关于oracle中的in和exists的效率问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于oracle中的in和exists的效率问题相关的知识,希望对你有一定的参考价值。
最近做报表的时候发现一段SQL执行速度很慢,如下:
select aa19.分公司 as 分公司,
case when count(aa19.独立故障编号) is null then 0 else count(aa19.独立故障编号) end as 月完成,
sum(aa19.月完成历时) as 月完成总历时
from(
select distinct(b.tr_code) as 独立故障编号,a.applycentcompany as 分公司,(case when b.end_time is null then sysdate else b.end_time end-b.apply_time)*24*60 as 月完成历时
from tr_queryregisterforreport a,tr_register b,tr_return_affirm cc
where b.tr_code = a.tr_code
and cc.cs_code=b.cssystem_no
and b.cssystem_no is not null
and b.reserver1=@prompt('客服工单类型:','A','省公司故障统计分析\客服工单类型',Mono,Free,Persistent,,User:4)
and (case b.status when '4' then '1' when '5' then '1' when '6' then '1' else '0' end ) = '1'
and to_number(to_char(cc.tr_end_time,'yyyymm')) = to_number(substr(to_char(to_date(@prompt('查询日期:','A','故障处理明细表\日期1',Mono,Free,Persistent,,User:2),'yyyymmdd')-1,'yyyymmdd'),1,6))
and to_number(to_char(cc.tr_end_time,'yyyymmdd')) < to_number(@prompt('查询日期:','A','故障处理明细表\日期1',Mono,Free,Persistent,,User:2))
and to_number(to_char(b.apply_time,'yyyymmdd')) = to_number(to_char(cc.tr_end_time,'yyyymmdd'))
--and a.producttype in (select c.name from tr_ywlx c where c.fenlei!='广视通')
and exists(select 1 from tr_ywlx c where c.fenlei!='广视通' and c.name = a.producttype)
)aa19 group by aa19.分公司 having aa19.分公司 like '%分公司%'
最后发现瓶颈在这么一处:
--and a.producttype in (select c.name from tr_ywlx c where c.fenlei!='广视通')
and exists(select 1 from tr_ywlx c where c.fenlei!='广视通' and c.name = a.producttype)
用exists的时候速度要慢很多很多,改用in的话反而会快很多。
(tr_ywlx约有50多条记录,tr_queryregisterforreport约有100W,但相关字段做过normal索引),很迷惘。
希望谁能结合1个简单的实例讲解下in和exists的效率问题,多谢。
主要是能结合一个实例讲解下2者的区别。
原理是什么我也不清楚,用数据库的人都这么说。 参考技术A 一般来说exists处理起来比in要快很多,优化SQL时一般都是建议将in改为exists,
从你所描述的情况来看:
and a.producttype in (select c.name from tr_ywlx c where c.fenlei!='广视通')---tr_ywlx数据相比之下很小很小,而且这个子查询只是表本身数据的筛选
and exists(select 1 from tr_ywlx c where c.fenlei!='广视通' and c.name = a.producttype)---这里是将tr_ywlx这个数据很小的表与100W笔数据的表关联起来了,形成了一个笛卡尔积,它要将两个表数据一对一进行比对,100W啊,肯定慢了
你给producttype做一个索引再试试本回答被提问者采纳 参考技术B 你的这个SQL实在是太复杂了,而且还用到了外链接,不知道为什么要写的这么复杂,我以前用过exists,比in的效率要高出很多。
关于EXISTS与IN的区别:
EXISTS检查是否有结果,判断是否有记录,返回的是一个布尔型(TRUE/FALSE)。
IN是对结果值进行比较,判断一个字段是否存在于几个值的范围中,所以 EXISTS 比 IN 快。
主要区别是:
exists主要用于片面的,有满足一个条件的即可,
in主要用于具体的集合操作,有多少满足条件.
exists是判断是否存在这样的记录,
in是判断某个字段是否在指定的某个范围内。
exists快一些吧 。
in适合内外表都很大的情况,exists适合外表结果集很小的情况。
参考资料:http://blog.163.com/yangzhongfei/blog/static/4610987520095284185360/
关于sql中in 和 exists 的效率问题,in真的效率低吗
原文: http://www.cnblogs.com/AdamLee/p/5054674.html
在网上看到很多关于sql中使用in效率低的问题,于是自己做了测试来验证是否是众人说的那样。
群众:
对于in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
这里我找到两张表,一个是用户信息表[INDIVIDUAL] 47万条数据,一个状态类型表[STATUS] 88条数据,对应上面所述的一多一少
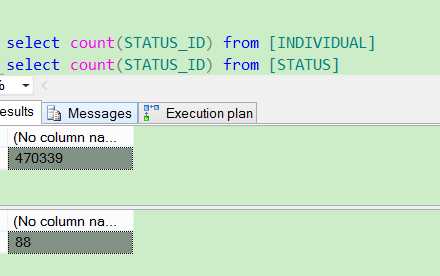
然后进行两种查询 (not exists 和 not in一组)(exists 和 in一组)
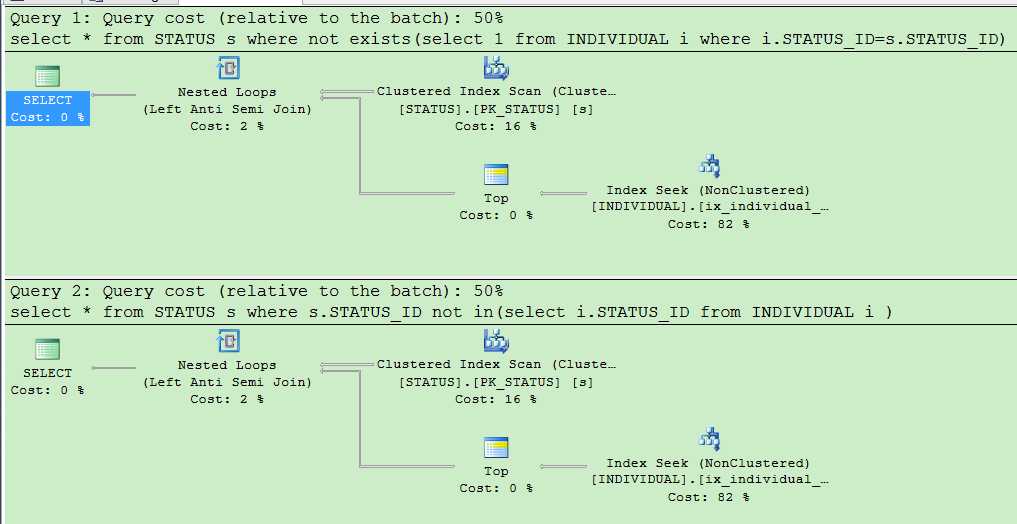
select * from STATUS s where not exists(select 1 from INDIVIDUAL i where i.STATUS_ID=s.STATUS_ID)
select * from STATUS s where s.STATUS_ID not in(select i.STATUS_ID from INDIVIDUAL i )
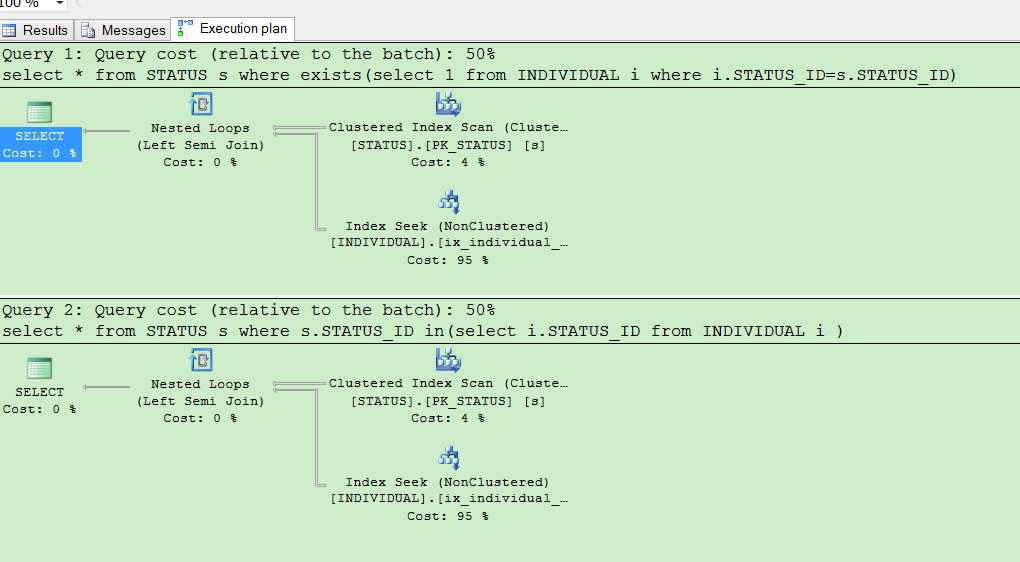
select * from STATUS s where exists(select 1 from INDIVIDUAL i where i.STATUS_ID=s.STATUS_ID)
select * from STATUS s where s.STATUS_ID in(select i.STATUS_ID from INDIVIDUAL i )
查看执行计划后发现,结果貌似是一样的,令人意外,可能大家认为in 比较慢的原因就是 IN先执行子查询 ,但是事实并不是这样的。
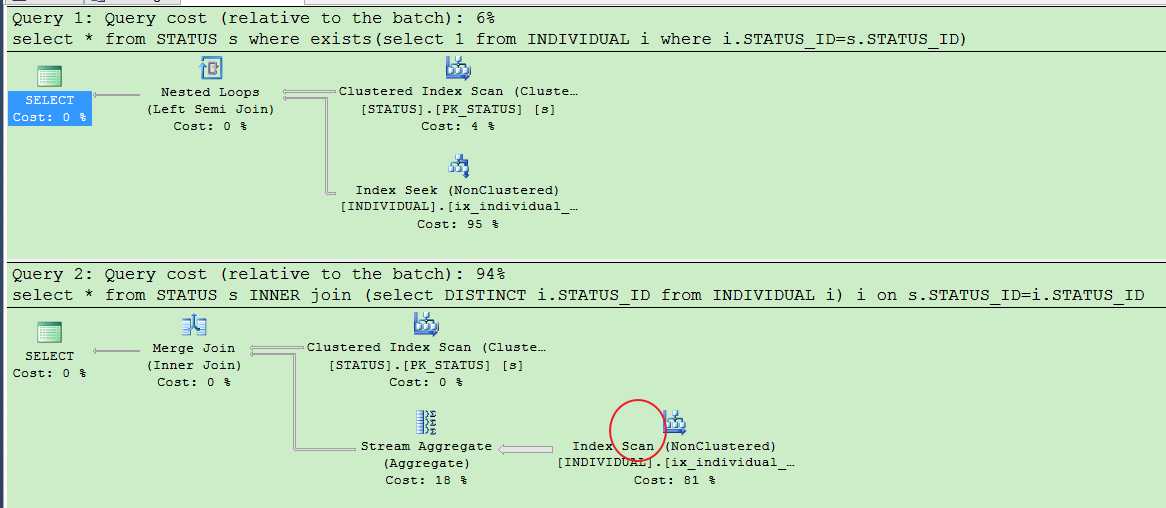
但是如果你使用join,就会发现真的对用户表全盘扫描了.....
以上是关于关于oracle中的in和exists的效率问题的主要内容,如果未能解决你的问题,请参考以下文章