Hive数据倾斜解决思路
Posted strongyoung88
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive数据倾斜解决思路相关的知识,希望对你有一定的参考价值。
Hive数据倾斜总结
发生倾斜的根本原因在于,shuffle之后,key的分布不均匀,使得大量的key集中在某个reduce节点,导致此节点过于“忙碌”,在其他节点都处理完之后,任务的结整需要等待此节点处理完,使得整个任务被此节点堵塞,要解决此问题,主要可以分为两大块:一是尽量不shuffle;二是shuffle之后,在reduce节点上的key分布尽量均匀。
倾斜探查
join key倾斜
select key, count(*) cnt
from B b
group by key
order by cnt desc;
如果某个key的cnt比较大,比如排在第1的key,cnt占了一大半,那使用这个key去join,极有可能发生数据倾斜。

像图中,排在第1的key,占据了4161w条记录,占表总记录数的一半,如果使用这个key去join,运行时肯定倾斜。
查看日志
如果发现,某个任务运行时间比较长,可以看下执行日志,如果运行时reduce阶段一直在99%,则极可能是发生了数据倾斜,如下图:
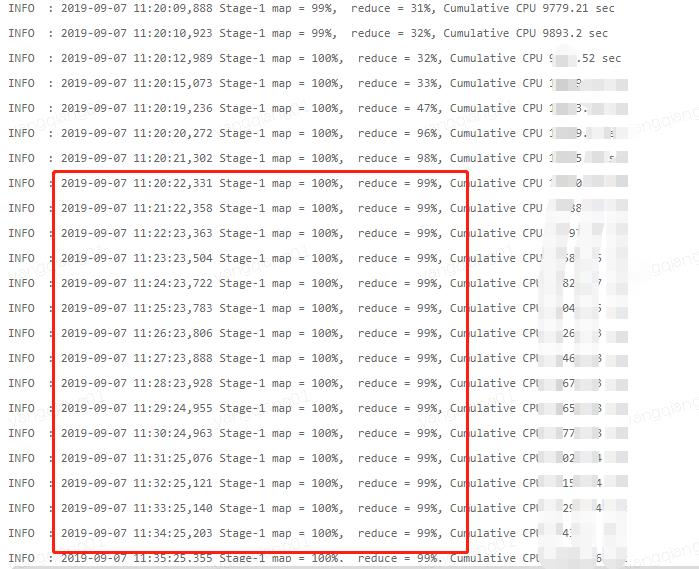
倾斜原因
-
key相同的太集中,导致倾斜
-
key的哈希结果,或分区函数的结果,导致key分布集中
解决方案
只要有shuffle,就有可能产生数据倾斜,解决数据倾斜的总体思路是:
- 能在map端处理的,不留到reduce端(当然,这不仅是解决数据倾斜的思路,这个适用所有的优化):
- 根据谓词下推规则,尽早过滤数据;
- 使用map Join
- 将key值尽量分散。
- 使用随机数打散,但要考虑不能影响结果。
- 提高并行度
具体的方法有以下:MapJoin,手工分割,添加随机前缀,使用列桶表等。
1. mapjoin
-
适应场景:Join的两个表中,有一个表比较小,小到可以完全放到分布式缓存中,默认的大小是25M。
-
配置方法(亲测有效):
set hive.auto.convert.join = true; set hive.mapjoin.smalltable.filesize=25000000; -
优点:运行时转换成mapjoin,无reduce阶段,运行时间极短
-
缺点:适用场景有限,需要占用分布式缓存
mapJoin原理
- Local work:
- read records via standard table scan (including filters and projections) from source on local machine
- build hashtable in memory
- write hashtable to local disk
- upload hashtable to dfs
- add hashtable to distributed cache
- Map task
- read hashtable from local disk (distributed cache) into memory
- match records’ keys against hashtable
- combine matches and write to output
- No reduce task
2. 手工分割
-
适应场景:当我们知道某些少量极个别的key 去join时会发生倾斜,我们可以手工将其分开执行,比如key=A时会发生倾斜,我们此时可以将所有的key分成两块来执行,一块是key=A,另一块是key<>A,如下:
-
实践代码(亲测有效)
select t1.* from t1 join t2 on t1.key=t2.key 拆成以下SQL: select t1.* from t1 join t2 on t1.key=t2.key where t1.key=A union all select t1.* from t1 join t2 on t1.key=t2.key where t1.key<>A -
缺点:场景有限
这种场景需要注意一下:如果倾斜的key,除了key=A外,还有其他key时也会发生倾斜时,并不一定适合去拆分。
3. 大表添加N种随机前缀,小表膨胀N倍数据
- 适用场景:小表不是很小,不太方便使用mapjoin。
- 解决方法:对大表的key添加N种随机前缀,对小表和N种随机前缀做笛卡尔积,使得大表里新生成的key在小表里都有可能正确地找到相应的key,解决思路可参考以下图:
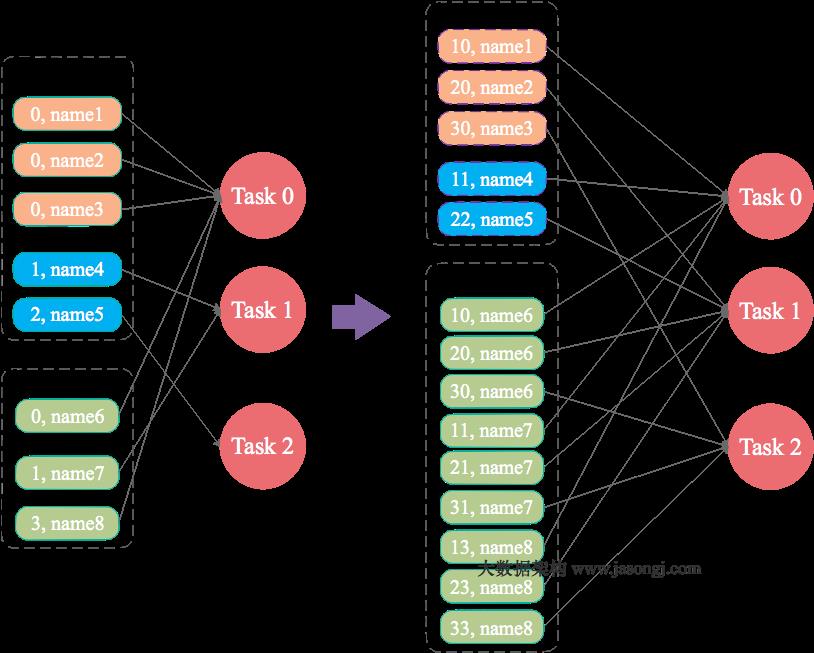
- 实践代码(亲测有效),以下代码是N的取值为10
select a.*
from a
left join (
select concat(c.rand_num,'_',d.key) as key from(
select rand_num from dual LATERAL VIEW explode(array(0,1,2,3,4,5,6,7,8,9)) rand_num_list as rand_num
)c join d
)b on concat(cast(9*rand() as int), '_', a.key) =b.key
where a.ds='2019-09-05'
- 优点:可适当降低倾斜程度。
- 缺点:N的取值不太好判断,需要多次实验,而且数据膨胀后,会增加资源消耗。
4. 使用Skewed Table或List Bucketing Table
-
Skewed Table vs. List Bucketing Table
- Skewed Table是倾斜表,元数据存储了倾斜key的信息,例如:
create table T (c1 string, c2 string) skewed by (c1) on ('x1')- List Bucketing Table是一种特殊的倾斜表,数据存储的时候会带有倾斜key的子目录,创建时需要指定
STORED AS DIRECTORIES,例如:
create table T (c1 string, c2 string) skewed by (c1) on ('x1') stored as directories; create table T (c1 string, c2 string, c3 string) skewed by (c1, c2) on (('x1', 'x2'), ('y1', 'y2')) stored as directories;- skewed table 不会创建子目录,但list bucketing table会。
-
适用场景:
- 每个分区中,倾斜key的数据占了绝大部分,比如表中的key有10个,但key=key1的数据占了总数据量的60%;
- 每个分区中,倾斜的key比较少,因为太多容易给元数据造成压力。
-
不适用场景:
- 如果倾斜的key的数量比较多,会给元数据存储造成压力
-
Skewed table 使用方法 :
set hive.optimize.skewjoin.compiletime =true;
set hive.optimize.skewjoin =true;
- List Bucketing Table不指定配置参数,直接Join,就能生效
5. 配置每个reduce节点处理的数据量
- 对于hive作业配置如下:
set hive.exec.reducers.bytes.per.reducer = 100000000;
-
配置:在Hive0.14.0版本之前,此配置默认为1G(1,000,000,000),在版本0.14.0之后,默认为256MB
-
优点:reduce个数增多,可以提高速度
-
缺点:但这个阈值不太好控制,还是容易产生倾斜。
-
对于spark作业
对于spark作业,可以采用spark自适应特性来缓解数据倾斜问题,配置如下:
| 属性名称 | 默认值 | 备注 |
|---|---|---|
| spark.sql.adaptive.enabled | false | 自适应执行框架的开关 |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 67108864 | 动态调整reduce个数的 partition 大小依据,如设置64MB,则reduce 阶段每个task最少处理 64MB的数据。 |
| spark.sql.adaptive.shuffle.targetPostShuffleRowCount | 20000000 | 动态调整reduce个数的partition条数依据,如设置20000000则reduce阶段每个task最少处理 20000000条的数据。 |
可以通过配置调整reduce阶段每个task处理的数据量的大小或处理的记录条数,经缓解数据倾斜问题
其他
以下两种方式都试过,但没感觉到提速。
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=100000; --如果在同一个join operator出现超过此阈值的相同的key,则认为此key为倾斜key
set mapred.reduce.tasks=800;
- 优点:reduce个数增多,可以提高速度
- 缺点:但这个阈值不太好控制,还是容易产生倾斜。
参考文献:
http://www.jasongj.com/spark/skew/
https://cwiki.apache.org/confluence/display/Hive/Skewed+Join+Optimization
https://cwiki.apache.org/confluence/display/Hive/ListBucketing
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization#LanguageManualJoinOptimization-PriorSupportforMAPJOIN
以上是关于Hive数据倾斜解决思路的主要内容,如果未能解决你的问题,请参考以下文章