SqueezeNet模型参数降低50倍,压缩461倍
Posted deep_learninger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SqueezeNet模型参数降低50倍,压缩461倍相关的知识,希望对你有一定的参考价值。
DenseNet
CNN网络从Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning,FractalNet,DenseNet 。网络越来越深,越来越宽。参数越来越大。12G的显存都不够。在保存精度的同时,尽量减少参数很重要。这里有很多方法,模型剪枝等,这里从网络设计上介绍。
本文讲一下最新由UC Berkeley和Stanford研究人员一起完成的SqueezeNet[1]网络结构和设计思想。SqueezeNet设计目标不是为了得到最佳的CNN识别精度,而是希望简化网络复杂度,同时达到public网络的识别精度。所以SqueezeNet主要是为了降低CNN模型参数数量而设计的。OK,下面直奔主题了。
设计原则
(1)替换3x3的卷积kernel为1x1的卷积kernel
卷积模板的选择,从12年的AlexNet模型一路发展到2015年底Deep Residual Learning模型,基本上卷积大小都选择在3x3了,因为其有效性,以及设计简洁性。本文替换3x3的卷积kernel为1x1的卷积kernel可以让参数缩小9X。但是为了不影响识别精度,并不是全部替换,而是一部分用3x3,一部分用1x1。具体可以看后面的模块结构图。
(2)减少输入3x3卷积的input feature map数量
如果是conv1-conv2这样的直连,那么实际上是没有办法减少conv2的input feature map数量的。所以作者巧妙地把原本一层conv分解为两层,并且封装为一个Fire Module。
(3)减少pooling
这个观点在很多其他工作中都已经有体现了,比如GoogleNet以及Deep Residual Learning。
Fire Module
Fire Module是本文的核心构件,思想非常简单,就是将原来简单的一层conv层变成两层:squeeze层+expand层,各自带上Relu激活层。在squeeze层里面全是1x1的卷积kernel,数量记为S11;在expand层里面有1x1和3x3的卷积kernel,数量分别记为E11和E33,要求S11 < (E11+E33)即满足上面的设计原则(2)。expand层之后将1x1和3x3的卷积output feature maps在channel维度拼接起来。

总体网络架构
直接上图说(左边的狗狗很忧伤啊):

看图就很明朗了,总共有9层fire module,中间穿插一些max pooling,最后是global avg pooling代替了fc层(参数大大减少)。在开始和最后还有两层最简单的单层conv层,保证输入输出大小可掌握。
下图是更详细的说明:非常清楚,就不再啰嗦了。
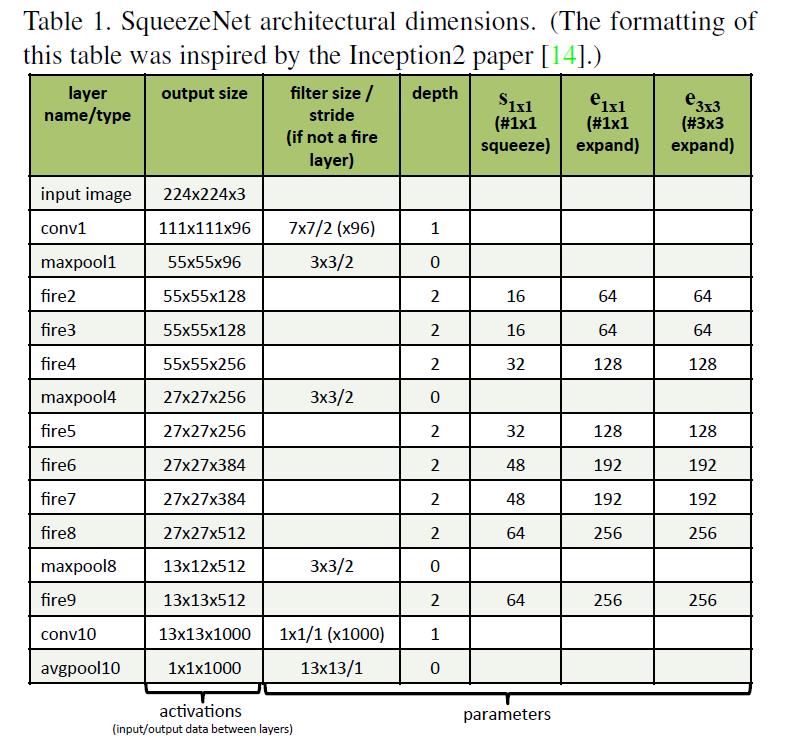
实验结果
主要在imagenet数据上比较了alexnet,可以看到准确率差不多的情况下,squeezeNet模型参数数量显著降低了(下表倒数第三行),参数减少50X;如果再加上deep compression技术,压缩比可以达到461X!还是不错的结果。不过有一点,用deep compression[2]是有解压的代价的,所以计算上会增加一些开销。

思考
SqueezeNet之前我就在研究如果降低网络规模,SqueezeNet印证了小得多的网络也可以到达很好的CNN识别精度。相信以后会出现更多小网络,做到state-of-the-art的精度。好,本篇就介绍到这里,希望对大家有启发,有的话请支持一下我博客哈!~谢谢!
参考资料
[1] SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1MB model size,2016
[2] Deep compression: Compressing DNNs with pruning, trained quantization and huffman coding, 2015
以上是关于SqueezeNet模型参数降低50倍,压缩461倍的主要内容,如果未能解决你的问题,请参考以下文章