新的Ubuntu服务器上如何安装深度学习环境的docker
Posted 往事如yan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新的Ubuntu服务器上如何安装深度学习环境的docker相关的知识,希望对你有一定的参考价值。
背景:
硬件:联想的双3090显卡 总共 48GB显存 4TB 刀片式服务器。
软件:只安装了nvidia的驱动,能用nvidia-smi查看显卡信息,但是 nvcc -V看不到东西。
镜像包是 nvidia_cu11_tf15.tar,里面包含:
tensorflow 1.15.2+nv
tensorflow-estimator 1.15.1
tensorrt 7.1.2.8
torch 1.9.0
torchvision 0.10.0step 1 搞通网络
外网:自己mate20手机插usb线给Ubuntu,然后手机点开 usb共享网络。
内网连接笔记本:网线对插笔记本和服务器,都改成 192.168.1.xx网段。
Windows修改IP地址:打开网络和共享中心,选择适配器设置,右键选择属性,然后选择Internet协议版本4(TCP/IPv4),点击属性,手动输入IP地址、子网掩码和默认网关。确保两台计算机的IP地址在同一网段内,例如192.168.1.x。然后可以使用ping命令测试两台计算机之间的连接。如果无法ping通,可以检查防火墙设置或者网络配置是否正确。
Ubuntu是有多个网卡的系统,我怎么知道哪个IP是我需要改的,或者我怎么手动修改该Ubuntu系统下的某个端口的IP地址、子网掩码和默认网关
如果需要手动修改某个端口的IP地址,可以使用ifconfig命令加上端口名来指定要修改的网卡,例如ifconfig eth0 192.168.1.2 netmask 255.255.255.0 gateway 192.168.1.1。这将把eth0端口的IP地址设置为192.168.1.2,子网掩码为255.255.255.0,默认网关为192.168.1.1。
能ping 通后,用 WinSCP 连接Ubuntu,然后上传 nvidia_cu11_tf15.tar 到 它的 data 目录。
step 2 安装 docker 和 nvidia-docker2
公司nvidia驱动和环境里的TensorFlow,torch 是不一样的。一开始担心 是不是 要 降级 Ubuntu下的显卡驱动。
启动后:先图形化实现 软件和更新
点击左下角 9个点点,上面搜索栏 搜索 软件和更新,或者 ctrl alt T 打开 终端,输入:
docker:
上面文章,拉到最后,参考 3 篇笔记 里的 第二篇 是可以成功安装 docker的。
docker-ce的快速安装_docker-ce安装_ftt@sxz的博客-CSDN博客
nvidia-docker2:
Ubuntu 14.04/16.04/18.04安装nvidia-docker2_nudt_qxx的博客-CSDN博客
注意一定要保持网络畅通。
因为 原系统里已经有了 nvidia驱动,所以 在只执行 三. 和 五.
五. 注意
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
如果你是全新安装,不需要执行这一步。
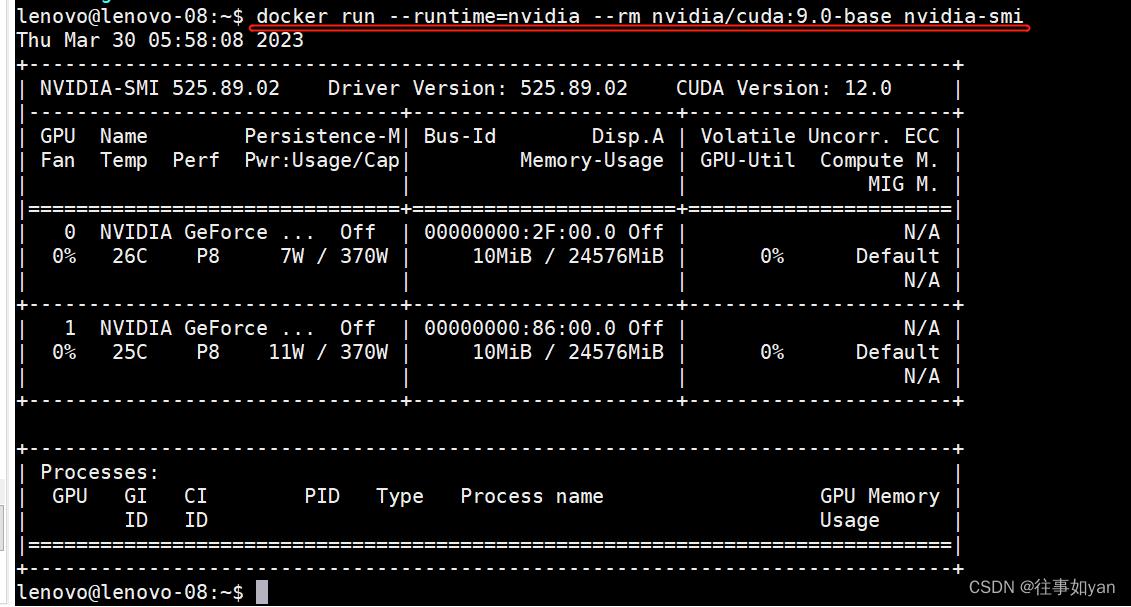
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi上面这条 一定要在 网络好的时候多执行一次,我第一次就是没有执行成功,后来是网速好的时候再次执行,才成功,执行成功是 下面这个结果:
step 3 如何使 docker服务 能 使用 GPU的TF,pytorch
docker load< xxx.tar
docker images
docker run --gpus all -itd <imageid:>
docker ps -a
docker exec -it dockerID bash
python3
import tensorflow as tf
print(tf.test.is_gpu_available())
step 4 docker里安装新的python包
以Django举例子。
1、进入容器
docker exec -it dockerID bash
2、安装django
>pip3 install -i https://pypi.douban.com/simple django
或 指定相应的django版本:
>pip3 install -i https://pypi.douban.com/simple django==2.0
pip3 安装 到 python3 的环境
3、验证是否安装成功
python -c "import django; print(django.get_version())"
step 5 如果要固化到镜像,则需要重新构建 Dockerfile
FROM ubuntu:latest
RUN apt-get update && apt-get install -y python3 python3-pip
RUN pip3 install django
COPY myproject /app/myproject
WORKDIR /app/myproject
EXPOSE 8000
CMD ["python3", "manage.py", "runserver", "0.0.0.0:8000"]在 Dockerfile 里 加上 ,RUN pip3 install django
然后构建镜像
Ubuntu20.04|最新一版的深度学习基础环境安装指导
对ubuntu的感悟:能不执行奇奇怪怪的操作,就不去执行!
别动不动就去修改 grub 界面后的一些配置信息。
目前的配置:(三台台式机和一台服务器上,已尝试成功。)
- nvidia driver # 最新版本
- ubuntu20.04
- cuda 11.0
- gcc g++ 9.3.0 (未降级)
- cudann 8.0
一 删除双系统下的Ubuntu系统
- 在windows磁盘管理中将含有ubuntu系统的分区执行“删除卷”操作,不过该类操作不能删除ubuntu的EFI系统分区,因为windows对其他系统的保护措施。
- 删除EFI系统分区需要通过Diskpart以对分区管理。
1 win+R 执行 Diskpart 命令 2 list disk 命令以查看当前磁盘列表;通过select disk X 来选择想要执行操作的磁盘; 3 选中磁盘后,输入list partition 来查看磁盘下的分区;通过select partition X 以选择想操作的分区; 4 选中分区后,输入 delete partition override 来强制删除分区;具体的,类型为“系统”的分区即为ubuntu的系统分区,需要注意的是,如果windows的系统分区和ubuntu的系统分区在同一个disk中,需要从分区的大小来区分两类系统。 - 下载 UEFI (全名忘记了)文件,能够实现将ubuntu的grub启动程序删除掉。sudo dpkg -i googlexxxx.debsudo dpkg -i googlexxxx.deb
二 安装Ubuntu系统
目前安装的ubuntu版本是20.04,且其内核是5.8.0-50-genetic。
具体细节不细讲,粗略讲,过程中联网下载相应软件;
安装成功后,需要执行以下两行命令和两个操作:
# 大致计划
1 sudo apt-get update
2 sudo apt-get upgrade
3 安装 ghelper 和 google. sudo dpkg -i googlexxxx.deb ,联网,以下载必要软件
4 添加中文输入法(这一步一般的,在upgrade之后会自动添加上拼音输入法必备的包,比如fcxit)
5 谨慎的,不设置,“软件与更新”软件中,不设置 从不更新等要求死的选项,因为可能会引起的有些包的升级或安装的不成功的现象发生(有过类似的经历,虽不知具体哪里的问题,但是一朝被蛇咬且免于不必要的麻烦,遂排除该种处理方法),取而代之的是,每次系统提醒更新,点击取消。
注意的是,sudo apt-get upgrade十分重要,该操作一般的会需要下载130多个包,包括了g++、gcc和make等与nvidia driver相关的最新版本的包。
三 筹备Nidia Driver的安装
- 【第一版本的感悟】需要讲在前面的是,我个人有个未经充分验证而属个人经验之谈的认知:驱动和cuda的安装方式应当选择统一类型,即要么都下载run文件安装,要么都deb方式,不过经常安装cuda的朋友也知道,驱动是不存在deb类型的。因此我推荐的唯一的方案是:两者均采用run文件的方式,安装之前通过浏览器预先下载好。
- 【第二版本的感悟】2021年5月31日,在一个服务器上安装驱动的过程中,按照上述第一版的方式,即安装驱动通过run文件的方式,发现了很多不同于在笔记本上安装时出现的问题,以及安装完成后出现的无法进入界面,而是一直处于一连串[OK] “一列字符串的start”等内容,具体没有截图。而后发现师弟通过使用Ubuntu中自带的服务器的Nvidia版本的驱动,在应用更改和重新启动后发现通过nvidia-smi命令,显示成功安装,并且在之后的安装过程中,cuda和cudnn等均成功安装,并成功运行代码。因此第一版感悟存在问题,但是在此仍做保留,为了记录思考的过程,仅此。
扩展知识点:
1 安装 驱动的 几种方式How to install the NVIDIA drivers on Ubuntu 20.04 Focal Fossa Linux重点是,通过阅读本文,晓得驱动的安装过程本不是必要禁用nouveau的,但是cuda安装时其实还是需要的。
1 下载run文件。
百度nvidia driver即可得相应链接;原则越高版本越好。
2 安装必要的包
# Install Prerequisites
sudo apt install build-essential libglvnd-dev pkg-config
3 禁用nouveau。
# The below commands will allow you to identify your Nvidia card model:
lspci -vnn | grep VGA
# Blacklist Nvidia nouveau driver
$ sudo bash -c "echo blacklist nouveau > /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
$ sudo bash -c "echo options nouveau modeset=0 >> /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
# Confirm the content of the newly created modeprobe file
$ cat /etc/modprobe.d/blacklist-nvidia-nouveau.conf
blacklist nouveau
options nouveau modeset=0
# 更新系统
$ sudo update-initramfs -u
# 重启系统(一定要重启)
# vertification , no output is well
lsmod | grep nouveau
另,
- 这一部分在cuda文档中也有发生过。
- 网上大部分的文章中,提及要stop lightdm,但是我的ubuntu20.04版本中并没有该服务,当我执行
sudo service lightdm stop时,返回错误failed to stop lightdm.service : Unit lightdm.service not load.
4 赋予run文件执行权限
- cd到之前下载下来的nvidia驱动安装文件所在的文件夹
- 给驱动run文件赋予执行权限:sudo chmod a+x NVIDIA-Linux-xxxxx.run
- 安装命令:
sudo ./NVIDIA-Linux-x86_64-418.56.run -no-x-check -no-nouveau-check -no-opengl-files- 只有禁用opengl这样安装才不会出现循环登陆的问题
- -no-x-check:安装驱动时关闭X服务
- -no-nouveau-check:安装驱动时禁用nouveau
- -no-opengl-files:只安装驱动文件,不安装OpenGL文件
5 安装过程中遇到的问题以对应答案
- ubuntu自带了发行版的驱动版本,是否继续使用该run文件安装? —— Continue installation
- 是否安装32位文件? —— No,除非安装steam游戏平台。
- X服务? —— No, 本人第一次安装时,选择yes出现重启后黑屏的问题;选择No后,无碍。但是之前看到nvida的官网文件中显示,建议选择yes。水平有限,仅能提出现象或偶然现象;但是之后几次选择NO,似乎又没有什么问题。
- 安装结束。 —— OK
- 另外,如果遇到
An NVIDIA kernel module 'nvidia-drm' appears to already be loaded in your kernel. This may be because it is in use (for example, by an X server, a CUDA program, or the NVIDIA Persistence Daemon), but this may also happen if your kernel was configured without support for module unloading. Please be sure to exit any programs that may be using the GPU(s) before attempting to upgrade your driver. If no GPU-based programs are running, you know that your kernel supports module unloading, and you still receive this message, then an error may have occured that has corrupted an NVIDIA kernel module's usage count, for which the simplest remedy is to reboot your computer.的问题。—— 先退出安装环节,同时执行两行命令:sudo systemctl isolate multi-user.target # 第一个命令会直接从图形界面进入到tty界面。 sudo modprobe -r nvidia-drm # 该命令可能需要自己拍照i记下。
参考文献:https://zhuanlan.zhihu.com/p/135875408
6 收尾与验证
网友们普遍的做法是:
# 挂载Nvidia驱动:
modprobe nvidia
# 检查驱动是否安装成功:
nvidia-smi
# 重启
sudo reboot
四 安装CUDA
说在前面的话:安装CUDA的时候是有讲究的,说白了就是其版本问题。
从两个方面决定:1 打算使用的tensorflow的版本;2 打算使用的pytorch的版本。
而tensorflow的版本又受限于gcc版本,而gcc版本如果太低,ubuntu的最新版本是不能下载安装的。比如说,ubuntu20.04,内核5.8.0-50,gcc默认安装后为9.3.0,而tensorflow2.4 目前的最新版本要求gcc为7.3.1。而ubuntu目前不能安装7的版本的gcc,而gcc版本如果低,可能会引起tensorflow不能使用(高版本不兼容低版本的情况确实存在,但是目前tensorflow2.4似乎能够支持9.3,但是之前的一些版本的tensorflow对于高版本的gcc无法使用。),同时,gcc版本低,在安装driver时,也会出现一些警告。(本人之前安装时,一直出现该警告,且自此再未安装成功过。)
不过,本人用的是pytorch框架,因而相对来说,对cuda版本和gcc要求无特别要求。
cudnn版本取决于cuda,驱动版本只需要与自己电脑的操作系统和GPU系列相匹配即可。
Tensorflow 目前 2.3版本 对应cuda 10.1;GCC对应7…3.1
tensorflow 2.4版本对应, cuda11.0; cuDNN 8.0 ; 7.3.1;
而 pytorch 要求cuda版本 11.1 或者 11.0 或者10.2 均可。其实pytorch也支持cuda10.0的版本,但是10.0的版本的pytorch目前在仍在维护中的最低一级的python版本3.6中已经没有源可以获取的了,安装的方式,需要通过对应虚拟环境下的conda命令进行安装,如果conda没有切换国内源,则下载安装pytorch的速度将挥比较漫长。
框架的更新迭代速度会很快,需要我们自己结合现状选择合适的cuda版本。在此提供三个链接作为参考:
1 cuda11.0对ubutnu等系统以及gcc等包的版本的要求
2 tensorflow最新版本对gcc、cuda的版本要求
3 pytorch的下载版本
综合来看,tensorflow的要求比较宽泛,但是pytorch相对比较宽松,因而,我决定这次尝试一次新版本:cuda 11.0 。
需要补充的是,如果你要安装openpose,那么cuda10.1+cudnn7.6.3更适合,因为caffe目前基本不怎么更新了,更别提及对cudnn的兼容。
参考链接:https://bbs.csdn.net/topics/397280925?page=1
1 各软件的安装版本
nvidia driver # 最新版本
ubuntu20.04
cuda 11.0
gcc g++ 9.3.0 (未降级)
cudann 8.0
1.1 Ubuntu20.04 中 gcc9 -> 7降级 (极度重要,cuda<11.0的可能需要考虑降级)
参考链接:https://blog.csdn.net/g1l1s1/article/details/106813628?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
其中,gcc-7-multilib g+±7-multilib这两个包我未曾指明安装,且相关依赖包也不曾涉及!
# 安装
sudo apt install -y gcc-7 g++-7 g++-7-multilib gcc-7-multilib
# 调整优先级
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 100
sudo update-alternatives --config gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 100
sudo update-alternatives --config g++
# 删除优先级 —————— 只是作为额外知识,正常情况下,不需要执行该命令。
sudo update-alternatives --remove gcc /usr/bin/gcc-5
2 Cuda下载
百度 nvidia cuda 11.0 即可,且选择run类型的文件。
3 cuda安装
# cd到之前下载下来的cuda安装文件所在的文件夹
# 输入安装命令:sudo sh cuda_9.1.85_387.26_linux.run
# 出现问题Do you accept the previously read EULA? 输入’accept’
# 选择要安装的项目。在driver的选项enter取消选中。
# (因为我们之前已经安装了固定版本的nvidia驱动)
# end 显示以下内容:
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-10.1/
Samples: Installed in /home/yan/, but missing recommended libraries
Please make sure that
- PATH includes /usr/local/cuda-10.1/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-10.1/lib64, or, add /usr/local/cuda-10.1/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-10.1/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-10.1/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 418.00 is required for CUDA 10.1 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run --silent --driver
Logfile is /var/log/cuda-installer.log
- 添加到环境变量
export PATH=/usr/local/cuda-11.0/bin${PATH:+:${PATH}} - 如果是cuda10.1,则
export PATH=/usr/local/cuda-10.1/bin:/usr/local/cuda-10.1/NsightCompute-2019.1${PATH:+:${PATH}}
参考链接:https://docs.nvidia.com/cuda/archive/10.1/cuda-installation-guide-linux/index.html#post-installation-actions
同时,观赏两个cuda版本的环境变量,可知,不同的版本的正确写法应该参考对应的说明文档! - 接着,
source ~/.bashrc
这里缺乏对整个过程的完整描述,有待完善。 - 很多文章中提到,验证的方式是
nvcc -V但是我发现自己安装好后,可以运行,但是nvcc似乎需要另外安装。本着能不安装就不安装的ubuntu生存策略,因而没有安装。———— 我在三台机子上均是安装该思路进行,都能十分顺利完成安装,同时使得openpose正常运行。
4 问题
安装结束后,在reboot的时候,出现了卡屏、黑屏以下述内容:
Unable to determine the device handle for GPU. GPU is lost. Reboot the system to recover this GPU.
不过,在重启过程中出现无法控制的黑屏和连续报错的内容ERROR: GPU:0: Error while waiting for GPU progress: 0x0000c57e:0 2:0:392:380;
最终胡乱敲出 sudo reboot 重启,竟真的停止了报错,重启后,cuda和driver可用,因为nvidia-smi使用后正常显示。
这一点需要多次安装该系列过程才能完善。
5 卸载
参考链接:https://docs.nvidia.com/cuda/archive/11.0/cuda-installation-guide-linux/index.html#removing-cuda-tk-and-driver
sudo apt-get --purge remove "*cublas*" "*cufft*" "*curand*" "*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "cuda*" "nsight*"
五 Cudnn安装
1 cudnn下载
目前只有tensorflow对cudnn的版本有要求,因而cudnn的具体版本以tensorflow最新版本的要求为主,即cudnn8.0。
下载runtime、developer 和 code samples三个版本。只有deb版本。
2 cudnn安装
- 解压三个包
参考官网说明: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#prerequisites
sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb
sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.deb # 注意的是,安装该步骤的前提是,上一个deb包被成功安装,因此顺序需要注意以下。
sudo dpkg -i libcudnn7-doc_7.6.5.32-1+cuda10.1_amd64.deb

2. 检查是否安装成功:
执行下面命令的时候,注意cudnn_samples_v7中最后的一个数字,如果安装的cudnn是7.x.x,则此处为7;若为8.x.x,则此处为8!
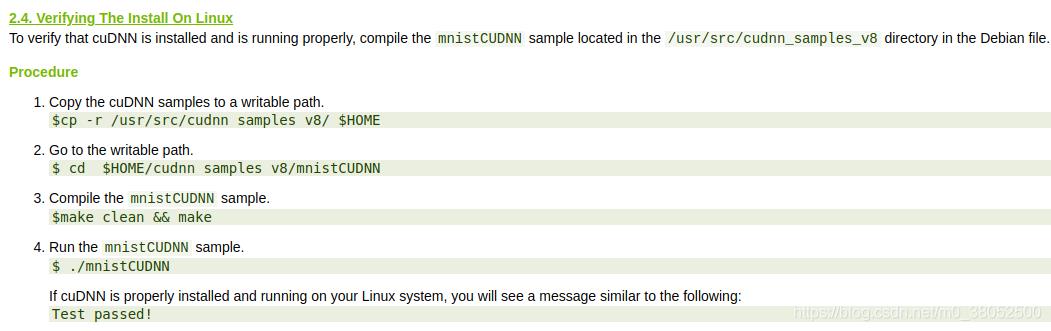
Copy the cuDNN samples to a writable path.
$cp -r /usr/src/cudnn_samples_v7/ $HOME
Go to the writable path.
$ cd $HOME/cudnn_samples_v7/mnistCUDNN
Compile the mnistCUDNN sample.
$ make clean && make
Run the mnistCUDNN sample.
$ ./mnistCUDNN
If cuDNN is properly installed and running on your Linux system, you will see a message similar to the following:
Test passed!
3 问题
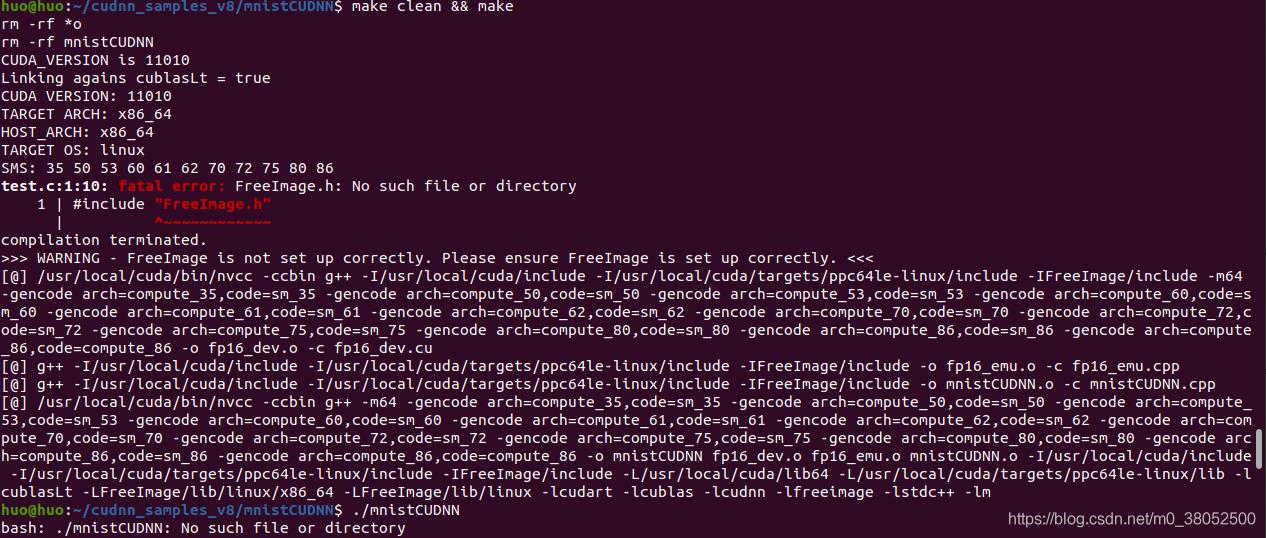
网址解答:https://forums.developer.nvidia.com/t/freeimage-is-not-set-up-correctly-please-ensure-freeimae-is-set-up-correctly/66950/2
方案: 缺乏相应的库; 考虑安装 sudo apt-get install libfreeimage3 libfreeimage-dev
网址解答:https://forums.developer.nvidia.com/t/freeimage-is-not-set-up-correctly-please-ensure-freeimae-is-set-up-correctly/66950/2
方案: 缺乏相应的库; 考虑安装 sudo apt-get install libfreeimage3 libfreeimage-dev
4 cudnn卸载
cd /home/zqzy #在主目录下执行卸载
sudo rm -rf /usr/local/cuda/include/cudnn.h
sudo rm -rf /usr/local/cuda/lib64/libcudnn*
参考链接:https://blog.csdn.net/zhuiqiuzhuoyue583/article/details/107374951
六 Anaconda
先安装anaconda再安装pycharm;
-
安装参考链接:https://docs.anaconda.com/anaconda/install/linux/
其中,如果出现conda: command not found的问题:
export PATH=/usr/yan/anaconda3/bin/activate
需要手动将anaconda的安装位置添加在~/.bashrc文件中。
同时,如果出现这种情况,那也就表明安装的时候,使用了sudo命令,使得所安装的软件因此被赋予了一定的权限。
因而紧接着还会出现,无法使用conda创建虚拟环境的情况:此时需要使用:sudo chmod -R 777 anaconda3以解决该问题。
不过最重要的是:安装程序时,不使用sudo。 -
删除操作基本上 直接删除相关文件夹即可,除此之外,anaconda的环境变量的地址需要删除。
删除参考连接:https://docs.anaconda.com/anaconda/install/uninstall/
Cold: 问题累积
1. 彻底清除某个包
如果遇到类似下文的情况,使用sudo apt remove xxx 清除不掉,只能加上 --purge ;问题的成因不了解,不过这个结果表示因为某些原因 该包虽然下载下来但是无法得到安装和设置!
Errors were encountered while processing:
gdm3
E: Sub-process /usr/bin/dpkg returned an error code (1)
2. 彻底卸载 cuda tookilt 、driver
# Ubuntu and Debian
# To remove CUDA Toolkit:
$ sudo apt-get --purge remove "*cublas*" "*cufft*" "*curand*" \\
"*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "cuda*" "nsight*"
# To clean up the uninstall:
$ sudo apt-get autoremove
如果driver来自run文件安装
# https://blog.csdn.net/gaoyi135/article/details/91586521
back to nvidia.run folder and run following code:
`sudo sh ./Nvidia .... .run --uninstall`
这时会出现If you plan to no longer use NVIDIA driver, you should make sure that no X screens are configured to use the NVIDIA X driver in your X configuration file. If you used nvidia-xconfig to configure X, it may have created a backup of you original configuration. Would you like to run 'nvidia-xconfig --restore-original-backup' to attempt restoration of the original X configuration file? 选择‘No’,随后点击’OK’
如果driver不是来是run文件参考官网说明: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#prerequisites
sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.deb sudo dpkg -i libcudnn7-doc_7.6.5.32-1+cuda10.1_amd64.deb
安装
# To remove NVIDIA Drivers
$ sudo apt-get --purge remove "*nvidia*"
# To clean up the uninstall:
$ sudo apt-get autoremove
3. linux 和 nvidia driver QA 网址
https://help.ubuntu.com/community/BinaryDriverHowto/Nvidia#Troubleshooting
4. ubuntu下U盘的输入输出问题
ubuntu系统下文件未复制结束就拔出硬盘,引起“无法显示xxxxx 全部内容,… 输入输出错误”。
通过ubuntu下的方式不能解决,最终在windows下删除硬盘中的 ubuntu中提及有问题的文件 后,在ubuntu中重新被识别。启示:ubuntu有了windows才保险。
4.1 ubuntu下 error mounting 问题
Error mounting /dev/sdb1 at /media/tong/C88B-29DD:
sudo apt-get install exfat-fuse exfat-utils
一般情况下,运行完上述命令,我们再重新拔出并插入 U 盘,应该就可以识别了。
5 bazel:
echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list
curl https://bazel.build/bazel-release.pub.gpg | sudo apt-key add -
sudo apt-get update && sudo apt-get install bazel
sudo apt-get upgrade bazel
6 python 依赖库
sudo apt-get install freeglut3-dev build-essential
libx11-dev libxmu-dev libxi-dev
libglu1-mesa-dev libglu1-mesa
libgl1-mesa-glx
libffi-devel
python-devel
openssl-devel
pip install -i https://pypi.doubanio.com/simple
Cython==0.20.2 h5py scikit_image==0.9.3
opencv-python scipy
setproctitle==1.1.10
python_gflags==3.1.1 python_magic==0.4.13 pyglib==0.1
tensorflow_gpu==1.1.0
numpy==1.16.4
python 2.7 版本
pip2 install opencv-python==4.2.0.32
python main/run.py checkpoints test_set/input test_set/keshan
7 杂碎
-
deb order:
卸载:
sudo dpkg -r package_name -
ubuntu recoery mode
mount -o remount,rw / # 读写权限 -
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update -
lspci |grep -i nvidia # 显卡信息
lsmod | grep nouveau # 是否禁用
8 批量解压和压缩
for z in *.rar; do unrar x "$z" dad; done
for z in Tester*; do rar a "$z" "$z"; done
且和rar的统计目录下必须创建dad文件夹
Windows
1 查看cuda和cudnn的版本
参考文章:https://www.cnblogs.com/wuliytTaotao/p/11453265.html#%E6%9F%A5%E7%9C%8B-cudnn-%E7%89%88%E6%9C%AC
-
查看 cuDNN 版本。
在命令行中执行:nvcc --version
或者进入 CUDA 的安装目录查看:C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA -
查看 cuDNN 版本。
进入 CUDA 的安装目录查看文件 cudnn.h。
C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v9.0\\include\\cudnn.h
如果不知道安装路径,或者安装了多个版本的 CUDA
可以使用pytorch查看import torch print(torch.__version__) print(torch.version.cuda) print(torch.backends.cudnn.version())
以上是关于新的Ubuntu服务器上如何安装深度学习环境的docker的主要内容,如果未能解决你的问题,请参考以下文章
深度学习远程炼丹:一文离线完成ubuntu+docker+pycharm环境配置
ubuntu+docker+pycharm环境深度学习远程炼丹使用教程