brpc源码学习- RDMA通信
Posted KIDGINBROOK
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了brpc源码学习- RDMA通信相关的知识,希望对你有一定的参考价值。
目录
因为kernel bypass和zero copy,使得rdma相对tcp有着显著的优势:低时延,高带宽,cpu消耗少,因此brpc也支持了使用rdma进行通信。
使用的方法很简单,client端只需要设置ChannelOptions.use_rdma = true,server端只需要设置ServerOptions.use_rdma = true
整体流程
接下来首先以polling + 共享CQ的模式介绍下整体流程
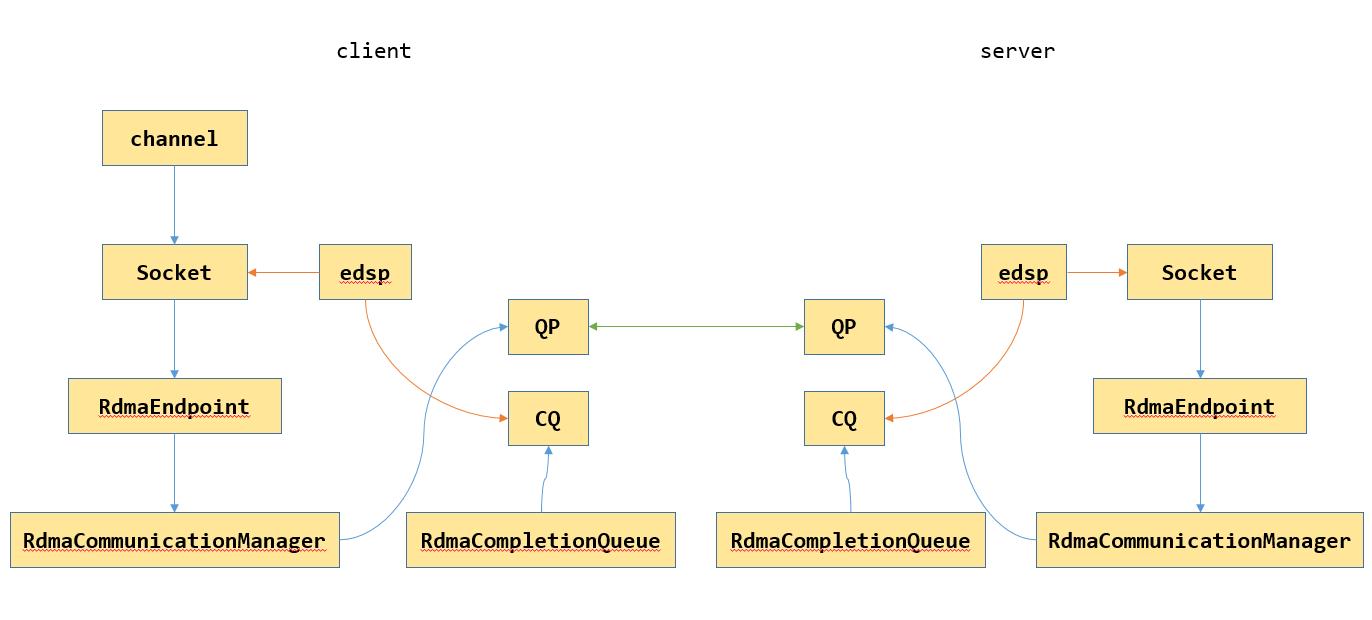
首先看下整体架构,如上图所示,RdmaCommunicationManager封装了verbs的api, RdmaEndpoint为Socket的成员,负责建立连接,数据收发等,RdmaCompletionQueue主要是对CQ的封装。
初始化
首先是rdma的初始化,client端在InitChannelOptions以及server的StartInternal会执行对rdma的初始化,即GlobalRdmaInitializeOrDieImpl

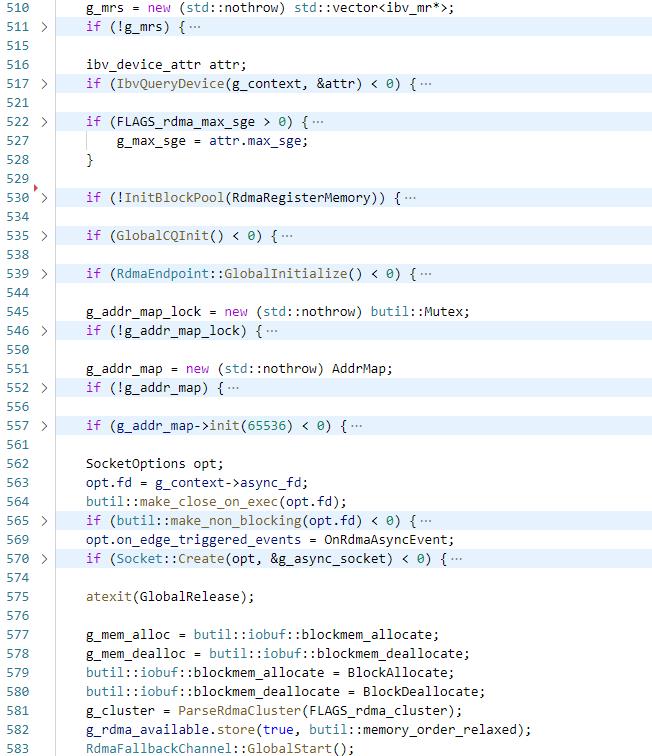
执行ReadRdmaDynamicLib,从libibverbs.so和librdmacm.so两个动态库中load各个函数,执行ibv_fork_init保证正确的执行fork,获取第一个active的device的context到g_context,获取ip地址到g_rdma_ip,然后创建ibv_pd到g_pd,创建ibv_mr的vector到g_mrs,然后通过ibv_query_device获取网卡的max_sge保存在g_max_sge,然后初始化内存池,初始化RdmaCompletionQueue,设置IOBuf的allocate和deallocate函数

内存池
由于rdma使用的内存需要被注册,因此这里将IOBuf使用的内存分配和释放函数做了替换
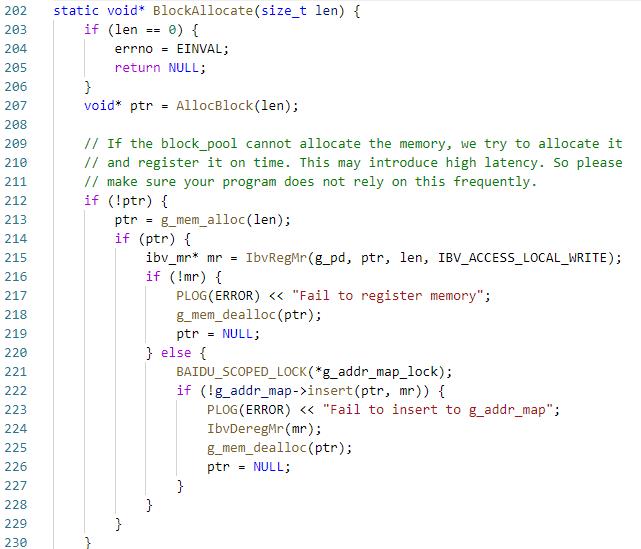
首先通过AllocBlock从rdma内存池中分配,分配不到的话就malloc然后再注册
然后简单介绍下内存池,整体和之前说的ObjectPool比较相似,维护了8KB、16KB、32KB和64KB这几种大小的block,分配内存时先在线程缓存里找,找不到会去全局找,全局也不够的话就malloc一段内存然后注册并加入到内存池。
建立连接
然后看下建链的过程:
建链过程比较复杂,整体如下图所示
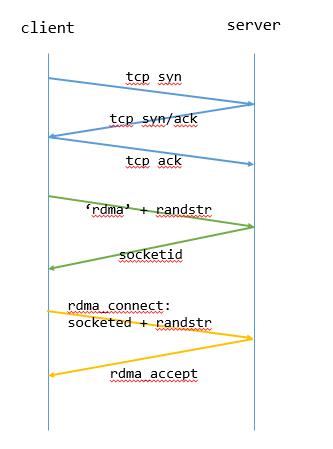
整体分为三个阶段。第一阶段是TCP三次握手,第二阶段是client向server发RDMA Hello消息,包含一个MAGIC_STR,即“RDMA”,以及一个随机字串Rand_Str。server收到这个消息后,将该连接对应的SocketID回复给client。第三阶段是client利用rdmacm发起rdma_connect请求,在请求中携带刚才收到的SocketID以及上一步中自己生成的随机字串Rand_Str。server端验证这两个值相互匹配后,接受这个RDMA连接请求,并把这个RDMA连接和SocketID对应的Socket绑定在一起。
下图表示建链过程中server和client的结构
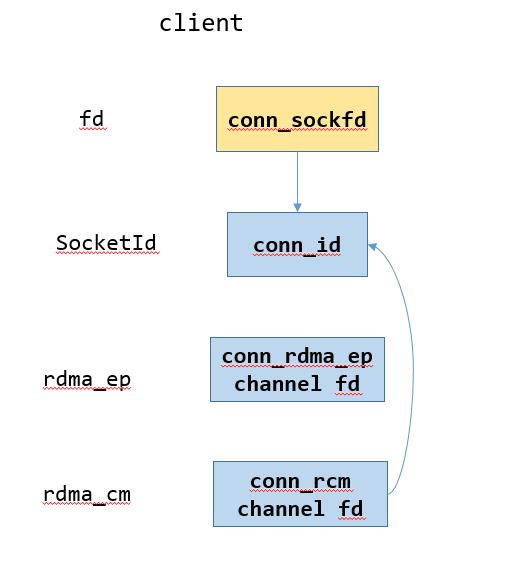
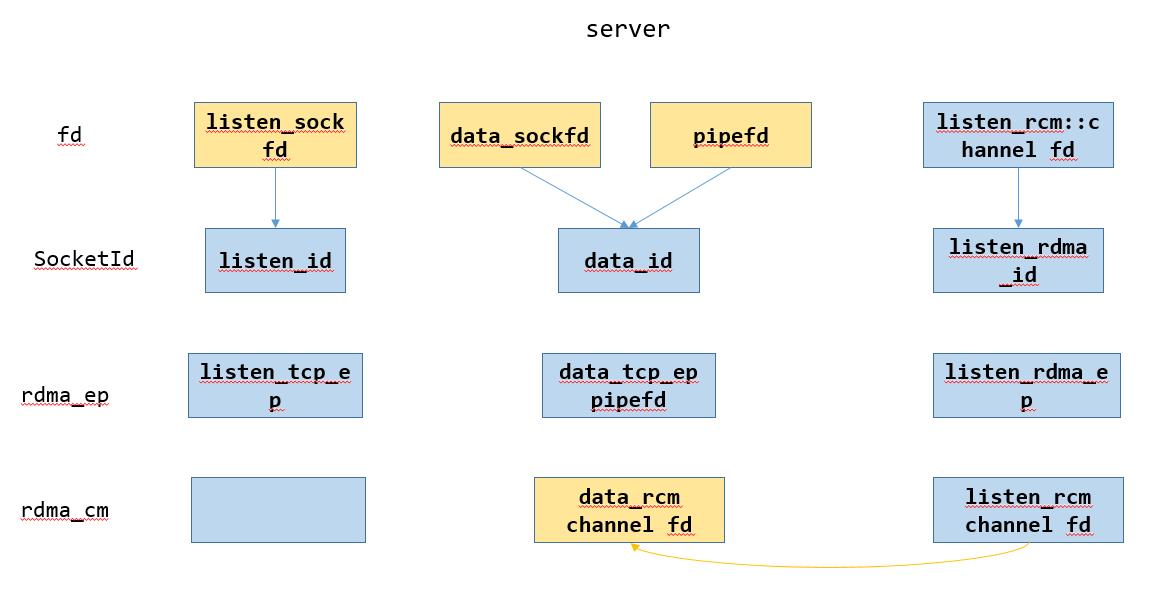
其中蓝色箭头的首尾分别表示在EventDispatcher中的fd和对应的data,黄色箭头表示创建
1. server端:server.start会创建listened_sockfd和RdmaCommunicationManager _listen_rcm
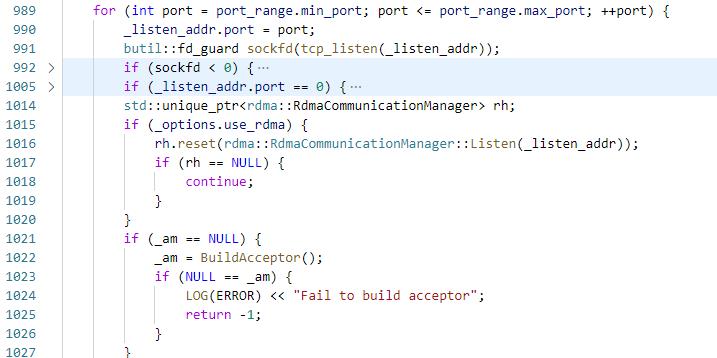
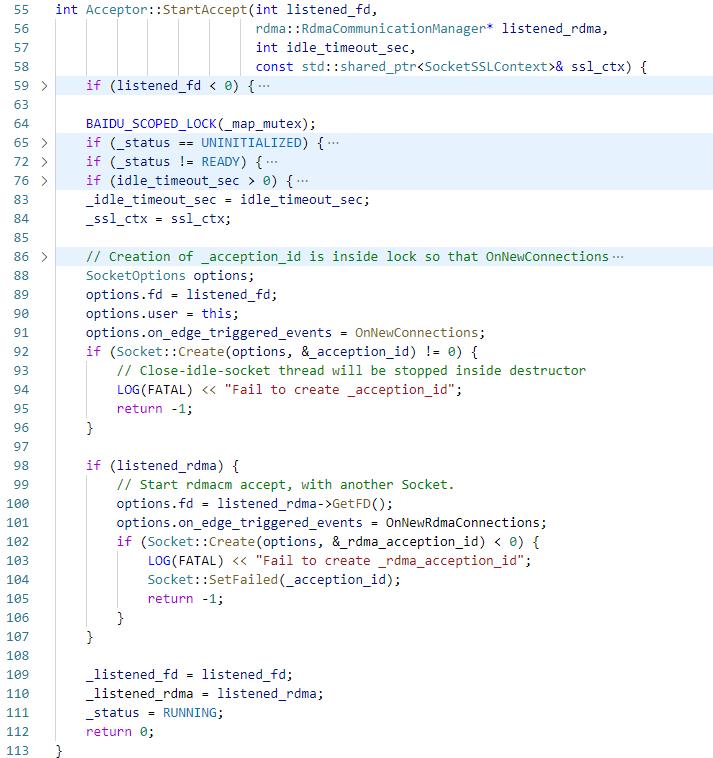
2. server端:然后通过StartAccept启动acceptor,创建两个Socket,liseten_id和listen_rdma_id,其中listen_id的fd是listened_sockfd,listen_rdma_id的fd是listen_rcm的channel fd
3. client端:创建conn_sockfd,执行connect
4. server端:listen_id触发OnNewConnectionsUntilEAGAIN,创建Socket data_id
5. client端:执行Socket::StartWrite,此时_rdma_state == RDMA_UNKNOWN,启动keep_write bthread
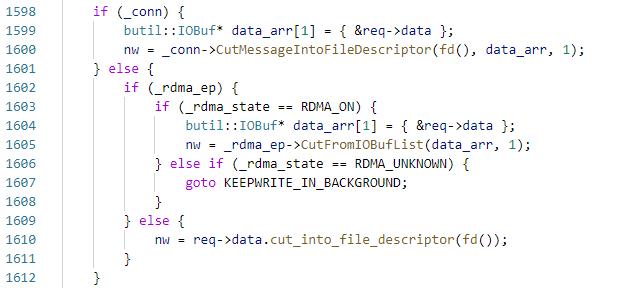
5.1 执行StartHandshake

5.1.1 _status = HELLO_C,向fd写"RDMA" + randstr

5.2 然后butex_wait在_epollout_butex上
6. server端:触发data_id的OnNewMessage,执行DoRead
6.1 此时rdma_state == RDMA_UNKNOWN,执行_rdma_ep->Handshake,注意这个函数,后面将会多次执行
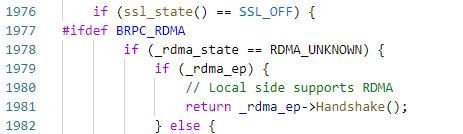

6.1.1 从data_id的fd读入"RDMA"+randstr,执行HandshakeAtServer,此时_status==UNINITIALIZED,_status转为HELLO_S,将data_id写回client

7. client端:触发conn_sockfd的OnNewMessage,同server端步骤5,执行conn_rdma_ep->Handshake
7.1 读入server的socketid,执行HandshakeAtClient

7.1.1 将server的socketid存储到_remote_sid
7.1.2 创建RdmaCommunicationManager conn_rcm,其实就是创建rdma_cm_id,注意这里在rdma_create_id的时候没有显式创建rdma_event_channel,所以之后调用例如rdma_resolve_addr等api是同步的,同步的原因是因为在rdma_resolve_addr里最后执行了rdma_get_cm_event;然后设置cm_id->channel->fd为NONBLOCK,因此rdma_get_cm_event将不再阻塞,所以接下来rdma_resolve_addr等api是异步的
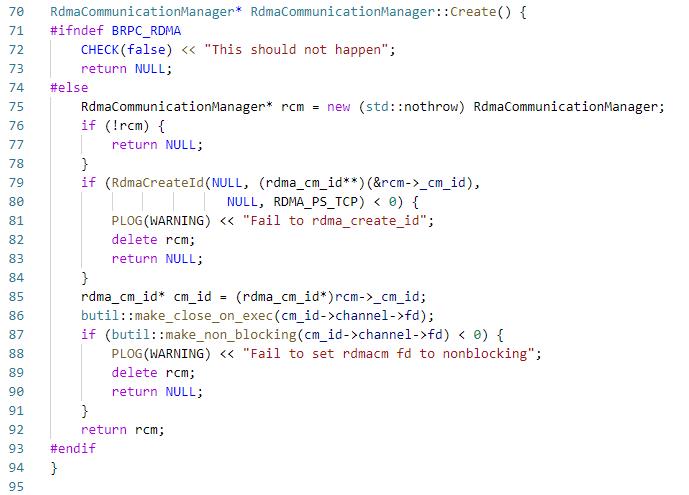
7.1.3 将conn_rcm的cm_id的channel fd添加到edsp中,data为connsock,然后执行ResolveAddr,如上所述,因为conn_rcm的cm_id的channel fd设置为O_NONBLOCK,所以rdma_get_cm_event为异步,即ResolveAddr为异步的,然后当ResolveAddr完成后会触发cm_id的channel fd的POLLIN,从而执行connsock的OnNewMessage
8. client端:重复了步骤6的执行链路,但是在Handshake的时候read到数据长度为0,因此执行conn_rcm->GetCMEvent得到RDMACM_EVENT_ADDR_RESOLVED event,
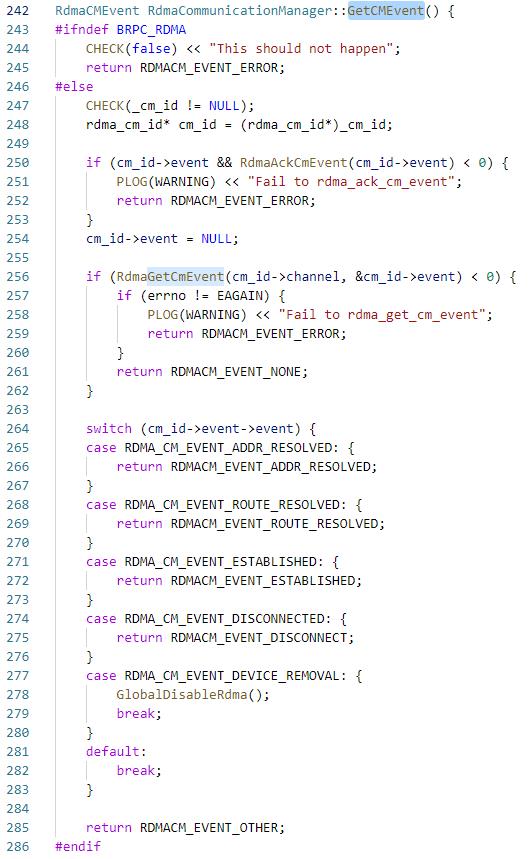
然后执行ResolveRoute,接下来的过程同步骤7,不再赘述,直接看ROUTE_RESOLVING
9. client端:ROUTE_RESOLVING阶段
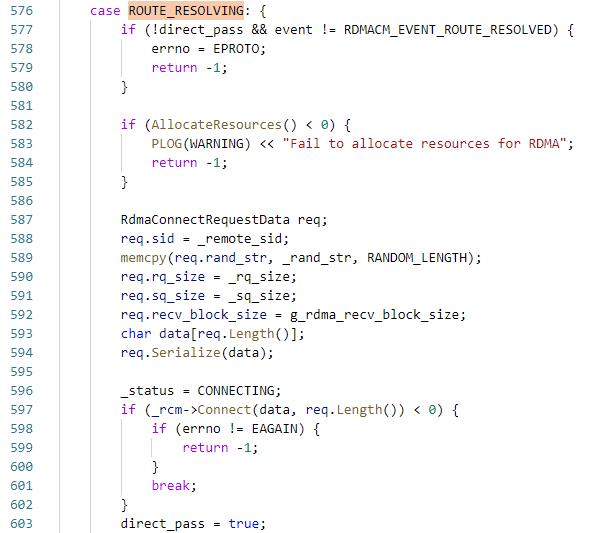
9.1 执行AllocateResources
9.1.1 获取完成队列_rcq
9.1.2 创建QP
9.1.3 创建_sbuf,_rbuf,_rbuf_data
9.1.4执行PostRecv,下发num个recv
9.2 将rq_size,sq_size和recv_block_size设置到conn_param,执行rdma_connect
10. server端:触发listen_rdma_id的POLLIN事件,执行OnNewRdmaConnectionsUntilEAGAIN,
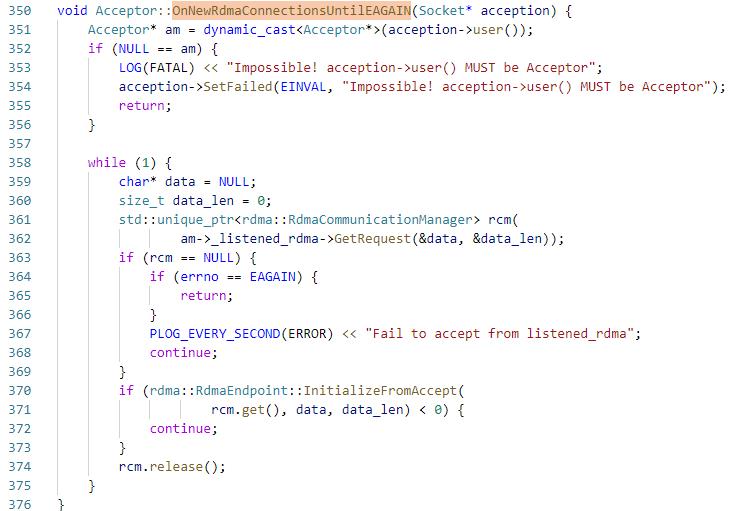
通过RdmaGetRequest获取到rdma_data_id,创建RdmaCommunicationManager data_rcm,拿到client端建连接时的private_data,

执行InitializeFromAccept
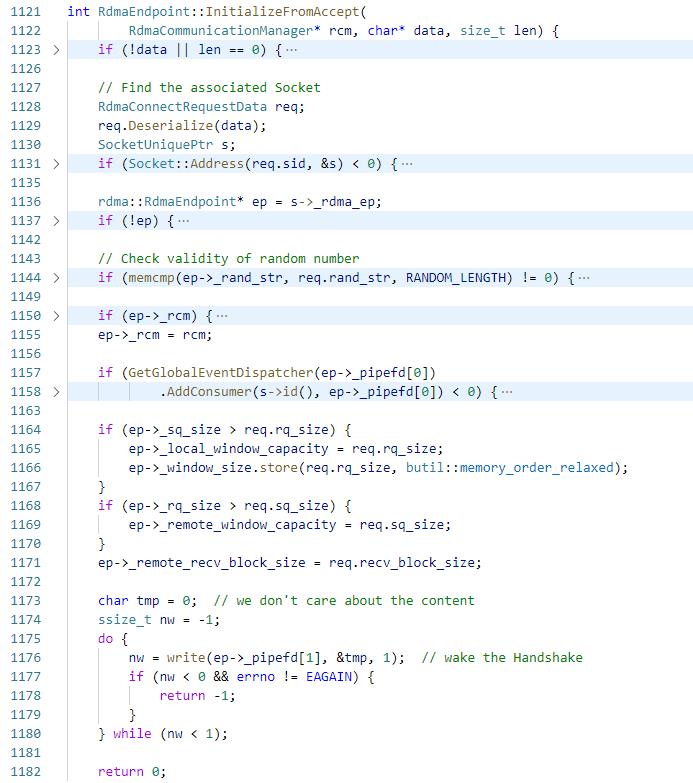
10.1 通过private_data中的socketid获取到data_id,通过比较randstr确认client数据是否正确,然后将data_rcm设置给data_id的_rdma_ep完成绑定,然后通过client端的参数调整server的参数
10.2 将pipefd添加到edsp,然后通过写pipefd触发data_id的流程5
11. server端:执行HandshakeAtServer,此时_status为HELLO_S,AllocateResources,然后将data_rcm的channel fd加入到edsp,然后accept

12. server端:Accept完成,设置_status = ESTABLISHED;_socket->_rdma_state = Socket::RDMA_ON;
13. client端:rdma_connect完成,获取到server端的参数,然后设置_status = ESTABLISHED; _socket->_rdma_state = Socket::RDMA_ON;_socket->WakeAsEpollOut()
基于polling模式的收发数据
然后看下发送逻辑,回顾下TCP场景,通过channel->CallMethod将request写入到Controller->_request_buf,然后在Socket::Write中建立连接,将request写入到fd,在rdma场景中,只有request写入fd这一步骤需要修改,应该写入到之前说的注册内存中,然后执行post send,具体的:
在Socket::StartWrite里会执行_rdma_ep->CutFromIOBufList写一次,没有写完则启动一个bthread后台执行KeepWrite
RdmaEndpoint::CutFromIOBufList,该函数是将输入的多个IOBuf写入到_sbuf中,这里有两个限制,网卡有max_sge的限制,另外发送长度不能超过对端下发的recv_wr对应的内存长度_remote_recv_block_size,因此每当达到这两个限制的时候就执行一次ibv_post_send,如果发送的长度小于64,那么使用IBV_SEND_INLINE的方式以避免网卡额外的一次DMA read,然后设置是否需要使用IBV_SEND_SOLICITED,这个在polling模式下没有用,暂时先不介绍;然后判断是否需要使用IBV_SEND_SIGNALED,由于在创建QP的时候设置了sq_sig_all=0,因此所有的send操作不会产生WC,这样对于应用程序来说轮询的WC变少了,对于网卡来说,减少了一次DMA write,因此提高了性能,但是因为直到该WC或者该WC后面的WC被ibv_poll_cq之后,这个send WR才被认为是完成了,send queue的指针才会被更新,因此这里会隔几个unsignal的WR会post一个signal的WR,否则send queue会overflow;然后设置WR的wr_id为socket_id + 版本号,执行ibv_post_send,到这里发送就执行结束了,接下来就在CQ中poll即可。
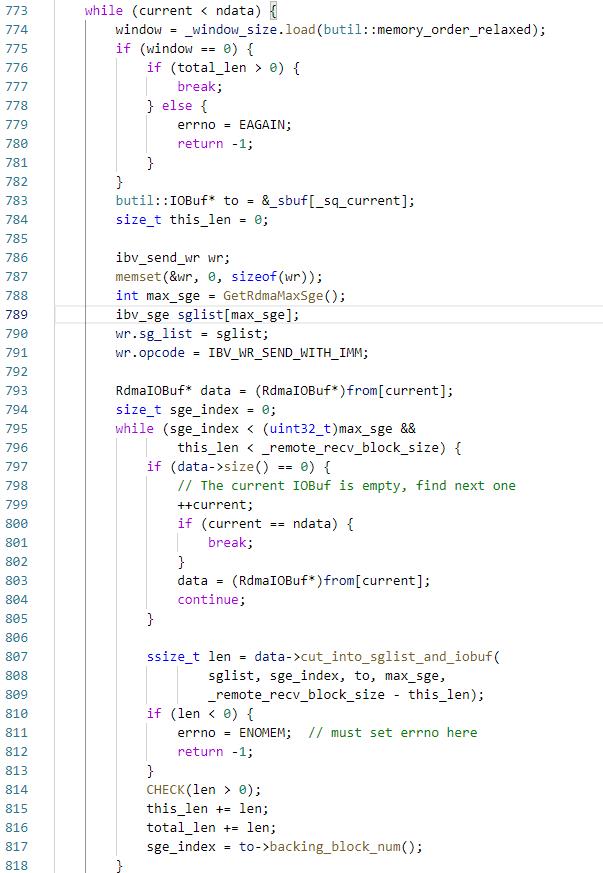
然后看下RdmaCompletionQueue的逻辑
在rdma全局初始化的时候会执行GlobalCQInit,这里会解析CQ可用的core和MSI-X向量
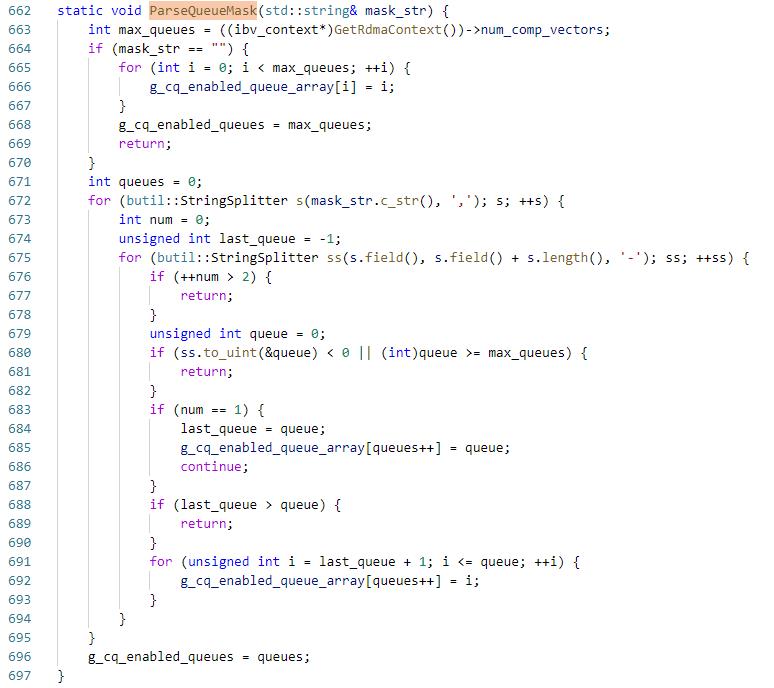
默认可用所有的MSI-X中断向量,用户也可以指定使用哪些中断向量,保存到g_cq_enabled_queue_array
类似的,ParseCpuMask获取CQ可用的core保存到g_cq_enabled_core_array,默认也是使用所有的core
polling模式下会初始化g_cq_num个CQ,初始化方法如下

首先是初始化,_queue_index为ibv_create_cq中指定的comp_vector,每个comp_vector对应了一个event queue,每个event queue对应了一个MSI-X中断向量,这样可以做到充分利用多核;然后创建cq,创建Socket _sid,启动一个bthread执行PollThis,PollThis中会执行PollCQ
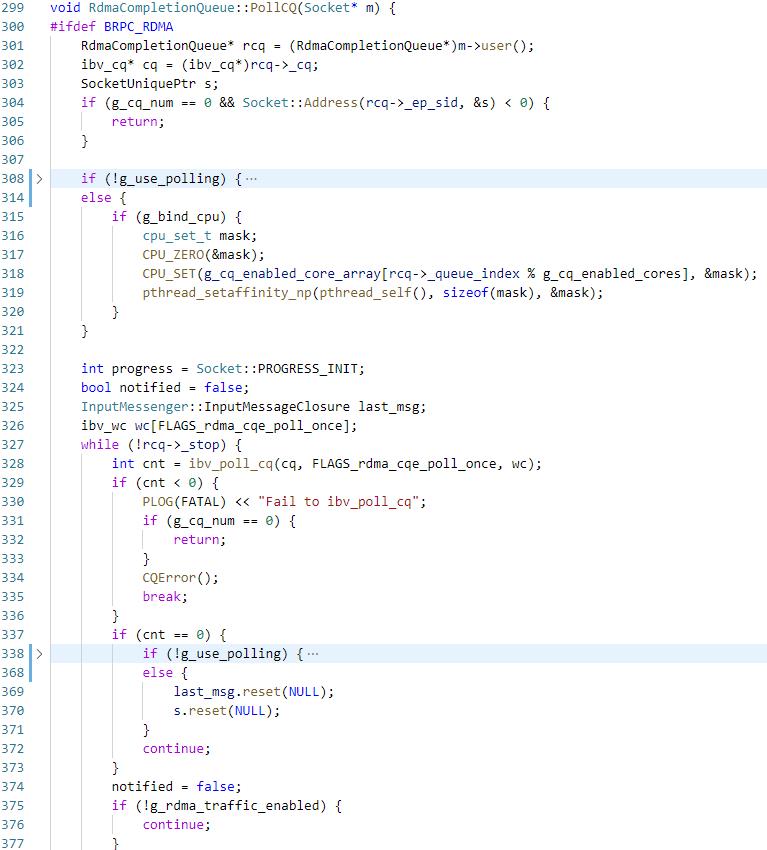
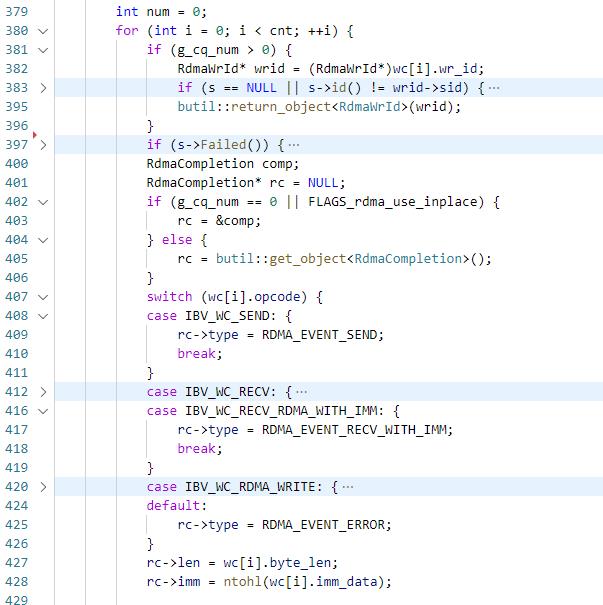

如果指定了绑核,那么会将线程绑定到g_cq_enabled_core_array的某一个core上,然后就在while循环中一直执行ibv_poll_cq,当poll到wc后,会根据wc的wr_id获取到该wc对应的Socket,然后根据wc设置RdmaCompletion comp,将comp添加到对应socket的_rdma_ep 的queue中并将_ncompletions加一,如果_ncompletions此时是0,说明没有bthread在该socket上处理消息,此时新建一个bthread执行HandleCompletions;否则说明有bthread在处理消息,此时什么也不做即可

HandleCompletions是循环执行HandleCompletion,直到_rdma_ep的_ncompletions为0,然后执行RdmaEndpoint::HandleCompletion,
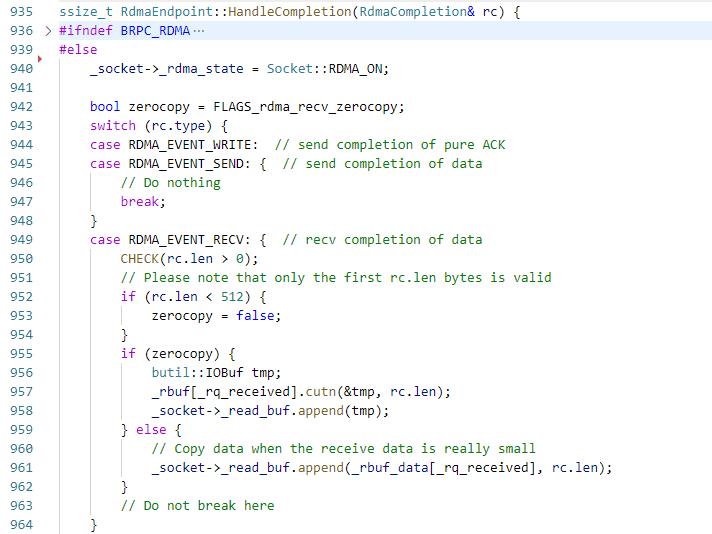
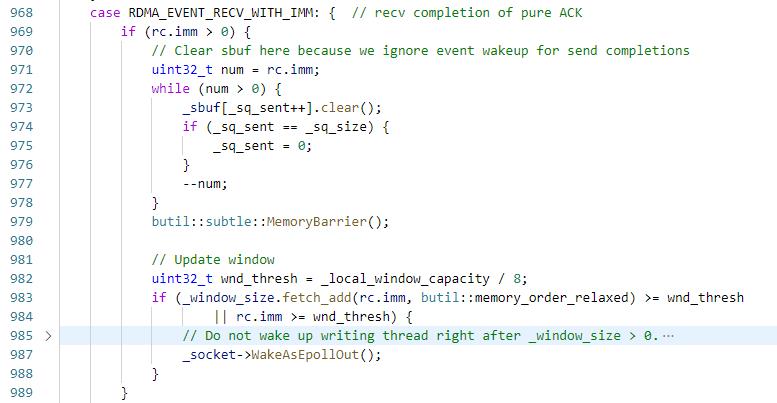
回到之前的发送逻辑,在send WR完成之后会执行到这里的RDMA_EVENT_SEND,其实什么都没做,然后看下接收数据的流程。
仍然先回顾一下TCP场景下接收数据的流程,当Socket收到数据之后会触发edsp,然后执行OnNewMessage,DoRead从fd上读取数据,切割成多条消息,交给多个bthread执行。
那对于rdma来说,需要改切割消息之前的步骤,对于polling模式的话没有edsp这一步骤,而是通过RdmaCompletionQueue的PollCq流程,如上所述,最后会执行RdmaEndpoint::HandleCompletion,因为对端是IBV_WR_SEND_WITH_IMM,所以会触发本端的IBV_WC_RECV,因此将_rbuf[_rq_received]取前len个字节到socket的_read_buf,然后再post一个recv wr,然后执行messenger->ProcessNewMessage,接下来的逻辑和TCP一致,不断的从socket的_read_buf中切割消息并启动多个bthread执行。
上文说到在发送完成之后其实什么也没做,send_buf的清理过程其实是由server端触发的,主要原因是流控,当server端没有下发recv WR的时候,此时如果client端发数据,会报RNR(receive not ready)的错误,因此需要在应用层做流控。
具体的,client端和server端都维护了三个值,_local_window_capacity表示本端最多可向对端post多少个send WR,其实就是min(local SQ, remote RQ),_remote_window_capacity表示对端可以post多少个send WR,其实就是min(local RQ, remote SQ),以及_window_size,表示还可以向本地SQ中post多少个WR
然后回顾client发送数据阶段,_window_size一开始设置_local_window_capacity,在CutFromIOBufList的时候每post一个send WR,_window_size会减一,当为0的时候写入会返回EAGIN,并且负责写入的bthread会wait在Socket的_epollout_butex上。
server收数据时在HandleCompletion post recv WR之后发现rc.len大于0,于是执行SendAck,将_new_rq_wrs加一,当超过_remote_window_capacity的一半后会执行SendImm,告诉client端新产生了这么多个recv WR,client可以发送这么多次。
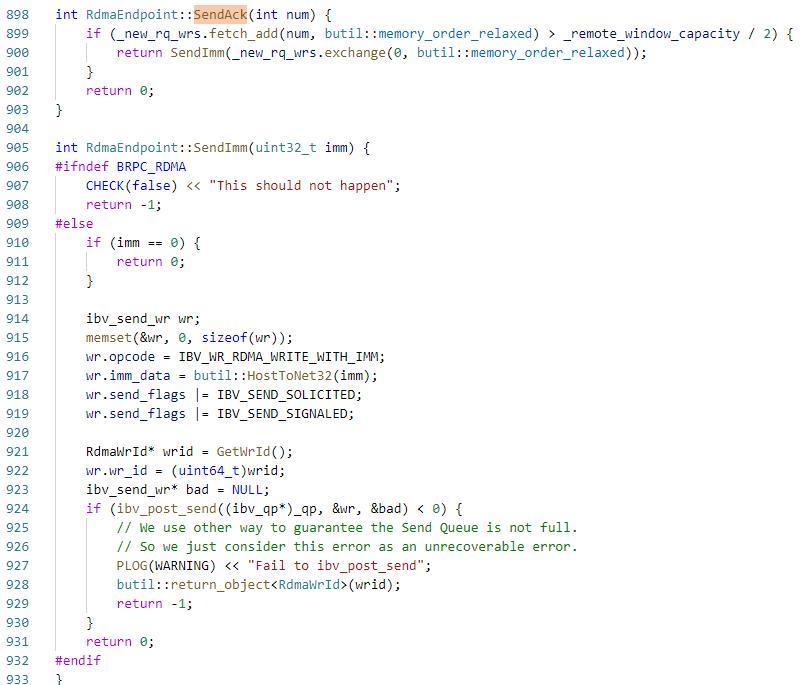
这里的opcode为IBV_WR_RDMA_WRITE_WITH_IMM,会触发client端CQ的IBV_WC_RECV_RDMA_WITH_IMM
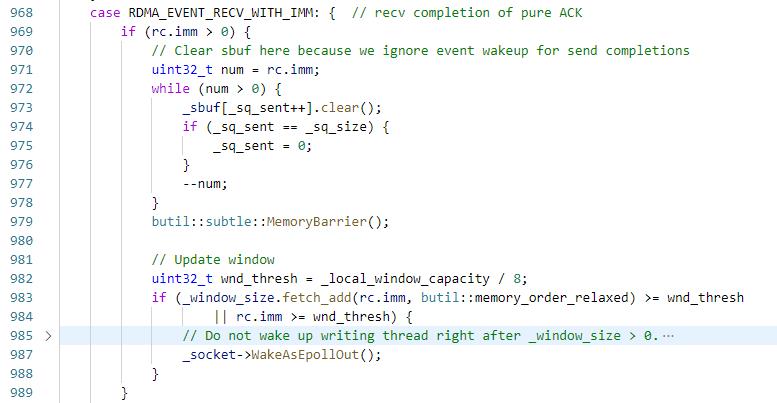
然后又回到这个逻辑,清理_new_rq_wrs 个_sbuf,然后将_window_size加上_new_rq_wrs,这里没有立即wake写数据的bthread,而是等超过阈值才唤醒,以避免bthread的频繁调度。
事件通知模式
最后再说一下基于事件通知的机制,前文说的都是基于polling的模式
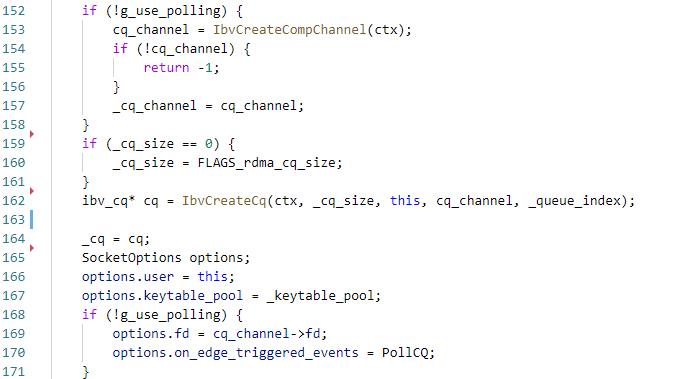
回顾之前RdmaCompletionQueue初始化过程,如果使用事件通知机制的话会创建ibv_comp_channel,将channel的fd设置给Socket,并将事件设置为PollCQ,这样当收到数据后会触发ibv_comp_channel fd的POLLIN,然后edsp会执行PollCQ,然后再看下PollCQ的流程
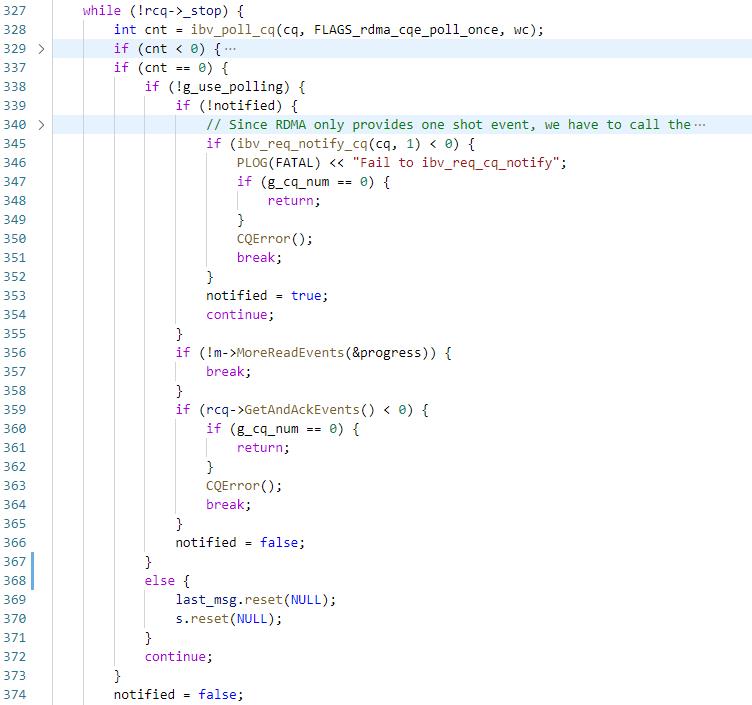
首先还是去ibv_poll_cq,拿到WC之后处理流程和之前一致,但是因为CQ只有处于armed状态的时候才会产生事件,当产生事件之后CQ会由armed转为fired,之后将不会产生事件,因此需要通过ibv_req_notify_cq使CQ重新处于armed状态,这里执行ibv_req_notify_cq的时候设置了solicited_only,所以只有solicit的WR对应的CQE才会触发事件。
由于在执行ibv_poll_cq到执行ibv_req_notify_cq之间的这段时间里可能产生了新的CQE,因此要再执行一下ibv_poll_cq。
最后,特别感谢Tuvie在学习brpc rdma过程中的答疑~
以上是关于brpc源码学习- RDMA通信的主要内容,如果未能解决你的问题,请参考以下文章