数据库日志采集系统方案设计
Posted 马小瑄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库日志采集系统方案设计相关的知识,希望对你有一定的参考价值。
前言
汽车之家几年前已实现了应用日志的采集,但是对数据库日志并没有实现集中采集, 排查定位数据库故障原因不便。2021年我们研发了数据库日志采集分析平台系统,实现了数据库主机系统日志,数据库错误日志,审计日志的采集和分析。
01
背景介绍
之家数据库日志以前分散在各DB宿主机及容器RDS上,没有实现集中采集,排查定位故障原因不便。2021年DBA研发了数据库日志采集分析平台,实现了主机系统日志,数据库错误日志,审计日志的采集和分析。通过日志的集中采集,提升了故障排查效率,并且深入挖掘日志价值,可为未来之家数据库的智能审计,智能运维(如故障预警,自愈,自动调优)提供基础。
02
日志分析发展历程
日志分析并不是一项新颖的技术了,需要的是实际解决问题的思路或工具,哪怕是一段只有20行的命令脚本都可以。日志分析的发展划可分成4个时代:
1.石器时代 : 石器时代日志分析通常依靠Excel、终端命令(awk、grep、sort、uniq、wc等)。
2. 铁器时代 : 铁器时代通常依靠脚本工具(自写工具)、简易交互式工具(logwatch、logparser)等。
3. 工业时代 : 工作时代大家在做日志分析的时候相比前两个时代已经有了太多 的进步了,各种开源、免费、付费的软件可供选择,比如:Elastic系列、Splunk等等。
4. 未来时代 : 这个时代大家在做日志分析时候我不知道会用到什么,但是从目前来看,机器学习、人工智能应该是核心之一。
统一日志分析平台的工作在看来可以简单 分为2个阶段:
平台实现: 日志规范化 --> 日志采集 --> 日志存储 --> 日志分析 --> 日志展示 --> 告警实现;
平台优化: 这个阶段是对平台实现中的每一个步骤进行优化。
以下对常见的开源日志采集工具做一 简单分析:
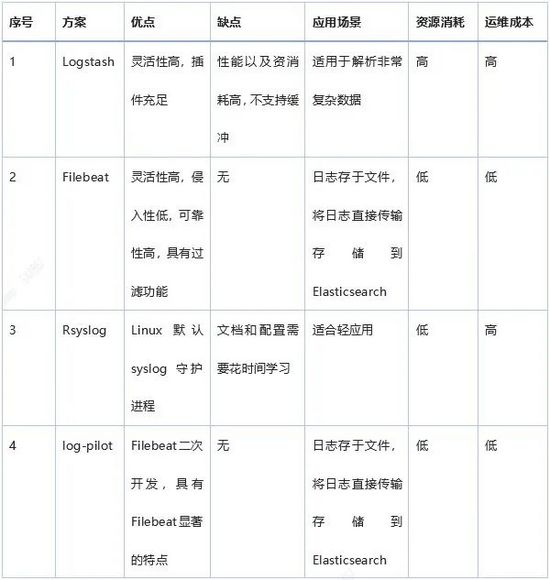
03
方案设计
之家数据库日志平台,可以分为应用层,日志采集层,缓存层,解析层,存储层,展示层,系统架构如 图1 。
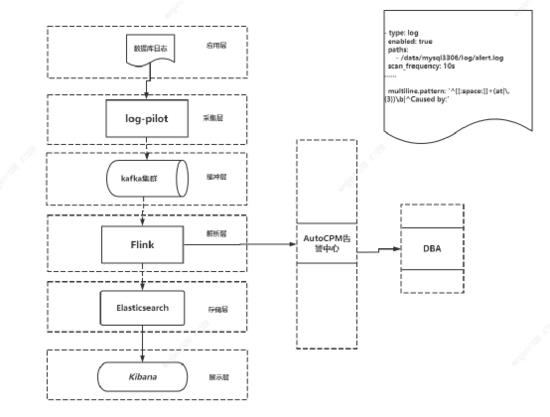
图 1 日志采集架构图
04
方案实施
通过之家二次开发的log-pilot日志采集工具,对数据库机器系统日志、DB错误日志、审计日志进行采集。采集的日志数据存入Kafka,为避免和其它业务日志相互影响, DBA采集申请了独立的KAFKA集群与Topic进行隔离。消费KAFKA数据采用Flink,对数据库日志数据进行处理,优化,精简,最终日志存入Elasticsearch。日志展示使用了开源的Kibana。 即数据流为日志源文件→ Log-pilot→ Kafka→ Flink→ ELasticsearch→ Kibana展示。
采集的数据库日志有错误日志,审计日志等,各种日志数据格式不统一,我们进行了日志规范化处理。其中审计日志支持json格式,DBA开发了Flink Api,Flink任务启动加载引用python包进行json数据处理赋值给ES索引字段。
另外为了高效运维管理数据库日志,做了如下工作:
-
日志可视化配置管理: 开发了日志配置管理界面,可以对DB实例进行日志路径配置,日志采集启停。
-
日志监控报警: 对ERROR或敏感数据审计日志,上报公司监控告警平台(AutoCMP),对重要日志信息及时发现并通知到告警接收人。
05
平台展示
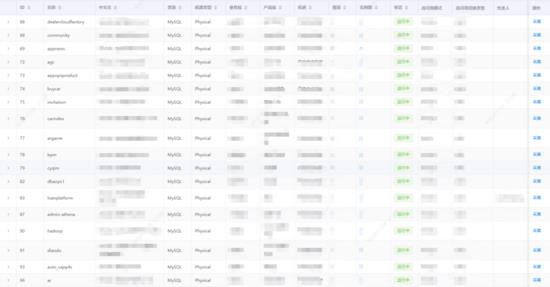
图 2 数据库物理实例日志采集
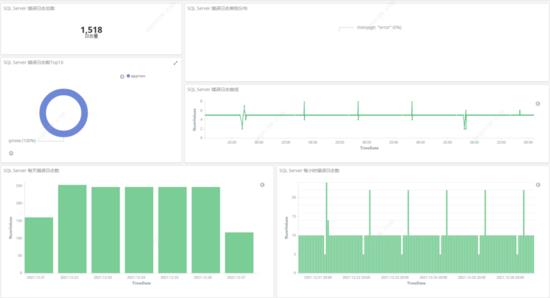
图 3 采集日志Dashboard展示

图 4 数据库日志报警
06
展望
未来计划增加重点数据库的SQL日志采集,通过分析SQL对高危操作。比如:DROP/TRUNCATE,DELETE等SQL语句执行进行审计监控报警。对数据库中warning/error等问题进行分析治理,进一步提升数据库服务质量。
Hadoop-Flume日志采集系统
Flume是Cloudera提供的日志收集系统,具有分布式、高可靠、高可用性等特点,对海量日志采集、聚合和传输,Flume支持在日志系统中制定各类数据发送,同时,Flume提供对数据进行简单处理,并写到各种数接受方的能力。其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
Flume的特征:可靠性,可扩展性,可管理性
接下来我们说的是Flume NG架构的优势:
1、NG 在核心组件上进行了大规模的调整
2、大大降低了对用户的要求,如用户无需搭建ZooKeeper集群
3、有利于 Flume 和其他技术、hadoop 周边组件的整合
4、在功能上更加强大、可扩展性更高
Flume的核心是把数据从数据源收集过来,在送到目的地,为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据
Flume传输的数据基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event从Source,流向Channel,再到Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另外一个地方。
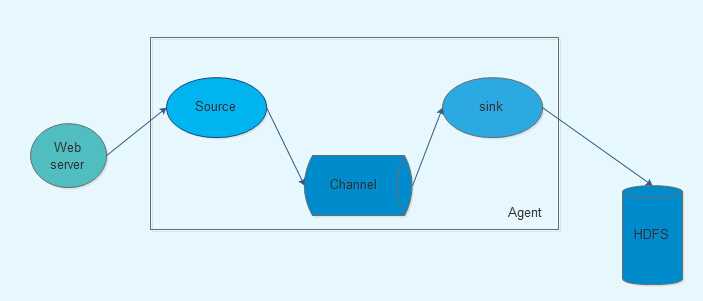
Source可以接收外部源发送过来的数据,不同的source可以接受不同的数据格式。比如有目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容
Channel是一个存储地,接收source的输出,直到sink消费掉channel中的数据。channel中的数据直到进入到下一个channel中或者进入终端才会被删除。当sink写入失败后,可以自动重启,不会造成数据丢失,因此很可靠
Sink会消费channel中的数据,然后送给外部源或者其他source。如数据可以写入到HDFS或者HBase中。
Flume允许多个agent连在一起,形成前后相连的多级跳:
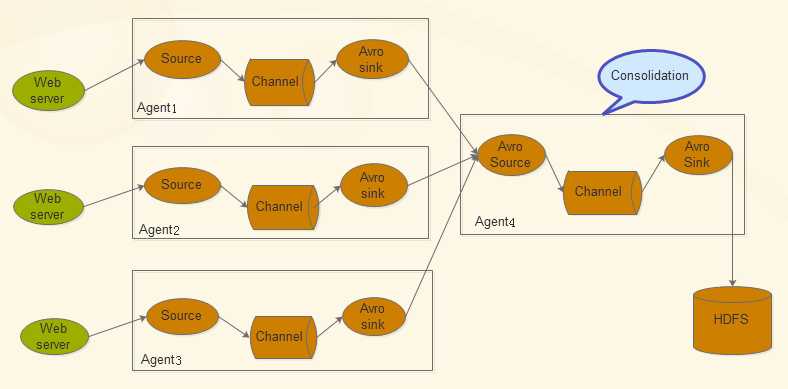
Flume架构核心组件:
source:source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个channel,source必须至少和一个channel关联
不同类型的source:与系统集成的source: Syslog, Netcat;直接读取文件的 source: ExecSource、SpoolSource;用于Agent和Agent之间通信的IPC Source: Avro、Thrift
channel:channel位于source和sink之间,用于缓存进来的event。当Sink成功的将event发送到下一跳的channel或最终目的时候,event从Channel移除。
几种channel类型:MemoryChannel 可以实现高速的吞吐,但是无法保证数据的完整性;FileChannel(磁盘channel)保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率
sink:Sink负责将event传输到下一跳或最终目的;sink在设置存储数据时,可以向文件系统、数据库、Hadoop存数据,在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到hadoop中,便于日后进行相应的数据分析。必须作用于一个确切的channel
下载源码包:http://mirror.bit.edu.cn/apache/flume/1.6.0/
1、安装软件包:
[[email protected] ~]$ tar -xvf apache-flume-1.6.0-bin.tar.gz
[[email protected] ~]$ tar -xvf apache-flume-1.6.0-src.tar.gz
2、将源码合并至安装目录apache-flume-1.6.0-bin下
配置环境变量:
[[email protected] ~]$ vim ~/.bash_profile
export FLUME_HOME=/home/lan/apache-flume-1.6.0-bin/
export PATH=$PATH:$FLUME_HOME/bin
测试flume-ng是否安装成功:
flume-ng version
3、
新建一个flume代理agent1的配置文件example.conf
[[email protected] ~]$ cd apache-flume-1.6.0-bin/conf/
[[email protected] conf]$ vim example.conf
#agent1
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = c1
#source1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/lan/agent1log
agent1.sources.source1.channels = c1
agent1.sources.source1.fileHeader = false
#sink1
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://master:9000/agentlog
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat = TEXT
agent1.sinks.sink1.hdfs.rollInteval = 4
agent1.sinks.sink1.channel = c1
#channel1
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /home/lan/agent1_tmp1
agent1.channels.c1.dataDirs = /home/lan/agent1_tmpdata
#agent1.channels.channel1.capacity = 10000
#agent1.channels.channel.transactionCapacity = 1000
新建agent1log:
[[email protected] ~]$ mkdir agent1log
[[email protected] ~]$ cd apache-flume-1.6.0-bin
[[email protected] apache-flume-1.6.0-bin]$ flume-ng agent -n agent1 -c conf -f /home/lan/apache-flume-1.6.0-bin/conf/example.conf -Dflume.root.logger=DEBUG,console
另启一个terminal,在监测目录下创建新的文件test2.txt
cd ~/agent1log
vim test2.txt
查看sink1的输出,发现目标路径下有一个以FlumeData开始,产生文件的时间戳为后缀的文件,说明flume能监测到目标目录变化,将产生变化的部分实时地收集到sink的输出中。
以上是关于数据库日志采集系统方案设计的主要内容,如果未能解决你的问题,请参考以下文章