Redis在项目中的运用总结
Posted 常生果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis在项目中的运用总结相关的知识,希望对你有一定的参考价值。
1 概述
Redis作为一款性能优异的内存数据库,在互联网公司有着多种应用场景,本文介绍笔者在项目中使用Redis的场景。主要从以下几个方面介绍:
分布式锁
接口限流器
订单缓存
Redis和DB数据一致性处理
防止缓存穿透和雪崩
分布式session共享
2 分布式锁
Redis实现分布式锁
3 接口限流器
Redis实现限流器
4 订单缓存
整个订单的存储结构如下:
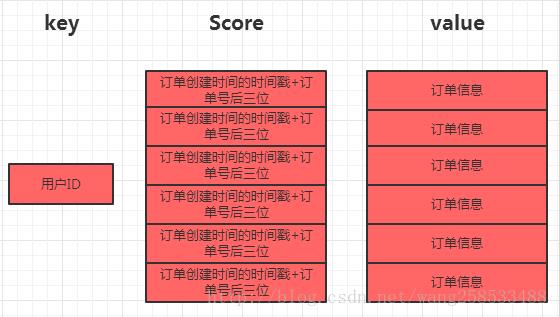
使用Redis的zset数据结构存储每个用户的订单,按照下单时间倒序排列,用户唯一标识作为key,用户的订单集合作为value,使用订单创建时间的时间戳+订单号后三位作为分数
为什么不直接使用下单时间的时间戳作为分数?因为下单时间只精确到秒,同一秒可能出现多个订单情况,这样就会出现相同的分数,而加上订单号后三位就能基本上避免这种情景。
只放用户的前N条订单即可,因为很少有用户会查看很久以前的订单,这样做会节省很多空间。如果有用户需要查看前N条之后的订单,再从数据库中查询即可,当然这种概率就比较小了。
5 Redis和DB数据一致性处理
只要有多份数据,就会涉及到数据一致性的问题。Redis和数据库的数据一致性,也是必然要面对的问题。我们这边的订单数据是先更新数据库,数据库更新成功后,再更新缓存,若数据库操作成功,缓存操作失败了,就出现了数据不一致的情况。保证数据一致性我们前后使用过两种方式:
方式一
循环5次更新缓存操作,直到更新成功退出循环,这一步主要能减小由于网络瞬间抖动导致的更新缓存失败的概率,对于缓存接口长时间不可用,靠循环调用更新接口是不能补救接口调用失败的。
如果循环5次还没有更新成功,就通过worker去定时扫描出数据库的数据,去和缓存中的数据进行比较,对缓存中的状态不正确的数据进行纠正。
方式二
跟方式一的第一步操作一样
若循环更新5次仍不成功,则发一个缓存更新失败的mq,通过消费mq去更新缓存,会比通过定时任务扫描更及时,也不会有扫库的耗时操作。此方式也是我们现在使用的方式,下面是示例代码:
for (int i = 0; i < 5; i++)
try
// 入缓存操作
addOrderListRedis(key, score, orderListVO);
break;
catch (Exception e)
log.error("IOrderRedisCache.putOrderList2OrderListRedis--->>jdCacheCloud.zAdd exception:", logSid, e);
if (i == 4) sendUpOrderCacheMQ(orderListVO, logSid); // 如果循环5次,仍添加缓存失败,发送MQ,通过MQ继续更新缓存
6 防止缓存穿透和雪崩
缓存为我们挡住了80-90%甚至更多的流量,然而当缓存中的大量热点数据恰巧在差不多的时间过期时,或者当有人恶意伪造一些缓存中根本没有的数据疯狂刷接口时,就会有大量的请求直接穿透缓存访问到数据库(因为查询数据策略是缓存没有命中,就查数据库),给数据库造成巨大压力,甚至使数据库崩溃,这肯定是我们系统不允许出现的情况。我们需要针对这种情况进行处理。下图是处理流程图:
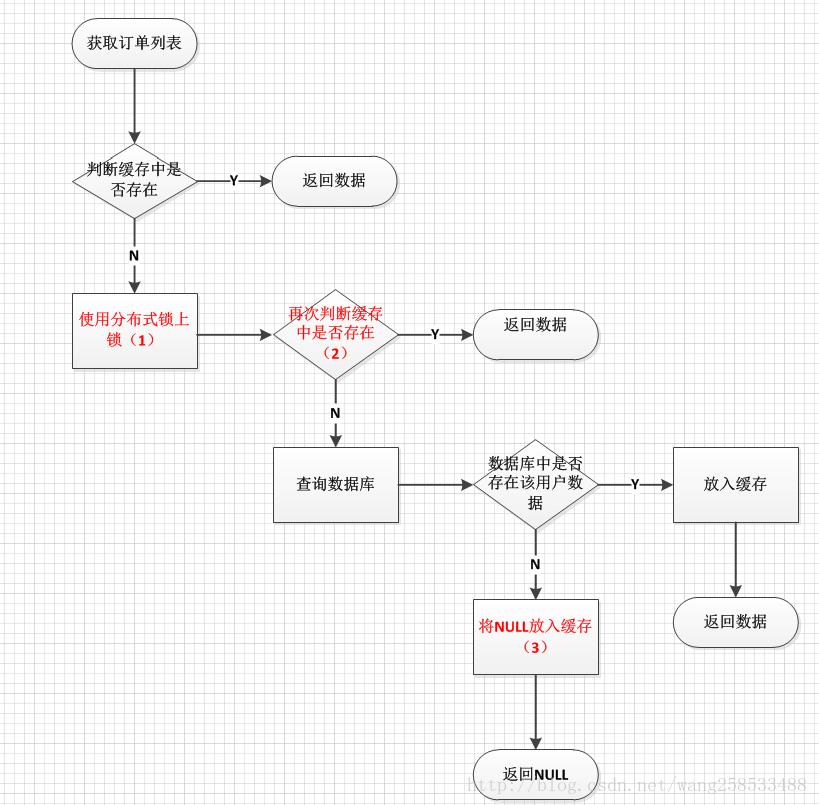
示例代码:
// 代码段1
// 锁的数量 锁的数量越少 每个用户对锁的竞争就越激烈,直接打到数据库的流量就越少,对数据库的保护就越好,如果太小,又会影响系统吞吐量,可根据实际情况调整锁的个数
public static final String[] LOCKS = new String[128];
// 在静态块中将128个锁先初始化出来
static
for (int i = 0; i < 128; i++)
LOCKS[i] = "lock_" + i;
// 代码段2
public List<OrderVOList> getOrderVOList(String userId)
List<OrderVOList> list = null;
// 1.先判断缓存中是否有这个用户的数据,有就直接从缓存中查询并返回
if (orderRedisCache.isOrderListExist(userId))
return getOrderListFromCache(userId);
// 2.缓存中没有,就先上锁,锁的粒度是根据用户Id的hashcode和127取模
String[] locks = OrderRedisKey.LOCKS;
int index = userId.hashCode() & (locks.length - 1);
try
// 3.此处加锁很有必要,加锁会保证获取同一个用户数据的所有线程中,只有一个线程可以访问数据库,从而起到减小数据库压力的作用
orderRedisCache.lock(locks[index]);
// 4.上锁之后再判断缓存是否存在,为了防止再获得锁之前,已经有别的线程将数据加载到缓存,就不允许再查询数据库了。
if (orderRedisCache.isOrderListExist(userId))
return getOrderListFromCache(userId);
// 查询数据库
list = getOrderListFromDb(userId);
// 如果数据库没有查询出来数据,则在缓存中放入NULL,标识这个用户真的没有数据,等有新订单入库时,会删掉此标识,并放入订单数据
if(list == null || list.size() == 0)
jdCacheCloud.zAdd(OrderRedisKey.getListKey(userId), 0, null);
else
jdCacheCloud.zAdd(OrderRedisKey.getListKey(userId), list);
return list;
finally
orderRedisCache.unlock(locks[index]);
防止穿透和雪崩的关键地方在于使用分布式锁和锁的粒度控制。首先初始化了128(0-127)个锁,然后让所有缓存没命中的用户去竞争这128个锁,得到锁后并且再一次判断缓存中依然没有数据的,才有权利去查询数据库。没有将锁粒度限制到用户级别,是因为如果粒度太小的话,某一个时间点有太多的用户去请求,同样会有很多的请求打到数据库。比如:在时间点T1有10000个用户的缓存数据失效了,恰恰他们又在时间点T1都请求数据,如果锁粒度是用户级别,那么这10000个用户都会有各自的锁,也就意味着他们都可以去访问数据库,同样会对数据库造成巨大压力。而如果是通过用户id去hashcode和127取模,意味着最多会产生128个锁,最多会有128个并发请求访问到数据库,其他的请求会由于没有竞争到锁而阻塞,待第一批获取到锁的线程释放锁之后,剩下的请求再进行竞争锁,但此次竞争到锁的线程,在执行代码段2中第4步时:orderRedisCache.isOrderListExist(userId),缓存中有可能已经有数据了,就不用再查数据库了,依次类推,从而可以挡住很多数据库请求,起到很好的保护数据库的作用。
---------------------
作者:秦霜
来源:CSDN
原文:https://blog.csdn.net/wang258533488/article/details/78901124
版权声明:本文为博主原创文章,转载请附上博文链接!
以上是关于Redis在项目中的运用总结的主要内容,如果未能解决你的问题,请参考以下文章