联盟ITU-T定制出来的一套语音压缩标准,它代表了对数PCM(logarithmic pulse-code modulation)抽样标准,是主流的波形声音编解码标准,主要用于电话。
G.711 标准下主要有两种压缩算法。
G.711将14bit(uLaw)或者13bit(aLaw)采样的PCM数据编码成8bit的数据流,播放的时候在将此8bit的数据还原成14bit或者13bit进行播放,不同于MPEG这种对于整体或者一段数据进行考虑再进行编解码的做法,G711是波形编解码算法,就是一个sample对应一个编码,所以压缩比固定为:
G.711是将语音模拟信号进行一种非线性量化, 详细的资料可以在ITU 上下到相关的spec 。下面主要列出一些性能参数:
G.711(PCM方式)
算法原理:
A-law的公式如下,一般采用A=87.6
画出图来则是如下图,用x表示输入的采样值,F(x)表示通过A-law变换后的采样值,y是对F(x)进行量化后的采样值。
由此可见
对应反量化公式(即上面函数的反函数):
G.711A输入的是13位(S16的高13位),这种格式是经过特别设计的,便于数字设备进行快速运算。
A-law如下表计算。
示例:
输入pcm数据为1234,二进制对应为(0000 0100 1101 0010)
二进制变换下排列组合方式(0 00001 0011 010010)
1、获取符号位最高位为0,取反,s=1
2、获取强度位00001,查表,编码制应该是eee=011
3、获取高位样本wxyz=0011
4、组合为10110011,逢偶数为取反为11100110,得到E6
使用在北美和日本,输入的是14位,编码算法就是查表,计算出:基础值+平均偏移值
μ-law的公式如下,μ取值一般为255
相应的μ-law的计算方法如下表
示例:
输入pcm数据为1234
1、取得范围值,查表得 +2014 to +991 in 16 intervals of 64
2、得到基础值为0xA0
3、得到间隔数为64
4、得到区间基本值2014
5、当前值1234和区间基本值差异2014-1234=780
6、偏移值=780/间隔数=780/64,取整得到12
7、输出为0xA0+12=0xAC
A-law和u-law画在同一个坐标轴中就能发现A-law在低强度信号下,精度要稍微高一些。
实际应用中,我们确实可以用浮点数计算的方式把F(x)结果计算出来,然后进行量化,但是这样一来计算量会比较大,实际上对于A-law(A=87.6时),是采用13折线近似的方式来计算的,而μ-law(μ=255时)则是15段折线近似的方式。
G711尽管是一种非常古老的话音编码算法,原理和计算也比较简单,但是其中用到的一些基本原理同样在其他编码算法中得到了应用,对其进行深入的了解有助于更好的理解其他的算法。
音视频 - 视频编码原理
目录
一部电影1080P,帧率25fps,时长2小时,文件大小 1920x1080x1.5x25x2x360 = 521.4G 数据量非常大,对存储和网络传输都有很大压力。因此视频压缩很有必要。
视频编码主要分为
熵编码、预测(帧内、帧间)、DCT变换和量化。
每一帧图像,划分一个个块(宏块)进行编码,大小一般是16x16(h264,vp8),32x32(h265,vp9),64x64(hz65,vp9,av1)
图像的冗余
- 空间冗余:相邻块很多时候有明显的相似性;
- 时间冗余:前后帧变化比较小,相似性高;
- 视觉冗余:人眼对图像的高频信息敏感度小于低频信息,去除高频信息有的时候差别不大;
- 信息熵冗余:压缩算法
熵编码
主要去除信息熵冗余。
如:字符串编码 aaaaabbbbbccccc(15个字节)压缩成5a5b5c(6个字节) 节省9字节空间
图像也是一样,图像出现较多连续相同的字符,扫描出像素值,最好是很小的像素,比如0 像素,因为0在二进制中只占1位即可(指数哥伦布编码)。
如何做到像素值有很多0呢?
先减少图像块的空间冗余和时间冗余,在编码的时候进行帧内预测和帧间预测。
帧内预测
- 在当前编码图像内部已经编码完成的块中找到与将要编码的块相邻的块,一般是即将编码的左边块,上边块左上角块和右上角块。
- 将这些块与编码块相邻的像素经过多种不同的算法得到多个不同的预测块。
- 然后再用编码块减去每个预测块得到一个个残差块。
- 最后取这些算法得到的残差块中像素的绝对值加起来最小的块为预测块,得到的这个预测块的算法称为帧内预测模式。
- 残差块中像素的绝对值之和最小,这个残差块的像素经过扫描之后的“ 像素串”的值比直接扫描编码块的像素串的像素值更接近0
帧间预测
- 在前面已经编码完成的图像中,循环遍历每一个块,将它作为预测块。用当前的编码块与这个块做差值,得到残差块,取残差块中像素值的绝对值加起来最小的块为预测块。
帧间预测的专业术语
- 预测块所在的已经编码的图像称为参考帧
- 预测块在参考帧中的坐标值(X0,Y1)与编码块在编码帧中的坐标值(X1,Y1)的差值(X0-X1,Y0-Y1)称为运动矢量。
- 在参考帧中去寻找预测块的过程称之为运动搜索。
- 编码的过程中真正的运动搜索不是一个个块去遍历寻找的,而是有快速的运动搜索算法。
总之通过预测得到的残差块的像素值比编码块的像素值,去除了大部分空间冗余和时间冗余,这样得到的像素值更小
希望得到出现连续的0像素,如何处理呢?
DCT变换和量化
将残差块变换到频域,分离图像的高频信息和低频信息,需要将图像块变换到频域。常用的是DCT变换,又叫离散余弦变换。
变换的每一个像素值我们称为系数,变换块左上角的系数是图像的低频信息,其余的是图像的高频信息。(低频信息表示图像的轮廓,高频信息表示图像的细节)
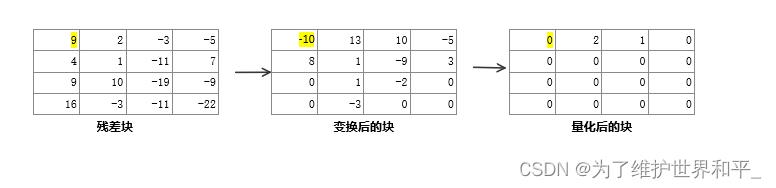
DCT后低频与高频信息分开,再做之字扫描,前面的就是低频信息,后面就是高频信息。由于人眼对高频信息不太敏感,用过一种手段去除掉大部分高频信息,将大部分高频信息置为0
将变换块的系数都同时除以一个值QStep(量化步长),得到的结果就是量化后的系数。QStep越大,得到量化后的系数就会越小。高频信息数值相比低频信息系数值更小,量化后更容易变成0。
编码器比较
| 编码标准 | 块大小 | 帧内编码 | 帧间编码 | 变换 | 熵编码 | 滤波和后处理 |
| H264 | 最大16x16 可划分成8x16 16x8 8x8 4x8 8x4 4x4 | 8个方向模式,planar+DC模式 | 中值MVP | DCT 4x4/8x8 | CAVLC,CABAC | 去块滤波 |
| H265 | 最大支持64X64,四叉树划分 | 33个方向模式,planar+DC模式 | Merge模式AMVP模式 | DCT 4x4/8x8/16x16/32x32 DST 4X4 | CABAC | 去块滤波 SAO滤波 |
| AV1 | 最大支持128x128,四叉树划分 | 56个方向模式+3个平滑模式+递归FilterIntra模式+色度CFL模式+色度板模式+帧内块拷贝模式 | OBMC+扭曲运动补偿+高级复合预测+复合帧内预测 | 4x4 - 64x64正方形+1:2/2:1 + 1:4/4:1矩形DCT/ADST/flipADST/IDTX | 多符号算数编码 | 去块滤波 CDEF LR滤波 Frame超分 |
标准越新,最大编码块越大,划分方式越多,编码模式越多,压缩效率越高,编码耗时越大。
清晰度和耗时对比
| 编码器 | H264 | H265 | AV1 |
| PSNR | 29.3 | 31.2 | 32 |
| 速度 | 25fps | 8fps | 3fps |
相同码率下,AV1清晰度稍好于H265,而H264最差,但编码耗时则相反。
在机器性能比较差的机器上编码,最好选择H264和VP8。如果在新机器上,可以考虑H265,VP9 AV1。
以上是关于G.711编码原理的主要内容,如果未能解决你的问题,请参考以下文章