大数据的一生一世——谈数据冷热分离技术
Posted Mr-Bruce
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据的一生一世——谈数据冷热分离技术相关的知识,希望对你有一定的参考价值。
前言
对于一个软件系统,无论其业务逻辑复杂到何种程度,最终都将体现到一条(批)数据的CRUD操作上,即创建、查询、更新与删除。正如人类面临生死的轮回,数据亦是如此。一条数据从被创建出来开始,随着时间的逝去,其价值逐渐变小,最终被删除。尽管在有些场景下,我们对客户承诺其数据会被永久保存,但这也是相对而言的。
数据的存在价值,在于其被使用的程度,即被查询或更新的频率。在不同的业务系统中,人们对处于不同时期的数据有着不同的使用需求。比如,在网络流量行为分析系统中,客户会对最近一个月公司发生的安全事件和网络访问情况感兴趣,而很少关注几个月前的数据;在电商订单系统中,用户会经常访问最近三个月的订单,而更久远的数据则几乎不会去看。针对这样一些业务场景,我们将数据按照时间划分为三个阶段:Hot、Warm、Cold。Hot和Cold的特性分别如下所示,而Warm处于二者之间,通常会被合并到Hot或Cold中,从而减少系统的复杂度,本文也不准备将其单独拿出来讨论。
- Hot(热数据)
- 被频繁查询或更新
- 对访问的响应时间要求很高,通常在10毫秒以内
- Cold(冷数据)
- 不允许更新,偶尔被查询
- 对访问的响应时间要求不高,通常在1~10秒内都可以接受

区分冷热数据的根本目的,在于控制成本。为什么这么说?因为通常情况下,为了支持热数据的操作特性,需要有较好的硬件配置,比如高性能CPU、大内存、SSD硬盘等等。随着时间的推移,系统里会积累越来越多的历史数据,如果依然采用高配置机器来存放这些使用频率非常低的数据,势必会带来非常高的成本。当然,如果数据量很小或者不计成本,那完全不需要考虑冷热区分,采用一个单体系统就可以应对所有事情了,比如mysql。
目前比较常见的冷热分离方案是将冷热数据分离到两套不同的系统,这两套系统拥有不同的存储特性、访问方式等,从而在保证热数据访问性能的同时,将冷数据的成本降低下来。而随着冷热分离方案的普及,很多框架也开始考虑类似的事情,尝试在自己的体系下支持将数据进行冷热分离,避免两套系统带来的复杂性。我们姑且将这两种方案分别称为“冷热分离异构系统”和“冷热分离同构系统”,本文将分别介绍几个相关的具体案例。
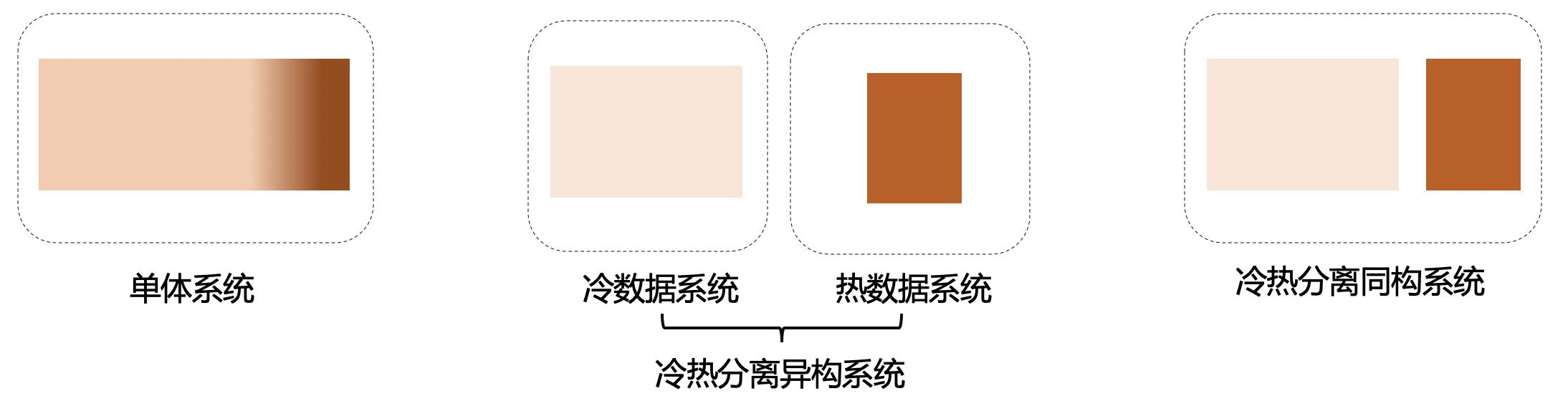
冷热分离异构系统
相比单体系统而言,将冷热数据分离到两个系统中,必然会带来整体的复杂性,需要在性能、成本、复杂度等因素之间做的一个权衡。实践中,通常需要结合具体的业务,考虑下面几件事:
- 冷热数据系统的选型
- 确定冷热数据分割线
- 如何进行数据的迁移
- 如何应对跨系统的查询
在系统选型上,对于热数据系统,需要重点考虑读写的性能问题,诸如MySQL、Elasticsearch等会成为首选;而对于冷数据系统,则需要重点关注低成本存储问题,通常会选择存储在HDFS或云对象存储(比如AWS S3)中,再选择一个相应的查询系统。冷热数据是按照时间推移来区分的,因此必然要敲定一个时间分割线,即多久以内的数据为热数据,这个值通常会结合业务与历史访问情况来综合考量。对于超过时间线的数据,会被迁移到冷数据中,迁移过程需要确保两点:不能对热数据系统产生性能影响、不能影响数据查询。数据分离后,不可避免的会出现某个查询在时间上跨到两个系统里面,需要进行查询结果的合并,对于统计类查询就可能会出现一定的误差,需要在业务层面有所妥协。
这里介绍两个冷热分离的实践方案,供大家参考。
网络行为数据分析系统
业务背景是,我们有很多UTM产品部署在用户的网络边界,对进出的网络数据进行扫描,扫描结果会上传到服务端进行处理、存储,从而提供统计分析查询功能,用户通过产品管理界面可以查看最近6个月的网络行为分析数据、定制日/周/月报表。
在该系统中,我们需要为所有用户保留6个月的数据,而根据我们的统计分析,90%以上的请求访问的是最近1个月的数据,因此采用热数据系统保留35天数据,其他的迁移到冷数据系统中存储。为了配合数据挖掘相关功能,目前冷数据保留2年。该系统的数据是只读的,且对外主要提供统计类查询,因此热数据采用Elasticsearch来存储,利用其聚合分析能力提供高性能查询。冷数据以Parquet的格式保存在AWS S3上,通过AWS Athena实现查询。AWS Athena是一款基于Presto的托管数据查询系统,根据查询时所扫描的数据量来收费,不查询不收费,采用该系统可以充分利用云服务的优势,避免自己维护一套冷数据查询系统。
数据实时上传到服务端后,会进入数据流中,通过Spark Streaming程序处理后写入到Elasticsearch,提供近实时数据查询。与此同时,实时数据也会备份到AWS S3。每天夜里,会启动一个Spark程序,加载前一天的备份数据进行处理并写入AWS S3,作为冷数据存储。该系统中,Elasticsearch中的Index按天分割,每天冷数据生成后会将冷热分割线往前推移,并删除热数据中对应的Index。
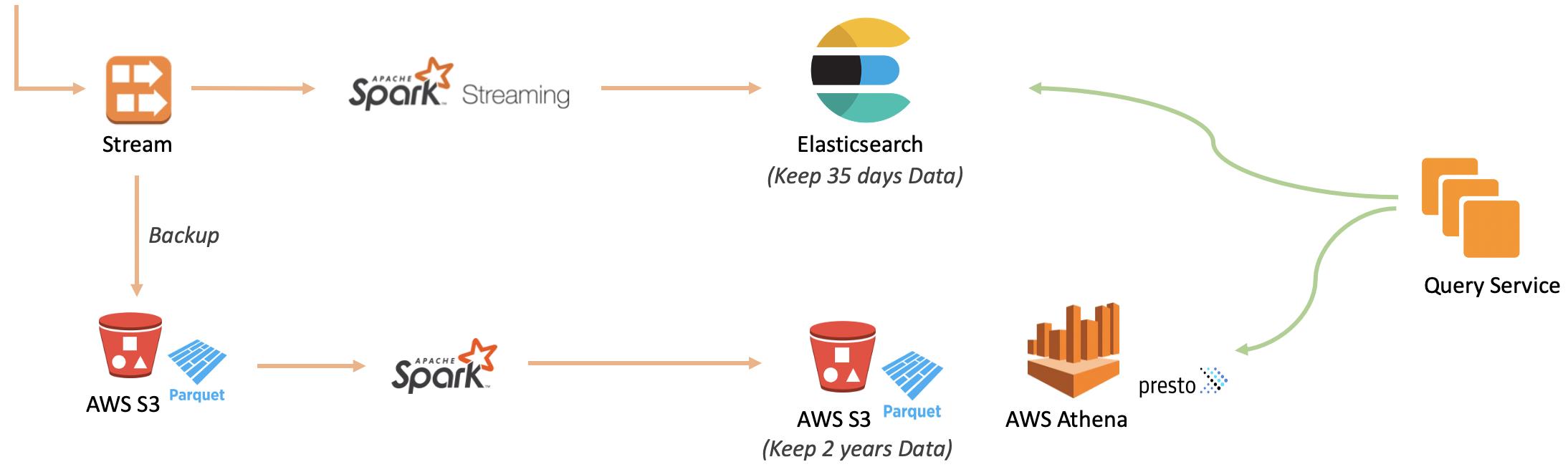
电商交易订单系统
业务背景是,用户在系统下单后会生成相应的交易订单信息,每天会产生大量的订单数据。这些数据需要永久保存,随时面对用户的低延迟查询,通常近3个月的订单是用户查询的主要对象。
在该系统中,热数据毫无疑问会采用MySQL(InnoDB)来实现,满足事务操作和高效查询的需求。当然,在查询系统前面还会有一层缓存,这里略过。冷数据以宽表的形式存储到HBase中,并采用Elasticsearch来提供相关的索引查询,配合HBase的数据查询。热数据在MySQL中保留90天,之后迁移到HBase中作为冷数据永久保存。
对于一个交易请求,会先在MySQL的订单表中创建订单记录,这些操作会通过BinLog同步到Kafka中,由Spark Streaming程序从Kafka中将相关订单信息变动提取出来,做相应的关联处理后写入到HBase中,同时更新Elasticsearch中的索引信息。每天定期将冷热分割线往前推移,并删除热数据中对应时间的订单表。
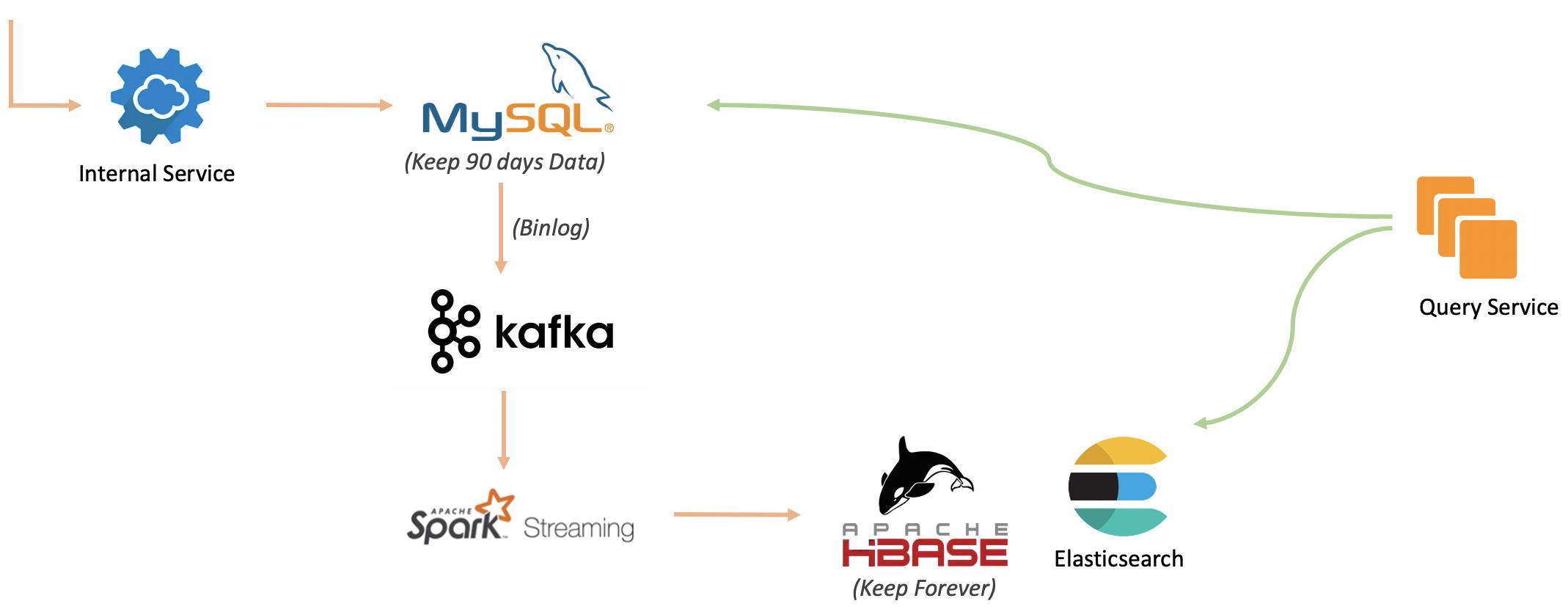
冷热分离同构系统
正如前文所述,冷热分离异构系统会带来整体的复杂性,主要表现在:需要维护两套系统,在业务逻辑中需要显式知道从哪里查询数据,甚至查询语法都不一样。很多开源框架在看到这一痛点后,开始在自己的体系下引入冷热分离的特性,试图以透明、统一的方式来应对冷热分离的需求。这里以Elasticsearch为例,来探讨下业界在冷热分离同构系统的诸多方案。
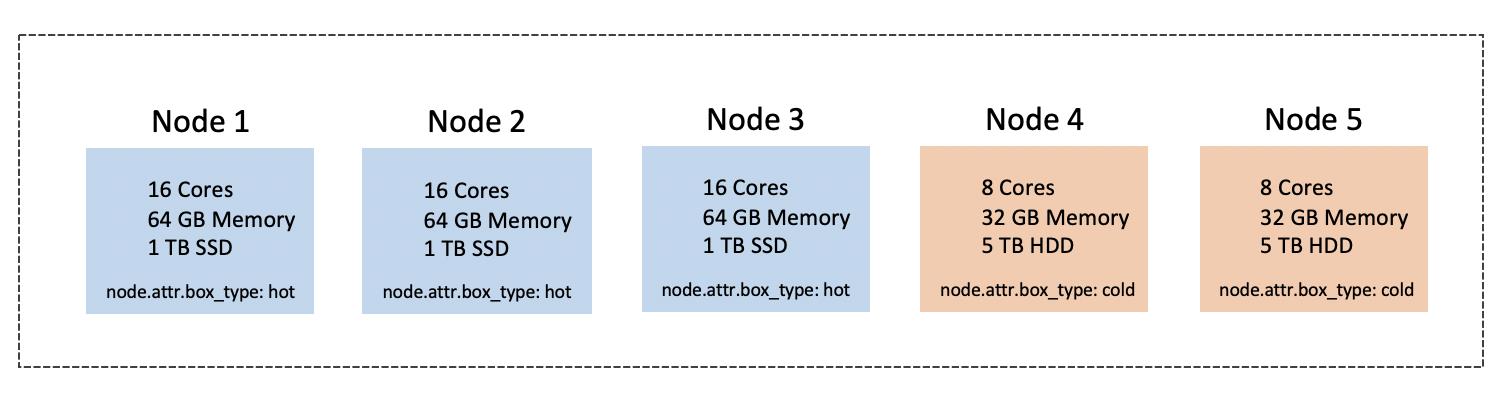
从Elasticsearch 5.0开始,便支持在一个集群中存放冷热数据,其核心思路是:在集群中放入不同配置的机器,将其打上不同的属性,比如下图中的Node 1/2/3便是高配置机器,用于存放热数据,属性为Hot,Node 4/5是低配置机器,用于存放冷数据,属性为Cold;当创建一个新的Index时,指定其数据分配到Hot属性的机器上;一段时间后,再将其配置修改为分配到Cold属性机器上,Elasticsearch便会自动完成数据迁移。
Elasticsearch 6.6之后,X-Pack中引入了Index Lifecycle Management机制,进一步简化了上述操作,我们不再需要自己定期去发送API做数据迁移了,只需要在Policy中设定Hot、Cold的生命周期即可,Elasticsearch会自动完成一切。
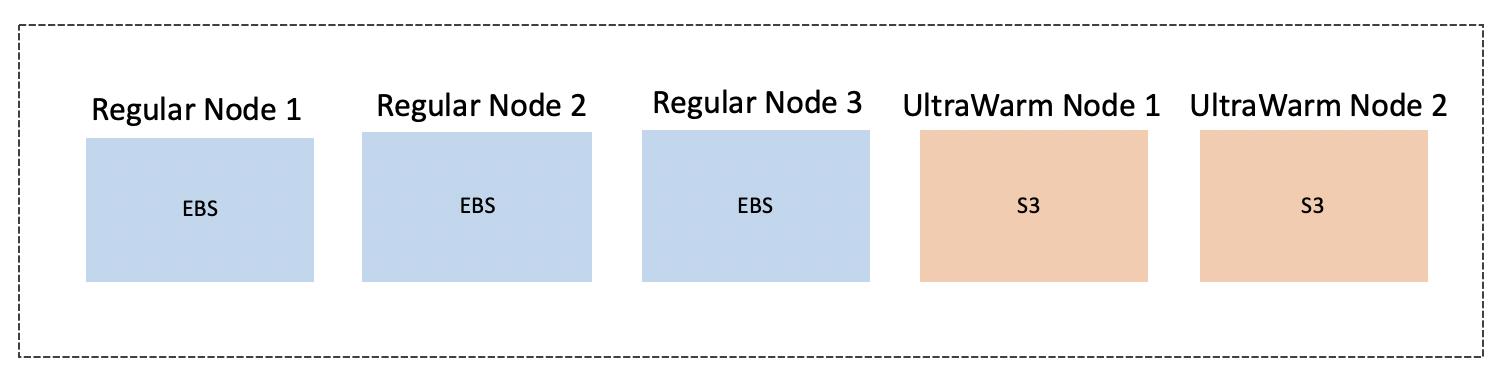
除了Elasticsearch官方作出的努力,各大云厂商也在积极往这方面发展。众所周知,随着云计算的发展,未来最便宜的数据存储方式是存储到云对象存储中,比如AWS S3。AWS在re:Invent 2019中发布了针对其Elasticsearch Service的UltraWarm机制,便是在推出冷热分离的解决方案。其基本思想跟上述相似,只是作为云服务,不再需要配置相应的机器属性,而是在创建集群时选择相应的UltraWarm机器,这类机器的数据存储在S3中。由业务自己决定何时需要将哪些Index转为冷数据,通过API发送相关请求到Elasticsearch即可。
结束语
本文探讨了大数据冷热分离的诸多解决方案,随着云计算的发展,应该会有越来越多的系统走向“冷热分离同构系统”的方案,从而简化整体的复杂性,在业务层表现为统一的访问方式。但是,异构系统中的冷数据系统还是会以另一种形式存在,毕竟我们需要将更多的历史数据沉淀到HDFS/S3这样的廉价存储系统中,为数据分析与挖掘提供弹药。
(全文完,本文地址:https://bruce.blog.csdn.net/article/details/106291463 )
版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!
Bruce
2020/06/14 下午
以上是关于大数据的一生一世——谈数据冷热分离技术的主要内容,如果未能解决你的问题,请参考以下文章