ELK 日志系统部署实现
Posted niaonao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK 日志系统部署实现相关的知识,希望对你有一定的参考价值。
文章目录
1. 前言
ELK 全家桶官网: elastic.co/cn
ELK 日志系统的常见解决方案:
通常的产品或项目部署至服务器,运行服务后会生成日志文件。
通过 Filebeat 监控相关文件夹,当有新日志产生,就读取新日志,将日志输送到 Kafka 中。经由 Logstash 消费 Kafka 生产的数据,进行加工过滤后输出到 ElasticSearch 进行日志数据的存储与全文检索。使用 Kibana 对日志数据进行可视化操作。
2. ELK 服务安装部署
2.1 Log4j 配置
<1> Log4j 安装
- Linux版安装包下载
wget http://mirror.bit.edu.cn/apache/logging/log4j/2.11.1/apache-log4j-2.11.1-src.tar.gz - 解压
应用安装路径/opt/elkf/apache-log4j
tar apache-log4j-2.11.1-src.tar.gz
mv apache-log4j-2.11.1-src apache-log4j
<2> Log4j 配置
服务器新建log4j-server.properties配置文件
接收应用端日志并保存至指定路径下/opt/elkf/root-log-folder/
示例配置:
#Define a narrow log category. A category like debug will produce some extra logs also from server itself
log4j.rootLogger=DEBUG,A4,file,D,E
log4j.category.org.apache.log4j.net=INFO
# Log Factor 5 Appender
log4j.appender.LF5_APPENDER = org.apache.log4j.lf5.LF5Appender
log4j.appender.LF5_APPENDER.MaxNumberOfRecords = 2000
#Define how the socket server should store the log events
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=/opt/elkf/root-log-folder/RollingFile.log
log4j.appender.file.MaxFileSize=1MB
log4j.appender.file.MaxBackupIndex=50
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=/n/n[%-5p] %dyyyy-MM-dd HH:mm:ss,SSS method:%l%n%m%n
log4j.logger.com.Test= DEBUG, test
log4j.additivity.test=false
log4j.appender.test=org.apache.log4j.FileAppender
log4j.appender.test.File=/opt/root-log-folder/test.log
log4j.appender.test.layout=org.apache.log4j.PatternLayout
log4j.appender.test.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.A4=org.apache.log4j.DailyRollingFileAppender
log4j.appender.A4.file=/opt/elkf/root-log-folder/DailyRollingFile.log
log4j.appender.A4.DatePattern='.'yyyy-MM-dd
log4j.appender.A4.layout=org.apache.log4j.PatternLayout
log4j.appender.A4.layout.ConversionPattern=/n/n[%-5p] %dyyyy-MM-dd HH:mm:ss,SSS method:%l%n%m%n
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = /opt/elkf/root-log-folder/Debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
<3> 服务启动
- 启动命令
java -classpath log4j-1.2.17.jar org.apache.log4j.net.SimpleSocketServer 4712 log4j-server.properties - 若4712端口未开放,需要开启端口并重启防火墙
firewall-cmd --zone=public --add-port=4712/tcp --permanent
2.2 Filebeat 配置
2.2.1 Filebeat 数据流转
<1> 数据流转说明
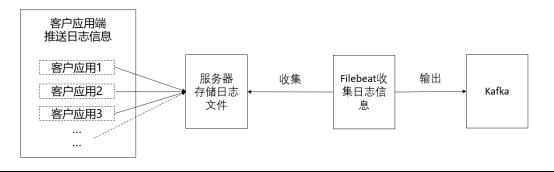
Filebeat 作为轻量级日志收集工具, 可收集服务器存储的日志文件信息; 根据日志来源区分日志type, document_type, log level等; 高版本Filebeat不支持多个输出, 此处配置Filebeat 数据输出到Kafka节点.
<2> 应用配置说明
在filebeat的安装路径的下编辑配置文件filebeat.yml添加output到Kafka, 支持多个prospectors, 仅支持一个output.
filebeat.prospectors:
- type: log
enabled: true
paths:
- /opt/elkf/root-log-folder/*.log
encoding: utf-8
fields:
document_type: root_log_folder
output.kafka:
hosts: ["192.168.200.81:8081"]
enabled: true
topic: logstash-kafka-topic
2.2.2 Filebeat 部署运行
<1> Filebeat 安装
- 产品官方地址
https://www.elastic.co/downloads/beats/filebeat - 应用安装路径
/opt/elkf/filebeat - 安装命令
下载安装包
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.3-linux-x86_64.tar.gz
解压安装包
tar -zxvf filebeat-6.5.3-linux-x86_64.tar.gz
<2> Filebeat的配置
编辑安装路径下配置文件filebeat_kafka.yml
cp filebeat.yml filebeat_kafka.yml
配置收集日志filebeat.prospectors 的日志类型,日志文件存放路径; filebeat 高版本不支持多个输出, 此处配置output.kafka, 指明输出到具体的topic主题.
filebeat.prospectors:
- type: log
enabled: true
paths:
- /opt/elkf/filebeat-6.5.3/log/*.log
encoding: utf-8
fields:
document_type: serverLog
# 从nginx日志输入
- type: log
enabled: true
paths:
- /opt/elkf/nginx/logs/access.log
encoding: utf-8
fields:
document_type: nginxLog
# 从root-log-folder输入
- type: log
enabled: true
paths:
- /opt/elkf/root-log-folder/*.log
encoding: utf-8
fields:
document_type: root_log_folder
output.kafka:
hosts: ["192.168.200.81:8081"]
enabled: true
topic: logstash-kafka-topic
<3> Filebeat运行
在应用安装路径下运行启动命令.
- 应用安装路径
/opt/elkf/filebeat - 运行命令
./filebeat -e -c filebeat_kafka.yml -d "publish"
2.3 Kafka 配置
2.3.1 Kafka 与 Zookeeper
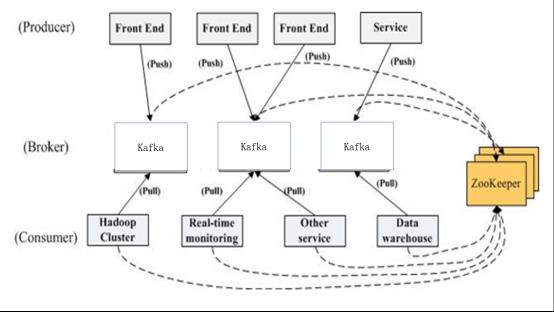
2.3.2 Zookeeper 的作用
- Broker注册
Broker在zookeeper中保存为一个临时节点 - Topic注册
在kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况都保存在zookeeper中 - 生产者负载均衡
当Broker启动时,会注册该Broker的信息,以及可订阅的topic信息。生产者通过注册在Broker以及Topic上的watcher动态的感知Broker以及Topic的分区情况,从而将Topic的分区动态的分配到broker上. - 消费者与分区的对应关系
对于每个消费者分组,kafka都会为其分配一个全局唯一的Group ID,分组内的所有消费者会共享该ID,kafka还会为每个消费者分配一个consumer ID,通常采用hostname:uuid的形式。在kafka的设计中规定,对于topic的每个分区,最多只能被一个消费者进行消费,也就是消费者与分区的关系是一对多的关系。 - 消费者负载均衡
消费者服务启动时,会创建一个属于消费者节点的临时节点,节点的路径为 /consumers/[group_id]/ids/[consumer_id],该节点的内容是该消费者订阅的Topic信息。每个消费者会对/consumers/[group_id]/ids节点注册Watcher监听器,一旦消费者的数量增加或减少就会触发消费者的负载均衡 - 消费者
kafka有消费者分组的概念,每个分组中可以包含多个消费者,每条消息只会发给分组中的一个消费者,且每个分组之间是相互独立互不影响的。 - 消费者的offset
在kafka的消费者API分为两种(1)High Level Api:由zookeeper维护消费者的offset (2) Low Level API,自己的代码实现对offset的维护。由于自己维护offset往往比较复杂,所以多数情况下都是使用High Level的APIoffset
2.3.3 Kafka 数据流转
<1>数据来源
- Filebeat,Filebeat 将数据输送到 Kafka
- Log4j,Log4j 使用 appender 将数据推送到 Kafka
<2>数据流向
- 使用 Logstash 中的 Kafka input 插件,将数据直接输送到 Logstash 中进行过滤筛选,再将处理后的数据推送到 ElasticSearch 中去。
2.3.4 Kafka 安装部署
<1> Zookeeper 介绍
- 软件版本
Zookeeper 3.4.10 - 链接
http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz - 介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务, 是 Google的Chubby一个开源的实现
<2> Zookeeper 安装
解压软件包至路径下/opt/elkf/
tar -zxvf zookeeper-3.4.12.tar.gz
修改配置文件
(1)修改文件名称
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg 设置dataDir , dataLog
(2)设置zookeeper节点的id,即在dataDir指定的目录下建立myid文件,设置id(在终端执行echo “1” >> myid),这个需要在每个zookeeper节点中执行,且id需要不一样。
(3)修改配置文件zoo.cfg在配置文件中添加
server.1=x.x.x.x:2888:3888
server.2=x.x.x.x:2888:3888
.........
Server.n=x.x.x.x:2888:3888
1,2是设置的zookeeper的id,2888是节点间通信的TCP端口,3888是用于首领选举的TCP端口
<3> Kafka 介绍
- 软件版本
Kafka 2.12 - 链接
http://mirrors.hust.edu.cn/apache/kafka/2.1.0/kafka_2.12-2.1.0.tgz - 介绍
分布式流平台
<4> Kafka 安装
解压软件包至路径/opt/elkf/下
tar -zxvf kafka_2.12-2.1.0.tgz -C /opt/elkf
修改配置文件 server.properties
(1)broker.id=x(x是整数) ,代表的是 kafka broker 的 id,集群中不同的kafka broker的broker.id 必须不同
(2)设置 log.dirs,这个目录是 kafka 数据存放的目录,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能
(3)设置 listeners=PLAINTEXT://172.16.2.15:9092 , 172.16.2.15 是 ip,这个 ip地址一定要与你的访问 kafka 时的地址一样,否则无法访问。9092 是 kafka 的端口。
(4)设置 zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183,
这个是 zookeeper 的 ip地址与端口号。当有多个 zookeeper 时,即使用 zookeeper 集群时,这时候有多个 zookeeper,这时候不同的 zookeeper 的 ip 与端口需要使用逗号分割
<5> 服务运行与停止
- Zookeeper运行
进入zookeeper目录(包含了bin,conf,lib等文件夹),执行./bin/zkServer.sh start conf/zoo.cfg,这个命令会将zookeeper放在后台执行 - 终止zookeeper
./bin/zkServer.sh stop - 运行Kafka
进入kafka目录(包含了bin,config,libs等文件夹),执行./bin/kafka-server-start.sh -daemon config/server.properties, 注意需要添加-daemon参数,这个参数是将kafka当作守护进程来运行,从而不需要其他的命令来辅助。
网上的运行方式是 nohup ./bin/kafka-server-start.sh config/server.properties & , 这样会生成一个额外的文件,既然它本就支持在后台运行,那么就用它自带的。而且自带的启动方式不会从zookeeper上掉线 - 终止kafka
./bin/kafka-server-stop.sh
2.3.5 Kafka 优化
<1>操作系统方面
- 设置vm.swappines=1,这个表示尽可能的去使用物理内存,而尽可能的避免使用虚拟内存。因为Linux使用磁盘作为虚拟内存,在速度方面要慢于物理内存.
- 设置vm.dirty_background_ratio与vm.dirty_ratio 前者表示定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存;后者表示当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存)(这两个选项的值需要进行测试才能确定)
- 对linux系统的网络栈进行调优,如
net.core.wmem_default,net.core.rmem_default,net.core_wmem_max,net.core.rmem_max,net.ipv4.tcp_wmem,net.ipv4.tcp_rmem,net.core.wmem_max,net.core.rmem_max,net.ipv4.tcp_window_scaling等。 - 对磁盘进行优化,在这里是对文件系统进行选择
<2>kafka软件方面的优化
- 垃圾回收器选项 使用G1垃圾收集器,G1会自动根据工作负荷情况进行自我调节,而且他的停顿时间是恒定的,可以在kafka的启动脚本里添加一行: export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC
-XX:MaxGCPauseMillis=20
-XX:InitiatingHeapOccupancyPercent=35
-XX:+DisableExplicitGC -Djava.awt.headless=true" - 数据中心布局 即最好将集群的broker安装在不同的机架上,至少不要让他们共享可能出现单点故障的基础设施,比如电源和网络
- 共享zookeeper,即使用最新版的kafka,让消费者将偏移量提交到kafka服务器上,避免提交到zookeeper上,减少对zookeeper的流量。
2.4 Logstash 配置与数据流转
2.4.1 Logstash 数据流转
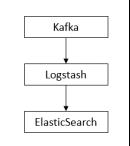
<1> 数据流转说明
日志信息经 Kafka 缓冲后批量提交数据,Logstash 配置 Data Input Source 为 Kafka,获取数据后支持过滤解析日志信息,再将数据输出到ElasticSearch进行存储。
<2> 应用配置说明
在 Logstash 的安装路径的 config/ 新建文件 logstash_kafka.conf.c 来配置 Logstash 的数据流通,数据过滤及数据流出
<3> Logstash 内部数据流转
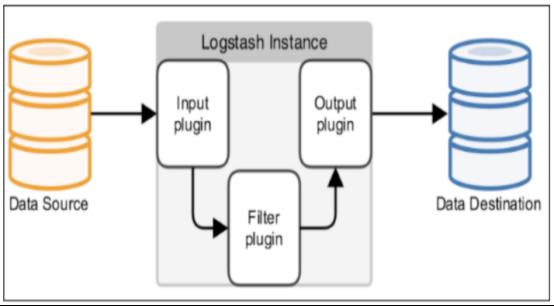
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
- 数据流流入
在ELK系统中我们接入了kafka作为消息队列。这时kafka就相当于上图中的Data Source(也就是数据源),在logstash的启动配置文件中我们设置了kafka集群的IP地址以及端口号。Logstash的管道口已经为kafka打开,当kafka中有数据时,logstash就会接收其数据 - 数据内部流转
当数据从logstash的input插件进入时,logstash就开始了数据的内部处理,也就是上图中Filter插件,在本系统中,我们使用了grok插件操作input中的message,将从kafka中传过来的项目名做了一个提取,应用到output插件中es插件的动态索引,以便于开发或者运维人员在kibana上的方便区分。 - 数据流出
当在内部处理完成以后,logstash会通过其输出插件将数据转发到下一个数据源接收点(es),这时es就作为上图中的Data Destination(数据目的地),在es插件中我们也设置了es集群所在服务器的IP地址及端口号以及登录es的账户名和密码,图中的index就是输出到es的动态索引,以logs-开头,拼接上Filter过滤器中提取出来的项目名,再拼接上一个日期。
2.4.2 Logstash 部署运行
<1> Logstash安装
- 官网下载新版本logstash6.5.X
https://www.elastic.co/downloads/logstash - 解压软件包
tar -zxvf logstash-6.5.1.tar.gz - 安装X-pack
cd logstash-6.5.1
./bin/logstash-pulgin install x-pack
<2> Logstash 配置
input
kafka
bootstrap_servers => ["192.168.200.81:8081"]
client_id => "logstash83"
group_id => "logstash"
auto_offset_reset => "latest"
consumer_threads => 2
decorate_events => true
topics => ["logstash-kafka-topic"]
type => "bhy"
codec => "json"
filter
grok
patterns_dir => ["./pattern"]
match => "message" => "%PROJECT_NAME:ProjectName"
mutate
lowercase => ["ProjectName"]
output
elasticsearch
user => "elastic"
password => "niaonao"
hosts => ["192.168.200.81:9200","192.168.200.83:9200"]
index => "logs-%[ProjectName]-%+YYYY.MM.dd"
manage_template => false
template_name => "logs.template"
<3> 配置详细说明
(1) input为输入模块,此处指定了接收kafka的端口号
- client_id :发出请求时传递给服务器的id字符串
- group_id:此使用者所属的组的标识符,主题中的消息将分发到具有相同的所有Logstash实例
- auto_offset_reset=>”latest”:从最新偏移量开始消费
- consumer_threads=>”2”:理想状态下多实例logstash线程数总和应该与分区数量一样多 以实现完美平衡,若线程多余则会出现某些线程处于空闲状态。
- docorate_events=>true:此属性会将当前topic、offset、group、patition等信息也带到 message中。
- topics =>[“logstash-kafka-topic”]:配置的topic,可配置多个
- type=>”bhy”:所有插件通用属性,尤其在input里面配置多个数据源
- codec=>”json”:该编解码器用于编码解码完整的json信息
(2) filter为过滤模块,为输入模块中的信息进行过滤 - grok:正则匹配解析操作message
- patterns_dir => ["./pattern"]是在logstash目录下建的一个patterns文件夹,里面建的一个文件是以key value形式的正则表达式(PROJECT_NAME 正则表达式)
- match属性作用是从message中把项目名称字段抠出来并赋值给另一字段ProjectName
mutate:对字段做处理,比如重命名,删除,替换,大小写等
(3) Output为输出模块这里使用elasticsearch将日志输出到ElasticSearch - stdoutcodec =>rubydebug:此为logstash标准输出
- Elasticsearch中:
设置es的user以及password、es的端口号这里需要注意的是,index为logstash创建index的规则,这里每天创建一个index,以日期结尾;templat_name为之前创建的模板名
<4> Logstash运行
运行命令如下
./bin/logstash -f ./config/logstash_kafka.conf.c
2.5 ElasticSearch 配置与数据流转
2.5.1 ElasticSearch 数据流转
<1> 数据流转说明
数据经 Logstash 解析过滤后流向 ElasticSearch 节点进行存储。Kibana配置 ElasticSearch 单节点的url,或者配置 ElasticSearch 集群中的 master node。
<2> 应用配置说明
在logstash的安装路径的config下新建配置文件logstash_kafka.conf添加output到ElasticSearch
output
elasticsearch
user => "elastic"
password => "niaonao"
hosts => ["192.168.200.81:9200","192.168.200.83:9200"]
index => "logs-%[ProjectName]-%+YYYY.MM.dd"
manage_template => false
template_name => "logs.template"
在elasticsearch安装路径的config下配置elasticsearch的Network
# ---------------------------------- Network ---------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.200.81
http.port: 9200
在 Kibana.yml 配置 ElasticSearch 的 url
# If your Elasticsearch is protected with basic authentication, these settings provide
elasticsearch.username: "elastic"
elasticsearch.password: "niaonao"
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://192.168.200.81:9200"
2.5.2 ElasticSearch 部署运行
<1> ES 安装
- 产品官方地址
https://www.elastic.co/downloads/elasticsearch - 应用安装路径
/opt/elkf/elasticsearch - 安装命令
下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.3.tar.gz
解压安装包
tar -zxvf elasticsearch-6.5.3.tar.gz
<2> ES 配置
编辑安装目录下config/elasticsearch.yml
此处以192.168.200.81服务器node-1节点配置为例;此节点在集群设计中配置为主节点
192.168.200.83服务器的node-2需要配置node.name为node-2, 此节点配置为非主节点node.master为false, network.host为192.168.200.81
# ---------------------------------- Cluster ----------------------------------#
# Use a descriptive name for your cluster:
#
cluster.name: niaonao_elk
#
# ------------------------------------ Node ---------------------------------#
# Use a descriptive name for the node:
#
node.master: false
node.name: node-1
# ----------------------------------- Paths ----------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /opt/elkf/esData/data
path.logs: /opt/elkf/esData/logs
# ----------------------------------- Memory --------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# ---------------------------------- Network ---------------------------------
network.host: 192.168.200.81
http.port: 9200
# 配置集群自动发现节点
discovery.zen.ping.unicast.hosts:["192.168.200.81", "192.168.200.83"]
# 配置最大master节点数目
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
# 解决bootstrap启动问题
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
<3> ES 运行
要求使用非root用户,在应用安装路径下运行启动命令.
应用安装路径/opt/elkf/elasticsearch, 运行命令./bin/elasticsearch –d
<4> 生成相关密码
手动输入生成密码,支持生成elastic、kibana、logstash-system三个用户和密码,在elasticsearch文件夹下执行 ./bin/x-pack/setup-passwords interactive
(Interactive表示手动输入密码,auto表示自动生成密码,在这里选择手动)手动输入为这三个用户设置的密码: 如图

<5> 运行失败问题处理
- 问题一:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改/etc 路径下的sysctl.conf文件配置
vm.max_map_count=262144
- 问题二:
max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
修改/etc/security路径下的limits.conf文件配置
* soft nofile 65536
* hard nofile 65536
2.6 Kibana 配置与数据流转
2.6.1 Kibana 数据流转
<1> 数据流转说明

Kibana配置ElasticSearch单节点的url来获取ElasticSearch的数据, ElasticSearch集群环境下Kibana只需配置ElasticSearch集群中的主节点url即可.
<2> 应用配置说明
在elasticsearch安装路径的config下配置elasticsearch.yml
集群环境下配置一个ElasticSearch主节点.
node.master: true
node.name: node-1
# ---------------------------------- Network ---------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.200.81
http.port: 9200
node.master默认为true, 其他节点配置为false
node.master: false
node.name: node-2
# ---------------------------------- Network ---------------------------------
# Set the bind address to a specific IP (IPv4 or IPv6):
network.host: 192.168.200.83
http.port: 9200
在Kibana.yml配置ElasticSearch集群环境中主节点的url
# If your Elasticsearch is protected with basic authentication, these settings provide
elasticsearch.username: "elastic"
elasticsearch.password: "niaonao"
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://192.168.200.81:9200"
2.6.2 Kibana 部署运行
<1> Kibana安装
- 产品官方地址
https://www.elastic.co/downloads/kibana - 应用安装路径
/opt/elkf/kibana - 安装命令
下载安装包
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.5.3-linux-x86_64.tar.gz
解压安装包
tar -zxvf elasticsearch-6.5.3.tar.gz
<2> Kibana 配置
编辑安装目录下config/kibana.yml配置文件
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "192.168.200.81"
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://192.168.200.81:9200"
# the username and password that the Kibana server uses to perform maintenance on the Kibana
elasticsearch.username: "elastic"
elasticsearch.password: "niaonao"
<3> Kibana 运行
在应用安装路径下运行以下命令, 在浏览器访问http://192.168.200.81:5601验证安装是否成功.
应用安装路径/opt/elkf/kibana, 运行命令./bin/kibana -d 即可启用 Kibana.
参考文章
ELK日志系统设计方案-Filebeat日志收集推送Kafka
ELK日志系统设计方案-Log4j日志直推Kafka
ELK日志系统设计方案-集群扩展
ELK日志系统部署实现
Powered By niaonao
以上是关于ELK 日志系统部署实现的主要内容,如果未能解决你的问题,请参考以下文章