[从0开始机器学习]4.线性回归 正规方程
Posted ζั͡ ั͡雾 ั͡狼 ั͡✾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[从0开始机器学习]4.线性回归 正规方程相关的知识,希望对你有一定的参考价值。
🐺本博主博客:ζั͡ ั͡雾 ั͡狼 ั͡✾的博客
🎀专栏:机器学习
🎀专栏:爬虫
🎀专栏:OpenCV图像识别处理
🎀专栏:Unity2D
⭐本节课理论视频:P23-P25 正规方程
⭐本节课推荐其他人笔记:正规方程(Normal equations)推导过程_momentum_的博客
🐺机器学习通过文字描述是难以教学学会的,每一节课我会推荐这个理论的网课,一定要看上面的理论视频!一定要看上面的理论视频!一定要看上面的理论视频!所以我只是通过代码实现,并通过注释形式来详细讲述每一步的原因,最后通过画图对比的新式来看结果比较。
⭐机器学习推荐博主:GoAI的博客_CSDN博客-深度学习,机器学习,大数据笔记领域博主
😊如果你什么都不懂机器学习,那我推荐GoAI的入门文章:机器学习知识点全面总结_GoAI的博客-CSDN博客_机器学习笔记
在线性回归中实际就是求代价函数对系数变量求导,导数为0的时候,即代价函数最小的时候,系数矩阵的值。以多元一次函数为例
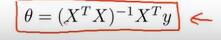
使用前提:1.X特征数量小于样本数量
2.X矩阵中不存在线性相关的量
缺点:n很大时候(n>10000),比起梯度下降法,运行远远慢
import numpy as np
# 全局变量
# 生成数据
# X中每一行代表一条数据i,代表着一个等式,其中列数代表着变量数,每个变量的系数是不知道的
# 每一行数据是y=k0x0+k1x1+k2x2+k3x3+k4x4,
# k是我们要回归的系数向量,x1,x2,x3,x4是每一行数据其中
# k0代表常数,x0恒为1
X = np.array([[5, 100, 58, -3],
[7, 120, 59, -3],
[3, 140, 50, -5],
[10, 80, 45, -1],
[6, 96, 55, -7],
[15, 200, 52, -11],
[11, 125, 65, -5],
[12, 63, 100, -3],
[20, 500, 66, -10]])
# 假设K系数为这个,咱们的算法就是逼近这个结果,当然,如果有自己的数据就更好了
preK = [12, -1, 2, 8] + np.random.random((1, 4))
# Y中的数据量等于X矩阵的行数
Y = (np.dot(preK, X.T) + np.random.random() * 15).ravel() # 加的一项是随机常数项,最后将矩阵转换成数组向量
# X矩阵中第一列加入x0=1参数
X = np.insert(X, 0, np.ones((1, len(X))), axis=1)
# 数据个数
m = len(X)
# 参数个数
n = len(X[0])
# 输出
print(f"有n个参数,就是X列数算上常数项所乘的单位1")
print(f"有m条数据,就是加常数后X行数")
# 系数变量K矩阵就是多元参数的系数,就是我们要递归的重点变量,先给这个矩阵的每个值都赋予初始值1
K = np.ones(n)
#正规方程,固定公式详细推导见吴恩达P23
def NorEq():
global X,Y,K
m1=np.dot(X.T,X)
m2=np.matrix(m1).I
m3=np.dot(m2,X.T)
K=np.dot(m3,Y.T)
if __name__ == "__main__":
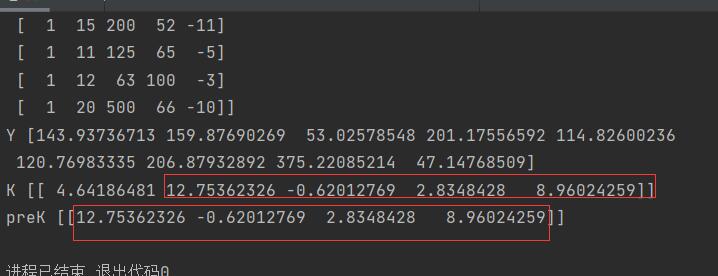
print("X",X)
print("Y",Y)
NorEq()
print("K",K)
print("preK",preK)可见结果完全一致
以上是关于[从0开始机器学习]4.线性回归 正规方程的主要内容,如果未能解决你的问题,请参考以下文章