Java物流项目第一天 项目概述与基础数据服务开发
Posted 办公模板库 素材蛙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java物流项目第一天 项目概述与基础数据服务开发相关的知识,希望对你有一定的参考价值。
品达物流TMS项目
第1章 项目概述和环境搭建
1. 项目概述
1.1 项目介绍
本项目名称为品达物流TMS,TMS全称为:Transportation Management System,即运输管理系统,是对运输作业从运力资源准备到最终货物抵达目的地的全流程管理。TMS系统适用于运输公司、各企业下面的运输队等,它主要包括订单管理、配载作业、调度分配、行车管理、GPS车辆定位系统、车辆管理、线路管理、车次管理、人员管理、数据报表、基本信息维护等模块。该系统对车辆、驾驶员、线路等进行全面详细的统计考核,能大大提高运作效率,降低运输成本,使公司能够在激烈的市场竞争中处于领先地位。
本项目从用户层面可以分为四个端:TMS后台系统管理端、客户端App、快递员端App、司机端App。
- TMS后台系统管理端:公司内部管理员用户使用,可以进行基础数据维护、订单管理、运单管理等
- 客户端App:App名称为
品达速运,外部客户使用,可以寄件、查询物流信息等 - 快递员端App:App名称为
品达快递员,公司内部的快递员使用,可以接收取派件任务等 - 司机端App:App名称为
品达司机宝,公司内部的司机使用,可以接收运输任务、上报位置信息等


1.2 物流行业介绍
物流运输市场目前上最普遍的有四种行业类别:快递、快运、专线、三方。这四种行业支撑着全国商品货物的流通。
快递:物流行业外的人对物流的直接反应就是快递,快递只是物流行业的一种形态,得益于电商的发展把快递行业推到大众视野之中。快递的接收群体大多为个人,也称C端。快运、专线、三方的发货和接收群体主要为B端,主要为企业与企业之间的合作,也有少量个人。
快运:快运承运的多是小批量货物,一般为几立方货物或几十公斤货物,如德邦快递、远成快运,运输对象为单个沙发,桌椅等,配送网络为自建和加盟两种方式。
专线:专线衔接的货物多数为大宗商品,货物往往依照吨来结算,送货主要送到仓库,工厂,门店。整个配送网络都是社会化网络,由不同的专线进行配合,货物运输需要经过多次中转、集拼。
三方:三方不直接从事货物运输,主要通过与工厂签订运输合同,将货物交给专线或者联系车队、司机将货物送到指定地点,属于轻资产运作模式。
1.3 系统架构
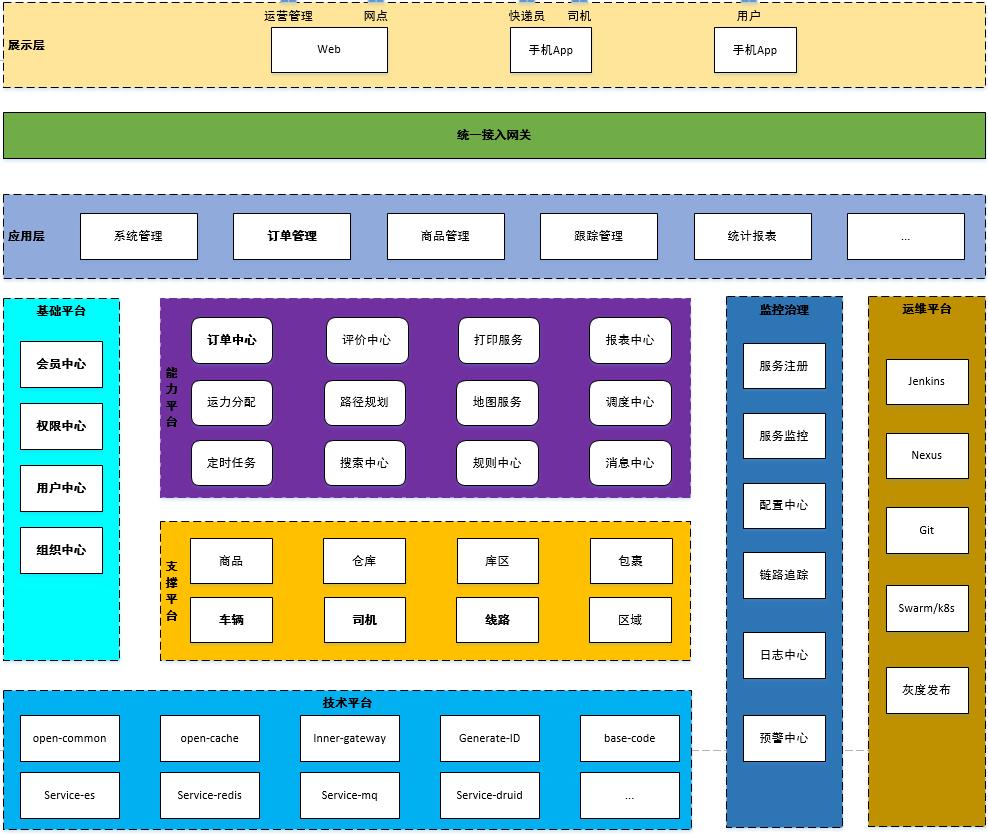

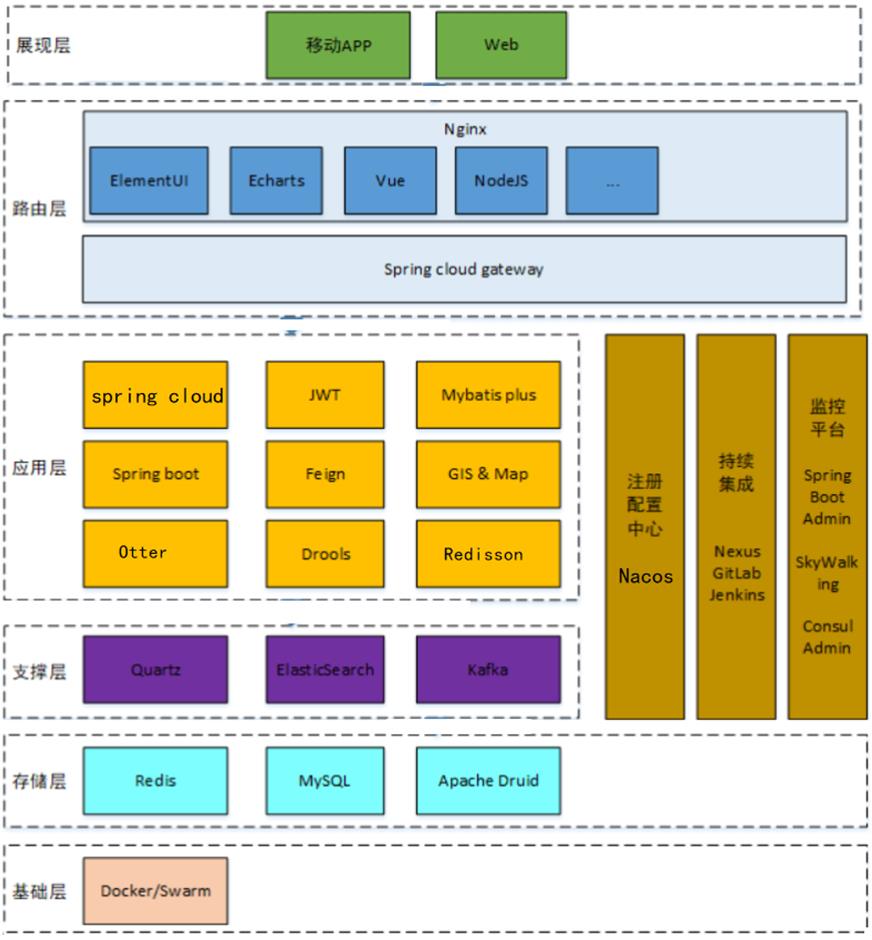
1.4 技术架构
2. 业务需求说明
2.1 产品需求和原型设计
参见资料中提供的"品达物流项目产品PRD文档_V0.5.1.docx"。
可以通过蓝湖在线查看产品原型。
蓝湖是一款产品文档和设计图的共享平台,帮助互联网团队更好地管理文档和设计图。
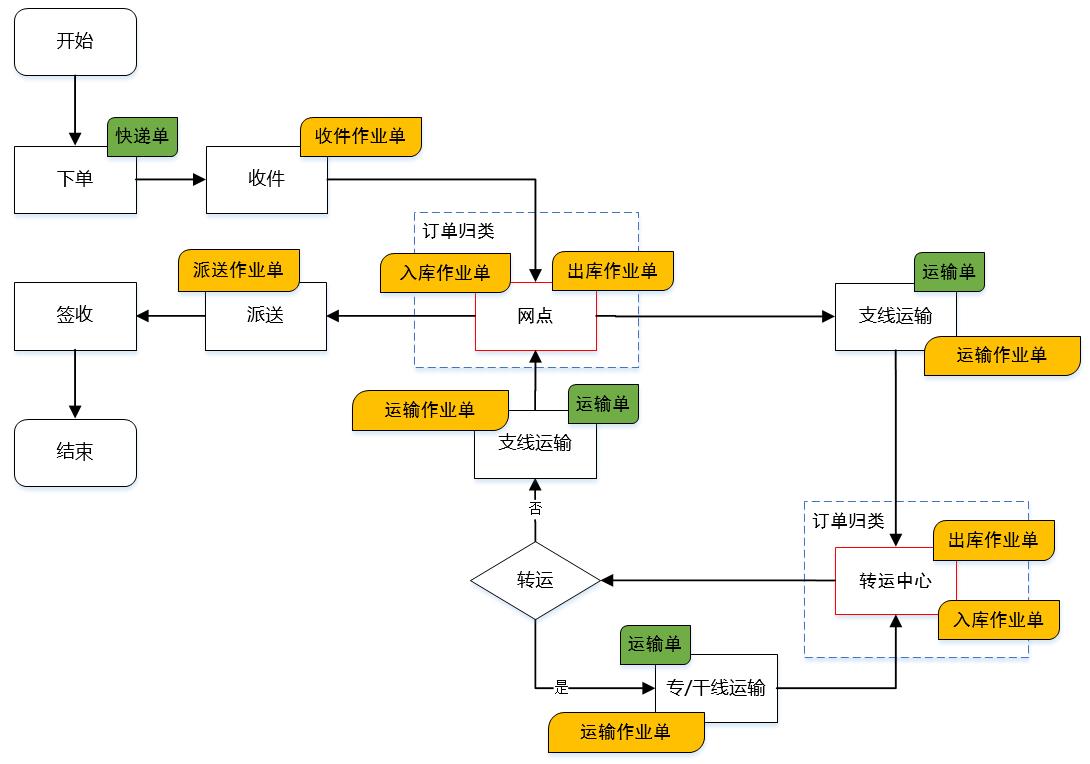
2.2 整体业务流程
下图展示的是从寄件人下单到最终收件人签收的整个流程:
3. 开发方式介绍
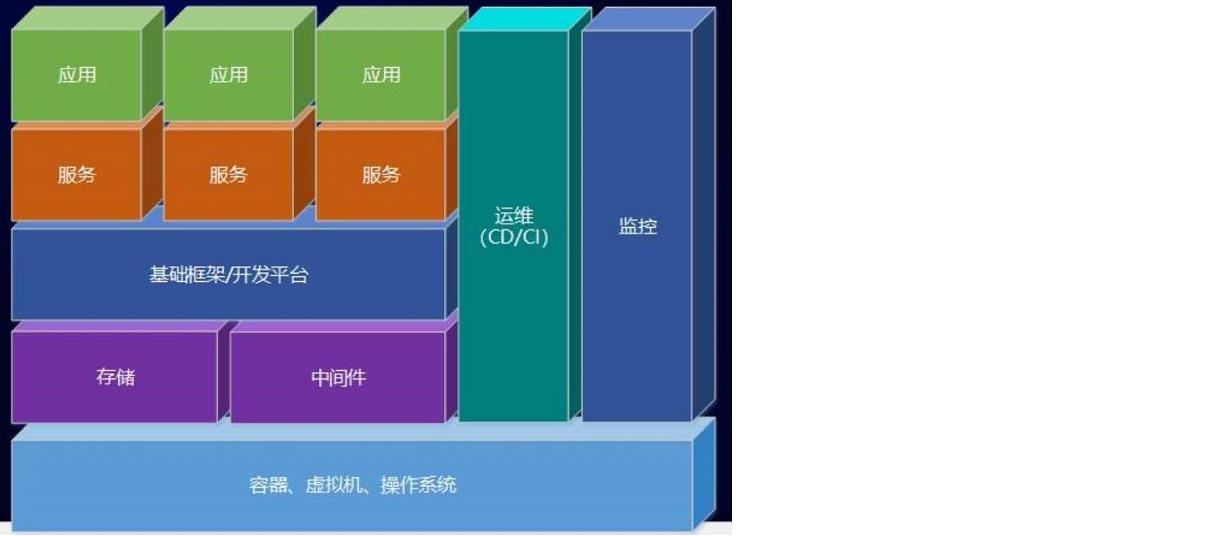
3.1 软件架构介绍
本项目的开发过程并不是从零开始,而是基于一些已有框架和服务来进行开发的。例如:TMS的后台管理端是通过通用权限系统进行菜单的配置、权限的配置、用户的配置、认证和鉴权等。客户端App是通过注册登录服务来完成C端用户的注册和登录功能。快递员端App是通过文件服务来完成附件的上传操作。
3.2 通用权限系统介绍
通用权限系统是黑马程序员自研的一个通用的开发平台和权限管理平台,提供了通用的岗位、组织结构、菜单、角色、用户等基础数据的维护功能,同时还提供了认证和鉴权功能,TMS项目可以直接来使用这些功能。
由于本课程主要开发的是TMS项目,所以依赖的通用权限系统已经提前部署好,我们直接使用即可。
3.3 短信服务介绍
企业开发中经常会使用到短信功能,市面上有多种短信服务平台可供选用,但是不同的短信平台调用方式都不相同,为了在项目中统一调用方式,黑马程序员对市面上主流的短信平台进行了整合,提供了统一的短信服务。在TMS中我们直接使用即可。
3.4 文件服务介绍
文件的上传、下载功能是软件系统中常见的功能,包括上传文件、下载文件、查看文件等。例如:电商系统中需要上传商品的图片、广告视频,办公系统中上传附件,社交类系统中上传用户头像等等。上传的文件有多种存储方式,例如:本地存储、FastDFS存储、云存储(阿里云、腾讯云、七牛云)等方式。不同的存储方式对应的处理方式都不相同,如果后期需要改变存储方式,维护成本比较高。针对以上问题,黑马程序员自研了通用的文件服务,对以上不同的存储方式进行了整合,对外暴露统一的文件服务接口。如果要改变存储方式,只需要在文件服务中修改配置即可切换,调用端程序代码不用做任何修改。
在TMS项目中的文件上传操作我们直接使用此文件服务即可。
3.5 注册登录服务介绍
注册登录服务是黑马程序员自研的针对C端用户的通用的注册登录服务,在TMS的客户端App会使用此服务来完成C端用户的注册和登录操作。
4. 基础数据配置
4.1 配置组织基础数据
组织结构数据是TMS的基础支撑数据,需要在通用权限系统中进行维护,如下图:
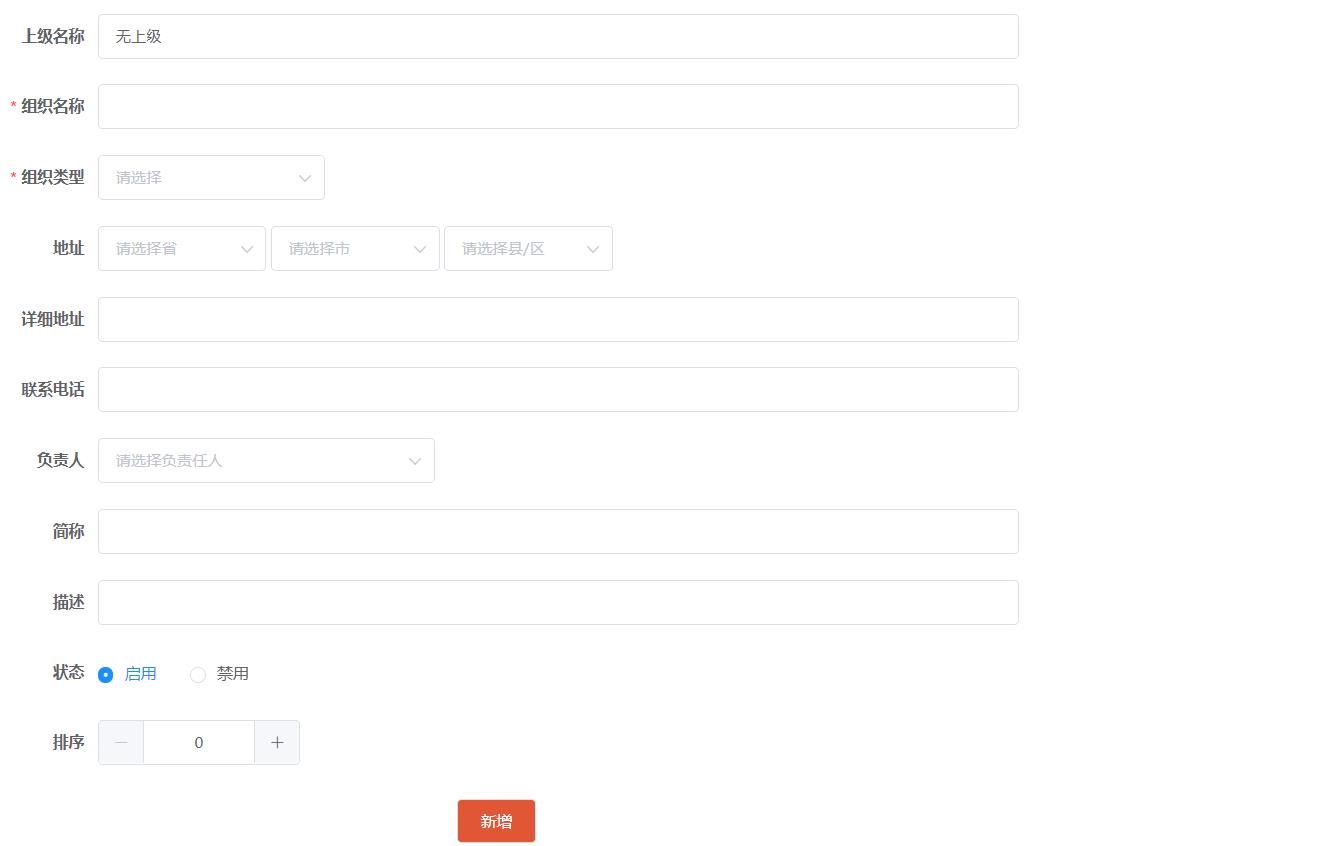
也可以直接执行资料中提供的sql脚本“pd_core_org.sql”来初始化TMS所需的组织结构数据,最终效果如下:

4.2 配置菜单、权限基础数据
菜单和权限数据也属于基础支撑数据,需要在通用权限系统中配置TMS项目对应的菜单和权限数据,如下:
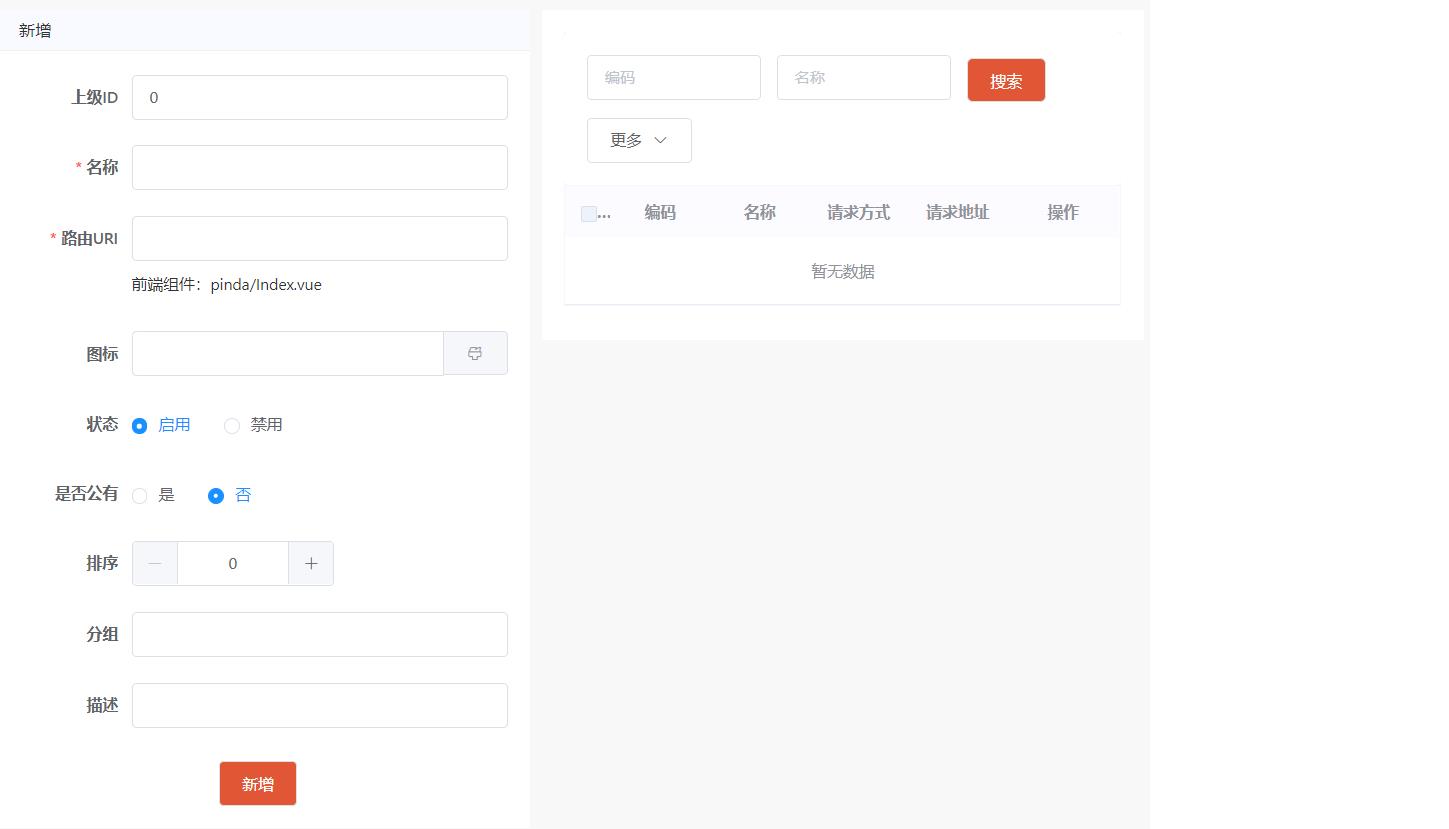
也可以直接执行资料中提供的sql脚本“pd_auth_menu.sql”和“pd_auth_resource.sql”来完成菜单和权限数据的初始化,最终效果如下:

4.3 配置岗位基础数据
岗位数据也属于基础支撑数据,可以在通用权限系统中配置TMS项目所需的岗位数据,如下:
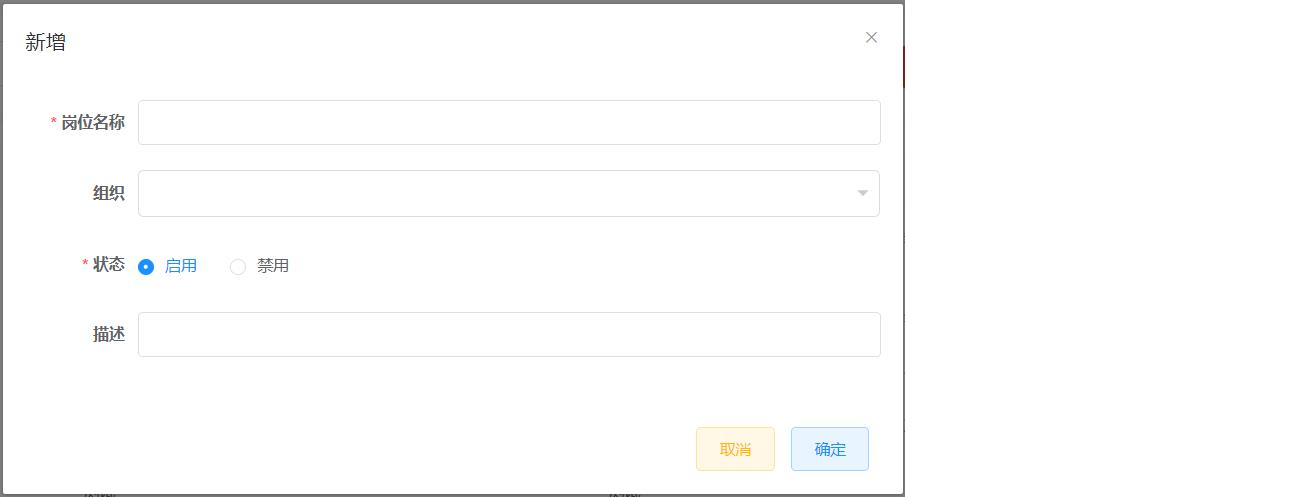
也可以直接执行资料中的sql脚本“pd_core_station.sql”来初始化TMS项目相关的岗位数据,如下:
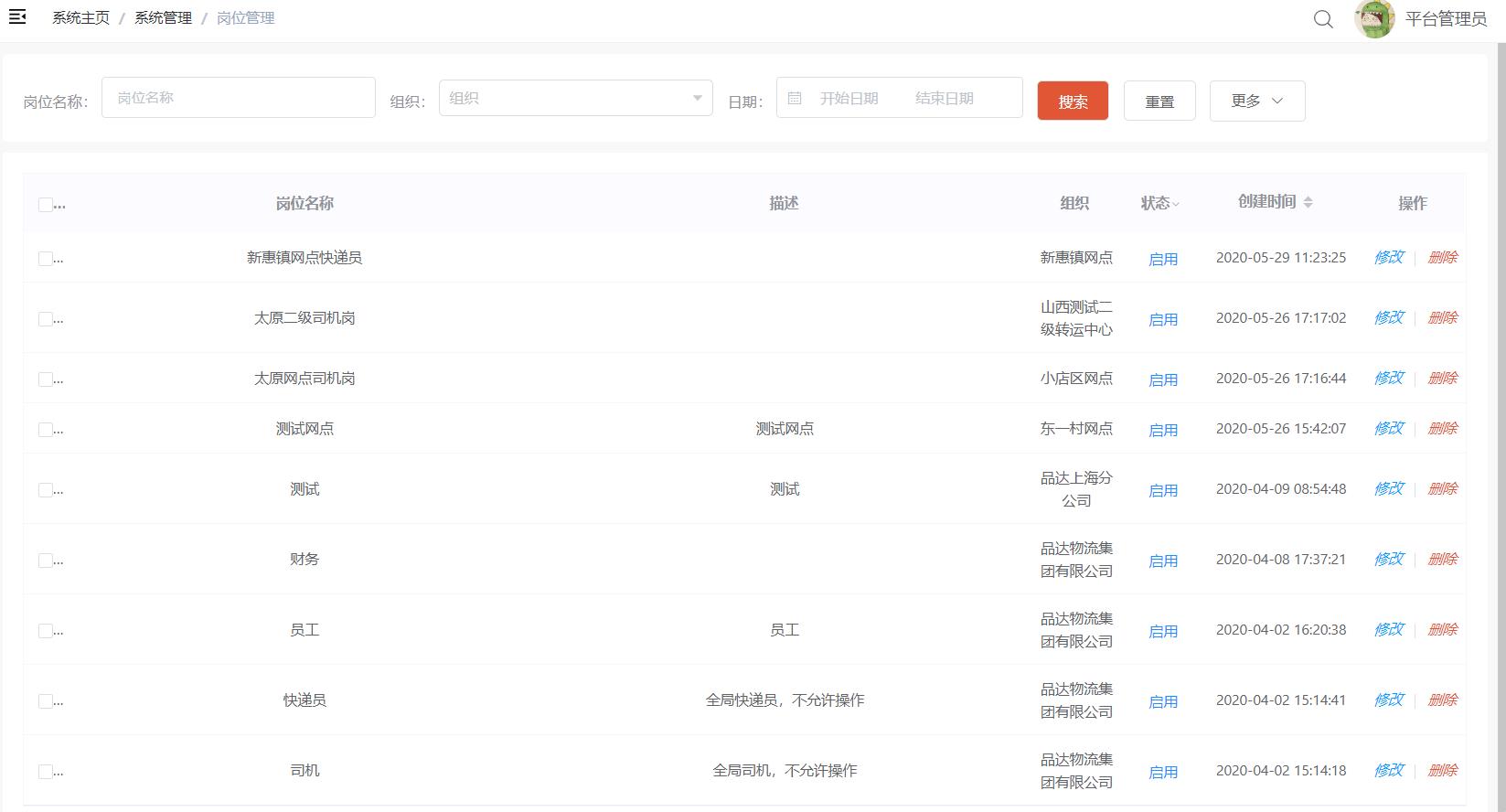
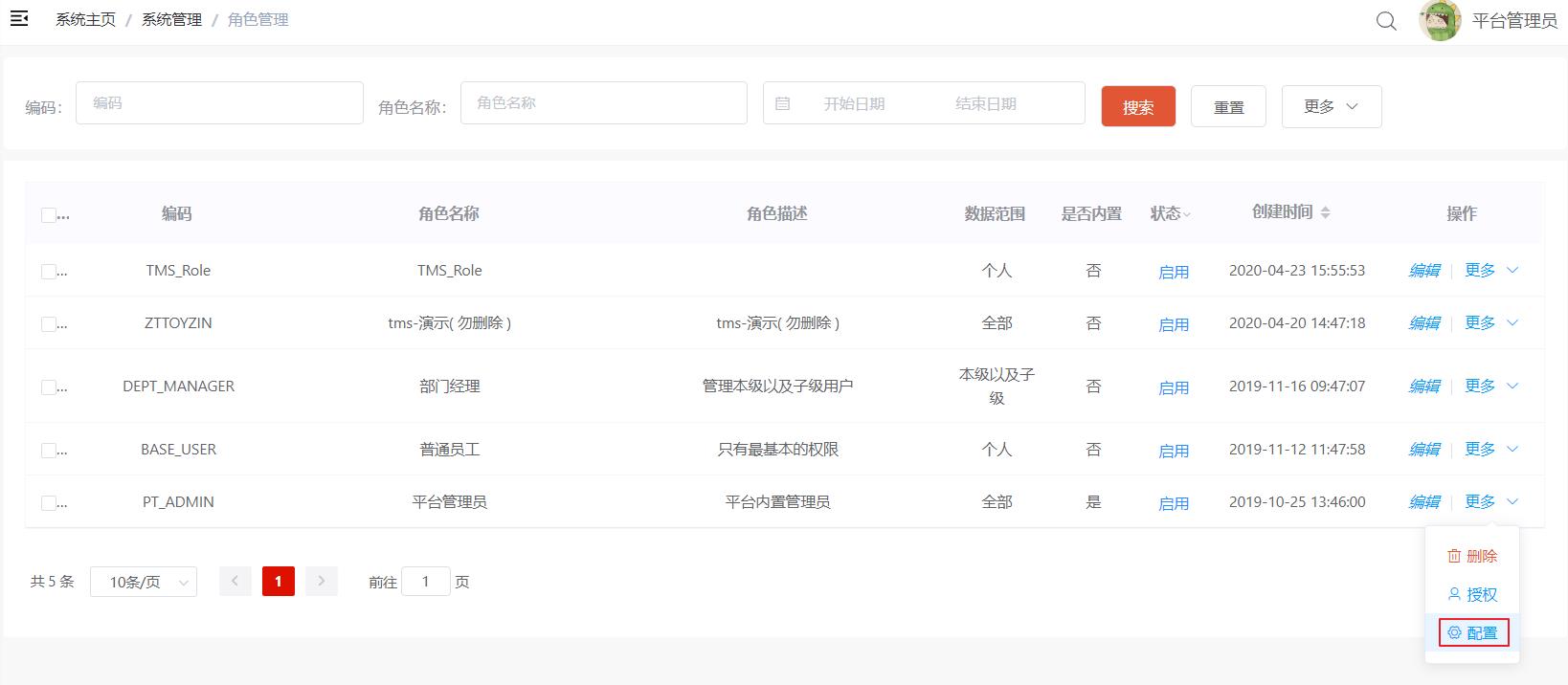
4.4 配置角色基础数据
角色数据也属于基础支撑数据,可以在通用权限系统中配置TMS项目所需的角色数据,如下:

也可以直接执行资料中的sql脚本“pd_auth_role.sql”来初始化TMS项目相关的角色数据,如下:

角色数据初始化完成后需要配置对应的菜单,如下:
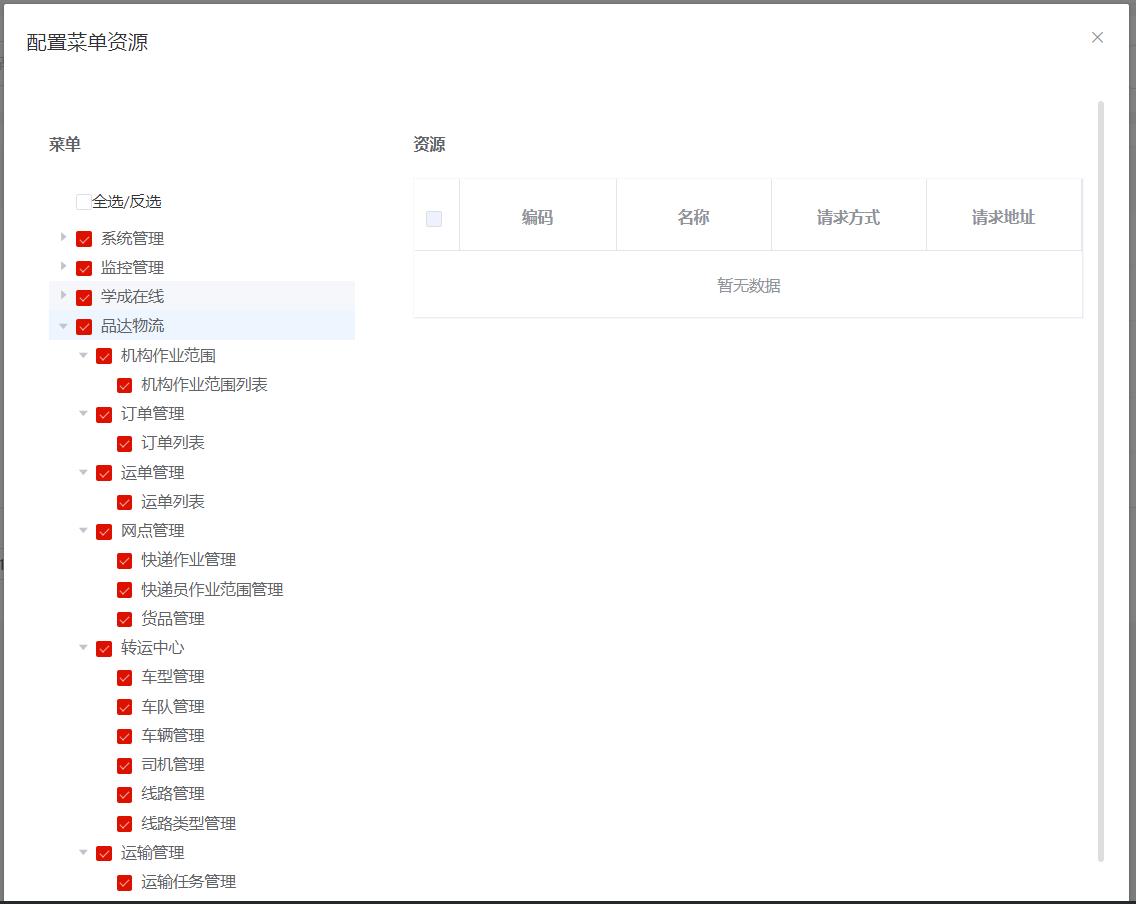
4.5 配置用户基础数据
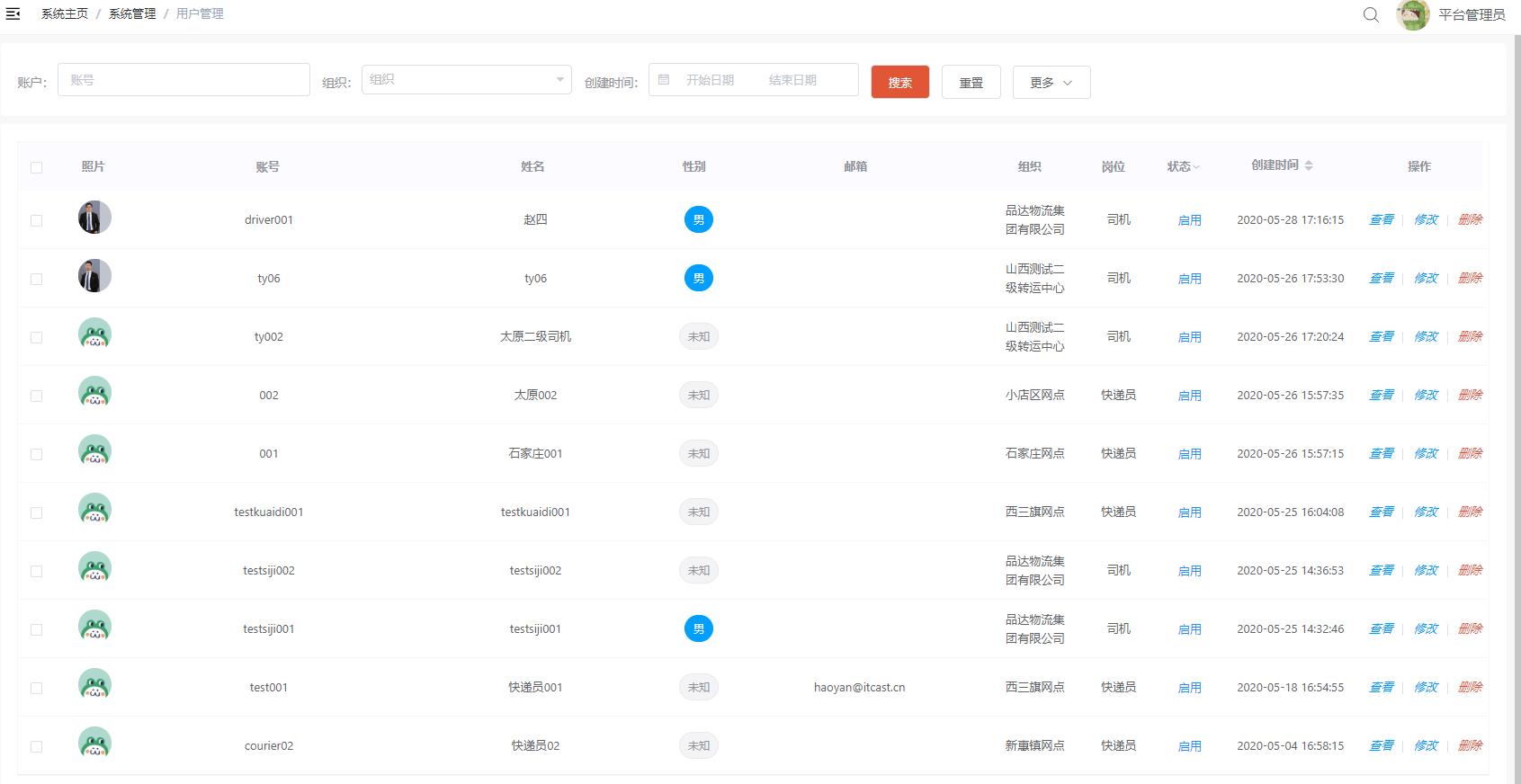
用户数据也属于基础数据,需要在通用权限系统中维护TMS中的用户数据,如下:
也可以直接执行资料中的sql脚本“pd_auth_user.sql”来初始化TMS项目相关的用户数据,如下:
用户数据初始化完成后需要在角色管理中进行角色和用户的关联操作,如下:


注意:此处维护的TMS用户数据分为三类:TMS后台系统用户、快递员、司机。
5. 搭建TMS项目开发环境
5.1 数据库环境搭建
执行资料中提供的sql脚本来完成TMS项目数据库的初始化工作

可以看到TMS项目共使用到6个数据库,如下:

各个数据库存放数据说明:
- pd_aggregation:存放聚合之后的数据,便于查询
- pd_base:存放TMS的基础数据,例如:车队、车辆、线路等
- pd_dispatch:存放定时任务相关数据
- pd_oms:存放订单相关数据
- pd_users:存放C端用户相关数据
- pd_work:存放作业相关数据,例如快递员的取件作业、司机的运输作业等
5.2 配置中心Nacos
TMS项目所需的配置文件需要统一配置在Nacos配置中心来统一管理和维护。由于TMS项目是属于微服务类型的项目,即根据业务拆分成若干个微服务,每个微服务都需要有对应的配置文件。
直接将资料中提供的压缩文件导入到Nacos中即可

导入后如下:
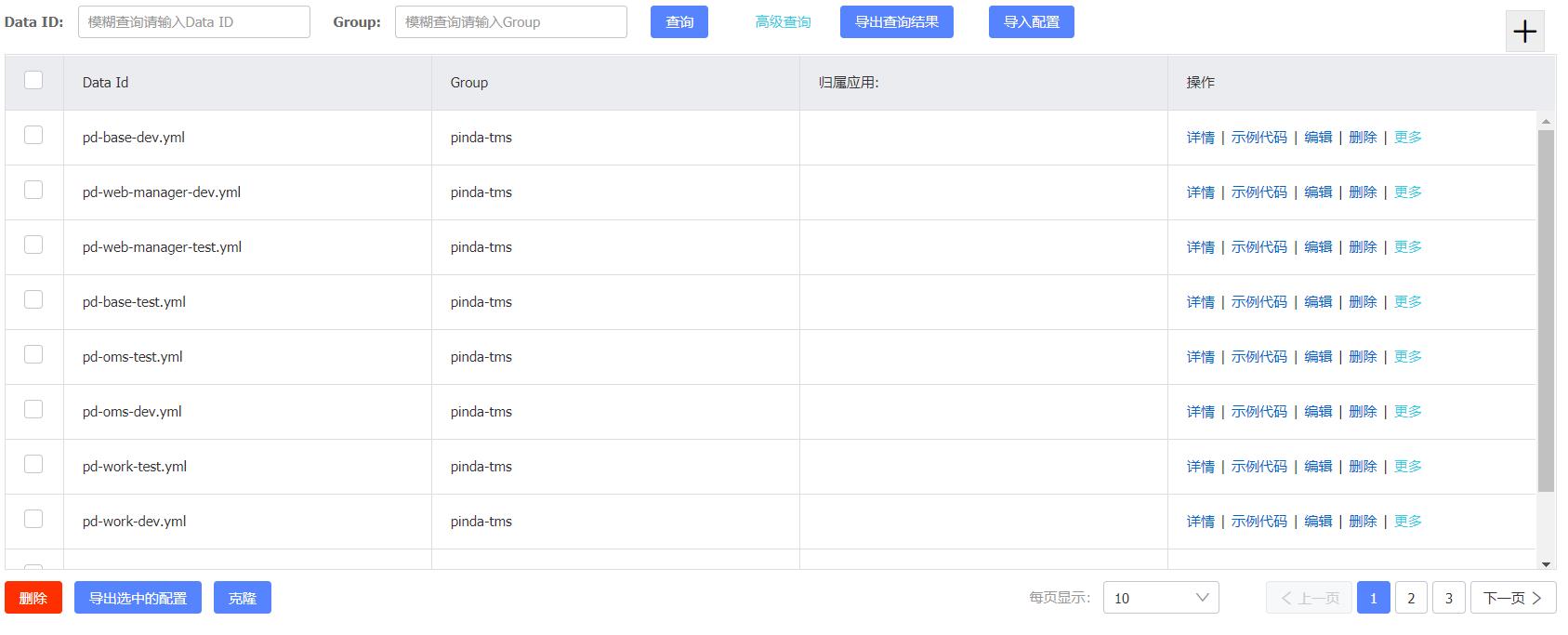
注:Nacos在作为配置中心的同时,还作为服务注册中心使用。
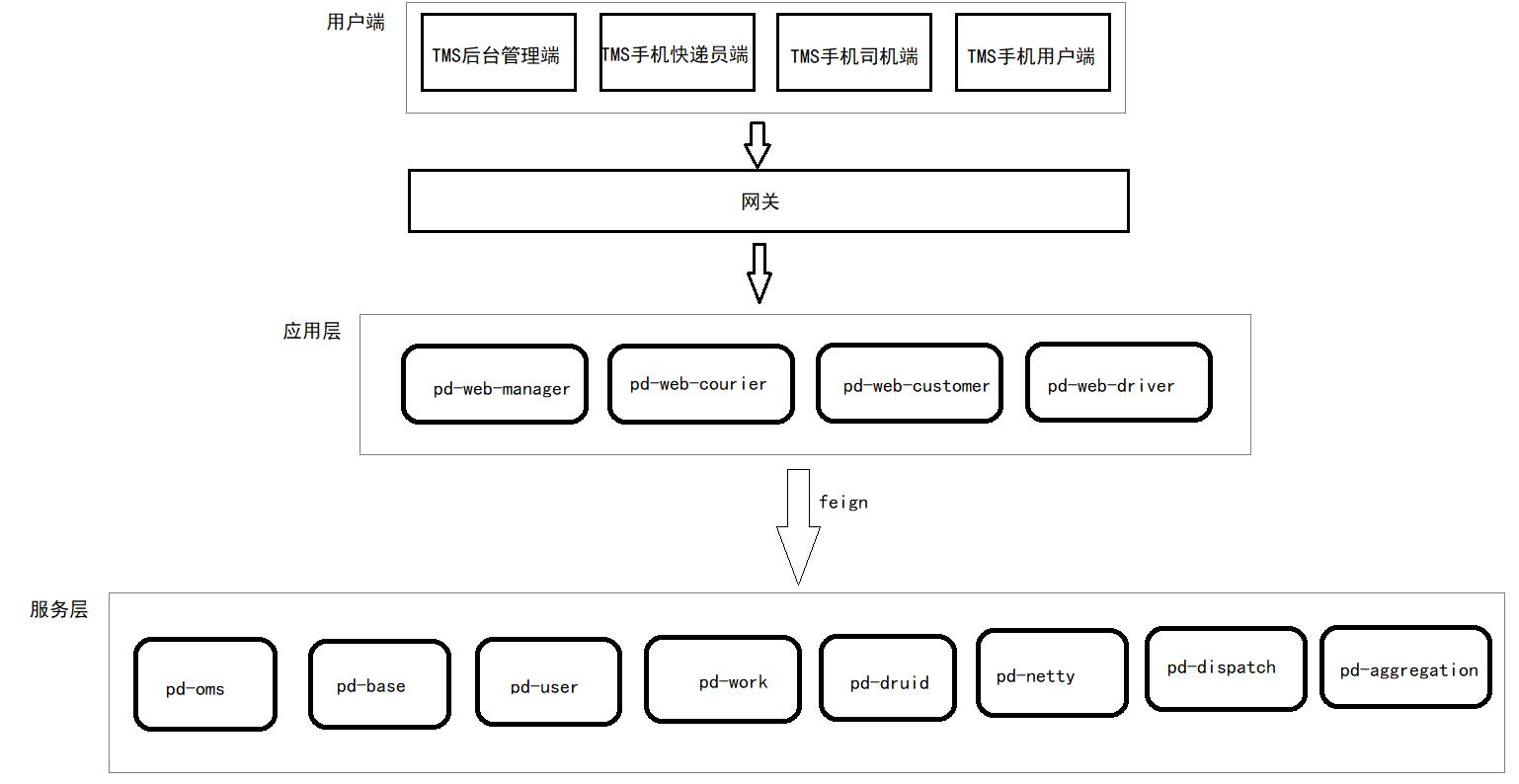
5.3 导入maven初始工程
TMS项目的maven工程结构提前已经搭建好,直接导入IEDA中,在此基础上进行开发即可。

下图展示了各个微服务的调用关系:
5.4 配置maven配置文件
上面我们导入的maven工程中使用到了通用权限系统中的两个jar,对应的maven坐标如下:
<dependency>
<groupId>com.itheima</groupId>
<artifactId>pd-auth-entity</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.itheima</groupId>
<artifactId>pd-auth-api</artifactId>
<version>1.0.0</version>
</dependency>
这两个jar在maven中央仓库是没有的,我们自己搭建了maven私服来管理这两个jar,这就需要在本地maven的settings.xml中进行私服的配置:

详细配置参照资料中初始工程\\settings.xml
品达物流TMS项目
第2章 基础数据服务开发(pd-base)
1. 基础数据服务数据模型
本章要开发的是基础数据微服务,对应的maven工程为pd-base。基础数据微服务提供TMS中基础数据的维护功能,例如:货物类型、车型、车队、车辆、车次、线路类型、线路等的维护功能。
基础数据服务对应操作的数据库为pd_base数据库,本小节就来了解一下pd_base数据库中所有的数据表结构。
1.1 pd_goods_type
pd_goods_type为货物类型表,结构如下:

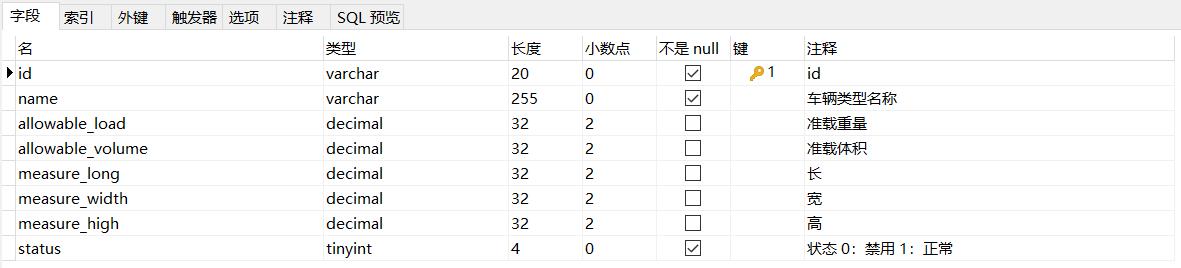
1.2 pd_truck_type
pd_truck_type为车辆类型表,结构如下:
1.3 pd_truck_type_goods_type
pd_truck_type_goods_type为车辆类型和货物类型关联表,结构如下:

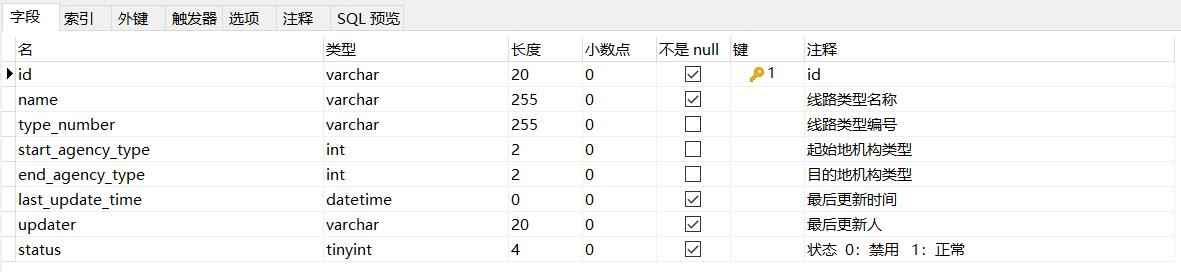
1.4 pd_transport_line_type
pd_transport_line_type为线路类型表,结构如下:
1.5 pd_transport_line
pd_transport_line为运输线路表,结构如下:

1.6 pd_transport_trips
pd_transport_trips为车次表,结构如下:

1.7 pd_fleet
pd_fleet为车队表,结构如下:

1.8 pd_truck_driver
pd_truck_driver为司机表,结构如下:

1.9 pd_transport_trips_truck_driver
pd_transport_trips_truck_driver为车次和司机关系表,结构如下:

1.10 pd_truck_license
pd_truck_license为车辆行驶证信息表,结构如下:
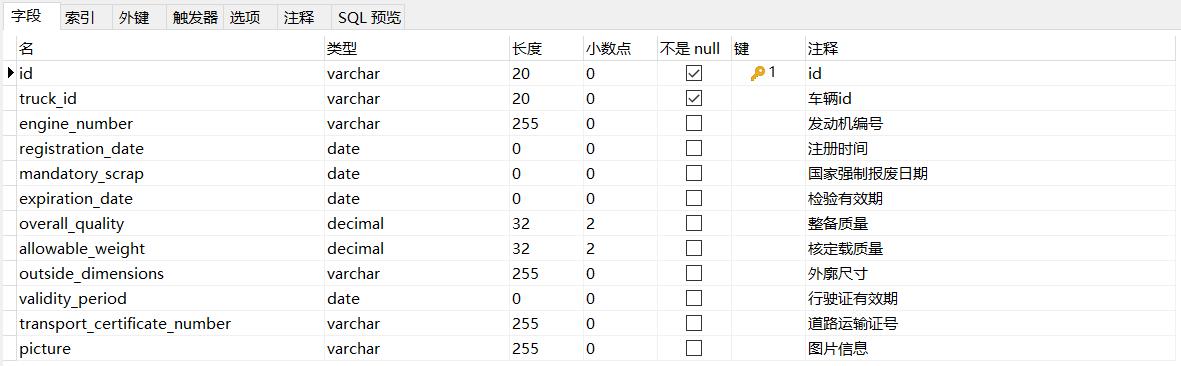
1.11 pd_truck_driver_license
pd_truck_driver_license为司机驾驶证信息表,结构如下:
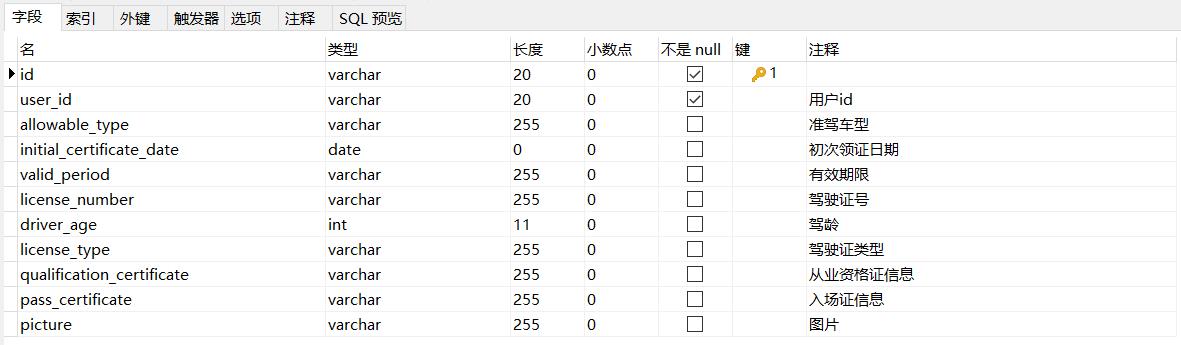
1.12 pd_agency_scope
pd_agency_scope为结构作业范围表,结构如下:

1.13 pd_truck
pd_truck为车辆表,结构如下:
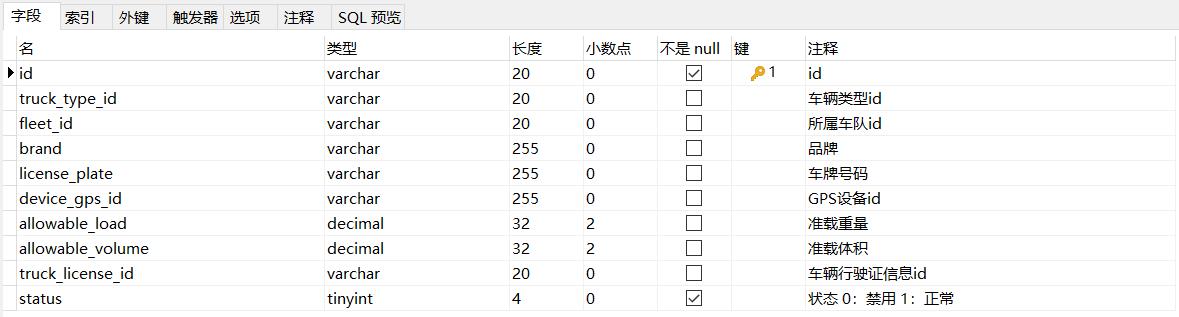
1.14 pd_courier_scop
pd_courier_scop为快递员作业范围表,结构如下:

2. 基础数据微服务开发准备
2.1 SpringBoot配置文件
bootstrap.yml:
server:
tomcat:
uri-encoding: UTF-8
max-threads: 1000
min-spare-threads: 30
port: 8185
connection-timeout: 50000ms
# servlet:
# context-path: /pd-base
spring:
application:
name: pd-base
# 环境 dev|test|prod
profiles:
active: dev
main:
allow-bean-definition-overriding: true
bootstrap-dev.yml:
spring:
cloud:
nacos:
username: tms
password: itheima123
discovery:
server-addr: 68.79.63.42:8848
group: pinda-tms
namespace: 6107f553-3214-48d8-89c3-945f8446e3d9
config:
server-addr: 68.79.63.42:8848
file-extension: yml
group: pinda-tms
namespace: 6107f553-3214-48d8-89c3-945f8446e3d9
# jackson时间格式化
jackson:
time-zone: $spring.jackson.time-zone
date-format: $spring.jackson.date-format
servlet:
multipart:
max-file-size: $spring.servlet.multipart.max-file-size
max-request-size: $spring.servlet.multipart.max-request-size
enabled: $spring.servlet.multipart.enabled
datasource:
druid:
type: $spring.datasource.druid.type
driver-class-name: $spring.datasource.druid.driver-class-name
url: $spring.datasource.druid.url
username: $spring.datasource.druid.username
password: $spring.datasource.druid.password
initial-size: $spring.datasource.druid.initial-size
max-active: $spring.datasource.druid.max-active
min-idle: $spring.datasource.druid.min-idle
max-wait: $spring.datasource.druid.max-wait
pool-prepared-statements: $spring.datasource.druid.pool-prepared-statements
max-pool-prepared-statement-per-connection-size: $spring.datasource.druid.max-pool-prepared-statement-per-connection-size
time-between-eviction-runs-millis: $spring.datasource.druid.time-between-eviction-runs-millis
min-evictable-idle-time-millis: $spring.datasource.druid.min-evictable-idle-time-millis
test-while-idle: $spring.datasource.druid.test-while-idle
test-on-borrow: $spring.datasource.druid.test-on-borrow
test-on-return: $spring.datasource.druid.test-on-return
stat-view-servlet:
enabled: $spring.datasource.druid.stat-view-servlet.stat-view-servlet
url-pattern: $spring.datasource.druid.stat-view-servlet.url-pattern
filter:
stat:
log-slow-sql: $spring.datasource.druid.filter.stat.log-slow-sql
slow-sql-millis: $spring.datasource.druid.filter.stat.slow-sql-millis
merge-sql: $spring.datasource.druid.filter.stat.merge-sql
wall:
config:
multi-statement-allow: $spring.datasource.druid.filter.wall.config.multi-statement-allow
#mybatis
mybatis-plus:
mapper-locations: $mybatis-plus.mapper-locations
#实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: $mybatis-plus.typeAliasesPackage
global-config:
#数据库相关配置
db-config:
#主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID", ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
id-type: $mybatis-plus.global-config.db-config.id-type
#字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
field-strategy: $mybatis-plus.global-config.db-config.field-strategy
#驼峰下划线转换
column-underline: $mybatis-plus.global-config.db-config.column-underline
logic-delete-value: $mybatis-plus.global-config.db-config.logic-delete-value
logic-not-delete-value: $mybatis-plus.global-config.db-config.logic-not-delete-value
banner: $mybatis-plus.global-config.banner
#原生配置
configuration:
map-underscore-to-camel-case: $mybatis-plus.configuration.map-underscore-to-camel-case
cache-enabled: $mybatis-plus.configuration.cache-enabled
call-setters-on-nulls: $mybatis-plus.configuration.call-setters-on-nulls
jdbc-type-for-null: $mybatis-plus.configuration.jdbc-type-for-null
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
2.2 服务启动类
package com.itheima.pinda;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@SpringBootApplication
@EnableDiscoveryClient
public class BaseApplication
public static void main(String[] args)
SpringApplication.run(BaseApplication.class, args);
2.3 配置类
package com.itheima.pinda.config;
import com.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig
@Bean
public PaginationInterceptor paginationInterceptor()
return new PaginationInterceptor();
package com.itheima.pinda.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurationSupport;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@Configuration
@EnableSwagger2
public class SwaggerConfig extends WebMvcConfigurationSupport
// 定义分隔符
private static final String splitor = ";";
@Bean
public Docket createRestApi()
// 文档类型
return new Docket(DocumentationType.SWAGGER_2)
// 创建api的基本信息
.apiInfo(apiInfo())
// 选择哪些接口去暴露
.select()
// 扫描的包
.apis(RequestHandlerSelectors.basePackage("com.itheima.pinda.controller"))
.paths(PathSelectors.any())
.build();
private ApiInfo apiInfo()
return new ApiInfoBuilder()
.title("品达物流管理后台基础数据--Swagger文档")
.version("1.0")
.build();
/**
* 防止@EnableMvc把默认的静态资源路径覆盖了,手动设置的方式
*
* @param registry
*/
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry)
// 解决静态资源无法访问
registry.addResourceHandler("/**").addResourceLocations("classpath:/static/");
// 解决swagger无法访问
registry.addResourceHandler("/swagger-ui.html").addResourceLocations("classpath:/META-INF/resources/");
// 解决swagger的js文件无法访问
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
2.4 Id生成器
package com.itheima.pinda.common;
import com.baomidou.mybatisplus.core.incrementer.IdentifierGenerator;
import com.itheima.pinda.common.utils.IdWorker;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
/**
* 自定义ID生成器
*/
@Component
public class CustomIdGenerator implements IdentifierGenerator
@Bean
public IdWorker idWorker()
return new IdWorker(1, 1);
@Autowired
private IdWorker idWorker;
@Override
public Long nextId(Object entity)
return idWorker.nextId();
3. 货物类型管理
3.1 业务需求和产品原型
货物类型是TMS的基础数据,表示物流货物的类别,例如:服饰、食品、数码产品等类型。
产品原型如下:


3.2 数据模型
货物类型对应的数据模型为:pd_base数据库中的pd_goods_type表,表结构如下:
3.3 导入实体类
package com.itheima.pinda.entity.base;
import java.io.Serializable;
import java.math.BigDecimal;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
/**
* 货物类型
*/
@Data
@TableName("pd_goods_type")
public class PdGoodsType implements Serializable
private static final long serialVersionUID = 1L;
/**
* id
*/
@TableId(value = "id", type = IdType.INPUT)
private String id;
/**
* 货物类型名称
*/
private String name;
/**
* 默认重量,单位:千克
*/
private BigDecimal defaultWeight;
/**
* 默认体积,单位:方
*/
private BigDecimal defaultVolume;
/**
* 说明
*/
private String remark;
/**
* 状态 0:禁用 1:正常
*/
private Integer status;
package com.itheima.pinda.entity.truck;
import java.io.Serializable;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* 车辆类型与货物类型关联
*/
@Data
@TableName("pd_truck_type_goods_type")
public class PdTruckTypeGoodsType implements Serializable
private static final long serialVersionUID = 1L;
/**
* id
*/
@TableId(value = "id", type = IdType.INPUT)
private String id;
/**
* 车辆类型id
*/
private String truckTypeId;
/**
* 货物类型id
*/
private String goodsTypeId;
3.4 服务接口开发
3.4.1 新增货物类型
第一步:创建GoodsTypeController并提供saveGoodsType方法
package com.itheima.pinda.controller.base;
import com.itheima.pinda.DTO.base.GoodsTypeDto;
import com.itheima.pinda.common.utils.Constant;
import com.itheima.pinda.common.utils.PageResponse;
import com.itheima.pinda.common.utils.Result;
import com.itheima.pinda.entity.base.PdGoodsType;
import com.itheima.pinda.entity.truck.PdTruckTypeGoodsType;
import com.itheima.pinda.service.base.IPdGoodsTypeService;
import com.itheima.pinda.service.truck.IPdTruckTypeGoodsTypeService;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.stream.Collectors;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
/**
* 货物类型管理
*/
@RestController
@RequestMapping("base/goodsType")
@Api(tags = "货物类型管理")
public class GoodsTypeController
@Autowired
private IPdGoodsTypeService goodsTypeService;
@Autowired
private IPdTruckTypeGoodsTypeService truckTypeGoodsTypeService;
/**
* 添加货物类型
*
* @param dto 货物类型信息
* @return 货物类型信息
*/
@PostMapping("")
@ApiOperation(value = "添加货物类型")
public GoodsTypeDto saveGoodsType(@RequestBody GoodsTypeDto dto)
PdGoodsType pdGoodsType = new PdGoodsType();
BeanUtils.copyProperties(dto, pdGoodsType);
pdGoodsType = goodsTypeService.saveGoodsType(pdGoodsType);
String goodsTypeId = pdGoodsType.getId();
if (dto.getTruckTypeIds() != null)
truckTypeGoodsTypeService.batchSave(dto.getTruckTypeIds().stream().map(truckTypeId ->
PdTruckTypeGoodsType truckTypeGoodsType = new PdTruckTypeGoodsType();
truckTypeGoodsType.setTruckTypeId(truckTypeId);
truckTypeGoodsType.setGoodsTypeId(goodsTypeId);
return truckTypeGoodsType;
).collect(Collectors.toList()));
BeanUtils.copyProperties(pdGoodsType, dto);
return dto;
第二步:创建IPdGoodsTypeService和IPdTruckTypeGoodsTypeService接口
package com.itheima.pinda.service.base;
import com.baomidou.mybatisplus.extension.service.IService;
import com.itheima.pinda.entity.base.PdGoodsType;
import java.util.List;
/**
* 货物类型
*/
public interface IPdGoodsTypeService extends IService<PdGoodsType>
/**
* 添加货物类型
*
* @param pdGoodsType 货物类型信息
* @return 货物类型信息
*/
PdGoodsType saveGoodsType(PdGoodsType pdGoodsType);
package com.itheima.pinda.service.truck;
import com.baomidou.mybatisplus.extension.service.IService;
import com.itheima.pinda.entity.truck.PdTruckTypeGoodsType;
import java.util.List;
/**
* 车辆类型与货物类型关联
*/
public interface IPdTruckTypeGoodsTypeService extends IService<PdTruckTypeGoodsType>
/**
* 批量添加车辆类型与货物类型关联
*
* @param truckTypeGoodsTypeList 车辆类型与货物类型信息
*/
void batchSave(List<PdTruckTypeGoodsType> truckTypeGoodsTypeList);
第三步:创建上面服务接口的实现类PdGoodsTypeServiceImpl和PdTruckTypeGoodsTypeServiceImpl
package com.itheima.pinda.service.base.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.itheima.pinda.common.CustomIdGenerator;
import com.itheima.pinda.mapper.base.PdGoodsTypeMapper;
import com.itheima.pinda.entity.base.PdGoodsType;
import com.itheima.pinda.service.base.IPdGoodsTypeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 货物类型实现类
*/
@Service
public class PdGoodsTypeServiceImpl extends ServiceImpl<PdGoodsTypeMapper, PdGoodsType> implements IPdGoodsTypeService
@Autowired
private CustomIdGenerator idGenerator;
@Override
public PdGoodsType saveGoodsType(PdGoodsType pdGoodsType)
pdGoodsType.setId(idGenerator.nextId(pdGoodsType) + "");
baseMapper.insert(pdGoodsType);
return pdGoodsType;
package com.itheima.pinda.service.truck.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.itheima.pinda.common.CustomIdGenerator;
import com.itheima.pinda.mapper.truck.PdTruckTypeGoodsTypeMapper;
import com.itheima.pinda.entity.truck.PdTruckTypeGoodsType;
import com.itheima.pinda.service.truck.IPdTruckTypeGoodsTypeService;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 车辆类型与货物类型关联实现类
*/
@Service
public class PdTruckTypeGoodsTypeServiceImpl extends
ServiceImpl<PdTruckTypeGoodsTypeMapper, PdTruckTypeGoodsType>
implements IPdTruckTypeGoodsTypeService
@Autowired
private CustomIdGenerator idGenerator;
@Override
public void batchSave(List<PdTruckTypeGoodsType> truckTypeGoodsTypeList)
truckTypeGoodsTypeList.forEach(pdTruckTypeGoodsType -> pdTruckTypeGoodsType.setId(idGenerator.nextId(pdTruckTypeGoodsType) + ""));
saveBatch(truckTypeGoodsTypeList);
第四步:创建PdGoodsTypeMapper接口和PdTruckTypeGoodsTypeMapper接口
package com.itheima.pinda.mapper.base;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.itheima.pinda.entity.base.PdGoodsType;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
/**
* 物类型Mapper接口
*/
@Mapper
public interface PdGoodsTypeMapper extends BaseMapper<PdGoodsType>
package com.itheima.pinda.mapper.truck;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.itheima.pinda.entity.truck.PdTruckTypeGoodsType;
import org.apache.ibatis.annotations.Mapper;
/**
* 车辆类型与货物类型关联Mapper接口
*/
@Mapper
public interface PdTruckTypeGoodsTypeMapper extends BaseMapper<PdTruckTypeGoodsType>
第五步:创建上面Mapper接口对应的xml映射文件
文件位置:/resources/mapper/base/PdGoodsTypeMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.pinda.mapper.base.PdGoodsTypeMapper">
</mapper>
文件位置:/resources/mapper/truck/PdTruckTypeGoodsTypeMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.pinda.mapper.truck.PdTruckTypeGoodsTypeMapper">
</mapper>
3.4.2 根据id查询货物类型
第一步:在GoodsTypeController中创建findById方法
/**
* 根据id查询货物类型
*
* @param id 货物类型id
* @return 货物类型信息
*/
@GetMapping("/id")
public GoodsTypeDto fineById(@PathVariable(name = "id") String id)
PdGoodsType pdGoodsType = goodsTypeService.getById(id);
GoodsTypeDto dto = null;
if (pdGoodsType != null)
dto = new GoodsTypeDto();
BeanUtils.copyProperties(pdGoodsType, dto);
dto.setTruckTypeIds(truckTypeGoodsTypeService.findAll(null, dto.getId()).stream().map(truckTypeGoodsType -> truckTypeGoodsType.getTruckTypeId()).collect(Collectors.toList()));
return dto;
第二步:在IPdTruckTypeGoodsTypeService接口中扩展findAll方法
/**
* 获取车辆类型与货物类型关联
*
* @param truckTypeId 车辆类型id
* @param goodsTypeId 货物类型id
* @return 车辆类型与货物类型关联
*/
List<PdTruckTypeGoodsType> findAll(String truckTypeId, String goodsTypeId);
第三步:在PdTruckTypeGoodsTypeServiceImpl实现类中实现findAll方法
@Override
public List<PdTruckTypeGoodsType> findAll(String truckTypeId, String goodsTypeId)
LambdaQueryWrapper<PdTruckTypeGoodsType> lambdaQueryWrapper = new LambdaQueryWrapper<>();
if (StringUtils.isNotEmpty(truckTypeId))
lambdaQueryWrapper.eq(PdTruckTypeGoodsType::getTruckTypeId, truckTypeId);
if (StringUtils.isNotEmpty(goodsTypeId))
lambdaQueryWrapper.eq(PdTruckTypeGoodsType::getGoodsTypeId, goodsTypeId);
return baseMapper.selectList(lambdaQueryWrapper);
3.4.3 查询所有货物类型
第一步:在GoodsTypeController中创建findAll方法
/**
* 查询所有货物类型
* @return
*/
@GetMapping("/all")
@ApiOperation(value = "查询所有货物类型")
public List<GoodsTypeDto> findAll()
List<PdGoodsType> goodsType = goodsTypeService.findAll();
List<GoodsTypeDto> goodsTypeDtoList = goodsType.stream().map(item ->
GoodsTypeDto dto = new GoodsTypeDto();
BeanUtils.copyProperties(item, dto);
return dto;
).collect(Collectors.toList());
return goodsTypeDtoList;
第二步:在IPdGoodsTypeService接口中扩展findAll方法
List<PdGoodsType> findAll();
第三步:在PdGoodsTypeServiceImpl中实现findAll方法
@Override
public List<PdGoodsType> findAll()
QueryWrapper<PdGoodsType> wrapper = new QueryWrapper<>();
wrapper.eq("status",1);
return baseMapper.selectList(wrapper);
3.4.4 分页查询货物类型
第一步:在GoodsTypeController中创建findByPage方法
/**
* 获取分页货物类型数据
*
* @param page 页码
* @param pageSize 页尺寸
* @param name 货物类型名称
* @param truckTypeId 车辆类型Id
* @param truckTypeName 车辆类型名称
* @return
*/
@GetMapping("/page")
@ApiOperation(value = "获取分页货物类型数据")
public PageResponse<GoodsTypeDto> findByPage(
@RequestParam(name = "page") Integer page,
@RequestParam(name = "pageSize") Integer pageSize,
@RequestParam(name = "name", required = false) String name,
@RequestParam(name = "truckTypeId", required = false) String truckTypeId,
@RequestParam(name = "truckTypeName", required = false) String truckTypeName)
IPage<PdGoodsType> goodsTypePage = goodsTypeService.findByPage(page, pageSize, name, truckTypeId, truckTypeName);
List<GoodsTypeDto> goodsTypeDtoList = goodsTypePage.getRecords().stream().map(goodsType ->
GoodsTypeDto dto = new GoodsTypeDto();
BeanUtils.copyProperties(goodsType, dto);
dto.setTruckTypeIds(truckTypeGoodsTypeService.findAll(null, dto.getId()).stream().map(truckTypeGoodsType -> truckTypeGoodsType.getTruckTypeId()).collect(Collectors.toList()));
return dto;
).collect(Collectors.toList());
return PageResponse.<GoodsTypeDto>builder().items(goodsTypeDtoList).counts(goodsTypePage.getTotal()).page(page).pages(goodsTypePage.getPages()).pagesize(pageSize).build();
第二步:在IPdGoodsTypeService接口中扩展findByPage方法
/**
* 获取分页货物类型数据
* @param page 页码
* @param pageSize 页尺寸
* @return 分页货物数据
*/
IPage<PdGoodsType> findByPage(Integer page, Integer pageSize,String name,String truckTypeId,String truckTypeName);
第三步:在PdGoodsTypeServiceImpl实现类中实现findByPage方法
@Override
public IPage<PdGoodsType> findByPage(Integer page, Integer pageSize, String name, String truckTypeId, String truckTypeName)
Page<PdGoodsType> iPage = new Page(page, pageSize);
iPage.addOrder(OrderItem.asc("id"));
iPage.setRecords(baseMapper.findByPage(iPage, name, truckTypeId, truckTypeName));
return iPage;
第四步:在PdGoodsTypeMapper接口中创建findByPage方法
List<PdGoodsType> findByPage(Page<PdGoodsType> page,
@Param("name")String name,
@Param("truckTypeId")String truckTypeId,
@Param("truckTypeName")String truckTypeName);
第五步:在PdGoodsTypeMapper.xml中提供sql
<select id="findByPage" resultType="com.itheima.pinda.entity.base.PdGoodsType">
SELECT
goods_type.*
FROM
pd_goods_type goods_type
<if test="truckTypeId != null || truckTypeName != null">
LEFT JOIN pd_truck_type_goods_type truck_type_goods_type ON goods_type.id = truck_type_goods_type.goods_type_id
</if>
<if test="truckTypeName != null">
LEFT JOIN pd_truck_type truck_type ON truck_type_goods_type.truck_type_id=truck_type.id
</if>
<where>
goods_type.status=1
<if test="truckTypeName != null">
AND truck_type.status=1
</if>
<if test="name != null">
AND goods_type.name LIKE "%"#name"%"
</if>
<if test="truckTypeId != null">
AND truck_type_goods_type.truck_type_id = #truckTypeId
</if>
<if test="truckTypeName != null">
AND truck_type.name LIKE "%"#truckTypeName"%"
</if>
</where>
</select>
3.4.5 查询货物类型列表
第一步:在GoodsTypeController中创建findAll方法
/**
* 获取货物类型列表
*
* @return 货物类型列表
*/
@GetMapping("")
@ApiOperation(value = "获取货物类型列表")
public List<GoodsTypeDto> findAll(@RequestParam(name = "ids", required = false) List<String> ids)
return goodsTypeService.findAll(ids).stream().map(pdGoodsType ->
GoodsTypeDto dto = new GoodsTypeDto();
BeanUtils.copyProperties(pdGoodsType, dto);
dto.setTruckTypeIds(truckTypeGoodsTypeService.findAll(null, dto.getId()).stream().map(truckTypeGoodsType -> truckTypeGoodsType.getTruckTypeId()).collect(Collectors.toList()));
return dto;
).collect(Collectors.toList());
第二步:在IPdGoodsTypeService接口中扩展findAll方法
/**
* 获取货物类型列表
* @param ids 货物类型id
* @return 货物类型列表
*/
List<PdGoodsType> findAll(List<String> ids);
第三步:在PdGoodsTypeServiceImpl实现类中实现findAll方法
@Override
public List<PdGoodsType> findAll(List<String> ids)
LambdaQueryWrapper<PdGoodsType> lambdaQueryWrapper = new LambdaQueryWrapper<>();
if (ids != null && ids.size() > 0)
lambdaQueryWrapper.in(PdGoodsType::getId, ids);
return baseMapper.selectList(lambdaQueryWrapper);
3.4.6 更新货物类型
第一步:在GoodsTypeController中创建update方法
/**
* 更新货物类型信息
*
* @param dto 货物类型信息
* @return 货物类型信息
*/
@PutMapping("/id")
@ApiOperation(value = "更新货物类型信息")
public GoodsTypeDto update(@PathVariable(name = "id") String id, @RequestBody GoodsTypeDto dto)
dto.setId(id);
PdGoodsType pdGoodsType = new PdGoodsType();
BeanUtils.copyProperties(dto, pdGoodsType);
goodsTypeService.updateById(pdGoodsType);
if (dto.getTruckTypeIds() != null)
truckTypeGoodsTypeService.delete(null, id);
truckTypeGoodsTypeService.batchSave(dto.getTruckTypeIds().stream().map(truckTypeId ->
PdTruckTypeGoodsType truckTypeGoodsType = new PdTruckTypeGoodsType();
truckTypeGoodsType.setTruckTypeId(truckTypeId);
truckTypeGoodsType.setGoodsTypeId(id);
return truckTypeGoodsType;
).collect(Collectors.toList()));
return dto;
第二步:在IPdTruckTypeGoodsTypeService接口中扩展delete方法
/**
* 删除关联关系
*
* @param truckTypeId 车辆类型id
* @param goodsTypeId 货物类型id
*/
void delete(String truckTypeId, String goodsTypeId);
第三步:在PdTruckTypeGoodsTypeServiceImpl实现类中实现delete方法
@Override
public void delete(String truckTypeId, String goodsTypeId)
LambdaQueryWrapper<PdTruckTypeGoodsType> lambdaQueryWrapper = new LambdaQueryWrapper<>();
boolean canExecute = false;
if (StringUtils.isNotEmpty(truckTypeId))
lambdaQueryWrapper.eq(PdTruckTypeGoodsType::getTruckTypeId, truckTypeId);
canExecute = true;
if (StringUtils.isNotEmpty(goodsTypeId))
lambdaQueryWrapper.eq(PdTruckTypeGoodsType::getGoodsTypeId, goodsTypeId);
canExecute = true;
if (canExecute)
baseMapper.delete(lambdaQueryWrapper);
3.4.7 删除货物类型
注意:此处删除货物类型为逻辑删除
在GoodsTypeController中创建disable方法
/**
* 删除货物类型
*
* @param id 货物类型id
* @return 返回信息
*/
@PutMapping("/id/disable")
@ApiOperation(value = "删除货物类型")
public Result disable(@PathVariable(name = "id") String id)
PdGoodsType pdGoodsType = new PdGoodsType();
pdGoodsType.setId(id);
pdGoodsType.setStatus(Constant.DATA_DISABLE_STATUS);
goodsTypeService.updateById(pdGoodsType);
return Result.ok();
4. 数据校验
4.1 数据校验方式
前面我们已经完成了基础数据服务中货物类型相关接口的开发,但是现在还存在一个问题就是数据没有进行合法性校验,例如货物类型的名称和状态都不能为空。那么如何进行数据的合法性校验呢?
整体来说,数据合法性校验可以分为前端实现和后端实现。前端校验主要是通过javascript实现,后端校验可以通过一些校验框架实现。
- 前端校验:主要是提高用户体验
- 后端校验:主要是保证数据安全可靠
由于我们开发的是后端(服务端),所以只需要进行后端校验即可。
4.2 hibernate validator介绍
校验参数基本上是一个体力活,而且冗余代码繁多,也影响代码的可读性,我们需要一个比较优雅的方式来解决这个问题。Hibernate Validator 框架刚好解决了这个问题,可以以很优雅的方式实现参数的校验,让业务代码和校验逻辑分开,不再编写重复的校验逻辑。
hibernate-validator优势:
- 验证逻辑与业务逻辑之间进行了分离,降低了程序耦合度
- 统一且规范的验证方式,无需你再次编写重复的验证代码
- 你将更专注于你的业务,将这些繁琐的事情统统丢在一边
hibernate-validator的maven坐标:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.0.18.Final</version>
</dependency>
注:在springboot项目中如果已经导入了spring-boot-starter-web的maven坐标,就不需要再显示的导入hibernate-validator的maven坐标了,因为在spring-boot-starter-web中已经通过maven的依赖传递特性传递过来了hibernate-validator的maven坐标,如下图:
4.3 hibernate-validator常用注解
hibernate-validator提供的校验方式为在类的属性上加入相应的注解来达到校验的目的。hibernate-validator提供的用于校验的注解如下:
| 注解 | 说明 |
|---|---|
| @AssertTrue | 用于boolean字段,该字段只能为true |
| @AssertFalse | 用于boolean字段,该字段只能为false |
| @CreditCardNumber | 对信用卡号进行一个大致的验证 |
| @DecimalMax | 只能小于或等于该值 |
| @DecimalMin | 只能大于或等于该值 |
| 检查是否是一个有效的email地址 | |
| @Future | 检查该字段的日期是否是属于将来的日期 |
| @Length(min=,max=) | 检查所属的字段的长度是否在min和max之间,只能用于字符串 |
| @Max | 该字段的值只能小于或等于该值 |
| @Min | 该字段的值只能大于或等于该值 |
| @NotNull | 不能为null |
| @NotBlank | 不能为空,检查时会将空格忽略 |
| @NotEmpty | 不能为空,这里的空是指空字符串 |
| @Pattern(regex=) | 被注释的元素必须符合指定的正则表达式 |
| @URL(protocol=,host,port) | 检查是否是一个有效的URL,如果提供了protocol,host等,则该URL还需满足提供的条件 |
4.4 使用hibernate-validator进行校验
第一步:修改GoodsTypeDto,为name和status属性加入hibernate-validator注解进行数据校验
/**
* 货物类型名称
*/
@ApiModelProperty("物品类型名称")
@NotNull
private String name;
/**
* 状态 0:禁用 1:正常
*/
@ApiModelProperty("状态 0:禁用 1:正常")
@NotNull
@Max(value = 1)
@Min(value = 0)
private Integer status;
第二步:修改GoodsTypeController,开启校验
/**
* 添加货物类型
*
* @param dto 货物类型信息
* @return 货物类型信息
*/
@PostMapping("")
public GoodsTypeDto saveGoodsType(@Validated @RequestBody GoodsTypeDto dto)
...
5. 导入基础数据服务其他代码
有效的email地址 |
| @Future | 检查该字段的日期是否是属于将来的日期 |
| @Length(min=,max=) | 检查所属的字段的长度是否在min和max之间,只能用于字符串 |
| @Max | 该字段的值只能小于或等于该值 |
| @Min | 该字段的值只能大于或等于该值 |
| @NotNull | 不能为null |
| @NotBlank | 不能为空,检查时会将空格忽略 |
| @NotEmpty | 不能为空,这里的空是指空字符串 |
| @Pattern(regex=) | 被注释的元素必须符合指定的正则表达式 |
| @URL(protocol=,host,port) | 检查是否是一个有效的URL,如果提供了protocol,host等,则该URL还需满足提供的条件 |
4.4 使用hibernate-validator进行校验
第一步:修改GoodsTypeDto,为name和status属性加入hibernate-validator注解进行数据校验
/**
* 货物类型名称
*/
@ApiModelProperty("物品类型名称")
@NotNull
private String name;
/**
* 状态 0:禁用 1:正常
*/
@ApiModelProperty("状态 0:禁用 1:正常")
@NotNull
@Max(value = 1)
@Min(value = 0)
private Integer status;
第二步:修改GoodsTypeController,开启校验
/**
* 添加货物类型
*
* @param dto 货物类型信息
* @return 货物类型信息
*/
@PostMapping("")
public GoodsTypeDto saveGoodsType(@Validated @RequestBody GoodsTypeDto dto)
...
5. 导入基础数据服务其他代码
直接导入资料中提供的基础数据服务其他模块代码即可,代码位置:资料\\基础数据服务(pd-base)代码导入
Java物流项目第五天 数据聚合服务开发(pd-aggregation)
品达物流TMS项目
第6章 数据聚合服务开发(pd-aggregation)
1. Canal概述
canal译意为水道/管道,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。

1.1 背景
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
1.2 工作原理
MySQL主从复制原理
-
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events)
-
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
-
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
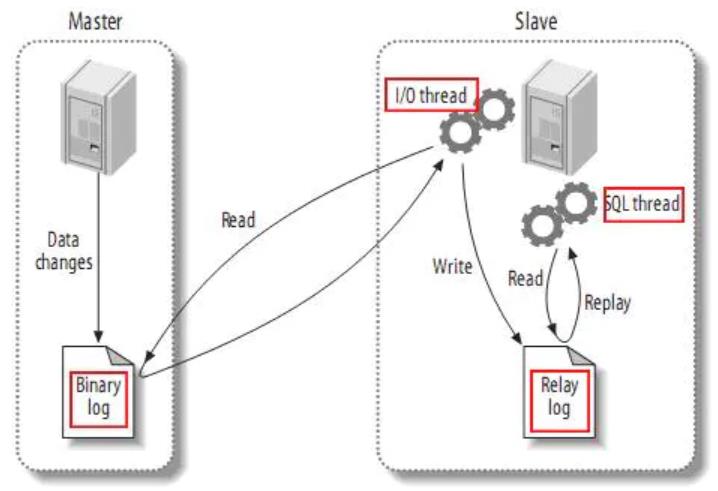
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)

1.3 架构

说明:
- server 代表一个canal服务,管理多个instance
- instance 伪装成一个slave,从mysql dump数据
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
1.4 HA机制设计
canal的高可用HA(High Availability)
- 为了减少对mysql dump的请求,要求同一时间只能有一个处于running,其他的处于standby状态
如下图所示:
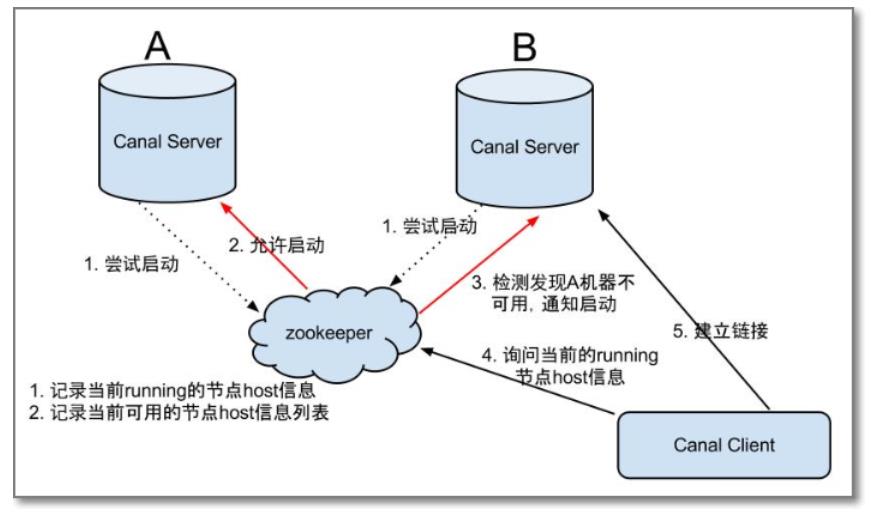
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建短暂的节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于备用状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行连接时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect
1.5 canal安装
- 创建mysql容器
docker run -id --name canal_mysql \\
-v /mnt/canal_mysql:/var/lib/mysql \\
-p 3306:3306 \\
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
- 安装vim
需要在MySQL容器中修改配置文件,但是容器中默认没有vim命令,需要进行安装。
直接执行命令安装vim速度会很慢,因为使用的是国外的源,需要更新Debian源以提高速度。
#在宿主机创建sources.list配置文件
vi sources.list
#内容为:
deb http://mirrors.tuna.tsinghua.edu.cn/debian/ buster main
deb http://mirrors.tuna.tsinghua.edu.cn/debian-security buster/updates main
deb http://mirrors.tuna.tsinghua.edu.cn/debian/ buster-updates main
#复制宿主机的配置到MySQL容器中
docker cp sources.list canal_mysql:/etc/apt/
#进入MySQL容器
docker exec -it canal_mysql /bin/bash
#执行安装命令
apt-get update && apt-get install vim -y
- 修改MySQL配置
需要让canal伪装成salve并正确获取mysql中的binary log,首先要开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,命令如下:
#修改MySQL配置文件
vim /etc/mysql/mysql.conf.d/mysqld.cnf
#添加的内容如下:
log-bin=mysql-bin
binlog-format=ROW
server_id=1
#开启binlog 选择ROW模式
#server_id不要和canal的slaveId重复
- 重启MySQL
docker restart canal_mysql
远程登录MySQL,查看配置状态,执行以下sql:
show variables like 'log_bin';
show variables like 'binlog_format';
show master status;
- 创建Canal账号
创建连接MySQL的账号canal并授予作为 MySQL slave 的权限,执行以下sql:
# 创建账号
CREATE USER canal IDENTIFIED BY 'canal';
# 授予权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
# 刷新并应用
FLUSH PRIVILEGES;
- 创建canal-server容器
docker run -d --name canal-server \\
-p 11111:11111 canal/canal-server:v1.1.4
- 配置canal-server
#进入canal-server容器
docker exec -it canal-server /bin/bash
#编辑canal-server的配置
vi canal-server/conf/example/instance.properties
内容如下:

- 重启canal-server
修改完成后重启canal-server,并查看日志:
#按ctrl+D退出容器,并重启容器
docker restart canal-server
#重启成功后进入容器
docker exec -it canal-server /bin/bash
#查看日志
tail -100f canal-server/logs/example/example.log
1.6 简单使用
在数据库服务中创建数据库canal_test并创建表:
CREATE TABLE `student` (
`id` varchar(20) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` varchar(5) DEFAULT NULL,
`city` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建Maven工程canal-demo,在pom.xml中添加依赖:
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
</dependencies>
编写代码获取canal数据:
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class CanalTest
public static void main(String[] args)
String ip = "39.98.107.235";
String destination = "example";
//创建连接对象
CanalConnector canalConnector = CanalConnectors.newSingleConnector(
new InetSocketAddress(ip, 11111), destination, "", ""
);
//进行连接
canalConnector.connect();
//进行订阅
canalConnector.subscribe();
int batchSize = 5 * 1024;
//使用死循环不断的获取canal信息
while (true)
//获取Message对象
Message message = canalConnector.getWithoutAck(batchSize);
long id = message.getId();
int size = message.getEntries().size();
System.out.println("当前监控到的binLog消息数量是:" + size);
//判断是否有数据
if (id == -1 || size == 0)
//如果没有数据,等待1秒
try
TimeUnit.SECONDS.sleep(1);
catch (InterruptedException e)
e.printStackTrace();
else
//如果有数据,进行数据解析
List<Entry> entries = message.getEntries();
//遍历获取到的Entry集合
for (Entry entry : entries)
System.out.println("----------------------------------------");
System.out.println("当前的二进制日志的条目(entry)类型是:" + entry.getEntryType());
//如果属于原始数据ROWDATA,进行打印内容
if (entry.getEntryType() == EntryType.ROWDATA)
try
//获取存储的内容
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
//打印事件的类型,增删改查哪种 eventType
System.out.println("事件类型是:" + rowChange.getEventType());
//打印改变的内容(增量数据)
for (RowData rowData : rowChange.getRowDatasList())
System.out.println("改变前的数据:" + rowData.getBeforeColumnsList());
System.out.println("改变后的数据:" + rowData.getAfterColumnsList());
catch (Exception e)
e.printStackTrace();
//消息确认已经处理了
canalConnector.ack(id);
数据对象格式:
Entry
Header
version [协议的版本号,default = 1]
logfileName [binlog文件名]
logfileOffset [binlog position]
serverId [服务端serverId]
serverenCode [变更数据的编码]
executeTime [变更数据的执行时间]
sourceType [变更数据的来源,default = MYSQL]
schemaName [变更数据的schemaname]
tableName [变更数据的tablename]
eventLength [每个event的长度]
eventType [insert/update/delete类型,default = UPDATE]
props [预留扩展]
gtid [当前事务的gitd]
entryType [事务头BEGIN/事务尾END/数据ROWDATA/HEARTBEAT/GTIDLOG]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
tableId [tableId,由数据库产生]
eventType [数据变更类型,default = UPDATE]
isDdl [标识是否是ddl语句,比如create table/drop table]
sql [ddl/query的sql语句]
rowDatas [insert/update/delete的变更数据,可为多条,event可对应多条变更,如批处理]
beforeColumns [字段信息,增量数据(修改前,删除前),Column类型的数组]
afterColumns [字段信息,增量数据(修改后,新增后),Column类型的数组]
props [预留扩展]
props [预留扩展]
ddlSchemaName [ddl/query的schemaName,会存在跨库ddl,需要保留执行ddl的当前schemaName]
Column
index [字段下标]
sqlType [jdbc type]
name [字段名称(忽略大小写),在mysql中是没有的]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
props [预留扩展]
value [字段值,timestamp,Datetime是一个时间格式的文本]
length [对应数据对象原始长度]
mysqlType [字段mysql类型]
2. Otter概述
2.1 介绍
Otter底层依赖Canal接收和解析mysql binlog日志,提供了可配置化的同步机制,纯java开发,免费开源的,基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库,是一个分布式数据同步系统。
典型的应用场景:
- 异构库同步
a. mysql -> mysql/oracle. (目前开源版只支持mysql增量,目标库可以是mysql或oracle,取决于canal的功能)
- 单机房同步 (数据库之间RTT < 1ms, RTT: 往返延迟)
a. 数据库版本升级
b. 数据表迁移
c. 异步二级索引
- 异地机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同步,RTT > 200ms)
a. 机房容灾
- 双向同步
a. 避免回环算法 (通用的解决方案,支持大部分关系型数据库)
b. 数据一致性算法 (保证双A机房模式下,数据保证最终一致性)
- 文件同步
a. 站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片).
例如: 账户信息表和账户交易明细表,更新账户余额后需要登记一条账户明细,用户可以通过交易明细表查看交易记录,但是交易明细表的数据量是逐步递增的,用户量多的系统,几个月下来的数据超过千万了,表数据量一多就导致查询和插入变慢,通过otter可以将记录同步到历史表,并且进行分表处理,用户往年的交易记录就可以查询历史表了,而原交易明细表就可以删除一个月甚至几天前的数据;
2.2 架构
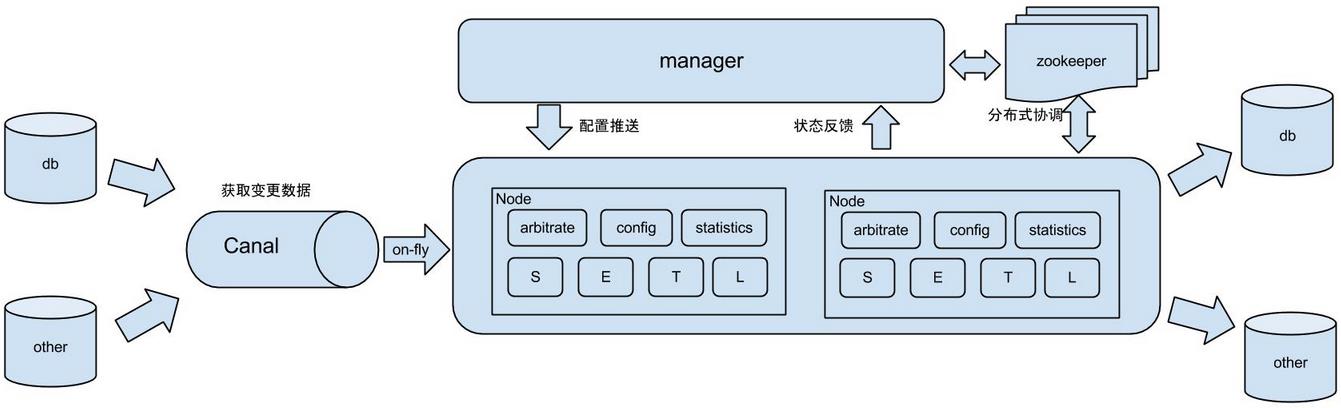
说明:
- db : 数据源以及需要同步到的库
- Canal : 获取数据库增量日志,canal支持独立部署和内嵌使用两种模式。otter使用canal的内嵌方法获取数据库增量日志
- manager : 配置同步规则设置数据源同步源等
- zookeeper : 协调node进行协调工作
- node : 负责任务处理,即根据任务配置对数据源进行解析并同步到目标数据库的操作。
原理描述:
基于Canal的开源产品,获取数据库增量日志数据。典型管理系统架构:manager(web管理)+node(工作节点)
- manager运行时推送同步配置到node节点
- node节点将同步状态反馈到manager上
- 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作
单机房复制示意图:
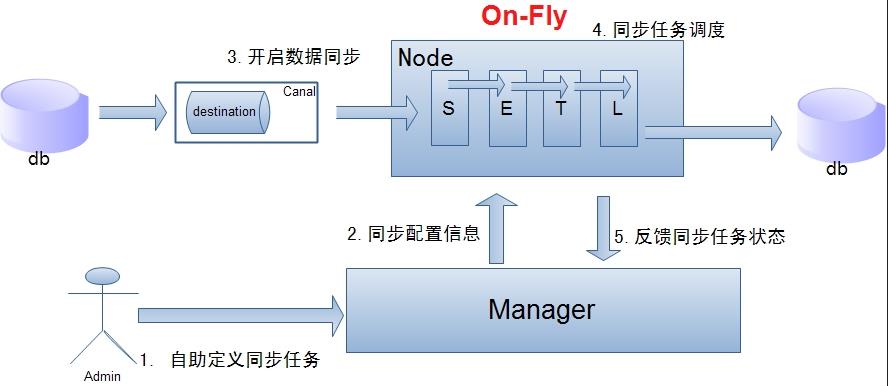
说明:
- 数据on-Fly,尽可能不落地,更快的进行数据同步.
- node节点可以有failover / loadBalancer.
跨机房复制示意图:
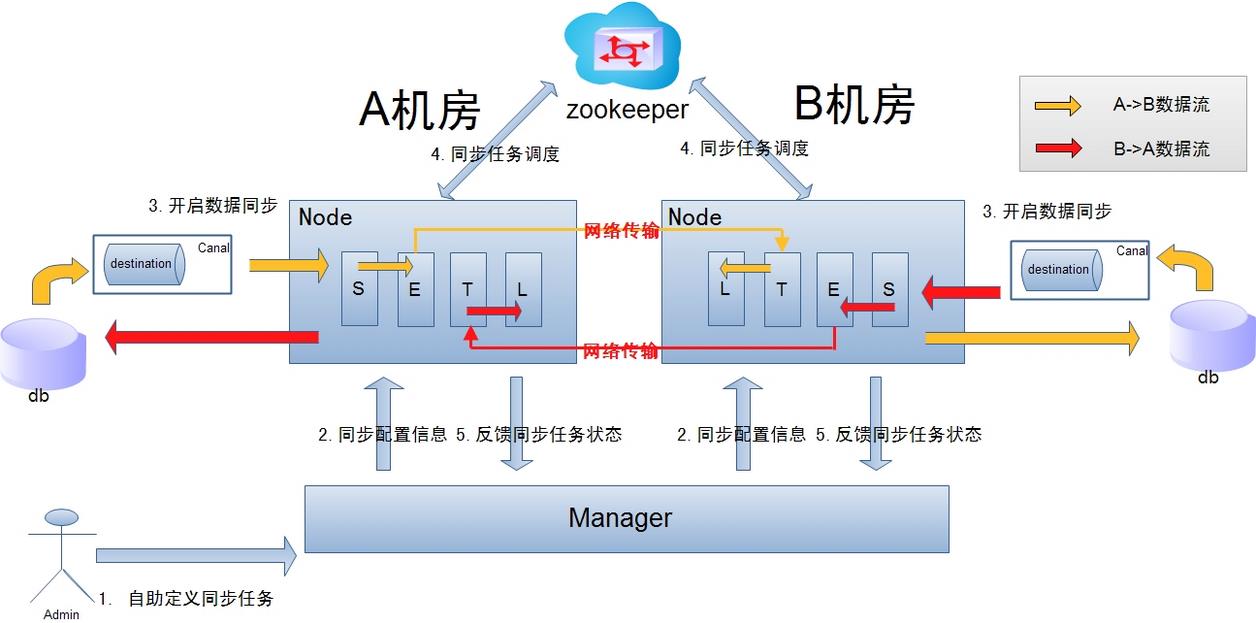
说明:
- 数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 (一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node)
- node节点可以有failover / loadBalancer. (每个机房的Node节点,都可以是集群,一台或者多台机器)
3. Otter安装配置
3.1 依赖环境安装
环境使用: CentOS 7.6
3.1.1 jdk安装
安装:
# 解压命令
tar -zxf jdk-8u191-linux-x64.tar.gz -C /usr/local/
# 修改配置命令
vi /etc/profile
# 添加内容:
export JAVA_HOME=/usr/local/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
# 配置生效命令
source /etc/profile
#查看java版本命令
java -version
3.1.2 docker安装
卸载旧版本:
yum remove docker \\
docker-client \\
docker-client-latest \\
docker-common \\
docker-latest \\
docker-latest-logrotate \\
docker-logrotate \\
docker-engine
使用 Docker 仓库进行安装,设置仓库:
yum install -y yum-utils \\
device-mapper-persistent-data lvm2
设置稳定的仓库:
yum-config-manager --add-repo \\
https://download.docker.com/linux/centos/docker-ce.repo
安装Docker:
#安装
yum install docker-ce docker-ce-cli containerd.io
#启动
systemctl start docker
#设置开机启动
systemctl enable docker
#安装好后,可以查看docker的版本
docker -v
3.2 MySQL安装
使用otter进行数据同步时,有三类数据库:
- 源数据库
- 目标数据库
- otter配置数据库
3.2.1 创建源数据库
在两个服务器上分别创建两个数据库,一个作为源库,一个作为目标库。
在服务器A上,使用docker创建otter的源库
cd /mnt
#创建目录,用于存放MySQL源库所需配置文件和数据,后续启动MySQL容器时需要进行目录映射
mkdir mysql_src
cd mysql_src
#conf目录用于存放MySQL数据库配置文件,data用于存放数据
mkdir conf data
cd conf
#创建MySQL数据库配置文件
vim docker.cnf
#文件内容
[mysqld]
server_id=1
character-set-server=utf8
collation-server=utf8_general_ci
binlog_format=row
log-bin=mysql-bin
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动MySQL容器
docker run -id --name otter_mysql1 \\
-v /mnt/mysql_src/data:/var/lib/mysql \\
-v /mnt/mysql_src/conf:/etc/mysql/conf.d \\
-p 3306:3306 \\
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
3.2.2 创建目标数据库
在服务器B上,使用docker创建otter的目标库,同时也作为otter的配置数据库
cd /mnt
#创建目录,用于存放MySQL目标库所需配置文件和数据,后续启动MySQL容器时需要进行目录映射
mkdir mysql_dest
cd mysql_dest
#conf目录用于存放MySQL数据库配置文件,data用于存放数据
mkdir conf data
cd conf
#创建MySQL数据库配置文件
vim docker.cnf
#文件内容
[mysqld]
server_id=2
character-set-server=utf8
collation-server=utf8_general_ci
binlog_format=row
log-bin=mysql-bin
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动MySQL容器
docker run -id --name otter_mysql2 \\
-v /mnt/mysql_dest/data:/var/lib/mysql \\
-v /mnt/mysql_dest/conf:/etc/mysql/conf.d \\
-p 3306:3306 \\
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
mysql源数据库的binlog必须配置成row,才能够进行数据同步:
-- 必须开启log-bin二进制日志
show variables like 'log_bin';
-- binlong 格式必须是row,以下命令查看当前数据库binlog方式:
show variables like 'binlog_format';
-- 必须有server_id,该参数跟数据库复制有关,详情看官网
show variables like 'server_id';
-- 字符集character_set_server 必须是utf8,否则配置数据源表验证不通过。
show variables like 'character_set_server';
3.2.3 初始化Otter配置数据库
cd /mnt
#创建目录,用于存放MySQL目标库所需配置文件和数据,后续启动MySQL容器时需要进行目录映射
mkdir mysql_otter
cd mysql_otter
#conf目录用于存放MySQL数据库配置文件,data用于存放数据
mkdir conf data
cd conf
#创建MySQL数据库配置文件
vim docker.cnf
#文件内容
[mysqld]
server_id=3
character-set-server=utf8
collation-server=utf8_general_ci
binlog_format=row
log-bin=mysql-bin
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#启动MySQL容器
docker run -id --name otter_mysql \\
-v /mnt/mysql_otter/data:/var/lib/mysql \\
-v /mnt/mysql_otter/conf:/etc/mysql/conf.d \\
-p 3306:3306 \\
-e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
在准备安装Otter的服务器的MySQL中执行以下SQL,创建名称为otter的数据库
create database otter DEFAULT CHARACTER SET utf8;
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON `otter`.* TO 'canal'@'%';
flush PRIVILEGES;
在otter数据库中创建表
# 下载otter数据库文件
wget https://github.com/alibaba/otter/blob/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
# 在mysql命令行中执行sql脚本进行建表
source /opt/otter/manager/otter-manager-schema.sql;
3.3 zookeeper安装
3.3.1 单机版安装
#启动容器:
docker run -id --name my_zookeeper -p 2181:2181 zookeeper:3.4.14
#查看容器运行情况:
docker logs -f my_zookeeper
使用客户端连接zookeeper:
docker run -it --rm --link my_zookeeper:zk zookeeper:3.4.14 zkCli.sh -server zk
3.3.2 集群版安装
一个一个的启动 ZK 很麻烦,这里直接使用 docker-compose 来启动 ZK 集群。
Docker Compose安装:
下载 Docker Compose 的当前稳定版本:
#安装pip
yum -y install epel-release python-pip
#升级pip
pip install --upgrade pip
pip install --upgrade setuptools --upgrade requests
#查看pip版本
pip -V
#使用pip安装Docker Compose
pip install docker-compose
测试是否安装成功:
docker-compose --version
删除docker-compose
pip uninstall docker-compose -y
首先创建一个名为 docker-compose.yml 的文件:
mkdir ~/zk_cluster
cd ~/zk_cluster
vi docker-compose.yml
docker-compose.yml 内容如下:
version: '3.8'
services:
zk01:
image: zookeeper:3.4.14
restart: always
container_name: zk01
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk01:2888:3888 server.2=zk02:2888:3888 server.3=zk03:2888:3888
zk02:
image: zookeeper:3.4.14
restart: always
container_name: zk02
ports:
- "2182:2181"
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk01:2888:3888 server.2=zk02:2888:3888 server.3=zk03:2888:3888
zk03:
image: zookeeper:3.4.14
restart: always
container_name: zk03
ports:
- "2183:2181"
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk01:2888:3888 server.2=zk02:2888:3888 server.3=zk03:2888:3888
注意Compose文件的版本,需要符合以下要求:
| Compose file format | Docker Engine release |
|---|---|
| 3.8 | 19.03.0+ |
| 3.7 | 18.06.0+ |
| 3.6 | 18.02.0+ |
| 3.5 | 17.12.0+ |
| 3.4 | 17.09.0+ |
| 3.3 | 17.06.0+ |
| 3.2 | 17.04.0+ |
| 3.1 | 1.13.1+ |
| 3 | 1.13.0+ |
| 2.4 | 17.12.0+ |
| 2.3 | 17.06.0+ |
| 2.2 | 1.13.0+ |
| 2.1 | 1.12.0+ |
| 2 | 1.10.0+ |
| 1 | 1.9.1.+ |
在 docker-compose.yml 当前目录下运行命令:
#校验docker-compose.yml
docker-compose config
#启动zookeeper集群
COMPOSE_PROJECT_NAME=zk_otter docker-compose up -d
查看启动的 ZK 容器,运行以下命令:
COMPOSE_PROJECT_NAME=zk_otter docker-compose ps

COMPOSE_PROJECT_NAME=zk_test 这个环境变量, 这是为我们的 compose 工程起一个名字, 以免与其他的 compose 混淆.
依次执行命令:
docker exec zk01 /bin/bash -c 'bin/zkServer.sh status'
docker exec zk02 /bin/bash -c 'bin/zkServer.sh status'
docker exec zk03 /bin/bash -c 'bin/zkServer.sh status'
可以看到一个主,两个从,集群搭建完成
集群连接:
查看Networks名称
docker inspect -f '.NetworkSettings.Networks' zk01
根据Networks名称连接集群:
docker run -it --rm \\
--link zk01:zk1 \\
--link zk02:zk2 \\
--link zk03:zk3 \\
--net zk_otter_default \\
zookeeper:3.4.14 zkCli.sh -server zk1:2181,zk2:2181,zk3:2181
3.4 aria2安装
aria2是一个多线程下载工具,运行otter需要aria2的支持
yum -y install epel-release aria2
3.5 Otter manager
3.5.1 安装
https://github.com/alibaba/otter/releases
mkdir /opt/otter
cd /opt/otter
# 将文件下载到/opt/otter目录
wget https://github.com/alibaba/otter/releases/download/otter-4.2.18/manager.deployer-4.2.18.tar.gz
wget https://github.com/alibaba/otter/releases/download/otter-4.2.18/node.deployer-4.2.18.tar.gz
# 解压manager
mkdir manager
tar -zxf manager.deployer-4.2.18.tar.gz -C manager
修改otter manager配置文件:
# 修改mysql数据库和zookeeper配置信息
vim /opt/otter/manager/conf/otter.properties
# 主要配置四个方面: 服务端口、数据库、zookeeper、邮箱
# 其他方面使用默认配置即可 修改内容如下:
## otter manager 域名/ip地址
otter.domainName = 更改成服务器ip或域名
## otter manager database config
otter.database.driver.class.name = com.mysql.jdbc.Driver
otter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otter?autoReconnect=true&useSSL=false
otter.database.driver.username = 更改成你的用户名
otter.database.driver.password = 更改成你的密码
启动otter manager:
/opt/otter/manager/bin/startup.sh
查看日志:
tail -500f /opt/otter/manager/logs/manager.log
用浏览器打开: http://otter主机ip:8080/
默认密码:admin/admin
3.5.2 配置
Manager启动后,需要配置zookeeper和node
3.5.2.1 配置zookeeper


3.5.2.2 配置node
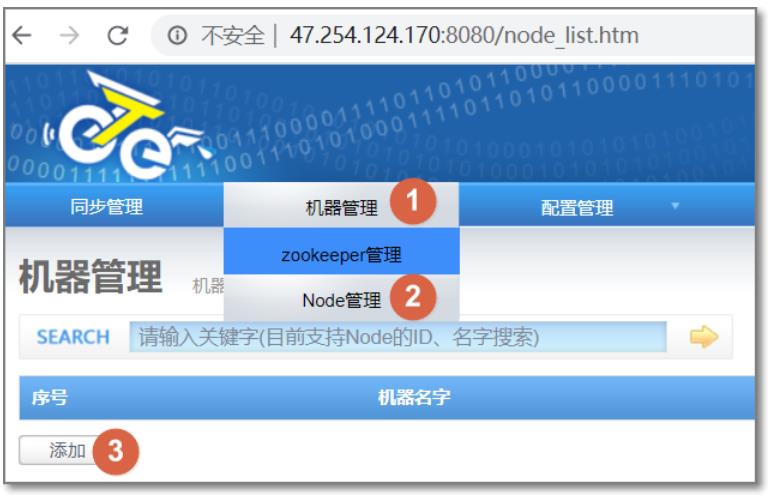

- 机器名称:可以随意定义,方便记忆即可
- 机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
- 机器端口:对应node节点将要部署时启动的数据通讯端口
- 下载端口:对应node节点将要部署时启动的数据下载端口
- 外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理
- zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群
- node这种设计,是为解决单机部署多实例而设计的,允许单机多node指定不同的端口
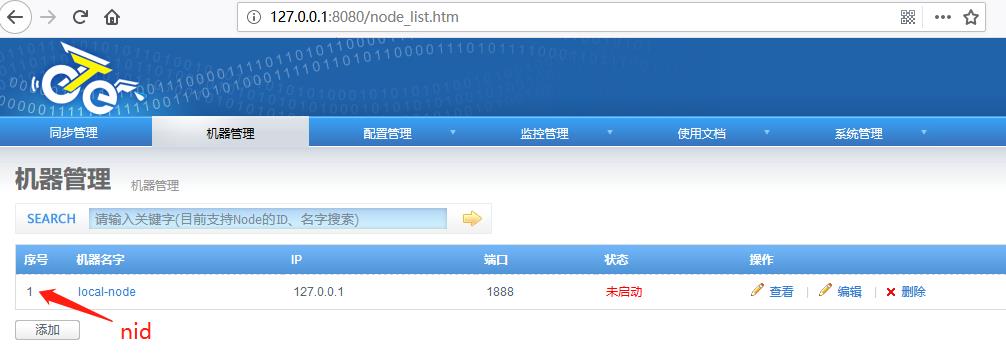
端口默认即可,添加完node后,列表中第一列是nid(此id要保存到node/conf/nid文件中的值):
3.5.3 说明
Otter Manager简化了一些admin管理上的操作成本,比如可以通过manager发布同步任务配置,接收同步任务反馈的状态信息等。
同步配置管理
- 添加数据源
- canal解析配置
- 添加数据表
- 同步任务
同步状态查询
- 查询延迟
- 查询吞吐量
- 查询同步进度
- 查询报警&异常日志
用户权限
- ADMIN : 超级管理员
- OPERATOR : 普通用户,管理某个同步任务下的同步配置,添加数据表,修改canal配置等
- ANONYMOUS : 匿名用户,只能进行同步状态查询的操作.
3.6 Otter node
# 解压到node目录中
cd /opt/otter/
mkdir node
tar -zxf node.deployer-4.2.18.tar.gz -C node/
# 添加nid(在manager中添加的node节点的nid)
cd /opt/otter/node/conf/
echo 1 > nid
node/conf/otter.properties这个文件是node节点的配置文件,使用默认配置即可:
# otter node root dir
otter.nodeHome = $user.dir/../
## otter node dir
otter.htdocs.dir = $otter.nodeHome/htdocs
otter.download.dir = $otter.nodeHome/download
otter.extend.dir= $otter.nodeHome/extend
## default zookeeper sesstion timeout = 60s
otter.zookeeper.sessionTimeout = 60000
## otter communication payload size (default = 8388608)
otter.communication.payload = 8388608
## otter communication pool size
otter.communication.pool.size = 10
## otter arbitrate & node connect manager config
otter.manager.address = 127.0.0.1:1099
启动node:
/opt/otter/node/bin/startup.sh
查看日志:
tail -500f /opt/otter/node/logs/node/node.log
此时从manager上可以看到node节点已启动:

我们可以通过这种方式添加多个node节点。
此时otter manager和node节点都启动了,我们可以开始配置数据同步了。
4. 设置同步任务
在源数据库和目标数据库中都需要创建数据库otter_test,并执行以下建表语句:
DROP TABLE IF EXISTS `tb_item`;
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',
`title` varchar(100) NOT NULL COMMENT '商品标题',
`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',
`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',
`image` varchar(500) DEFAULT NULL COMMENT '商品图片',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',
`created` datetime NOT NULL COMMENT '创建时间',
`updated` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
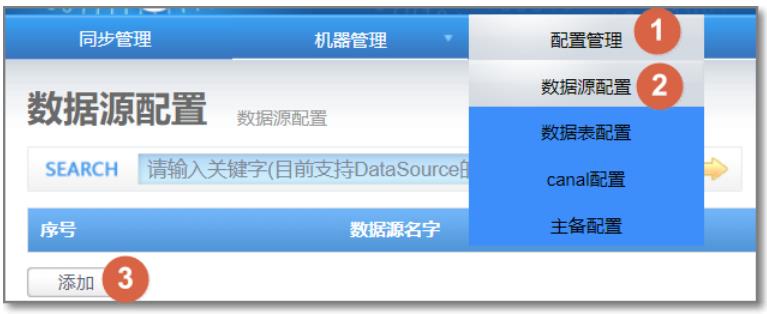
4.1 数据源配置
配置源数据库:

配置目标数据库:

添加完成:
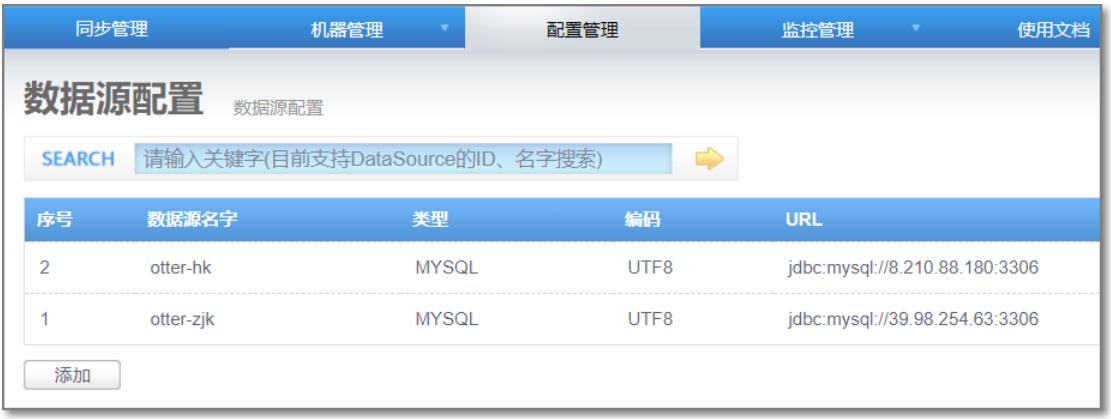
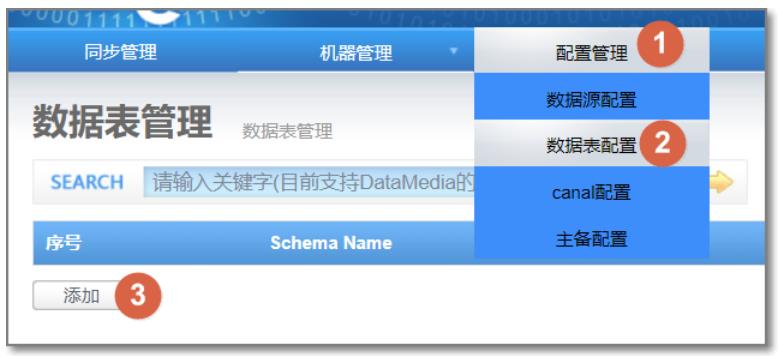
4.2 数据表配置
添加源数据库表和目标数据库表
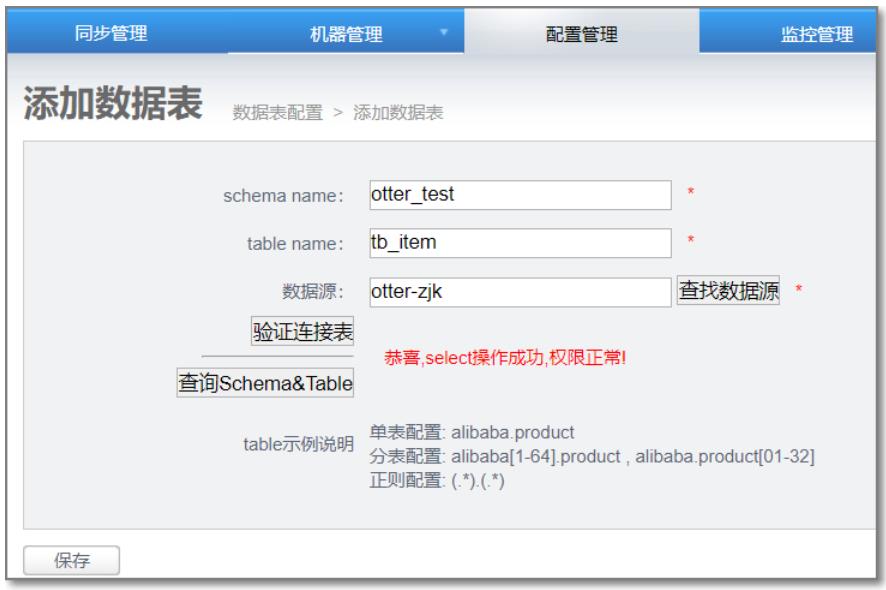
4.3 添加canal

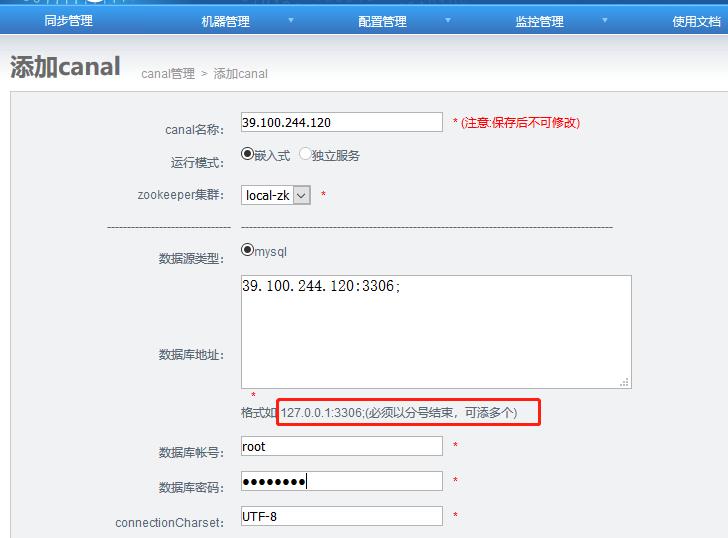

1. 数据库地址:指源库的ip和端口
2. connectionCharset ==> 获取binlog时指定的编码
3. 位点自定义设置 ==> 格式:“journalName”:"",“position”:0,“timestamp”:0;
指定位置:“journalName”:"",“position”:0;
指定时间:“timestamp”:0;
4. 内存存储batch获取模式 ==> MEMSIZE/ITEMSIZE,前者为内存控制,后者为数量控制. 针对MEMSIZE模式的内存大小计算 = 记录数 * 记录单元大小
内存存储buffer记录数
内存存储buffer记录单元大小
5. 心跳SQL配置 ==> 可配置对应心跳SQL,如果配置 是否启用心跳HA,当心跳SQL检测失败后,canal就会自动进行主备切换.
4.4 添加channel
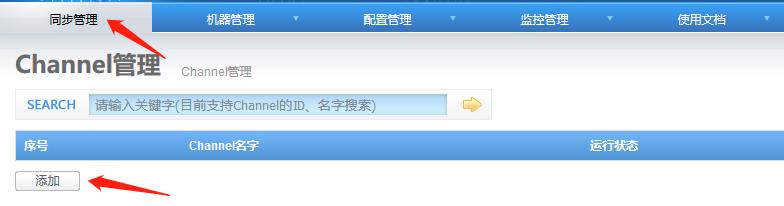

行记录模式:如果目标库中不存在记录时,执行插入。
列记录模式:变更哪个字段就同步哪个字段,在双A同步时,为减少数据冲突,建议使用此选项。(双A只的是双主、且会同时修改同一条记录)
4.5 添加pipeline

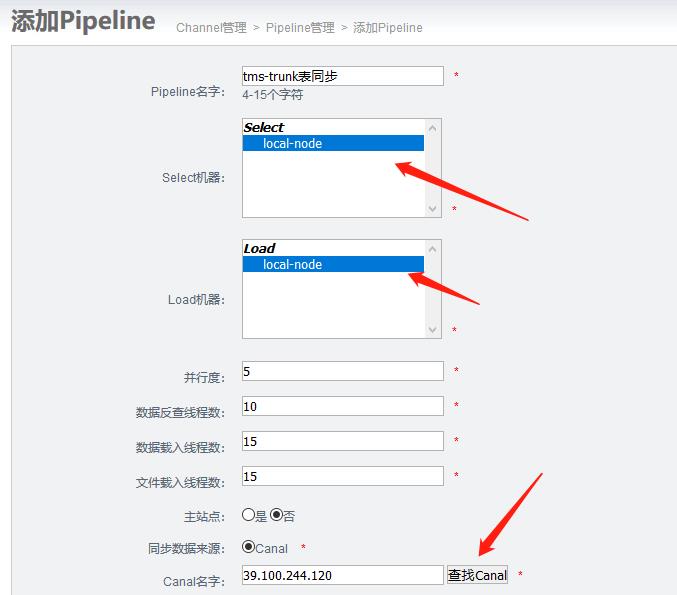
pipeline参数
- 并行度. ==> 查看文档:Otter调度模型,主要是并行化调度参数.(滑动窗口大小)
- 数据反查线程数. ==> 如果选择了同步一致性为反查数据库,在反查数据库时的并发线程数大小
- 数据载入线程数. ==> 在目标库执行并行载入算法时并发线程数大小
- 文件载入线程数. ==> 数据带文件同步时处理的并发线程数大小
- 主站点. ==> 双A同步中的主站点设置
- 消费批次大小. ==> 获取canal数据的batchSize参数
- 获取批次超时时间. ==> 获取canal数据的timeout参数
pipeline 高级设置
- 使用batch. ==> 是否使用jdbc batch提升效率,部分分布式数据库系统不一定支持batch协议
- 跳过load异常. ==> 比如同步时出现目标库主键冲突,开启该参数后,可跳过数据库执行异常
- 仲裁器调度模式. ==> 查看文档:Otter调度模型
- 负载均衡算法. ==> 查看文档:Otter调度模型
- 传输模式. ==> 多个node节点之间的传输方式,RPC或HTTP. HTTP主要就是使用aria2c,如果测试环境不装aria2c,可强制选择为RPC
- 记录selector日志. ==> 是否记录简单的canal抓取binlog的情况
- 记录selector详细日志. ==> 是否记录canal抓取binlog的数据详细内容
- 记录load日志. ==> 是否记录otter同步数据详细内容
- dryRun模式. ==> 只记录load日志,不执行真实同步到数据库的操作
- 支持ddl同步. ==> 是否同步ddl语句
- 是否跳过ddl异常. ==> 同步ddl出错时,是否自动跳过
- 文件重复同步对比 ==> 数据带文件同步时,是否需要对比源和目标库的文件信息,如果文件无变化,则不同步,减少网络传输量.
- 文件传输加密 ==> 基于HTTP协议传输时,对应文件数据是否需要做加密处理
- 启用公网同步 ==> 每个node节点都会定义一个外部ip信息,如果启用公网同步,同步时数据传递会依赖外部ip.
- 跳过自由门数据 ==> 自定义数据同步的内容
- 跳过反查无记录数据 ==> 反查记录不存在时,是否需要进行忽略处理,不建议开启.
- 启用数据表类型转化 ==> 源库和目标库的字段类型不匹配时,开启改功能,可自动进行字段类型转化
- 兼容字段新增同步 ==> 同步过程中,源库新增了一个字段(必须无默认值),而目标库还未增加,是否需要兼容处理
- 自定义同步标记 ==> 级联同步中屏蔽同步的功能.
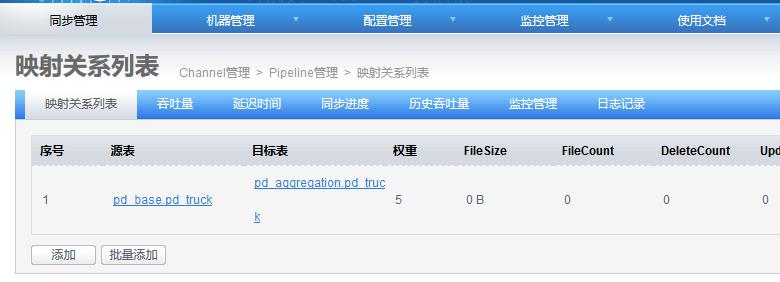
4.6 添加映射关系表
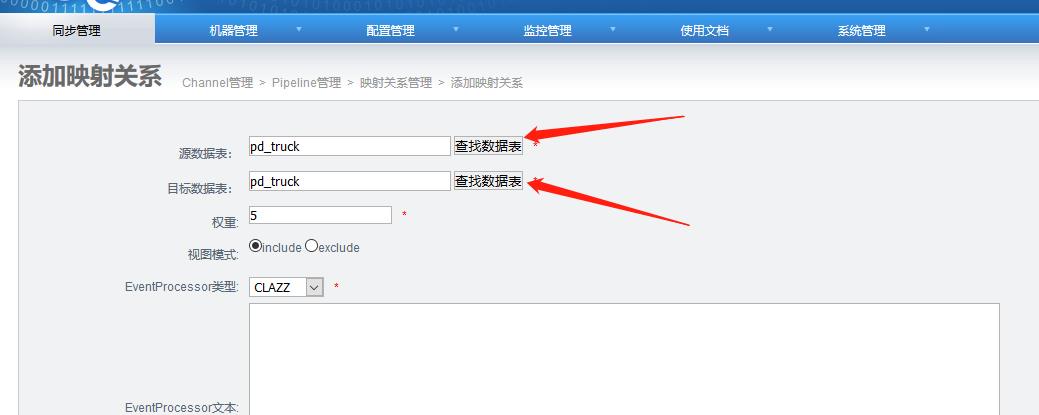
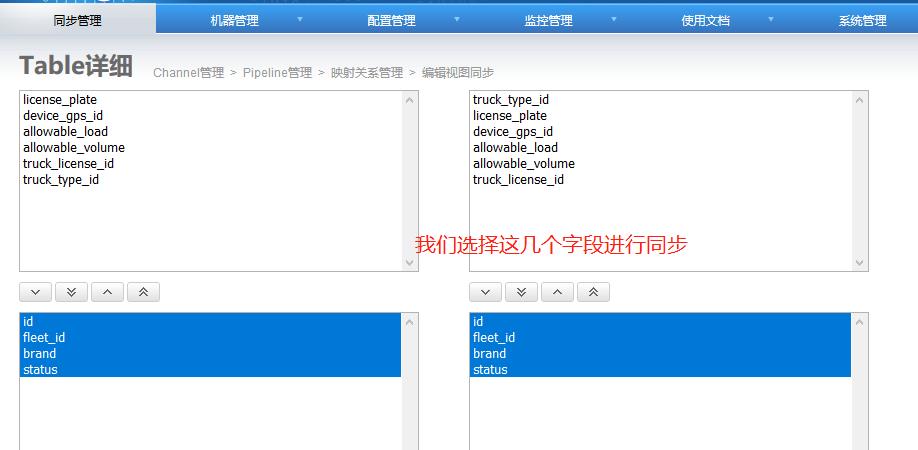
添加完成:
4.7 测试验证
启动channel
在源表中插入条记录,数据同步到目标表中。
5. 数据聚合服务介绍
. ==> 查看文档:Otter调度模型
5. 传输模式. ==> 多个node节点之间的传输方式,RPC或HTTP. HTTP主要就是使用aria2c,如果测试环境不装aria2c,可强制选择为RPC
6. 记录selector日志. ==> 是否记录简单的canal抓取binlog的情况
7. 记录selector详细日志. ==> 是否记录canal抓取binlog的数据详细内容
8. 记录load日志. ==> 是否记录otter同步数据详细内容
9. dryRun模式. ==> 只记录load日志,不执行真实同步到数据库的操作
10. 支持ddl同步. ==> 是否同步ddl语句
11. 是否跳过ddl异常. ==> 同步ddl出错时,是否自动跳过
12. 文件重复同步对比 ==> 数据带文件同步时,是否需要对比源和目标库的文件信息,如果文件无变化,则不同步,减少网络传输量.
13. 文件传输加密 ==> 基于HTTP协议传输时,对应文件数据是否需要做加密处理
14. 启用公网同步 ==> 每个node节点都会定义一个外部ip信息,如果启用公网同步,同步时数据传递会依赖外部ip.
15. 跳过自由门数据 ==> 自定义数据同步的内容
16. 跳过反查无记录数据 ==> 反查记录不存在时,是否需要进行忽略处理,不建议开启.
17. 启用数据表类型转化 ==> 源库和目标库的字段类型不匹配时,开启改功能,可自动进行字段类型转化
18. 兼容字段新增同步 ==> 同步过程中,源库新增了一个字段(必须无默认值),而目标库还未增加,是否需要兼容处理
19. 自定义同步标记 ==> 级联同步中屏蔽同步的功能.
4.6 添加映射关系表
[外链图片转存中…(img-YbkqG5RW-1650435876180)]
[外链图片转存中…(img-DfWviEHx-1650435876181)]
[外链图片转存中…(img-yonXqBrh-1650435876182)]
[外链图片转存中…(img-EDD5z6yy-1650435876184)]
添加完成:
[外链图片转存中…(img-KdOzQ5Ez-1650435876185)]
4.7 测试验证
启动channel
[外链图片转存中…(img-EDzSAi31-1650435876186)]
在源表中插入条记录,数据同步到目标表中。
5. 数据聚合服务介绍
数据聚合微服务,对应的maven工程为pd-aggregation。数据聚合微服务提供TMS中各种作业、单据、任务的集中查询功能。数据聚合服务对应操作的数据库为pd_aggregation,库中的表和数据都是通过otter从其他库同步过来的。
以上是关于Java物流项目第一天 项目概述与基础数据服务开发的主要内容,如果未能解决你的问题,请参考以下文章