分布式数据库架构路线大揭秘
Posted Gauss松鼠会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式数据库架构路线大揭秘相关的知识,希望对你有一定的参考价值。
文章目录
这些年大家都在谈分布式数据库,各大企业也纷纷开始做数据库的分布式改造。那么所谓的分布式数据库是什么?采用什么架构,优势在哪?为什么越来越多企业选择它?我们不妨一起来深入了解下。
分布式数据库是如何演进的?
回顾分布式数据库的演进历程,我们可以大致概括为三个发展阶段:应用分库分表做垂直拆分、分布式中间件、分布式数据库。每个阶段都呈现出了不同的特点:
应用分库分表做垂直拆分本质上是应用侧的改造,和数据库本身没有太大关系。
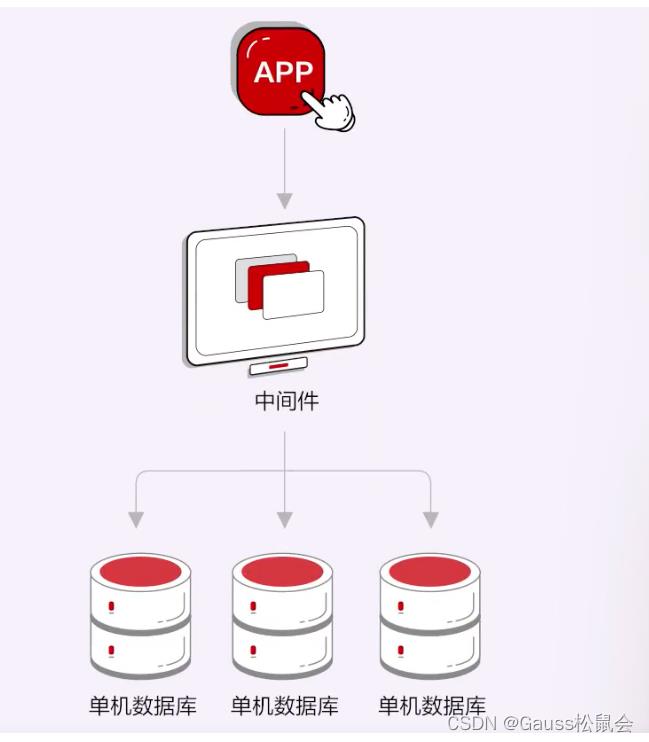
在分布式中间件阶段,分布式数据库本质上是由两部分组成的,上层是分布式中间件,底层再搭载开源mysql或PG单机内核。这种方式因为使用了比较成熟的内核,所以生态友好、成本较低,比较容易实现,不过缺点也显而易见,比如功能降级、分布式事务处理能力较差,最重要的是,因为使用的是开源产品的内核,数据库会始终受制于开源代码修改、专利、发行方式等很多方面的风险,这种形式显然已经无法满足当前国内金融、政企客户的需求。
到了分布式数据库阶段,主要呈现出两种形态。一种是基于分布式存储实现的分布式数据库,这种形态先有分布式存储,再叠加数据库能力,我们习惯把它称为“分布式+”。
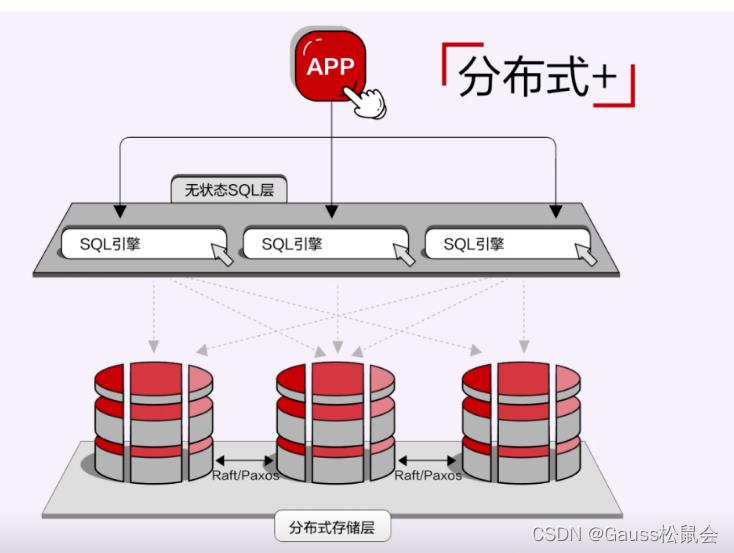
这种架构在分布式比较擅长的领域,更容易形成它的技术竞争力。什么是分布式擅长的领域呢?
比如说像扩展性、及时的扩展性,大规模运维的灵活性,比如扩缩容。在这方面,分布式+的天花板会更少,因为它一开始就是按照分布式存储来设计的。这里面有意思的一点是,这跟架构本身没有太大关系,我们看到,今年所有的在国内的分布式+的厂商都有一个共同特点,就是在整个存储引擎的设计上跟今天我们认知的,不管是MySQL还是PG,都不一样。它不是一个类似于B-TREE的这样一种结构,而通常是基于LSM-Tree存储引擎,数据写内存,然后批量写持久化的这样一种方式。
这是因为这些分布式+的厂商,他们的所有技术体系都来源于Google,而Google最早做的第一款产品就是分布式存储,叫Big Table,Big Table本身就是基于LSM-Tree的,这是一个历史传统。这就是为什么LSM-Tree跟分布式+本身没有必然关系,但是今天我们看到国内所有走分布式+路线的厂商,都使用的是LSM-Tree。
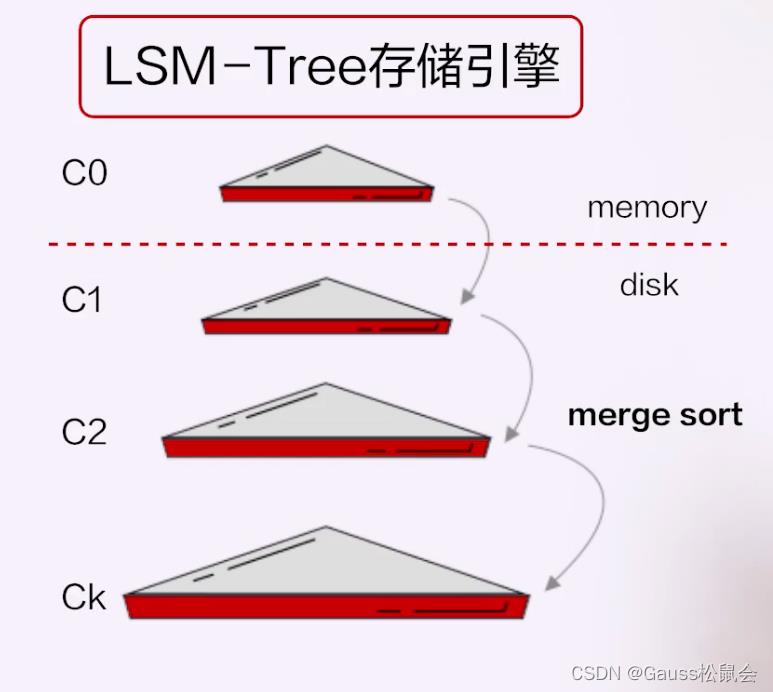
LSM-Tree有它的优点,比如主备之间的异构性有天生的优势,但也有一个非常大的缺点,就是对于场景的普遍适用性。它比较适合于写密集的场景,有大量写入插入,比如我的订单、流水化的订单,但不太适合状态类的业务,有大量的读和写,要去更新状态。而且它把随机写转为顺序写,在做compaction也就是内存和持久化存储数据合并时也会有空间放大和性能抖动问题,所以它整个场景的适用性比B-Tree要低。
这个阶段的另外一种形态,就是基于分布式数据库理论实现的原生分布式数据库,与“分布式+”正好相反,它是先有TP单机数据库引擎,再叠加分布式能力,我们一般称之为“数据库+”,华为云GaussDB分布式数据库就是这种形态的典型代表。
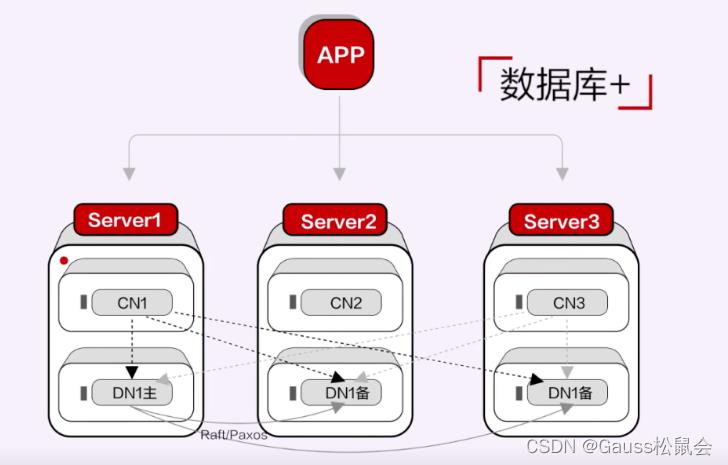
这种形态不存在空间放大和性能抖动的问题,而且更容易在数据库本身所擅长的领域发挥优势,比如说性能、复杂SQL处理能力、企业级能力。同时,因为金融政企客户在使用分布式技术之前,往往已经有分库分表、使用分布式中间件产品的经验,所以对这种架构的认可度更高,学习成本也相对较低,因此这种形态也是国内当前被采用较多的一种。
数据库+与分布式中间件有什么区别?
数据库+和分布式中间件,这两种形式从架构上来看是非常相似的,分布式中间件上面是一个代理层,下面有很多单机数据库。我们可以这么来看,就像是天平的两端,一端在0,一端在1,里面有三个非常大的差别。
如何处理分布式事务,提供外部一致性?
分布式中间件通常是基于XA来实现数据一致性,但XA本身是不能实现外部一致性的,一般只支持最终一致性,而数据库+的分布式数据库可以基于内置全局授时来实现全局一致性读,从而支持外部一致性。
如何处理分布式SQL?
分布式中间件是把数据库作为黑盒,数据节点之间只能通过SQL的形式传递,是标准的SQL。
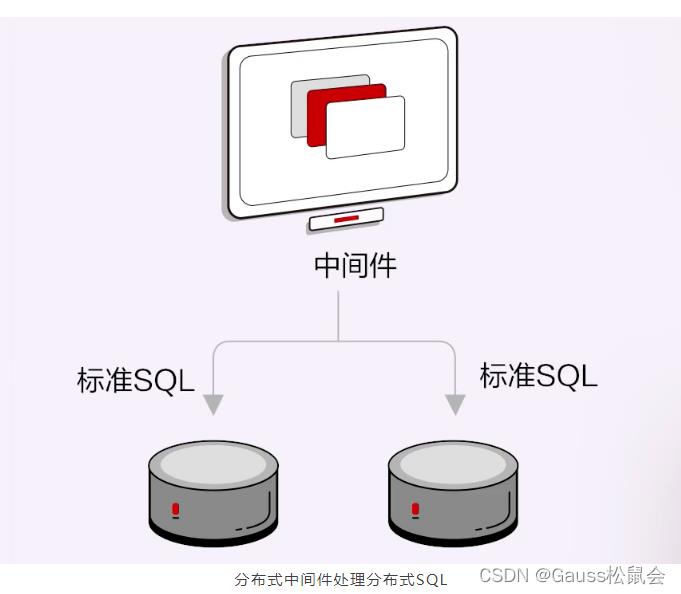
而数据库+的代理层和数据节点是一个数据库的不同部分,互相之间可以传递更加内部的东西,比如计划树,不同的数据节点之间也不需要代理节点,可以直接传递。
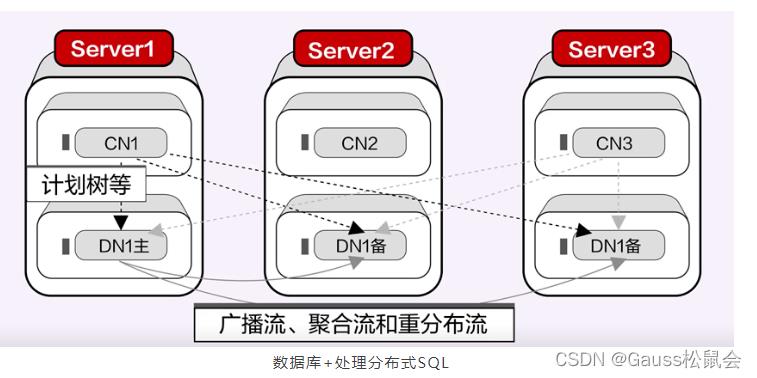
如何实现分布式一致性?
分布式中间件通常是基于传统主备架构,使用半同步、最大保护等模型来实现分布式一致性,不过这种形式下一致性和高可用是没有办法同时兼顾到的,而数据库+是基于原生分布式共识而打造,比如Quorum、Paxos,Raft,可以实现底层无损容灾,同时满足一致性和高可用性。
对于数据库厂商而言,如果以上三个问题全都做到了,那我们可以说它是分布式数据库,如果三者都无法做到,我们一般说它是分布式中间件,如果说只做到了其中的一部分,那就很难下定义究竟是分布式中间件还是分布式数据库,但可以从这三方面去衡量它的天平更倾向哪一边。
数据库+更适合金融政企的未来
出现三种不同的技术路线,本质上是团队的人员能力模型、特质和最初要解决的问题决定了最终走向哪条路线。技术没有绝对的好与坏,只有是不是合适。今天我们看到很多金融政企客户都在提分布式数据库,从0到1的突破可能是由于政策性的突破,因为国产化,但从1到N的突破,是需要产品本身竞争力的突破。
我们发现,在这个阶段,客户不再关心分布式,客户关心什么?关心的是数据库本身。不管叫什么技术,能不能满足需求,能不能提供足够的性能、足够的扩展性、足够的高可用,能不能支撑复杂的业务场景,我们的观点是,最终这个行业会回归到他的本源,分布式数据库的本源是数据库,不管叫分布式+还是数据库+,最终给客户的核心价值仍然是数据库。因此,数据库+更能匹配金融政企未来长期的发展。
GaussDB融合了华为在数据库领域15年多的战略投入,是基于分布式理论打造的行业领先的国产原生分布式关系型数据库,采用行业先进的全并行分布式架构,有应对海量并发事务处理与复杂查询混合负载的能力;还有同城跨AZ、两地三中心、数据0丢失等多种高可用方案,出色的金融级高可用商用能力全方面满足金融级监管要求。
现在,GaussDB已经在金融行业积累了非常丰富的实践经验,历经华为终端云、华为流程IT、全球TOP银行、运营商等各种严苛场景的考验,不仅成功助力邮储银行新一代个人业务分布式核心系统全面投产上线,为全行6.5亿个人客户、4万多个网点提供日均20亿笔、峰值6.7万笔/秒的交易处理能力,还通过一系列技术创新,轻松支撑华为流程IT ERP系统5倍业务压力下性能保持线性,实现业务效率的10倍提升,是企业数字化转型、核心数据上云、分布式改造的信赖之选。
揭秘java大数据学习路线图
很多的同学在学习JavaEE的路上都过得的是坎坷,可以说是夜以继日的敲代码在学习,却发现自己是事倍功半,有的时候遇到一个bug真的很难受,无限互联java大数据培训专家为大家整理了一篇很值得大家去借鉴的学习路线图文章,希望大家在学习的路上一能帆风顺!
一、Java的核心
这就是学习Java的基础,掌握程度的深与浅甚至直接影响后面的整个学习进程。
Java的核心主要包括了几个部分:
一、 java大数据学习路线图
1、初级的有语法基础、面向对象思想。
学习任何一门语言语法都是必须的,因为Java的接近自然语言,也是一种相对比较容易学的语言。同时面向对象编程更是其核
心思想,要理解其实只要记住一句话就行了,那就是:一切皆是对象。
2、中级的IO流、多线程、反射及注解等。
IO流程、多线程等是相对比较高级一点的了,通过学习我们会发现这些都很有用而且很有趣。例如我们可以读取一个Excel文件
、将一个文件分离,做一 个时钟、使用多个线程发送邮件等等很多有意思的事。另外反射及注解更是后面流行框架SSH等的基础,
在使用中你便会慢慢感受到它的无穷魅力。
3、高级一点的就是设计模式和框架之类了。
要学习好一门语言,仅仅会使用还是不够的,我们不仅要深入研究其原理,而且还要找到其一些共性的东西,从而减少反复的
劳动,让代码可重用、更可靠且更容易被别人理解。
二、前端Web
现在来说Java最流行的应用还是Web开发。那么作为Web开发,对于前台的知识的学习也是必须的,当然并不是一定要按照前端
工程师的标准去要求。 但是一些基础的知识也是必须要掌握的,毕竟Web应用是前台和后台的一个交互的过程。像HTML、CSS、Java
等都是基础的知识,另外作 为开发人员对目前最流行的Java框架Jquery更是必学不可的。
三、数据库
有人说,所有的应用无非就是数据的输入、处理到输出的过程。期间同时可能还会涉及到数据的存储问题。对于结构化的数据
,我们常用的还是像 Oracle、Mysql和PostgreSQL之类的关系型数据库。同时针对数据库编程还是PL/SQL需要学习。使用Java访问
数据库的话还有 JDBC。那么对于非结构化的数据以及大数据该如何处理呢?其实这里也已经有了非常成熟的解决方案了,那便是
Hadoop。就Hadoop而言他并不是一 种思想,更多是一个实现了Mapreduce模式的框架。
四、J2EE
好了,前面这么多准备的工作。下面我们进入正题。作为Java开发,CoreJava是核心,而作为JavaWeb开发,我认为Servlet才
是核 心。Servlet是服务器端的Java应用程序,但是与普通的Java应用程序不同的是,它是由web服务器来加载启动,即我们常说的
Servlet, 如Tomcat便是servlet容器。另外谈到J2EE开发,这里有一个重要的模型不得不提一下,很多人其实已经想到了,那便是
MVC(模型-视图-控 制器)模型。在传统的web开发中,往往是JavaBean充当模型、JSP做视图而Servlet作为控制器。
五、框架
说到框架,其实已经提到了著名的MVC模型,SSH(Struts+Spring+Hibernate)就是一个非常好的实现。对于每一个框架的作 用
,我想就不用多说了,毕竟这里并不是想写一本教程。另外还有工作流开发的JBPM,搜索引擎Lucence及使系统对外提供接口的
webservice 应用组件等都是应该要掌握的。
六、服务器
关于服务器,像tomcat、jboss、weblogic及websphere等便不提了,因为太普遍了。这里要说的是Nginx,
Nginx ("engine x")是一个高性能的HTTP和反向代理服务器。其以占有内存少,并发能力强而著称,连新浪、网易、腾讯这类
知名企业也在使用,所以还有什么理由不去学它呢?
七、工具
这里主要介绍几个开发辅助工具。如日志工具Log4j、测试工具Junit、版本管理工具SVN还有项目管理maven等。
另外还有第三方插件Ectable。
八、项目示例
Springside是以Spring框架为核心的J2EE应用参考示例,是JavaEE中的比较主流的技术选型及最佳实践的总结与演示,非常值得一看。把它看透了,J2EE就差不多了甚至是比较厉害的了。
兄弟连Java大数据专家觉得,说到底,对于技术的学习,有一个规则是通用的,那便是实践。把学习到的东西马上用起来做出一个示例来,我认为是一种 比较好的学习方法。首先它是对零散知识的一个自然总结,另外通过一些小示例的实践,可以增加学习的兴趣。而且可以通过示例,深入学习其实现的原理,加深掌 握的程度且能更快的应用到实际开发中,提高工作效率。
兄弟连Java大数据
以上是关于分布式数据库架构路线大揭秘的主要内容,如果未能解决你的问题,请参考以下文章