数据库的基本操作
Posted 幽萌之雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库的基本操作相关的知识,希望对你有一定的参考价值。
目录
一、数据库的基本操作
1、数据库的登录及退出
退出数据库,以下三种方式都可以:
exit
quit
ctrl+d
2、查看所有数据库

3、显示数据库版本
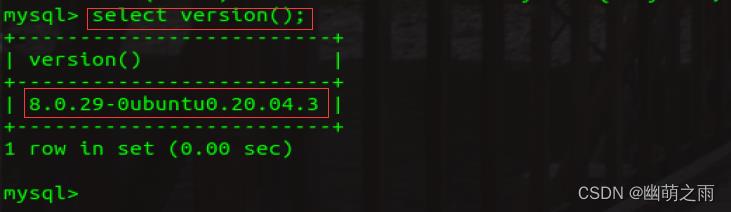
4、显示时间

5、创建数据库

6、查看创建数据库的语句

注意:在创建数据库或查看创建数据库语句时,database没有s。
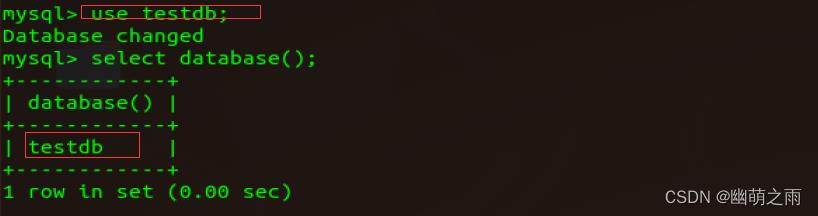
7、查看当前使用的数据库

当选择了某个数据库时,显示如下:
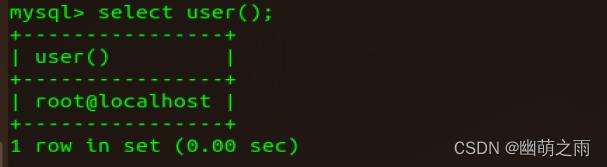
8、查看当前用户
9、使用某个数据库

10、删除数据库

二、数据表的基本操作
1、查看当前数据库中的所有表

2、创建表
创建表的命令:create table 数据库表名字 (字段 类型 约束 [字段 类型 约束]),中括号中的可以省略。
约束:
- 主键 primary key : 物理上存储的顺序
- 非空 not null : 此字段不允许填写空值
- 唯一unique: 此字段的值不允许重复
- 默认default: 当不填写此值时,会使用默认值。如果填写时,以填写的值为准
- 外键foreign key : 对关系字段进行约束,当为关系字段填写值时,会到关联的表中查询此值是否存
- 在,如果存在则写成功,如果不存在则写失败。 虽然外键约束可以保证数据的有效性,但是在进行
- 数据的crud(增加,修改,删除,查询)时,都会降低数据库的性能。
- auto_increment 表示自动增长
创建表
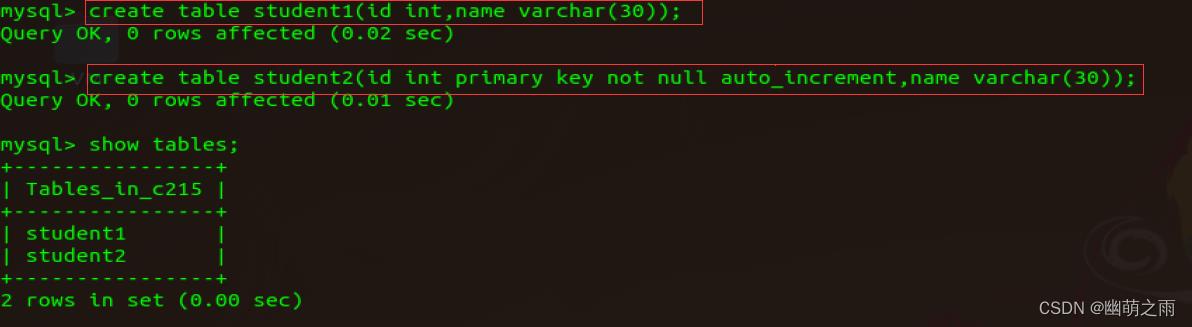
再创建一个students表
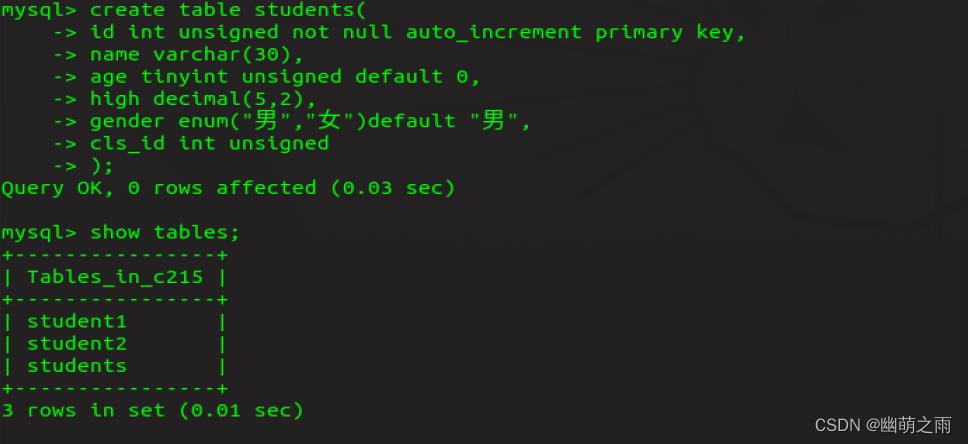
3、查看表结构
查看表结构也就是查看各个字段的信息。

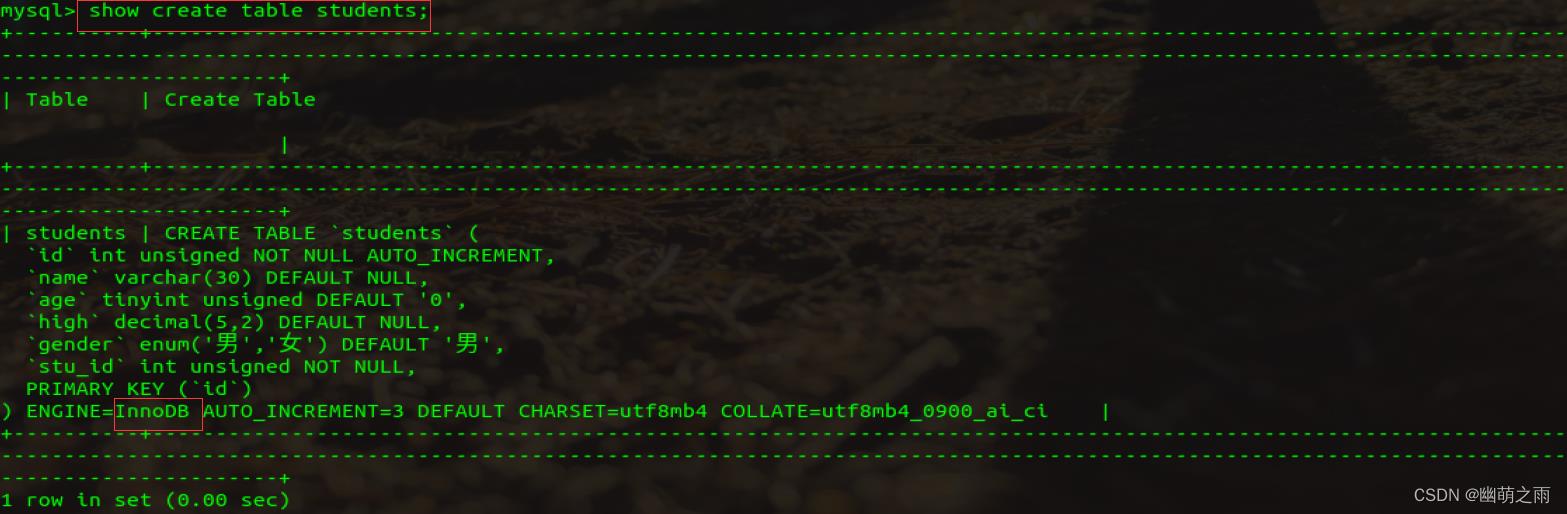
4、查看创建表的语句
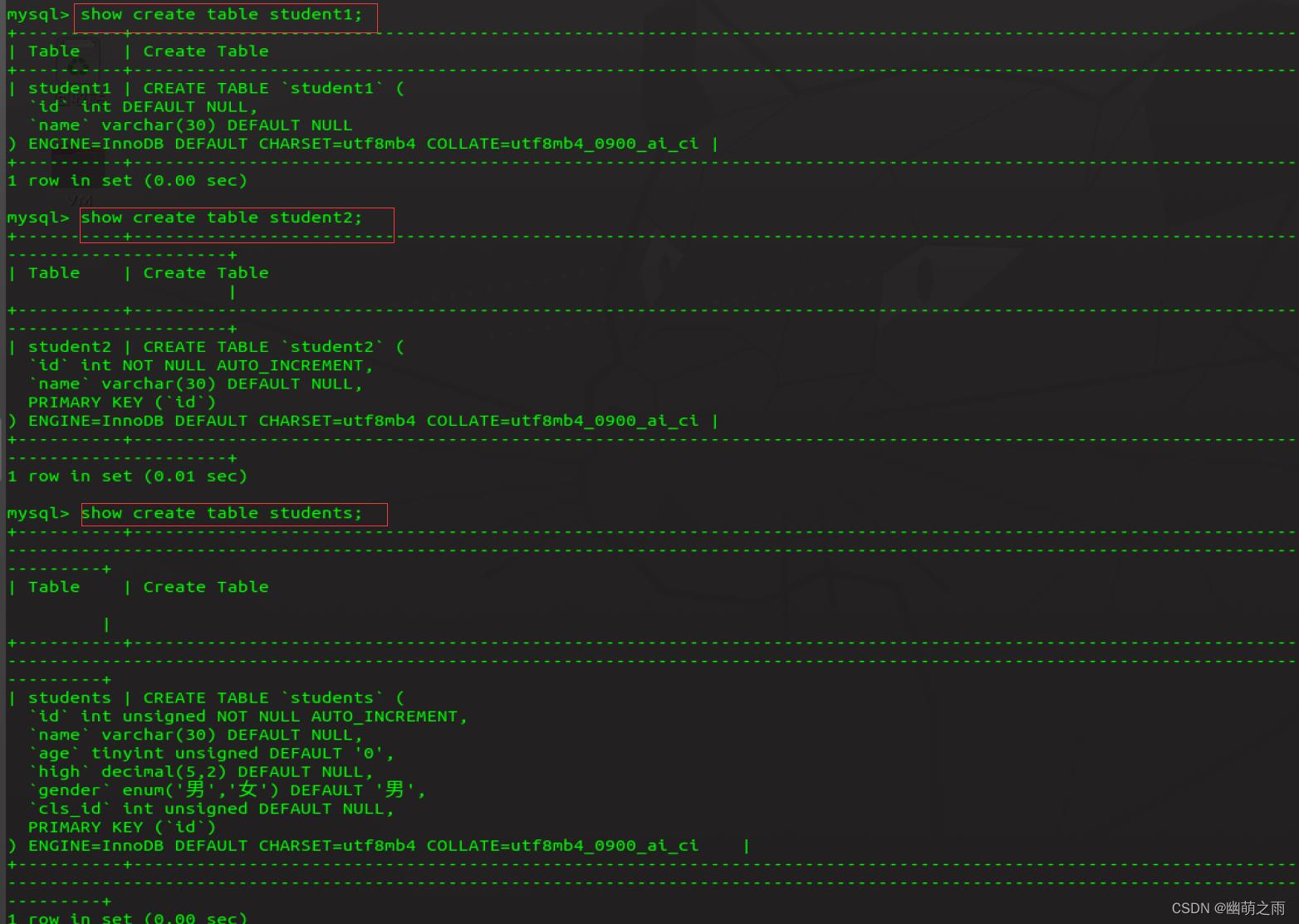
5、向表中插入,更新,删除数据
插入:
更新:
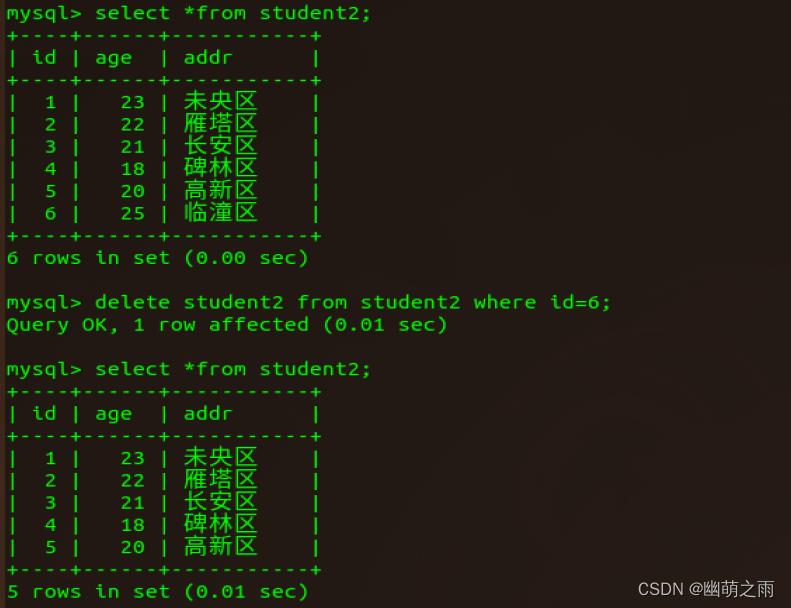
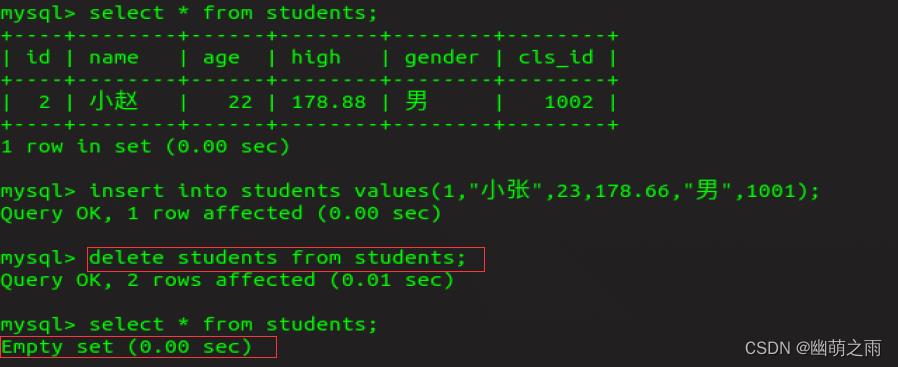
删除:
删除指定行:
删除所有行:


6、查看表中数据
查看所有数据:
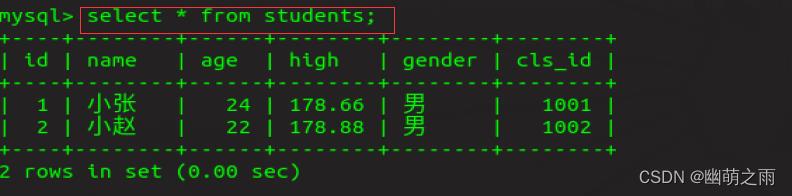
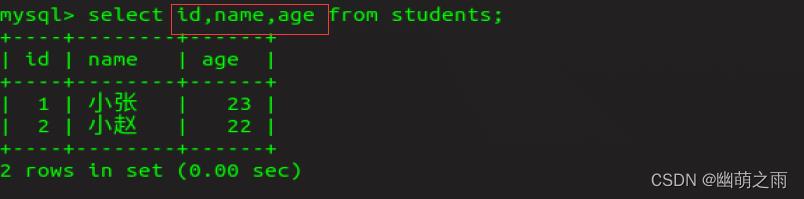
也可以查看指定数据(把*换成想查找的具体字段就行):
7、修改表名字

8、修改表字段信息
添加字段:alter table 表名 add 列名 类型;
重新命名字段:alter table 表名 change 原字段名 新字段名 类型及约束;
修改字段:
删除字段:alter 表名 drop 列名
修改表的存储引擎:
常见引擎:MyISAM,InnoDB
查看之前的引擎:
修改之后:





9、删除表

三、mysql查询操作
1、基本查询
查询所有字段:

查询指定字段:

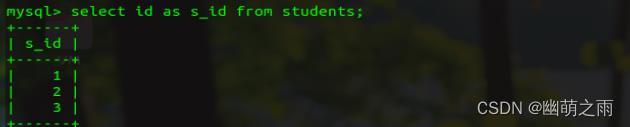
使用as给字段起名:
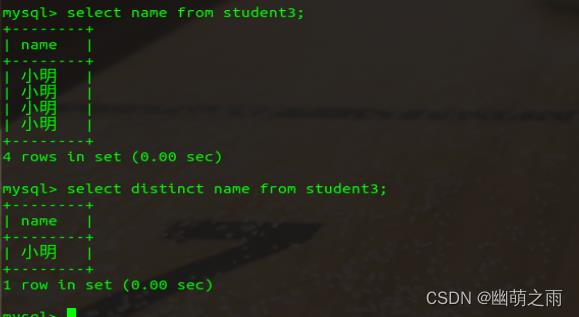
消除重复行:
2、条件
比较运算:大于,小于,大于等于,小于等于,相等,不相等;逻辑运算
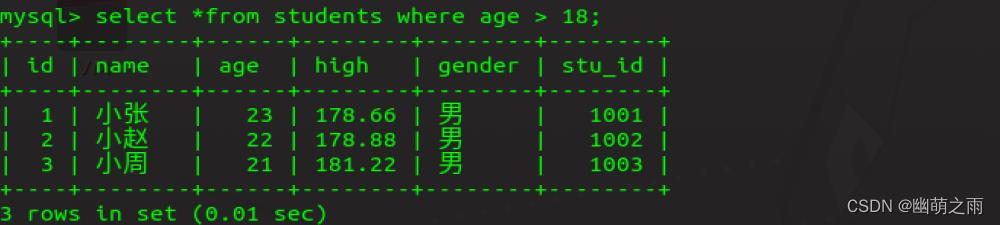
查询年龄大于18岁的学生信息
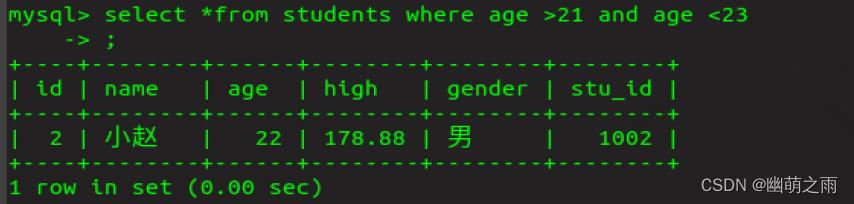
查询年龄在大于21小于23的
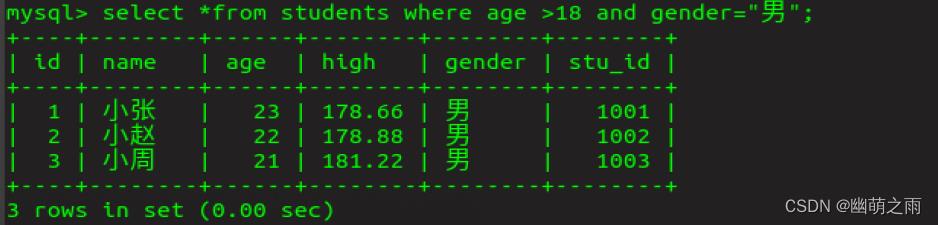
查询18岁以上的男性
查询十八岁以上的身高大于180的同学
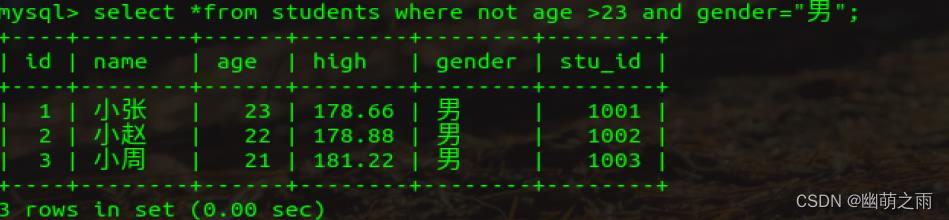
查询没有超过23岁的男性
查询没有超过十八岁的女性


模糊查询
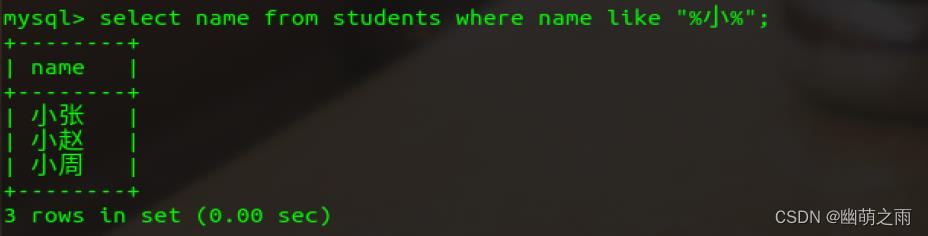
模糊查询就是通一小部分信息查询对应的个体,如图:
查询姓名中以“小”开始的名字
查询姓名中含有“小”的所有名字
查询有两个字的名字
查询至少有两个字的名字



范围查询
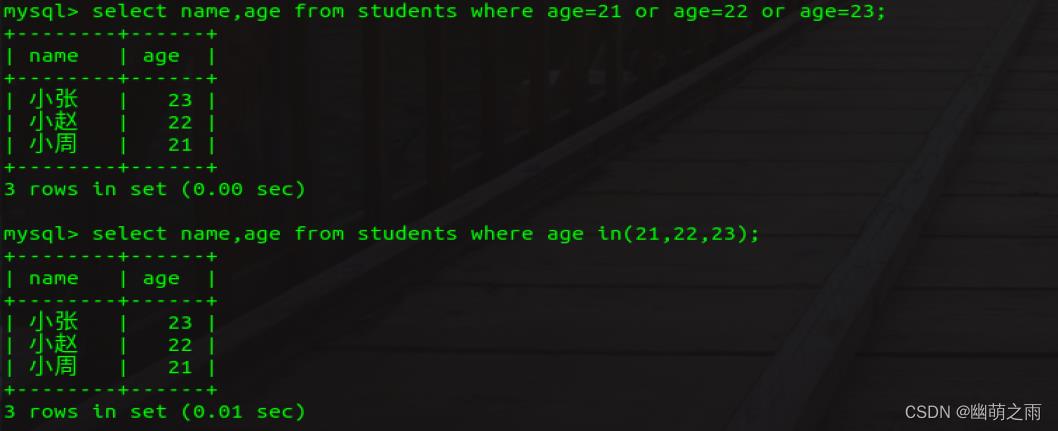
查询年龄为18,20,24的学生信息
查询年龄不是18,20,24
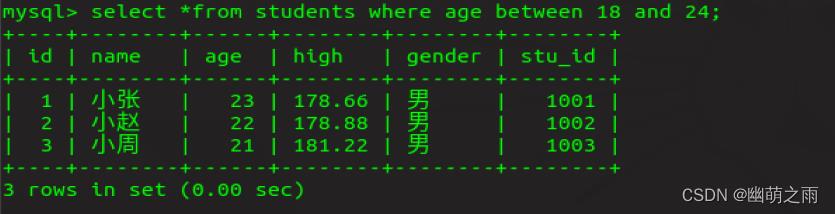
查询年龄在18到24之间的所有学生所有信息
查询年龄不在18到24岁之间姓名,年龄信息
查询学生学号为空的学生



3、排序
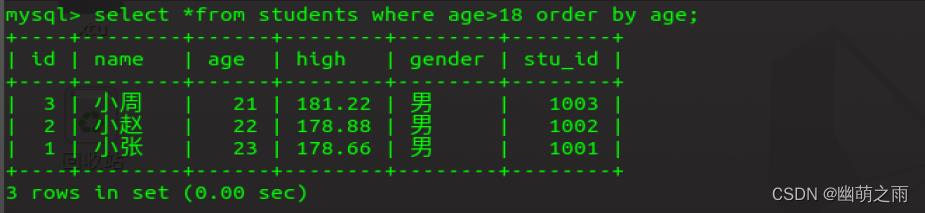
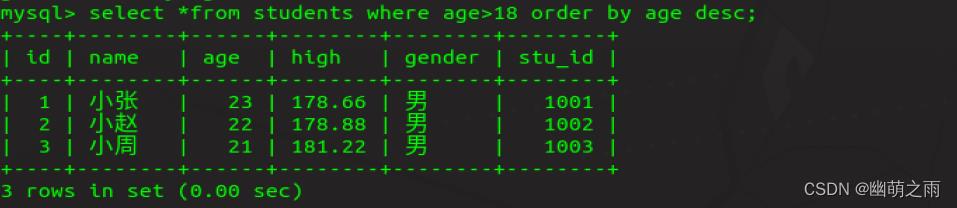
查询年龄在18岁以上的学生,年龄从小到大
查询年龄在18岁以上的学生,年龄从大到小
查询年龄在18到24岁之间的学生,按照年龄从小到大,身高从高到底排序

4、聚合函数
count()总数,max()最大值,min()最小值,sum()求和,avg()平均值,round()四舍五入
新表信息:
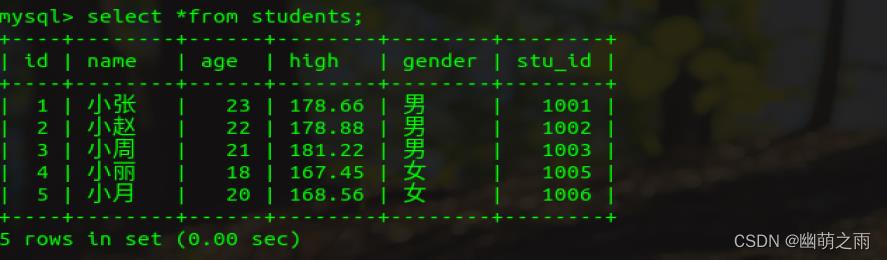
查询男生有多少人
查询最大年龄
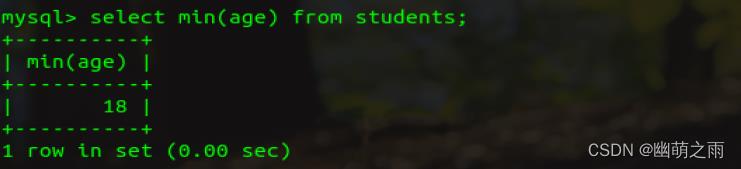
查询最小年龄
计算所有人的年龄总和
计算平均年龄
计算平均年龄,设置平均年龄的小数位数





5、分组
新表信息:
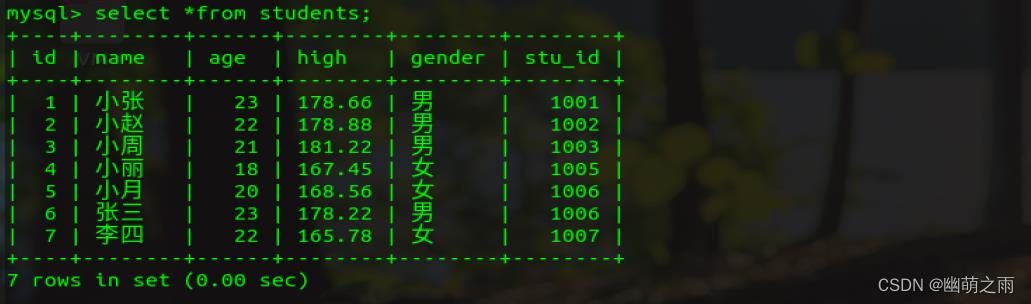
group by分组
按照性别分组
计算男生和女生的人数
查看性别分组中,年龄最大的
查看性别分组中,每个组的人名




6、连接查询
内连接查询时比较常见的连接查询,可以查询两张及两张以上的数据表信息
假设一个学生的姓名、年龄、性别信息在第一张表中,家庭住址、学号信息在另一张表中,现在需要这个学生的全部信息,我们就需要连接查询
6.1、内连接查询
- 定义:从一张表中取出一条记录,去另一张表中匹配,当某个条件在这两张表中相同时就会保留下来。
- 查询条件:当两张表中存在相同意义的字段的时候,就可以用过该查询方式来连接查询,当该字段的值相同时就可以查出该记录。
现在有两张表student1,student2,如下:


查询两张表能对应上得全部信息
查询方式一:
查询方式2:


6.2、外连接查询
对于内连接来说,我们只会保留符合连接条件的信息,而对于那些不符合连接条件的信息,我们不会保留,有时我们可能还需要这些信息,那么外连接就是解决这个问题的。外连接不仅仅会保留符合连接条件的信息,对于那些不符合连接条件的列,将会被填上NULL值,再返回到结果中。外连接中参与连接的表有主从之分,主表的每行数据去匹配从表的数据列。外连接分为左外部连接和右外部连接两种。
6.2.1、左连接查询
left join:以主表所在的方向区分外部连接,主表在左边,称为左外部连接;左表不管能不能匹配上连接条件,最终都会保留,只是右表不能匹配的字段都置为NULL;

6.2.2、右连接查询
right join:以主表所在的方向区分外部连接,主表在右边,称为右外部连接;右表不管能不能匹配上条件,最终都会保留,只是左表不能匹配的字段都置NULL(这里右表的所有结果都能匹配上左表,所以这里没有NULL值)。

7、自关联
但一个表与其自身进行连接时,称为表的自身连接
查询比id号为1的同学身高高的同学信息;

8、子查询和联合查询
下面这篇文章介绍的很详细
https://blog.csdn.net/weixin_39411321/article/details/90602030?spm=1001.2014.3001.5502
Sql 库和表的基本操作基本数据类型
一、数据库的基本操作
基本操作:
1、查看当前数据库:show databases;
2、进入到指定的数据库:use [数据库名],
数据库的增删改查:
1、创建数据库:create database [数据库名]
2、删除数据库:drop database [数据库名]
3、修改数据库的编码:alter database [数据库名] charset gbk;
4、查看当前数据库:select database();
show create database [数据库名];
二、表的基本操作
基本操作:
1、查看当前数据库里的表:show tables;
表的增删改查
1、创建表:
create table [表名] (字段+约束)
2、删除表:
drop table [表名],
3、修改表:
update db1.t1 set name=\'Andey\' where id=2;
4、查询表
查询所有select * from [表名]
根据条件查询:where 条件
查询字段:select id,name.......
5、复制表
create table t2 select * from t1 ( 既复制表结构也复制表内容 );
create table t2 select * from t1 where 1>2; (只复制表结构) 或:create table t2 like db1.t1;
三、表的存储引擎
create table t1 ( id int ) engine = innodb;(默认引擎)
create table t2 (id int ) engine = myisam;
create table t3(id int)engine=memory;(做缓存,退出后表的数据消失)
create table t4(id int)engine=blackhole;(无论往表里怎么插数据,都为空)
四、数据的基本类型:
1、整型(默认使用就行)
包括tinyint 、smallint 、int 、bigint
有符号:
无符号:
2、float单精度类型:
float(m,d)m表示小数点前后位的个数,d 表示小数点后的个数
double双精度类型:
double(m,d)相同
float、double两者表示的范围不一样随着小数点后的位数增多,表示的数值越来越不准确
decimal 精确表示小数,随着小数点后的位数增多,数值一直精准
3、日期类型
year:表示年份如1998,2000
date:YYYY—MM—DD用now()表示年 月 日
time:HH:MM:SS 用now()表示 时 分 秒
datetime:YYYY—MM—DD , HH:MM:SS Now() 年 月 日,时 分 秒
4、char()和varchar()
查询: select @@sql_mode;
https://www.cnblogs.com/majj/p/9167178.html
在使用char_length()查询长度的时候char 和varchar()
如:select x,length(x),y,length(y) from t1;
char()会将字符里的空格删除,显示非空的字符长度(可以通过修改sql_mode修改char的显示)
varchar()会将字符完全显示出来 包括空格
5、枚举和集合类型
enum(\'x1 \' , \' x2\' ,\' x3 \'......)相当于单选
set(\'b1 \' , \'b2 \' , \' b3 \' , \' b4 \' ......)可以选中多个
create table usetable(
-> id int,
-> name varchar(20),
-> sex enum(\'male\',\'female\',\'other\'),
-> fav set(\'football\',\'basketball\')
-> );
insert into usetable values
-> (1,\'alex\',\'male\',\'football,basketball\');
五、完整性约束:
PRIMARY KEY (PK) #标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) #标识该字段为该表的外键
NOT NULL #标识该字段不能为空
UNIQUE KEY (UK) #标识该字段的值是唯一的
AUTO_INCREMENT #标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT #为该字段设置默认值
UNSIGNED #无符号
ZEROFILL #使用0填充
1、not null 与 default 约束同一个字段
当未添加数据时 会自动设置为 默认值
create table student2(
-> id int not null,
-> name varchar(50) not null,
-> age int(3) unsigned not null default 18,
);
2 、unique 分单列唯一、 多列唯一、组合唯一(联合唯一)
单列唯一:在创建表时 为某一个字段设置unique 约束
多列唯一:在创建表时 为对多个字段设置unique约束
组合唯一
create table services(
-> id int,
-> ip char(15),
-> port int,
-> unique(id),
-> unique(ip,port)
-> );
组合唯一:插入两行记录 只要有一行不相同,就符合组合唯一
insert into services values
-> (1,\'192,168,11,23\',80),
-> (2,\'192,168,11,23\',81),
-> (3,\'192,168,11,25\',80);
3、primary key:主键,一个表里唯一标示的字段
not null + unique ==primary key
以上是关于数据库的基本操作的主要内容,如果未能解决你的问题,请参考以下文章