主流数据库之索引及其例子
Posted ice三分颜色
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主流数据库之索引及其例子相关的知识,希望对你有一定的参考价值。
文章目录
目录
前言
大家好,我是ice三分颜色。
个人主页:ice三分颜色的博客
本文讲了索引的相关知识,索引的概念,索引的分类,设置的基本原则,创建索引的三个方式和注意事项,索引的性能分析,删除索引等知识点。索引是重难点呀,很重要。
走过路过的小伙伴们点个赞和关注再走吧,欢迎评论区交流,努力什么时候开始都不算晚,那不如就从这篇文章开始!
大家一起成长呀!笔芯

索引
概述
概念
1.索引,是由数据库表中一列或多列组合而成的一种特殊的数据结构,利用索引可以快速查询数据库表中的特定记录信息(索引类似于字典中的目录,可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。多列索引类似于先按照一个条件,这个条件相同,那么就继续判断第二个条件,就是第二列索引以此类推)
2.索引影响数据性能,高效的索引能提高查询速度和性能。mysql默认查询是根据搜索条件进行全表扫描(从第一个到最后一个叫全表扫描),遇到匹配条件的记录就加入到结果集合当中。若涉及多表连接、查询条件复杂、数据量大的时候,没有索引扫描执行的数据量就会很大,很慢。
3.索引包含从表或视图中一个或多个列生成的键,以及映射到指定数据行的存储位置指针。(数据库中索引的形式与书的目录相似,键值就像目录中的标题,指针相当于页码。索引能像目录一样快速查找内容(表数据),不必扫描整个数据表找。)
4.索引是依赖于表建立的,提供了数据库中编排表中数据的内部方法。表的存储由两部分组成,一部分是表的数据页面,另一部分是索引页面。索引就存放在索引页面上。
5.索引一旦创建,将由数据库自动管理和维护。(例如,向表中插入、更新和删除一条记录时,数据库会自动在索引中做出相应的修改。执行查询时,查询优化器会对可用的多种数据检索方法的成本进行估计,从中选用最有效的查询计划。)
6.索引并不是越多越好,要正确认识索引的重要性和设计原则,创建合适的索引。(数据量很少的时候,没必要加索引)
在数据库中使用索引的优缺点:
优点:1.加速数据检索:索引能够以—列或多列值为基础实现快速查找数据行。2.优化查询:查询优化器依赖于索引起作用,索引能够加速连接、排序和分组等操作。3.强制实施行的唯一性:通过给列创建唯一索引,可以保证表中的数据不重复。
缺点:1.虽然索引提高了查询速度,却会降低更新表的速度,因为更新表时,MySQL不仅要保存数据,还要保存索引。2.建立索引会占用磁盘空间的索引文件。
索引分类
MySQL的索引可分为如下5类:普通索引、唯一性索引、主键索引、全文索引、空间索引。(一般来说前三种就可以了,常用的是主键索引和唯一性索引)
普通索引
普通索引(index)是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。索引的关键字是index。
唯─性索引
唯一索引(unique)列的值必须唯一,允许有空值。如果是组合索引,则列值的组合必须唯一。在一个表上可以创建多个unique索引。
主键索引
主键索引(primary key)是一种特殊的唯一索引,不允许有空值。一般是在建表的同时创建主键索引。也可通过修改表的方法增加主键,但一个表只能有一个主键索引。(一般是和实际物理顺序保持一致的)
全文索引
全文索引(fulltext)是指在定义索引的列上支持值的全文查找,允许在索引列中插入重复值和空值。该索引只对char、varchar和text类型的列编制索引,并且只能在
MylSAM存储引擎表中编制。在MySQL默认情况下,对于中文作用不大。
空间索引
空间索引(spatial)是对空间数据类型的字段建立的索引。MySQL中的空间数据类型有4种:geometry、point、linestring和polygon。空间索引只有在存储引擎MyISAM的表中创建。对于初学者来说,这类索引很少会用到。(我们存储引擎用的是innoDB)
其他分类
如果按照创建索引键值的列数分类,索引还可以分为单列索引和复合索引。
如果按照存储方式分类,可分为二叉树(B-Tree)索引和Hash索引。
索引设置的基本原则
在数据表中创建索引时,为使索引的使用效率更高,必须考虑在哪些字段上创建索引和创建什么类型的索引。原则如下:
1.一个表创建大量索引,会影响insert、update和delete语句的性能。应避免对经常更新的表创建过多的索引,要限制索引的数目。
2.若表的数据量大,对表数据的更新较少而查询较多,可以创建多个索引来提高性能。
3.经常需要排序、分组和联合操作的字段一定要建立索引,即将用于join、where判断和order by排序的字段上创建索引。
4.在视图上创建索引可以显著的提升查询性能。
5.尽量不要对数据库中含有大量重复值的字段建立索引,在这样的字段上建立索引有可能降低数据库的性能。
6.在主键上创建索引。在InnoDB中如果通过主键来访问数据效率是非常高的。每个表只能创建一个主键索引。
7.要限制索引的数目。对于不再使用或者很少使用的索引要及时删除。
创建索引
创建索引通常有3种命令方式:使用CREATE INDEX语句来创建索引、创建表时附带创建索引、通过修改表来创建索引。
使用CREATE INDEX语句建立索引
格式:CREATE [unique|fulltext|spatial] INDEX 索引的名称 ON 表名(表名的哪一列的列名1,列名2…)
例:为employee表的ename列上建立一个升序普通索引ename_index。
CREATE INDEX ename_index ON employee(ename ASC);
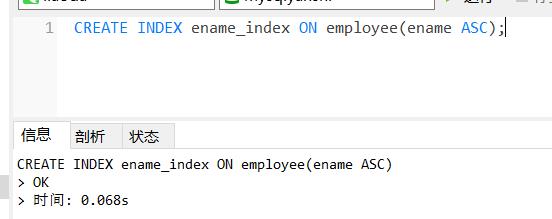
例:在employee表的ename列上建立一个唯一性索引ename_uni_index。
CREATE UNIQUE INDEX ename_uni_index ON employee(ename);

例:在employee表的empno和ename列上建立一个复合索引empno_ename_index。
CREATE INDEX empno_ename_index ON employee(empno,ename);
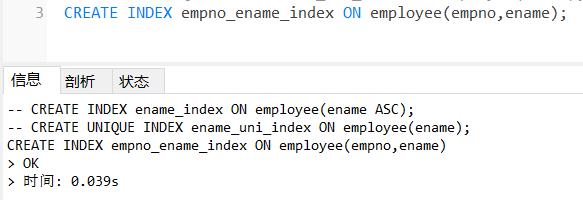
可以使用show index from table_name语句查看表中已创建的索引
SHOW INDEX FROM employee;如下

我们也可直接在navicat中employee表右键设计表处查看索引,如下
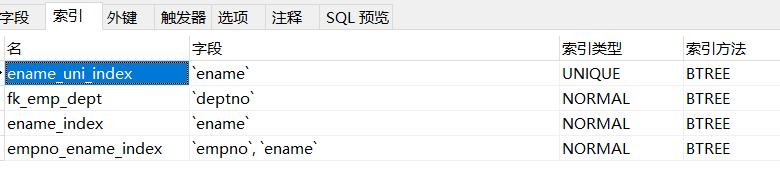
创建表时创建索引
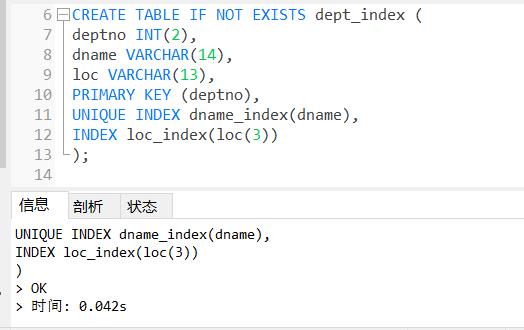
例:创建dept_index表时为dname字段建立一个唯一性索引dname_index,为loc字段的前3个字符创建一个前缀索引loc_index。
CREATE TABLE IF NOT EXISTS dept_index (
deptno INT(2),
dname VARCHAR(14),
loc VARCHAR(13),
PRIMARY KEY (deptno),
UNIQUE INDEX dname_index(dname),
INDEX loc_index(loc(3))
);
修改表时创建索引
例:在dept_index表上建立deptno和dname的复合索引。
ALTER TABLE dept_index ADD INDEX deptno_dname_index(deptno, dname);

查看dept_index表已创建的索引
Show index from dept_index;

创建索引注意事项
1.只有表的所有者才有权限给表创建索引。
2.索引的名称必须符合MySQL的命名规则,且必须是表中唯一的。(主键索引必定是唯一的,唯一性索引不一定是主键。一张表上只能一个主键,但可以有一个或者多个唯—性索引。)
3.当给表创建unique约束时,MySQL会自动创建唯一索引。创建唯一索引时,应保证创建索引的列不包括重复的数据,并且不要有两个及以上的空值(null)。因为创建索引时将两个空值也视为重复的数据,如果有这种数据,必须先将其删除,否则索引不能被成功创建。也就是说唯一索引只允许有一个空值。
索引性能分析
MySQL5.0之后自带query诊断分析工具“Show Profiles”,可以定位出一条SQL语句执行的各种资源消耗情况(如CPU,IO等),以及该SQL执行所耗费的时间。
要使用首先需要开启profile
默认数据库是不开启的,且变量profiling是用户变量,每次都要重新启用
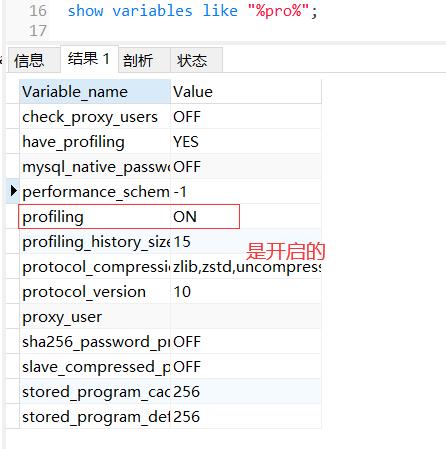
查看profile是否开启的
show variables like "%pro%";

设置开启profile
(因为查看,知道我的是开启的,所以就不需要再进行这一步)
set profiling = 1;
查看SQL执行的耗时详情
show profiles; -- 查看所有SQL的总的执行时间。
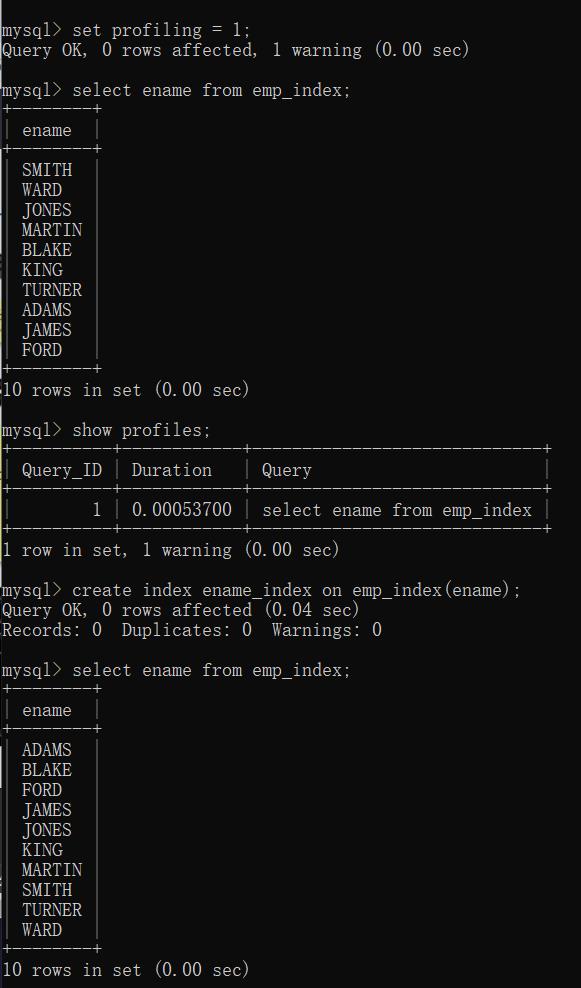
例:对员工姓名在加入索引前后进行执行时间性能分析(过程如下)
-- 通过employee表创建表emp_index
CREATE TABLE emp_index AS SELECT * FROM employee;
-- 开启profile
set profiling = 1;
-- 查询未加索引前的员工姓名
SELECT ename FROM emp_index;
-- 查看sQL的执行时间
show profiles;
-- 为ename添加索引
CREATE INDEX ename_index ON emp_index(ename);
-- 查询加索引后的员工姓名
SELECT ename FROM emp_index;
-- 查看最近一条SQL的执行时间
show profiles;
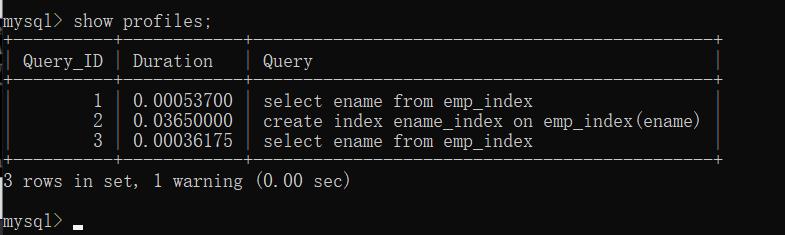
结果如下:

删除索引
删除索引是不用的索引,要及时进行更新和维护,因为索引是有上限的。可以通过DROP语句和ALTER TABLE语句删除。
利用drop index语句删除索引
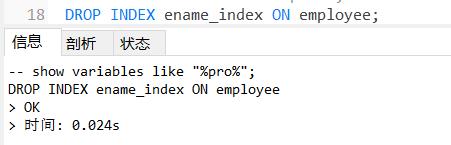
格式: DROP INDEX 索引名 ON 表名 ;
例:
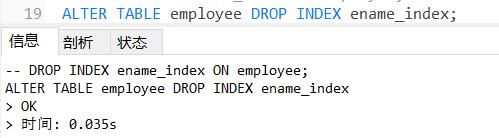
DROP INDEX ename_index ON employee;
利用alter table语句删除索引
可以先用CREATE INDEX ename_index ON employee(ename ASC);重新创建一下索引ename_index,之后再作为测试用alter table删除
格式:
ALTER TABLE 表名 [DROP PRIMARY KEY| DROP INDEX 索引名|DROP FOREIGN KEY fk_symbol
例:
ALTER TABLE employee DROP INDEX ename_index;
Python数据结构之序列及其操作
数据结构是计算机存储,组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
在Python中,最基本的数据结构为序列(sequence)。序列中的每个元素都有编号:从0开始递增,即其位置或索引,其中第一个元素的索引为0,第二个元素的索引为1,依此类推。最后一个元素的位置为-1。
Python包含6种内建的序列:字符串,Unicode字符串,列表,元组,buffer对象和xrang对象。
字符串
与数字一样,字符串也是值,用单引号或双引号括起来。‘Hello world!‘ 或 "Hello world!"
列表
列表由一系列按特定顺序排列的元素组成,用[]括起来。列表中的元素可以是数字,字符串,列表,元组,字典,集合。列表不同于元组和字符串的地方:列表是可变的
元组
即不可变列表,用()括起来。
有几种操作适用于所有序列,包括索引、切片、相加、相乘和成员资格检查。另外,Python还提供了一些内置函数,可用于确定序列的长度以及找出序列中最大和最小的元素。(迭代)
序列通用操作
1.索引
#字符串 first = ‘hello,world!‘ print(first[0]) print(first[-1]) >>>h >>>-1 #列表 colour = [‘red‘,‘white‘,‘blue‘,‘black‘] print(colour[0]) print(colour[-1]) >>>red >>>black #元组 colour = (‘red‘,‘white‘,‘blue‘,‘black‘) print(colour[0]) print(colour[-1]) >>>red >>>black
2.切片
除使用索引来访问单个元素外,还可以使用切片来访问特定范围内的元素:使用两个索引,用冒号分隔。
#字符串 numbers= ‘123456789‘ print(numbers[0:3]) >>>123 #列表 numbers= [1,2,3,4,5,6,7,8,9] print(numbers[0:3]) >>>[1, 2, 3] #元组 numbers= (1,2,3,4,5,6,7,8,9) print(numbers[0:3]) >>>(1, 2, 3)
#使用来个索引来指定切片的边界,其中第一个索引指定的元素包含在切片内,但第二个索引指定的元素不包含在切片内。
2.1切片的简写
当想要访问序列中最后几个元素而又不知道其索引位置时,可以使用负数索引。以列表为例。
numbers= [1,2,3,4,5,6,7,8,9] print(numbers[-3:-1]) print(numbers[-3:]) >>>[7, 8] >>>[7, 8, 9]
#第二个索引指定的元素不包含在切片内。
如果切片始于序列开头,可省略第一个索引。
numbers= [1,2,3,4,5,6,7,8,9] print(numbers[:3]) >>>[1, 2, 3]
切片位于序列中间元素时
#序列中第3个元素到第4个元素 numbers= [1,2,3,4,5,6,7,8,9] print(numbers[2:5]) >>>[3, 4, 5] #序列中第3个元素到倒数第4个元素 numbers= [1,2,3,4,5,6,7,8,9] print(numbers[2:-3]) >>>[3, 4, 5,6]
2.2步长
普通切片中,步长为1,意味着从一个元素移到下一个元素,指定步长时,将从起点和终点之间按照指定步长提取元素。
numbers= [1,2,3,4,5,6,7,8,9] print(numbers[0:8:2]) #步长为2 可以简写为print(numbers[::2]) print(numbers[0:8:3]) #步长为3 可以简写为print(numbers[::3]) >>>[1, 3, 5, 7] >>>[1, 4, 7]
步长不能为0,但可以为负数,即从右向左提取元素。
numbers= [1,2,3,4,5,6,7,8,9] print(numbers[8:0:-2]) >>>[9, 7, 5, 3]
#切片也必须从右到左
3.序列相加
a = ‘hello‘ b = ‘world‘ print(a+b) >>>helloworld x = [1,2,3] y = [4,5,6] print(x+y) >>>[1, 2, 3, 4, 5, 6]
#不同类型的序列不能相加
4.乘法
a = ‘hello‘ print(a*5) >>> hellohellohellohellohello
5.成员资格
a = ‘hello,world!‘ print(‘h‘ in a) print(‘x‘ in a) >>>True >>>False
只有两种返回结果:True和False
6.长度,最小值和最大值
内置函数len返回序列包含的元素个数,min和max分别返回序列中最小和最大的元素。以列表为例。、
numbers = [45,8,126,78,3,17,5] print(len(numbers)) #长度 print(min(numbers)) #最小值 print(max(numbers)) #最大值 >>>7 >>>3 >>>126
以上是关于主流数据库之索引及其例子的主要内容,如果未能解决你的问题,请参考以下文章