MySQL Workbench 操作详解(史上最细)
Posted 敏姐儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL Workbench 操作详解(史上最细)相关的知识,希望对你有一定的参考价值。
mysql Work Space

右键新建的数据库BMI,设置为此次连接的默认数据库,接下来的所有操作都将在这个数据库下进行

将bmi下拉单展开,点击Table,右键创建Table:

给Table命名,添加Column,设置Column的Datatype,PrimaryKey等属性。点击Apply后,Workbench仍会自动生成SQL语句,再次点击Apply,成功创建新表,在左下角可以看到:

**mysql workbench创建数据库的时候PK,NN等的含义**
-
PK:primary key (列是主键的一部分) 主键
-
NN : not null (列可为空) 是否为空
-
UQ : 外键
-
AI : 自动增加
-
BIN : 二进制(if dt is a blob or similar, this indicates that is binary data, rather than text)
-
UN : 无符号
-
ZF : 补零
各种图标的含义

注意:上述英文对应所点按钮之英语 汉字为翻译内容 本文不一一赘述了
Execute the selected portion of the script or everything, if there is no selection
如果没有选择 那么就执行脚本的锁定或者所有的内容

Execute the statement under the keyboard cursor
在键盘光标下执行的语句

Execute the EXPLAIN command on the statement under the cursor
对游标下的语句执EXPLAIN

Stop the query being executed ( the connection to the DB server will not be restarted and any open transactions will remain open
停止正在执行的查询(与DB服务器的连接不会重新启动,任何打开的事务都将保持打开状态)

Toggle whether execution of SQL script should continue after failed statements
切换语句失败之后 是否应该继续执行SQL脚本

Commit the current transactionNOTE : all query tabs in the same connection share the same transaction . To have independent transactions , you must open a new connection .
提交当前事务注意:同一连接中的所有查询选项卡共享同一事务。要拥有独立的事务,必须打开一个新连接。

回滚中的当前事务选项卡

Toggle autocommit mode . When enabled , each statement will be committed immediatelyNOTE : all query tabs in the same connection share the same transaction To have independent transactions , you must open a new connection .
切换自动提交模式。启用后,将立即提交每条语句注意:同一连接中的所有查询选项卡共享同一事务要拥有独立事务,必须打开新连接。


将当前语句或所选内容保存到代码段列表。

美化/重新格式化SQL脚本


切换长行的换行(对于大文件,请禁用此选项)
编辑框



重置所有排序的列


刷新数据重新执行原始查询


切换单元格内容的换行

结果网格

电子编辑

字段类型

查询状态

执行计划
TIPS:
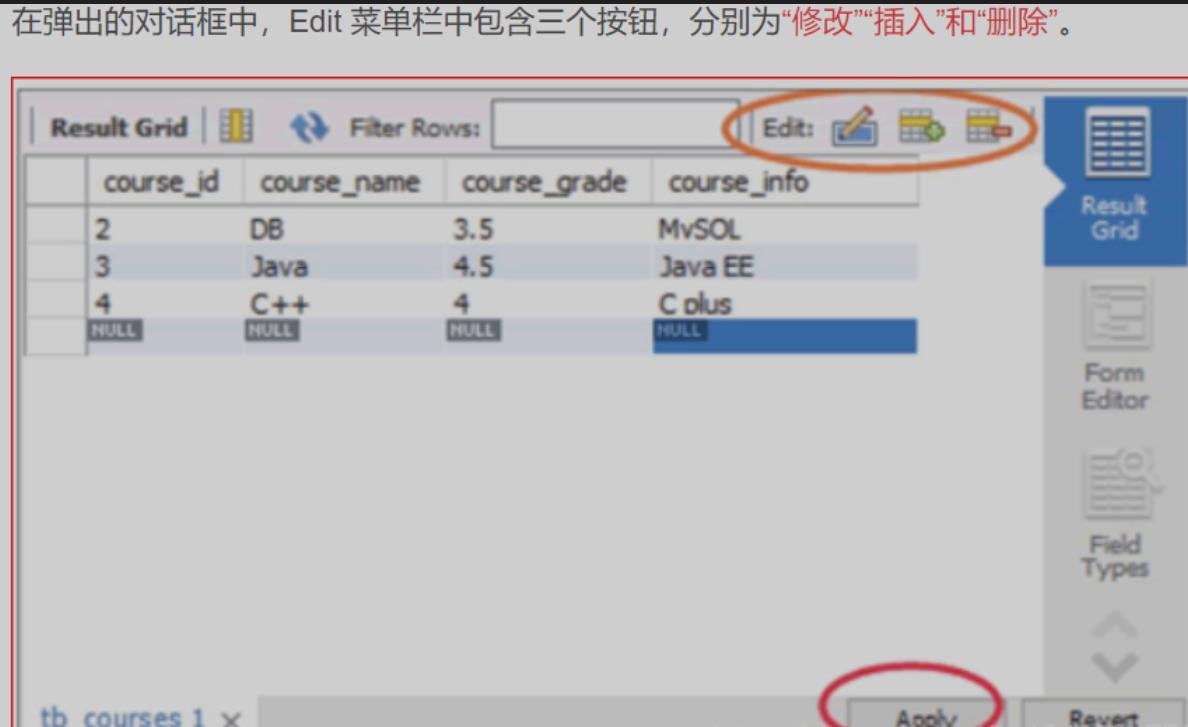
查看数据表

在查看数据表的对话框中,Info 标签显示了该数据表的表名、存储引擎、列数、表空间大小、创建时间、更新时间、字符集校对规则等信息,如下图所示。

在 Columns 标签显示了该表数据列的信息,包括列名、数据类型、默认值、非空标识、字符集、校对规则和使用权限等信息,如下图所示。

修改数据表

删除表

在弹出的对话框中单击 Drop Now 按钮,可以直接删除数据表,如下图所示。

主键约束
当勾选PK复选框的时候 该列就是数据表的主键 当取消复选框的时候 那么意味着取消该列的主键约束

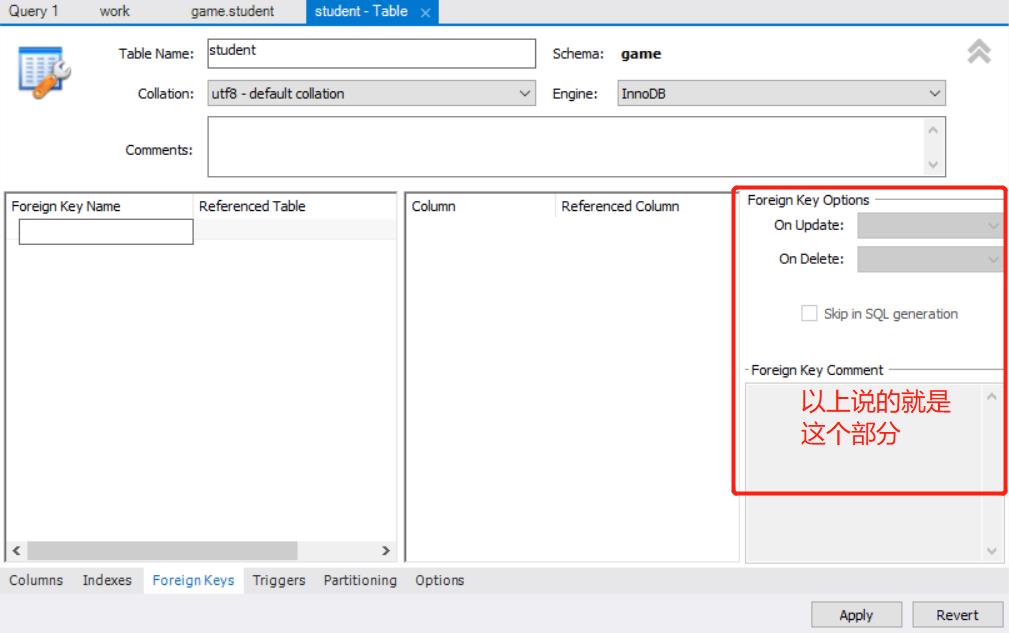
外键约束
在工作台中
Foreign Key name 外键名称
Referenced Table 关联的 关联的主表
Column 选择外键的字段
Referenced Table 选择主表关联的字段
外键的约束模式
- SET NULL 闲着模式
- 主表记录 被删除或者更改 从表相关的外键置为null
- CASCADE 级联操作
- 主表中删除或者跟新了某条信息,从表中与该表记录有关的记录也将发生改变
- DISTRICT 严格模式 (NO ACTION 和 DISTRICT 一样 )
- 当从表中有外键数据数据和主表关联 主表中的数据就不能更新或者删除
在外键约束的列表中,在需要删除的外键上右击,选择 Delete selected 选项,删除对应的外键,单击 Apply 按钮,即可完成删除,如下图所示删除线格式

设置完成之后,可以预览当前操作的 SQL 脚本,然后单击 Apply 按钮,最后在下一个弹出的对话框中直接单击 Finish 按钮,即可完成数据表 “st” 中外键的删除,如下图所示。

唯一约束
勾选UQ复选框时 该列就是数据表的唯一约束索引
取消勾选UQ复选框时 该列就不是数据表的唯一约束索引

非空约束
勾选 NN 复选框时,该列为数据表的非空约束;
取消勾选 NN 复选框时,则取消该列的非空约束
执行简单的sql
修改“work”表,给它加一个age字段。这里在“query”里面编写我们的sql语句,如下图所示。
alter table game.work add column age integer;

按“ctrl+enter”执行这个语句之后,我们就会看到下方的输出部分,会显示我们这个查询执行的具体情况。

MODEL
-
使用workbench设计ER图也很简单。选择File -> New Model:

-
在新展开的页面中“Model Overview”界面双击“Add Diagram”图标:
-
双击后即可看到设计界面,workbench中叫EER图,其实就是增强的(enhanced)ER图。
TIS注意各个图标的含义
-
选择对象

-
移动模型

-
删除对象

-
在选定区域放置一个新层用于直观地对关系图中的相关对象进行分组

-
建立一些文本描述

-
和text相对应 但是插入的是图片

-
建立一张表

-
建立一张视图
-
MySQL工作台将存储过程和存储函数统一到一个称为例程的逻辑对象中。例程组用于对相关例程进行分组(授权函数)

注意有些信息可以进行详细设置:

使用MODEL生成SQL语句
如果你需要sql语句,那么需要利用Model来生成。
首先打开一个Model,点击File -> Open Model,如图:

选择一个mvb类型文件,就是Model。
打开这个Model后,要生成它对应的sql语句,需要点击File -> Export -> Forward Engineer SQL CREATE SCRIPT,如图:

点击之后就会出现下图:

之后点击finish

TIPS
你也可以点击Database -> Forward Engineer来生成 但要注意,这么做在生成sql语句文件的同时,数据库中的语句也被清空了,并换成了新生成的sql。换句话说,这个方法是用来生成sql语句文件同时更改原数据库中的sql的,原有文件全被清空!如果你暂时还没想清空数据库则不要用这个方式
反向工程
使用workbench从库中导出ER图也很简单,在连接界面点击上方导航的Database -> Reverse Engineer,然后一路Next,这期间会让你选择要导出ER图对应的库,最后Finish,反向ER图就出来了。
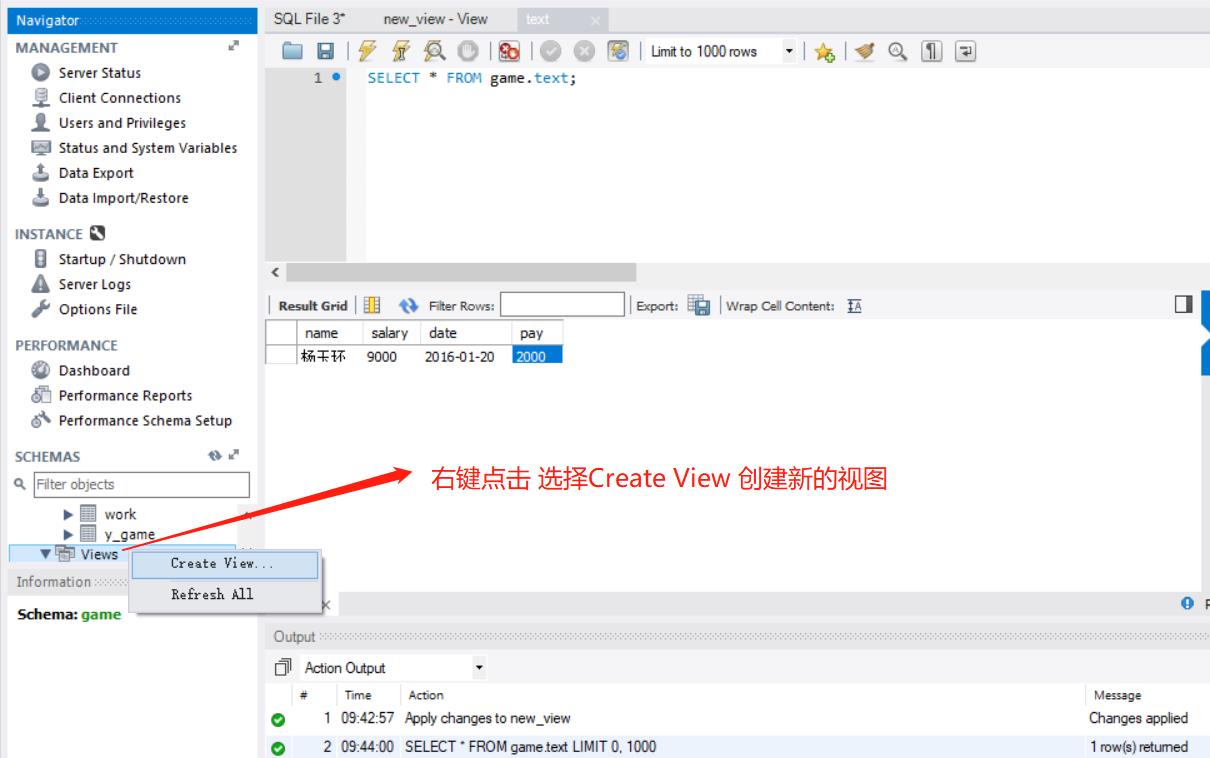
创建视图
在 SCHEMAS 列表中展开当前默认的 test_db 数据库,
在 Views 菜单上右击,选择“Create View…”,即可创建一个视图,如下图所示。
选择 Select Rows–Limit 1000 选项,即可查看视图内容
在查看视图内容的对话框中,视图内容为只读,不可修改,如下图所示

删除视图

存储过程
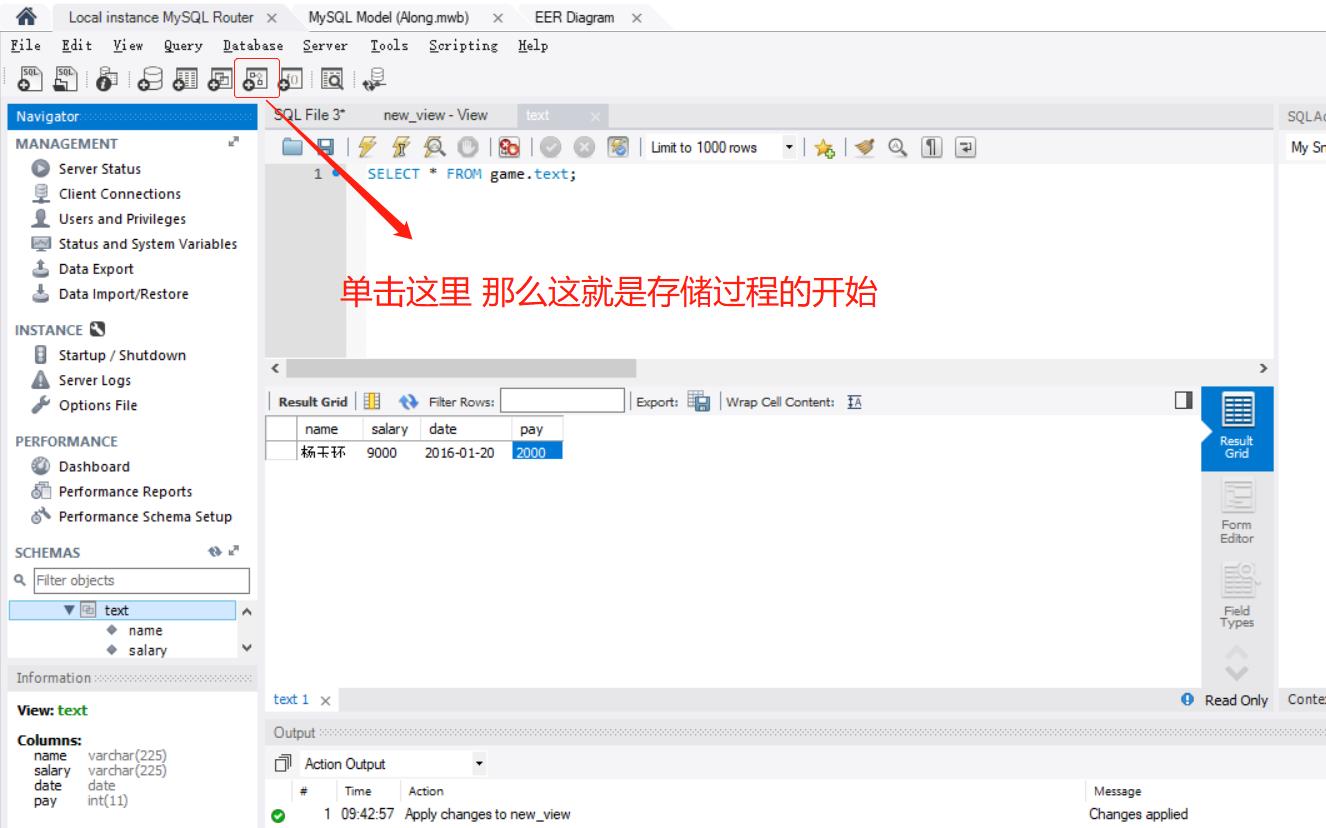
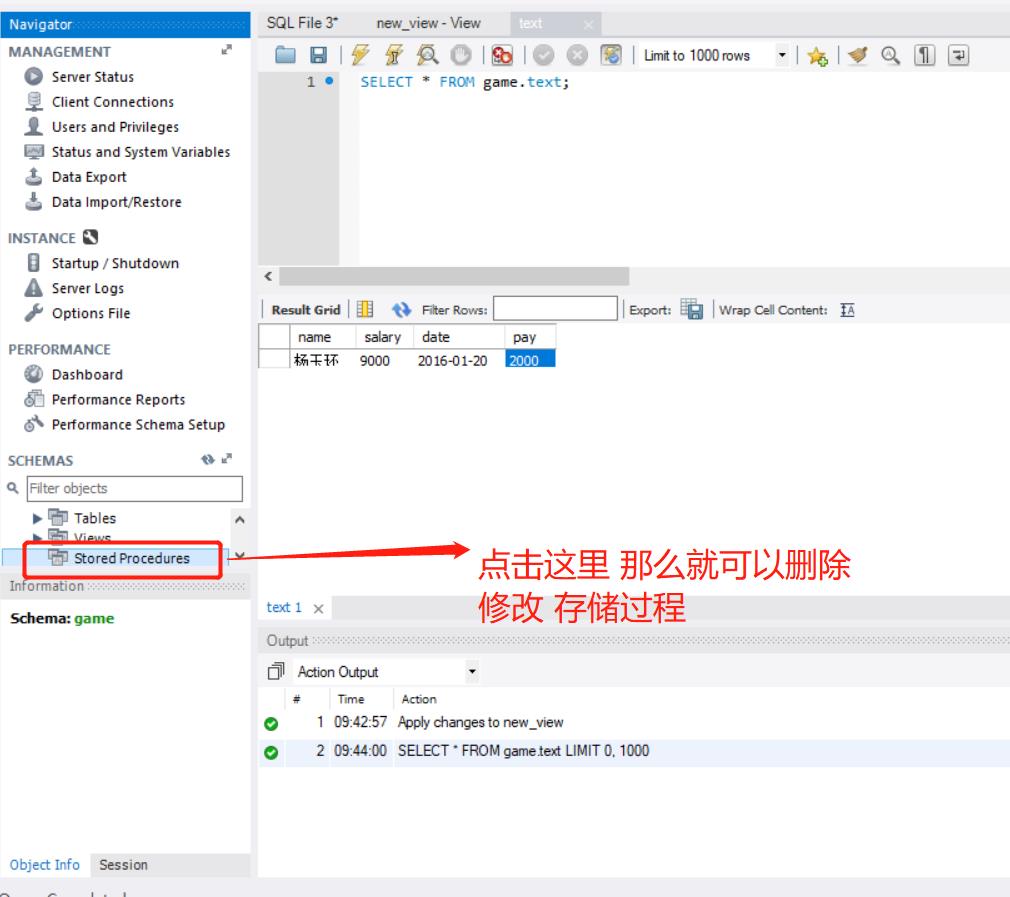
触发器

然后点击 Alter Insert 创建触发器
用户和权限
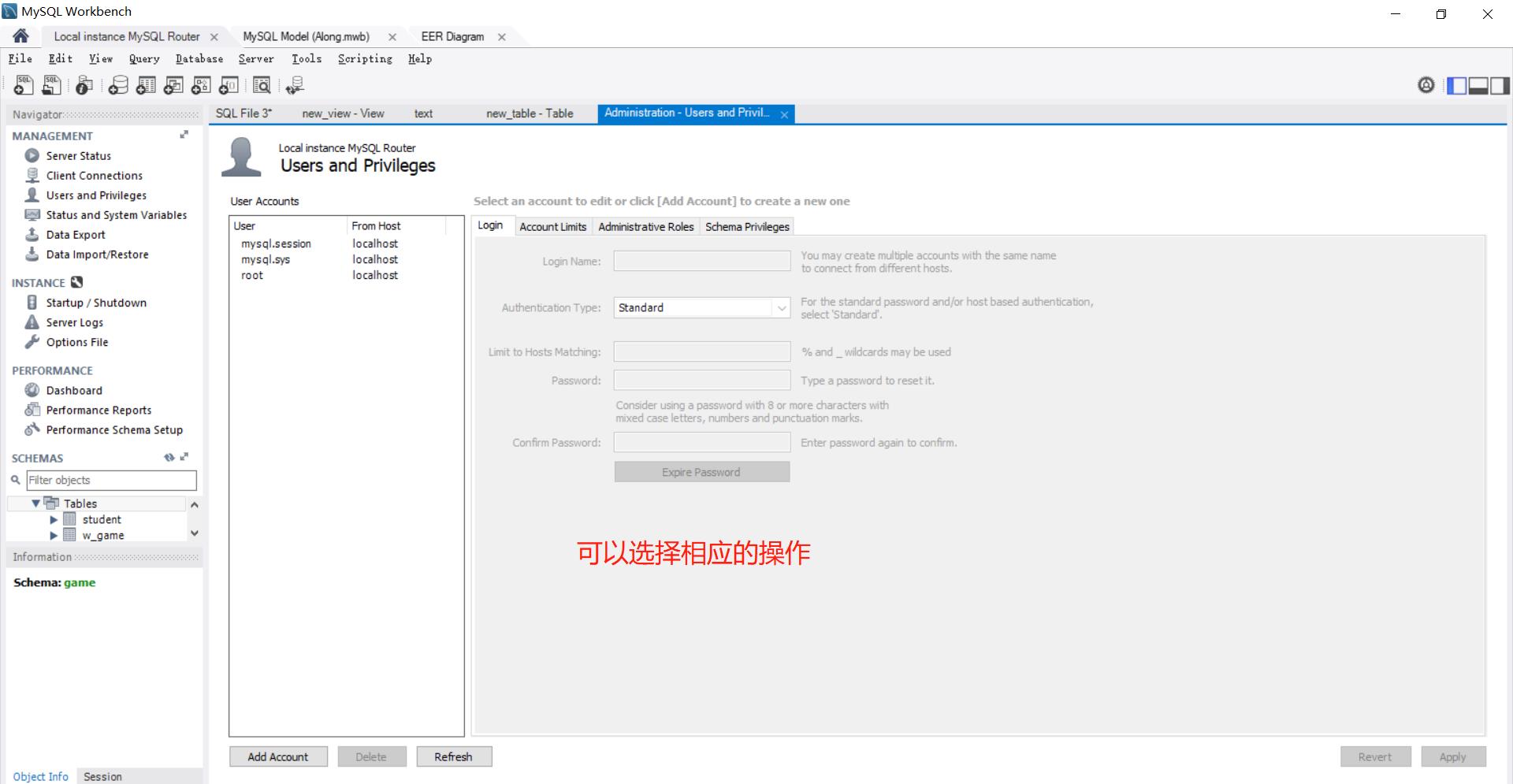
1 创建用户
在菜单栏中选择 Server 菜单,在展开的列表中选择 Users and Privileges 选项。

左上角的方框中显示当前数据库中的用户列表,包括数据库系统默认的用户 mysql.session、mysql.sys、root 以及自定义的用户,同时列表中还显示用户的主机名称,如 localhost。在管理界面的左下角可以单击 Add Account 按钮,即可创建一个新用户,如下图所示。
从零开始搭建公司SpringCloud架构技术栈(史上最细),这套架构绝了!
作者:Anakki
来源:blog.csdn.net/qq_29519041/article/details/85238270
上一篇:Maven官宣:干掉Maven和Gradle!推出更强更快更牛逼的新一代构建工具,炸裂!
一、微服务基础
1.什么是SpringCloud?
SpringCloud官网:https://spring.io/projects/spring-cloud(个人建议是用谷歌浏览器访问官网打开中文翻译粗略把官网读一遍)
个人理解:
以前的服务器就好像,一个会语数外全能的老师,为学生提供服务,这个老师生病了,那全校停课。现在微服务流行后,学校有了数学教研组,语文教研组,外语教研组,每个教研组有一群老师具体负责某科的教学,缺了谁,学校都照样运转。
而这个变化中,那些改变历史的程序员就是把一个服务器中的众多服务,或好几台服务器中的众多服务,分类出来,解耦合出来,把他们类似的功能交给同一个集群来做,把互相耦合在一起的功能剥离出来,按业务,按功能来把他们作为一个个微服务放在服务器上,而这个服务器就只提供一个服务,或较少的服务。让一个超大的服务逻辑,解耦合为一个个小服务,均匀的分布在各自的服务器中。微服务就微在这。
每个教研组就是一个微服务集群。他们提供同样的服务,而注册中心Eureka就是这个存放这个教研组老师名单的地方,学生们想先访问这个注册中心获取教师名单,然后根据相应的负载方法去访问各自老师。不至于让集群中某一老师累死也不至于让某一老师闲死。
而Zuul网关呢,就是学校的门卫,某些学生来学校找谁,它负责指引(路由),并且通过一些非常简单的配置,达到阻拦一些人进入(身份验证),或者控制想学数学的人只能去数学教研组,不能去核能教研组学怎么造原子弹(权限验证)。
那Hystrix熔断器呢,可以把它当成学校的志愿者,当一个教研组集体罢课后,学生找不到老师了,这些志愿者及时的告诉来访问的学生,相应的结果,异常信息等,免得大量的学生在学校等待,这些志愿者赶快把这些等待的学生梳理出去,学生一直在学校等待,那其他需要学生的学校,也会等待学生,最后造成大面积的学校瘫痪。这里学生我们看成一个个请求。熔断器就是把某事故的蔓延即使熔断了。
当然这些组件也是微服务需要注册到Eureka注册中心
那SpringCloud就可以看成是这个学校了。众多上面提到的组件相当于都是这个学校的各职能部门。
二、微服务的搭建
ps: 博主基于Maven+idea搭建。
另外SpringCloud需要基于springboot搭建。
引入Spring Boot相关依赖:这里的springboot用的是1.5.7版本;引入Spring Cloud相关依赖:这里为 Edgware.SR5
2.1 工程初始化配置
在Idea中创建工程:File -> New ->Project
点击 Empty Project -> Next

项目命名 -> 项目位置
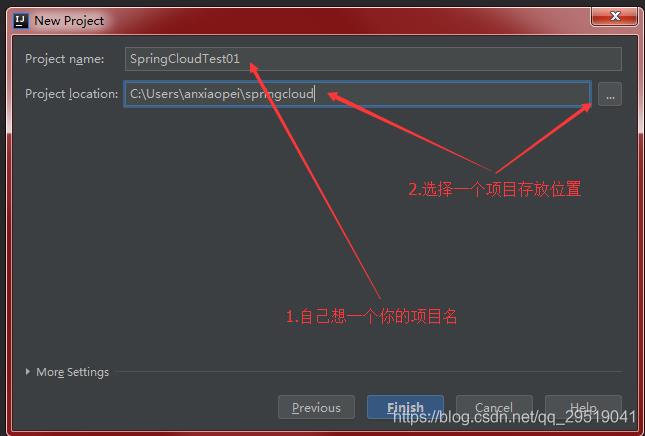
选择模组 modules ->next

进入新的窗口后,开始配置Maven,打开设置 setting
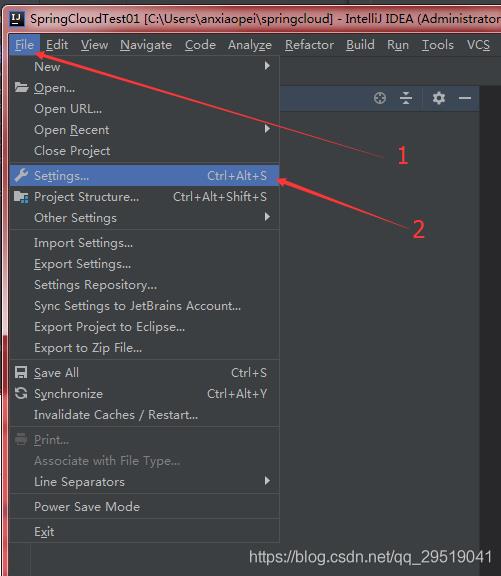
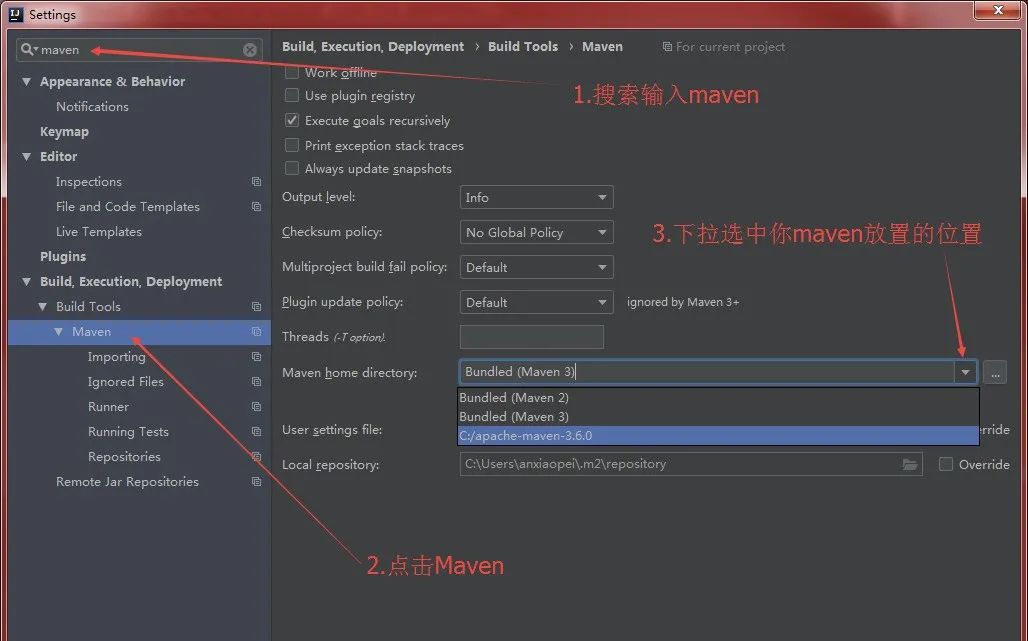
因为我之前做过配置,因此只需要改变框1的路径,如第一次配置需要自己找到你maven放置的位置,以及settings.xml,repository的位置,实在不会的百度 maven集成idea

3个框选择完毕后点击 ok
接下来新建module

这里可能会出现加载不出archetype list的问题

用了网上的所有解决办法花了3个小时解决都没用,重启之后竟然可以了····你敢信?????小时候网吧网管的至理名言都忘了!!重启一下嘛!!
出来之后 选择quickstart ->下一步
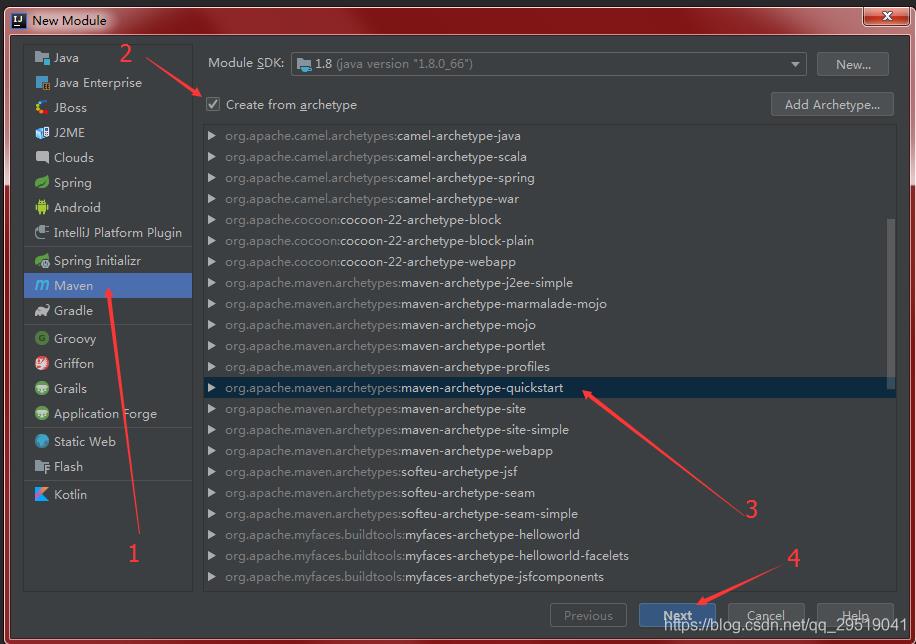
名字自己想 想好后,复制一下你想好的 ArtifactId点击Next,groupId为组织名 也是自己想一个,一般为公司网址反写。另外搜索公众号互联网架构师后台回复“2T”,获取一份惊喜礼包。
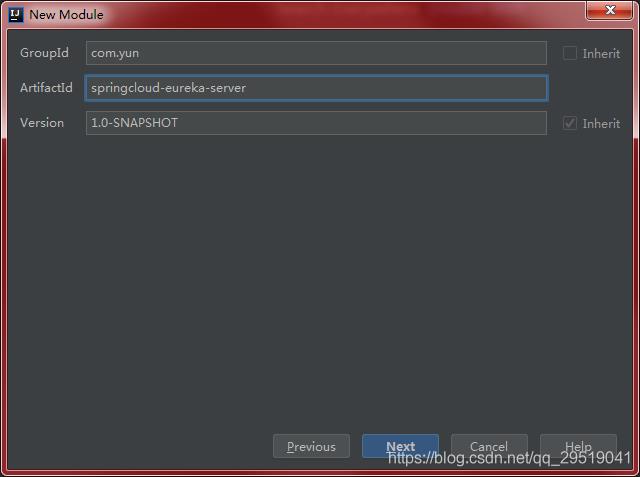
粘贴后下一步
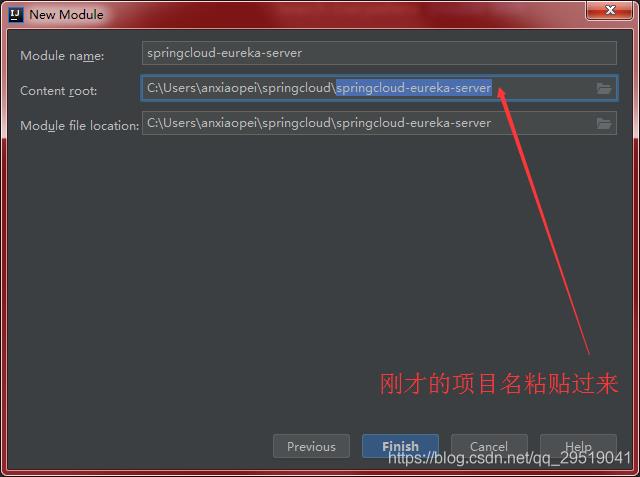
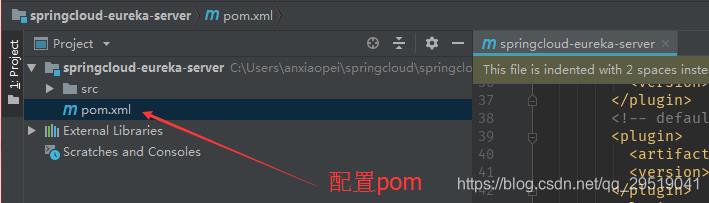
提供注册服务的服务器pom.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yun</groupId>
<artifactId>springcloud-eureka-server</artifactId>
<version>1.0-SNAPSHOT</version>
<name>springcloud-eureka-server</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<!--引入springboot-parent父项目-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.7.RELEASE</version>
</parent>
<dependencies>
<!--引入springcloud的euekea server依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
<!--指定下载源和使用springcloud的版本-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Edgware.SR5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>点击Import Changes
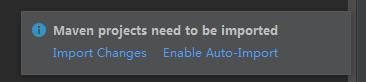
等待右下角加载springcloud的依赖

2.2 Springboot的搭建 以及提供注册服务 的 服务配置
创建resources文件夹

并设置作为资源根目录,之后文件变成这样 之后文件夹变成有黄色的横杠
之后文件夹变成有黄色的横杠
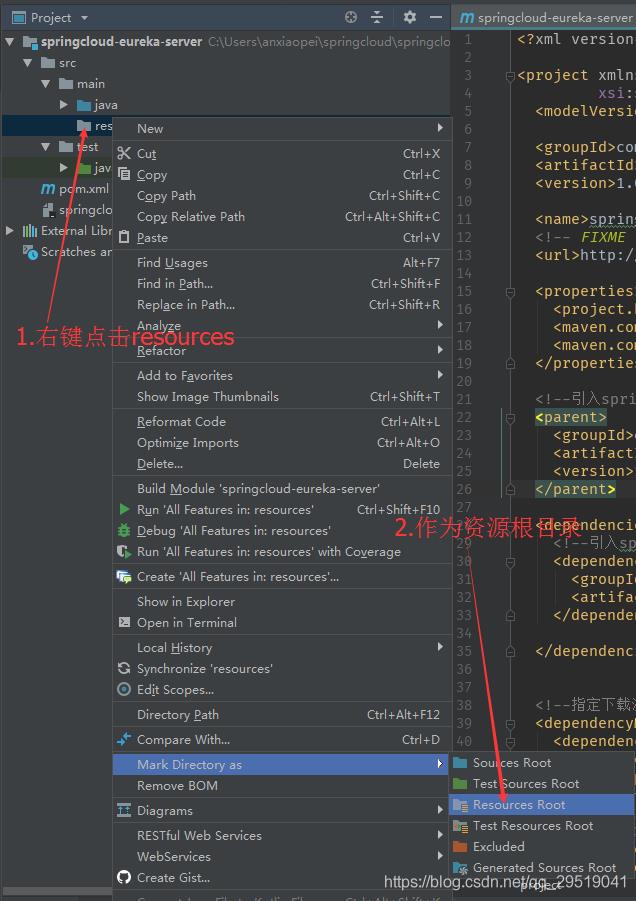
在resources下新建文件,文件名为application.yml (对是yml 不是xml ,博主第一次学习时,还以为是其他博主打错了,踩了一个小坑)
配置yml,注意:如果只配置前两行端口号信息会报错

server:
port: 8700 # 端口自己决定
# 指定当前eureka客户端的注册地址,也就是eureka服务的提供方,当前配置的服务的注册服务方
eureka:
client:
service-url:
defaultZone: http://$eureka.instance.hostname:$server.port/eureka
register-with-eureka: false #自身 不在向eureka注册
fetch-registry: false #启动时禁用client的注册
instance:
hostname: localhost
#指定应用名称
spring:
application:
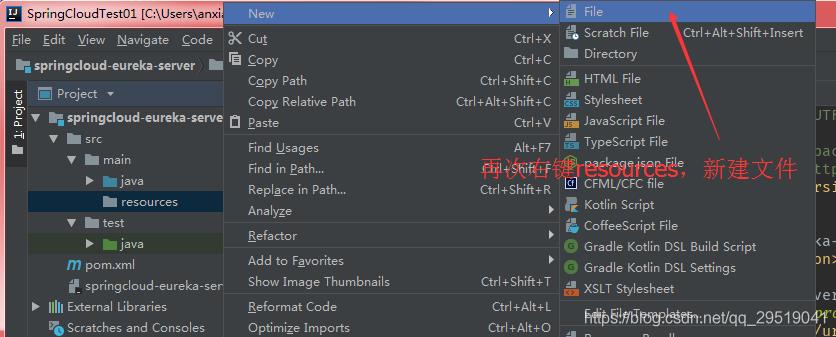
name: eureka-server知识补充:

开发springboot的入口类 EurekaServerApplication.java
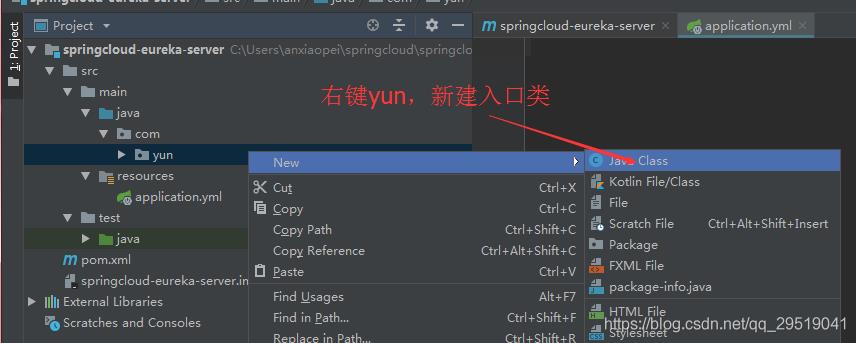
EurekaServerApplication.java
package com.yun;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer //当前使用eureka的server
public class EurekaServerApplication
public static void main(String[] args)
SpringApplication.run(EurekaServerApplication.class,args);
右键运行当前类:

运行成功console画面

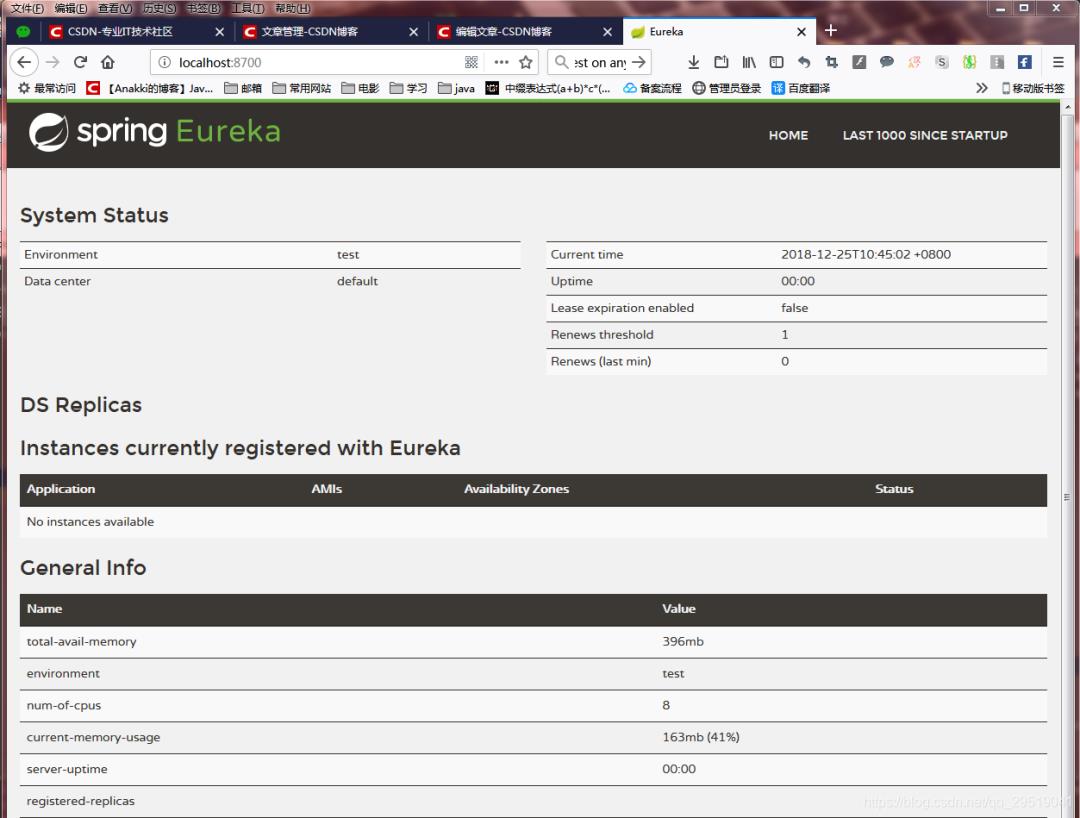
尝试进入eureka管理界面 端口号为 yml里配置的(端口号自己设置 需要大于公用和保留的端口号)1024~65535
一般我喜欢设置为 8700到8800之间
如下 管理界面已经可以登录了。
2.3 客户端client 提供真正服务的角色的配置, 它提供服务 在 服务注册方server (注册中心)进行注册
同样新建module,选择quickstart点击下一步

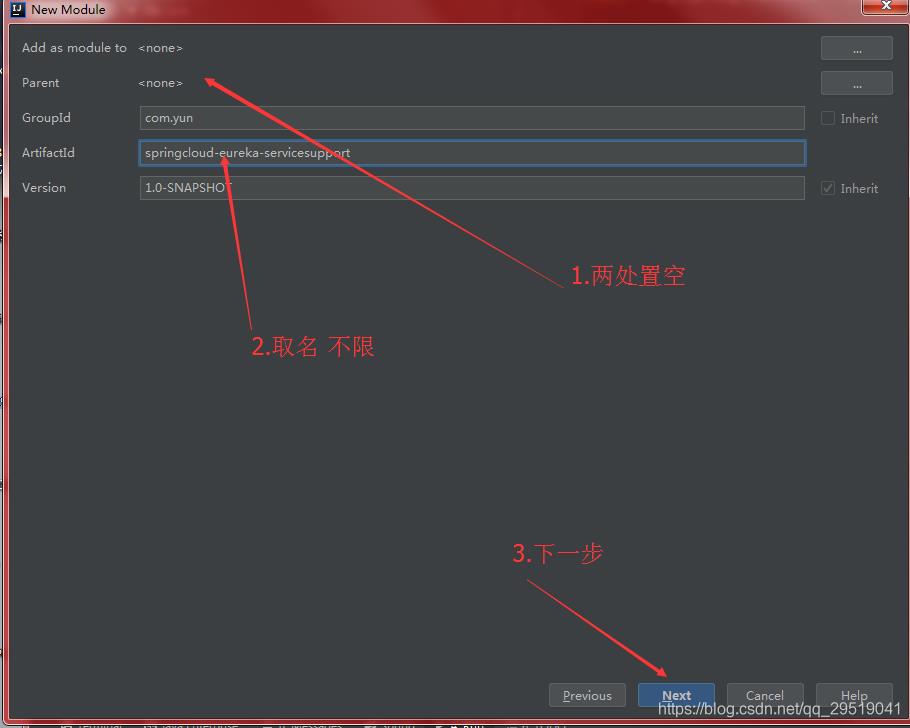
两个位置 置空
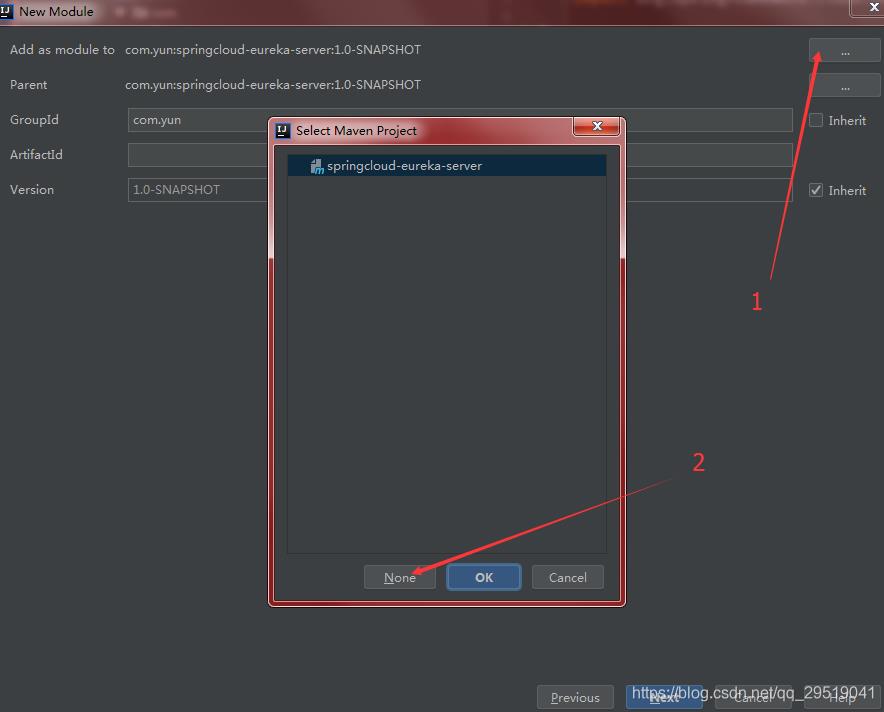
取名 下一步
注意这里要在根目录springcloud 下创建模组,content root 会默认在之前的模组之下创建模组 这样创建模组会出现问题并报错

推荐这种配置方法 在content root下springcloud后改名字 如下图配置点下一步,红框处一般默认为上一个模组的文件目录名,需要改为你的模组名
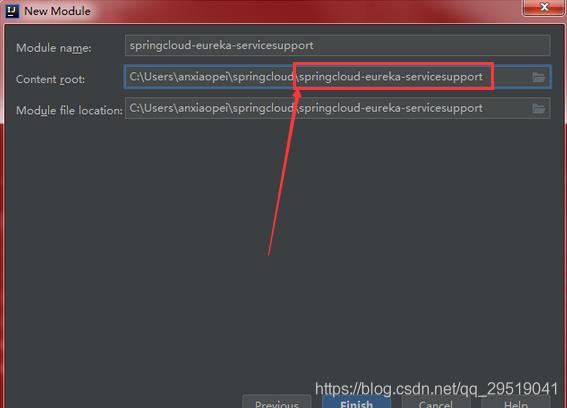
成功后为并列状态,如不为并列或报错请重新配置
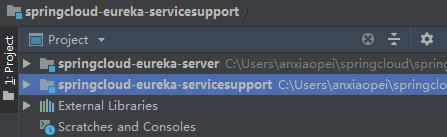
配置servicesupport的pom,与server的pom配置相同,只需要把第一个pom的1的方框处server改为client
和第一个微服务同理 我们需要配置入口类 pom.xml application.yml,因为是服务提供者,这里还需编写服务类controller
application.yml
server:
port: 8701 # 服务提供方
# 指定当前eureka客户端的注册地址,
eureka:
client:
service-url:
defaultZone: http://$eureka.instance.hostname:8700/eureka
instance:
hostname: localhost
#当前服务名称
spring:
application:
name: eureka-servicepom.xml:
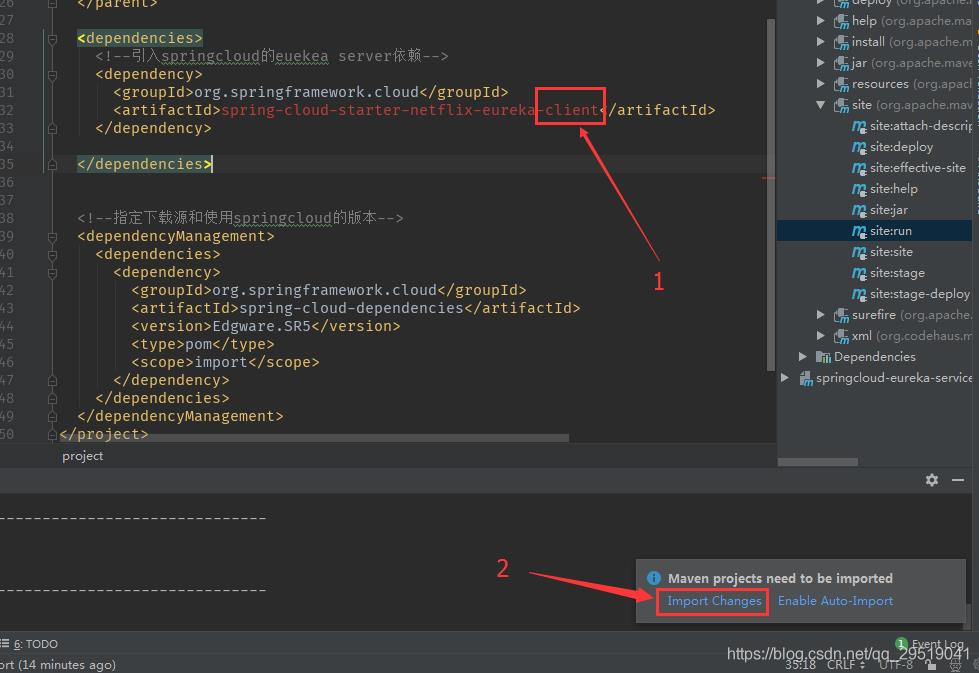
编写所提供的 服务controller:
package com.yun;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/Hello")
public class Controller
@RequestMapping("/World")
public String helloWorld(String s)
System.out.println("传入的值为:"+s);
return "传入的值为:"+s;
入口类 并运行此微服务:
package com.yun;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient//代表自己是一个服务提供方
public class EurekaServiceApplication
public static void main(String[] args)
SpringApplication.run(EurekaServiceApplication.class,args);
右键入口类名点击 run(当然开启此服务时需要先开启server服务 就是我们第一个编写的微服务)

此时再进入服务注册的页面 http://localhost:8700/
可以看见服务提供者已被注册进 服务注册者
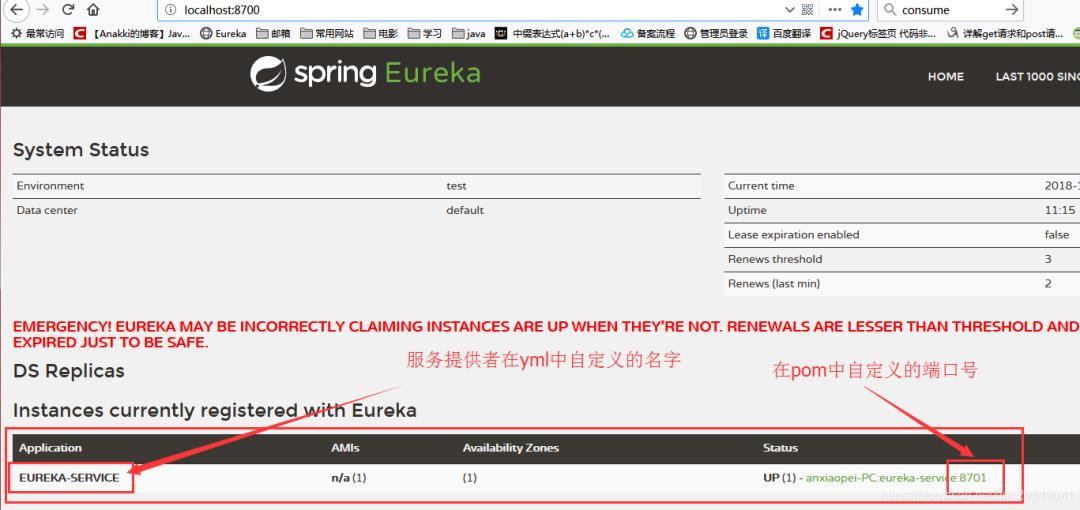
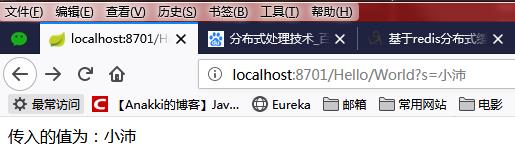
在直接访问一下服务提供者的 网络位置http://localhost:8701/Hello/World?s=小沛
我们已经看见 可以访问了,证明此微服务可用。
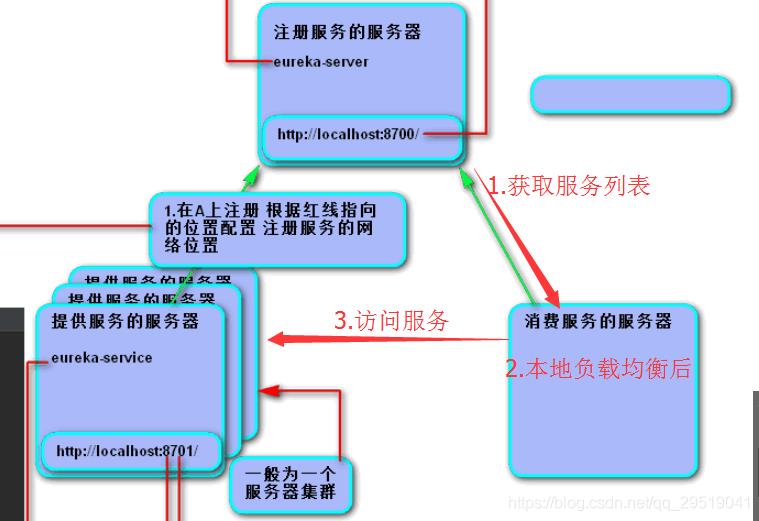
但是我们一般不直接调用所需的微服务,而是经过提供注册服务的服务器server,获取所需的服务提供者列表(为一个列表,此列表包含了能提供相应服务的服务器),他们也许是个集群,因此server会返回一个 ip+端口号的表,服务消费者通过相应算法访问这表上的不同服务器,这些服务器提供的是相同的服务,这种在服务消费者一方挑选服务器为自己服务的方式是一种客户端的负载均衡。
目前博主所知的有 轮询和随机两种方式 访问这些服务器,轮询就是循环的意思,假如有3台服务器,访问方式就是1,2,3,1,2,3,1,2,3····,随机就是随机,回想一下random方法,一种无规律的方式。这两种方式都是为了,访问每个服务器的可能性尽量的相同。还有权重负载这种算法,意思就是 根据服务器负载能力的分配相应的服务。能力大的干得多。能力小的干得少。
2.4 服务的调用方式
第一种调用方式:restTemplate+ribbon


第二种调用方式:feign

2.4.1 restTemplate+ribbon
ribbon是一种负载均衡的客户端,它是什么呢?请详读https://www.jianshu.com/p/1bd66db5dc46
可以看见其中的一段如下:
而客户端负载均衡和服务端负载均衡最大的不同点在于上面所提到服务清单所存储的位置。在客户端负载均衡中,所有客户端节点都维护着自己要访问的服务端清单,而这些服务端端清单来自于服务注册中心,比如上一章我们介绍的Eureka服务端。同服务端负载均衡的架构类似,在客户端负载均衡中也需要心跳去维护服务端清单的健康性,默认会创建针对各个服务治理框架的Ribbon自动化整合配置,比如Eureka中的org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration,Consul中的org.springframework.cloud.consul.discovery.RibbonConsulAutoConfiguration。在实际使用的时候,我们可以通过查看这两个类的实现,以找到它们的配置详情来帮助我们更好地使用它。
接下来我们来搭建基于ribbon的客户端,他用于消费服务。
同理先搭建springboot的环境
与之前搭建servicesupport不同的是:
第一步:现在pom中需要在dependencies中添加ribbon依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
</dependency>第二步:yml如下配置:
server:
port: 8702 # 服务消费方
# 指定当前eureka客户端的注册地址,
eureka:
client:
service-url:
defaultZone: http://$eureka.instance.hostname:8700/eureka
instance:
hostname: localhost
#当前服务名称
spring:
application:
name: eureka-consumer服务的消费方依旧需要在注册方8700端口去注册。配置当前服务消费方的端口8072,名字为eureka-consumer。另外搜索公众号互联网架构师后台回复“2T”,获取一份惊喜礼包。
第三步:依旧需要启动类,因为它是一个springboot的架构:
package com.yun;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient //当前使用eureka的server
public class EurekaConsumerApplication
public static void main(String[] args)
SpringApplication.run(EurekaConsumerApplication.class,args);
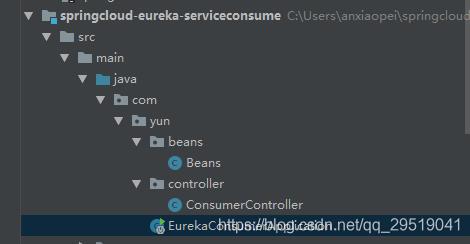
如上图:
我们需要一个controller类来编写ribbon的代码。
package com.yun.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@RequestMapping("/Hello")
class ConsumerController
@Autowired
private LoadBalancerClient loadBalancerClient;
@Autowired
private RestTemplate restTemplate;
@RequestMapping("/Consumer")
public String helloWorld(String s)
System.out.println("传入的值为:"+s);
//第一种调用方式
//String forObject = new RestTemplate().getForObject("http://localhost:8071/Hello/World?s=" + s, String.class);
//第二种调用方式
//根据服务名 获取服务列表 根据算法选取某个服务 并访问某个服务的网络位置。
//ServiceInstance serviceInstance = loadBalancerClient.choose("EUREKA-SERVICE");
//String forObject = new RestTemplate().getForObject("http://"+serviceInstance.getHost()+":"+serviceInstance.getPort()+"/Hello/World?s="+s,String.class);
//第三种调用方式 需要restTemplate注入的方式
String forObject = restTemplate.getForObject("http://EUREKA-SERVICE/Hello/World?s=" + s, String.class);
return forObject;
我们常用第三种调用方式。
第一种是直接调用:不经过注册中心那服务列表,直接访问的servicesupport
第二种:是根据服务名选择调用,如上图需要做如下注入
@Autowired
private LoadBalancerClient loadBalancerClient;
如上图代码中第二种调用方法的代码所示。
用服务名去注册中心获取服务列表,当前客户端底层会做随机算法的选取获得服务并访问。
第三种需要一个@Bean的注解自动注入并直接调用restTemplate对象调用服务。底层调用模式与第二种调用方式一样。如下:
package com.yun.beans;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class Beans
//管理简单对象
@Bean
@LoadBalanced
public RestTemplate getRestTemplate()
return new RestTemplate();
@Bean注解告诉工厂,这个方法需要自动注入。
@LoadBalanced,表示需要做负载匀衡。
然后如controller中一样注入一下restTemplate,并且使用他,区别是可以直接使用服务名访问了
String forObject = restTemplate.getForObject("http://EUREKA-SERVICE/Hello/World?s=" + s, String.class);
开始测试:
1.运行server的启动类:
2.运行servicesupport的启动类:
3.运行serviceconsume的启动类:
浏览器访问:

8072为服务消费方的端口
访问方法解析:
访问服务消费方@RequestMapping指定的路径及消费方的端口来访问消费方的controller
controller根据服务名去server方获取获取服务列表,获取服务列表后根据随机的模式负载匀衡后去选择服务地址去访问servicesupport:如下图
---------- 更新于星期日2018年12月30日 20:02 待续....---------
2.5 Eureka server的高可用配置
点击下图配置
接下来配置三台01,02,03的虚拟机参数
01:8699
02:8698
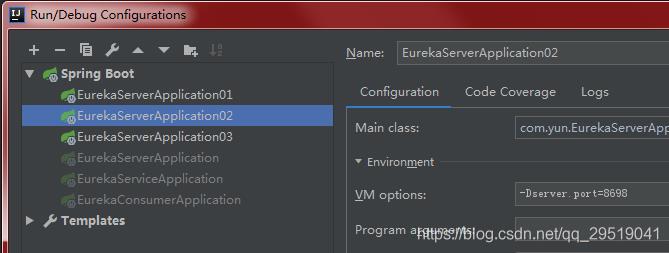
03:8697
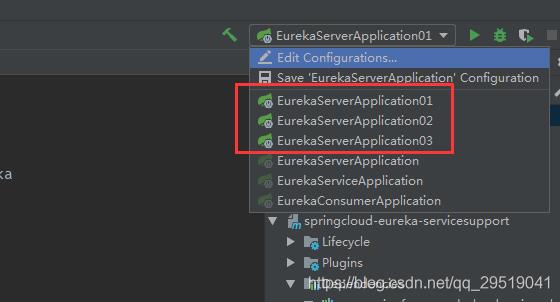
之后点ok保存,可看见多出三个启动项
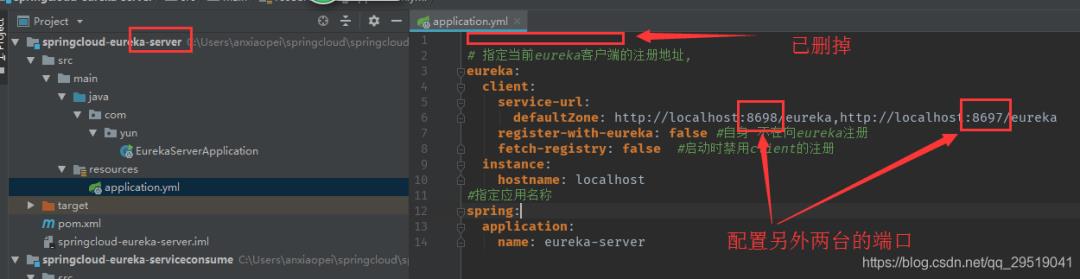
接下来分别改注册端口号,defaultZone分别启动三个启动项
打开server的yml配置,删掉前两行端口号配置(图中有错,请把instance 和hostname那两行删掉)
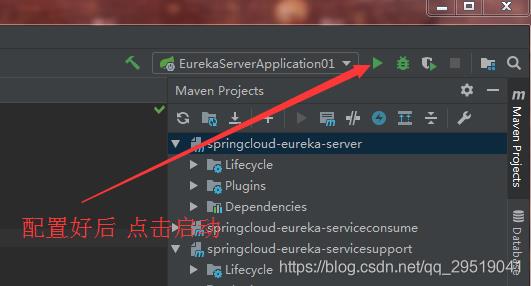
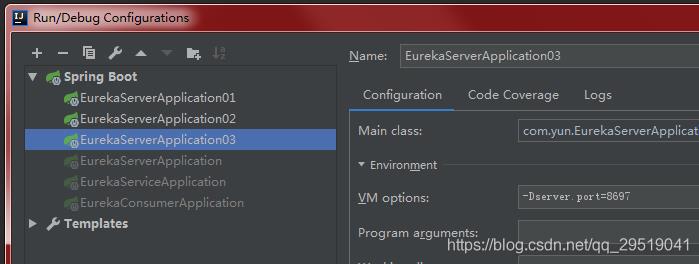
同理,我们再次改动端口号为8699和8697后,把启动项改为02,之后启动(图中有错,请把instance 和hostname那两行删掉)
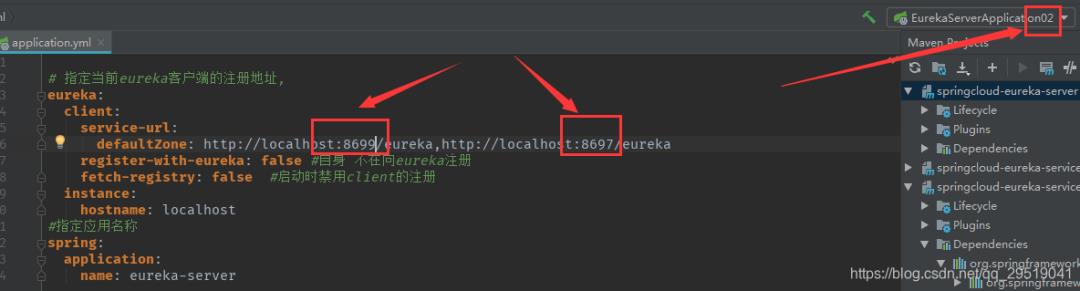
同理把yml端口改为8699 和 8698后,把启动项改为03,之后启动(图中有错,请把instance 和hostname那两行删掉)
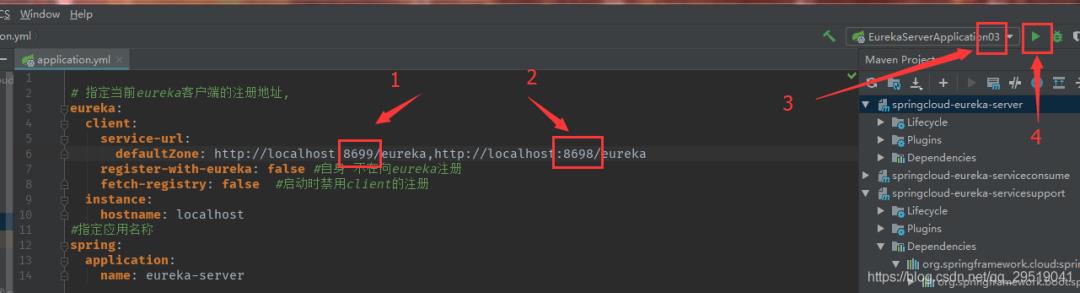
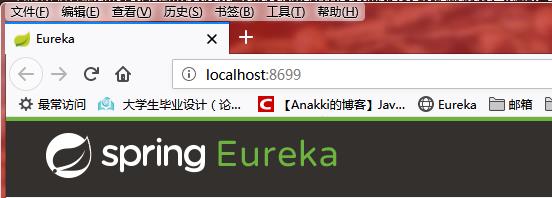
启动后分别访问三个01,02,03端口,已经可以看见可以访问了。


打开服务提供方的yml配置如下,把端口号改为三个中其中的一个。
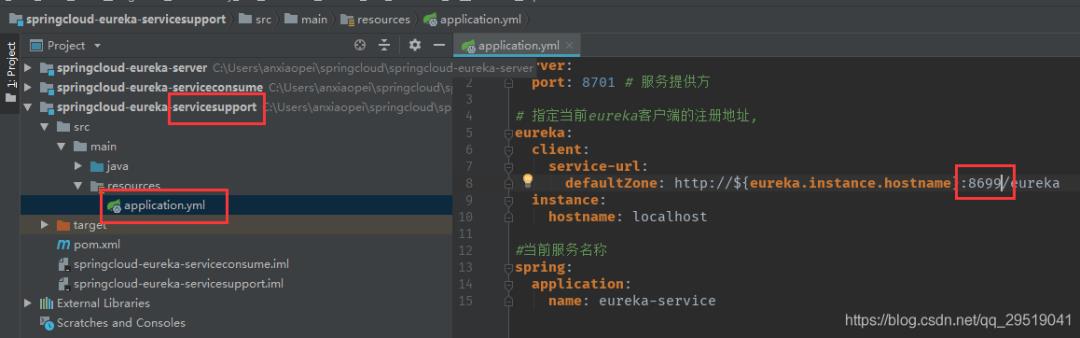
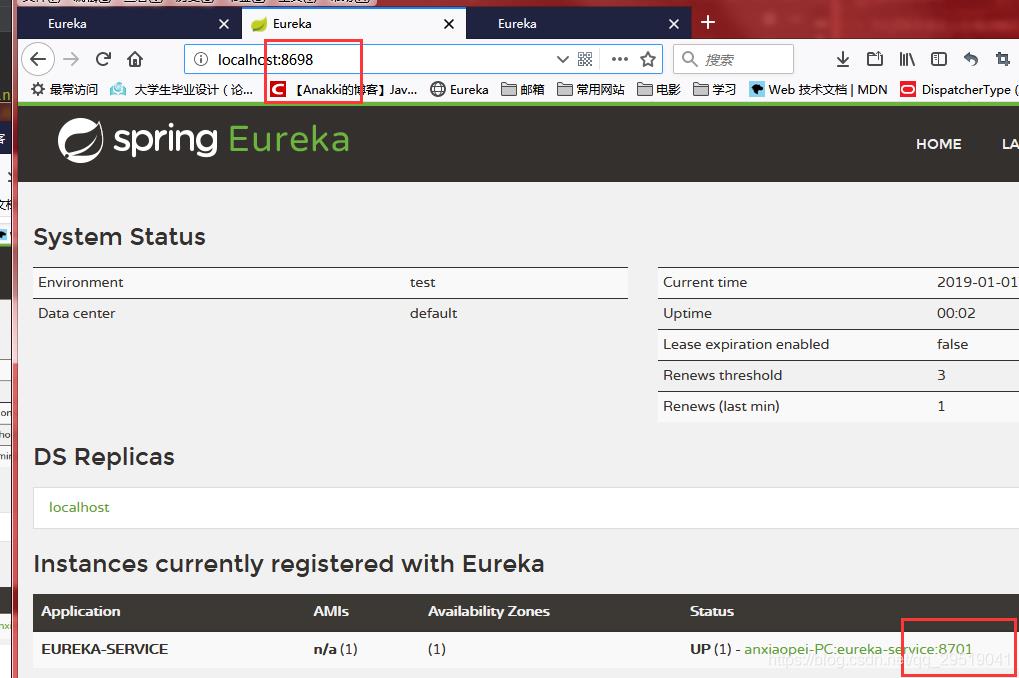
启动服务提供方之后,再次访问三个01,02,03我们会发现
重点:即使服务提供方只注册了一个端口号8699,但是另外两个端口号,也能感知到服务提供方8701的存在了。如下图:

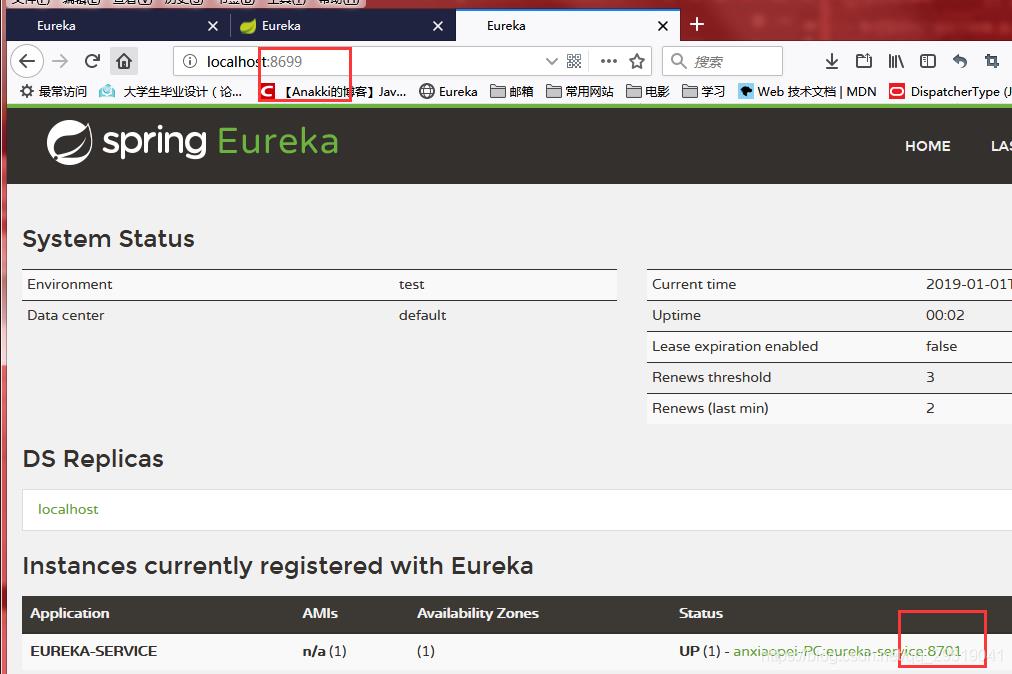
接下来像服务消费方中添加服务注册者的端口号,这样在server挂掉任何一个的时候,都能有其他的server也能获取服务列表

访问以下服务消费方,发现可以通过消费方调用server服务列表并且访问service了

我么随便关闭其中两个server的副本,重启serviceconsume,再进行访问。必须重启serviceconsume才能清空缓存,清掉consume里面有的服务列表。

上图发现即使关闭两台server后依旧可以访问,如下图,依旧从server中获取了服务列表,从中也能看见之后不用再获取服务列表了。

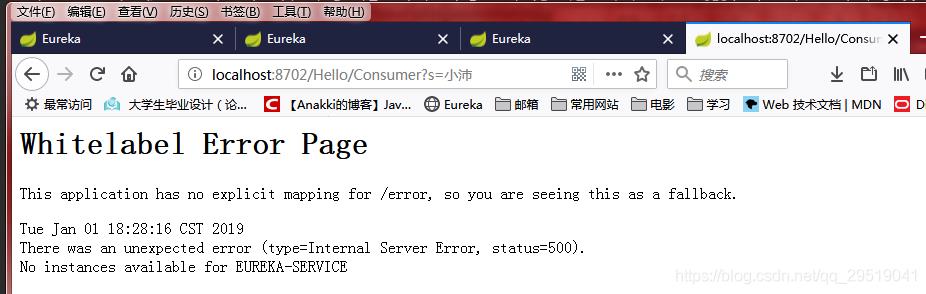
但是当我们关掉所有server后。访问还是没问题,因为缓存了服务列表。

但是让我们来重启一下serviceconsume,再访问就不行了。
综上我们就完成了springcloud中server的高可用配置
搭好了别忘点赞呀~
相关阅读:2T架构师学习资料干货分享
PS:如果觉得我的分享不错,欢迎大家随手点赞、转发、在看。以上是关于MySQL Workbench 操作详解(史上最细)的主要内容,如果未能解决你的问题,请参考以下文章
从零开始搭建公司SpringCloud架构技术栈(史上最细),这套架构绝了!