sona:Spark on Angel大规模分布式机器学习平台介绍
Posted zhongrui_fzr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sona:Spark on Angel大规模分布式机器学习平台介绍相关的知识,希望对你有一定的参考价值。
Angel是一个基于参数服务器(Parameter Server)开发的高性能分布式机器学习平台,它基于腾讯内部的海量数据进行了反复的调优。 Angel的核心设计理念围绕模型,将高维度的大模型切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数,以及灵活的同步协议,轻松实现各种高效的机器学习算法。 Angel基于Java和scala开发,能在Yarn上直接调度运行,并基于PS Service,支持Spark on Angel,集成了部分图计算和深度学习算法。 Angel-PS实现了基于参数服务器的矩阵计算,将分布在多台PS Server上的参数矩阵抽象为PSModel,只需要完成PSModel的定义、实现其计算过程,就可以实现一个运行在参数服务器上的简单算法。 简单的angel-ps架构如下图所示- PS是存储矩阵参数的多台机器,向计算节点提供矩阵参数的拉取、更新服务
- 每个worker是一个逻辑计算节点,一个worker可以运行一或多个task
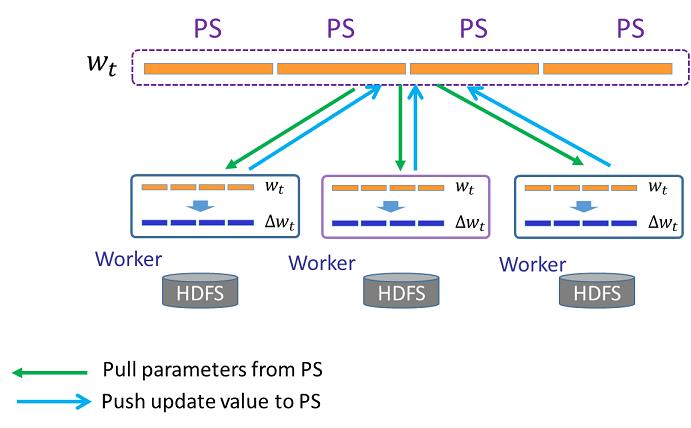 机器学习的算法,一般以迭代的方式训练,每次迭代worker从PS拉取最新的参数,计算一个更新值,推送给PS
Angel整体架构
机器学习的算法,一般以迭代的方式训练,每次迭代worker从PS拉取最新的参数,计算一个更新值,推送给PS
Angel整体架构
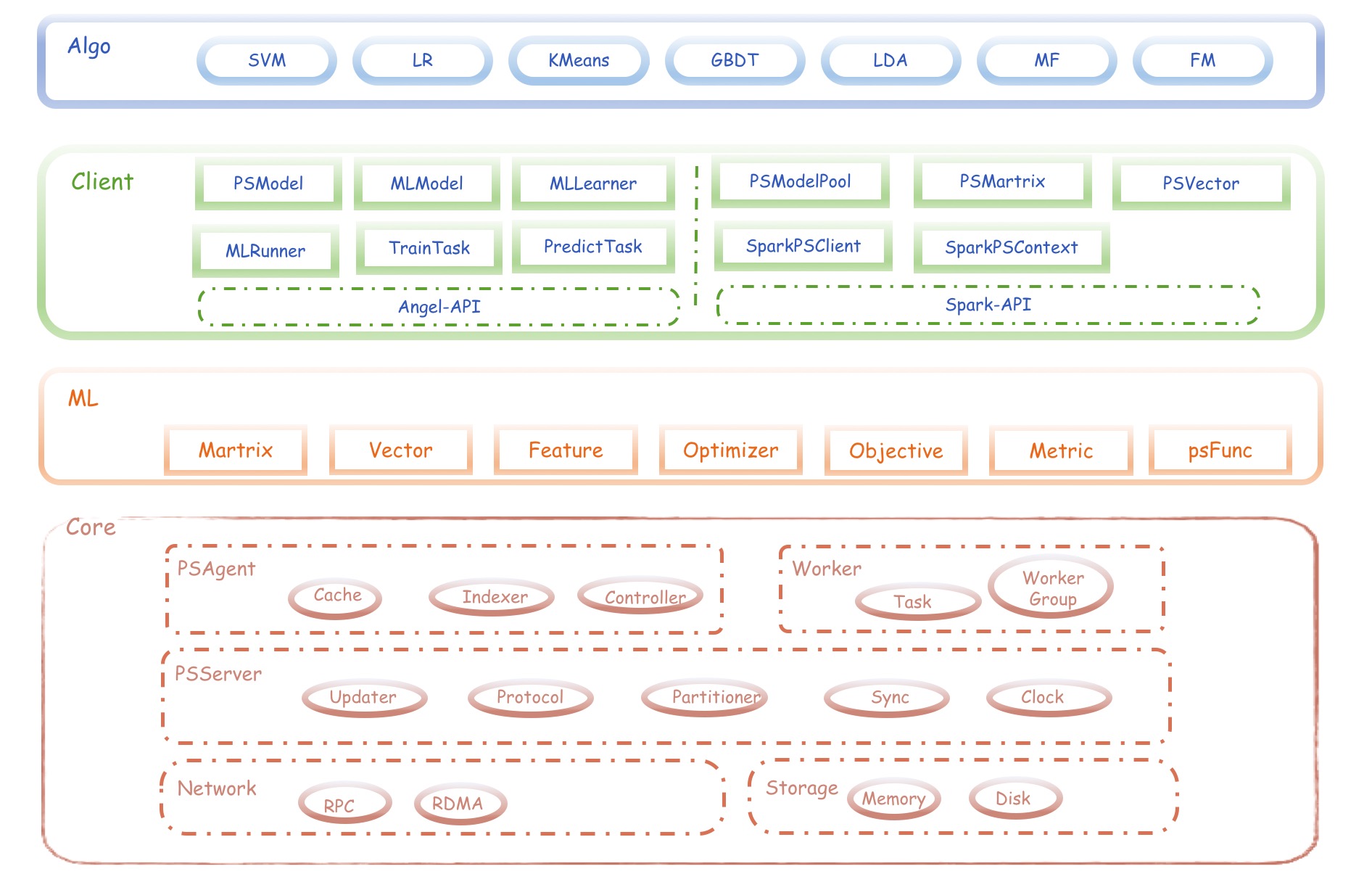
 angel的架构分为三大模块:
1、 Parameter Server层:提供通用的参数服务器服务,负责模型的分布存储,通讯同步和协调计算,并通过PSAgent提供PS Service
2、worker层:基于Angel自身模型设计的分布式运行节点,自动读取并划分数据,局部训练出模型增量,通过PS Client和PS Server通信,完成模型训练和预测。一个worker包含一个或多个Task,Task是Angel计算单元,这样设计的原因是可以让Task共享Worker的许多公共资源。
3、Model层,这是一层虚拟抽象层,并非真实存在的物理层。关于Model的Push和Pull,各种异步控制,模型分区路由,自定义函数。。。是联通Worker和PSServer的桥梁。
除了这三个模块,还有2个很重要的类,
1、Client:Angel任务运行的发起者
angel的架构分为三大模块:
1、 Parameter Server层:提供通用的参数服务器服务,负责模型的分布存储,通讯同步和协调计算,并通过PSAgent提供PS Service
2、worker层:基于Angel自身模型设计的分布式运行节点,自动读取并划分数据,局部训练出模型增量,通过PS Client和PS Server通信,完成模型训练和预测。一个worker包含一个或多个Task,Task是Angel计算单元,这样设计的原因是可以让Task共享Worker的许多公共资源。
3、Model层,这是一层虚拟抽象层,并非真实存在的物理层。关于Model的Push和Pull,各种异步控制,模型分区路由,自定义函数。。。是联通Worker和PSServer的桥梁。
除了这三个模块,还有2个很重要的类,
1、Client:Angel任务运行的发起者
- 启动和停止PSServer
- 启动和停止Angel的Worker
- 加载和存储模型
- 启动具体计算过程
- 获取任务运行状态
- 原始计算数据以及参数矩阵的分片和分发
- 向Gaia申请Worker和ParameterServer所需的计算资源
- 协调,管理和监控Worker以及PSServer
- PSServer层:通过PS-Service,提供灵活的多框架PS支持
- Model层:提供PS必备的功能,并支持对性能进行针对性优化
- Worker层:能基于Angel自主API,进行算法开发和创新的需求
 1、
Angel-Core:核心层
Angel的核心层,包含如下组件:
1、
Angel-Core:核心层
Angel的核心层,包含如下组件:
- PSServer
- PSAgent
- Worker
- AngelClient
- 网络:RPC & RDMA
- 存储:Memory & Disk
- Matrix
- Vector
- Feature
- Optimizer
- Objective
- Metric
- psFunc
- SVM
- LR (各种优化方法)
- KMeans
- GBDT
- LDA
- MF(矩阵分解)
- FM(因式分解机)
- Angel_PS_Worker:启动master,PS和Worker,Angel独立完成模型的训练
- Angel_PS_service:PS Service模式,在这种模式下,Angel只启动Master和PS,具体的计算交给其他计算平台(如Spark,TensorFlow)负责,Angel只负责提供Parameter Server的功能
- Angel支持多种同步协议:除了通用的BSP(Bulk Synchronous Parallel)外,为了解决task之间互相等待的问题,Angel还支持SSP(Stale Synchronous Parallel)和ASP(Asynchronous Parallel)
- 训练数据和模型自动切割:Angel根据配置的worker和task数量,自动对训练数据进行切分,同样,也会根据模型大小和PS实例数量,对模型实现自动分区。
- 易用的编程接口:MLModel、PSModel、AngelClient
- psFunc:为了满足各类算法对参数服务器的特殊需求,Angel将参数获取和更新过程进行了抽象,提供了psf函数功能。用户只需要继承Angel提供的psf函数接口,并实现自己的参数获取/更新逻辑,就可以在不修改Angel自身代码的情况下定制自己想要的参数服务器的接口。
- 自定义数据格式:Angel支持Hadoop的InputFormat接口,可以方便的实现自定义文件格式。
- 自定义模型切分方式:默认情况下, Angel将模型(矩阵)切分成大小相等的矩形区域;用户也可以自定义分区类来实现自己的切分方式
- PS容错:PS容错采用了checkpoint模式,也就是每隔一段时间将PS承载的参数分区写到hdfs上。如果一个PS实例挂掉,Master会新启动一个PS实例,新启动的实例会加载挂掉PS实例写的最近的一个checkpoint,然后重新开始服务。这种方案的优点是简单,借助了hdfs多副本容灾,缺点是不可避免的会丢失少量参数更新
- worker容错:一个worker实例挂掉后,Master会重新启动一个Worker实例,新启动的Worker实例从Master处获取当前迭代轮数等状态信息,从PS处获取最新模型参数,然后重新开始被断掉的迭代。
- Master容错:Master定期将任务状态写入hdfs,借助于Yarn提供的App Master 重试机制,当Angel的Master挂掉后,Yarn会重新拉起一个Angel的master,新的Master加载状态信息,然后重新启动Worker和PS,从断点出发重新开始计算。
- 慢worker检测:Master将会收集一些Worker计算性能的一些指标,如果检测到有一些worker计算明显慢于平均计算速度,Master会将这些worker重新调度到其他的机器上,避免这些worker拖慢整个任务的计算进度。
- spark RDD是不可变区,Angel PS是可变区
- Spark通过PSAgent与Angel进行协作和通讯
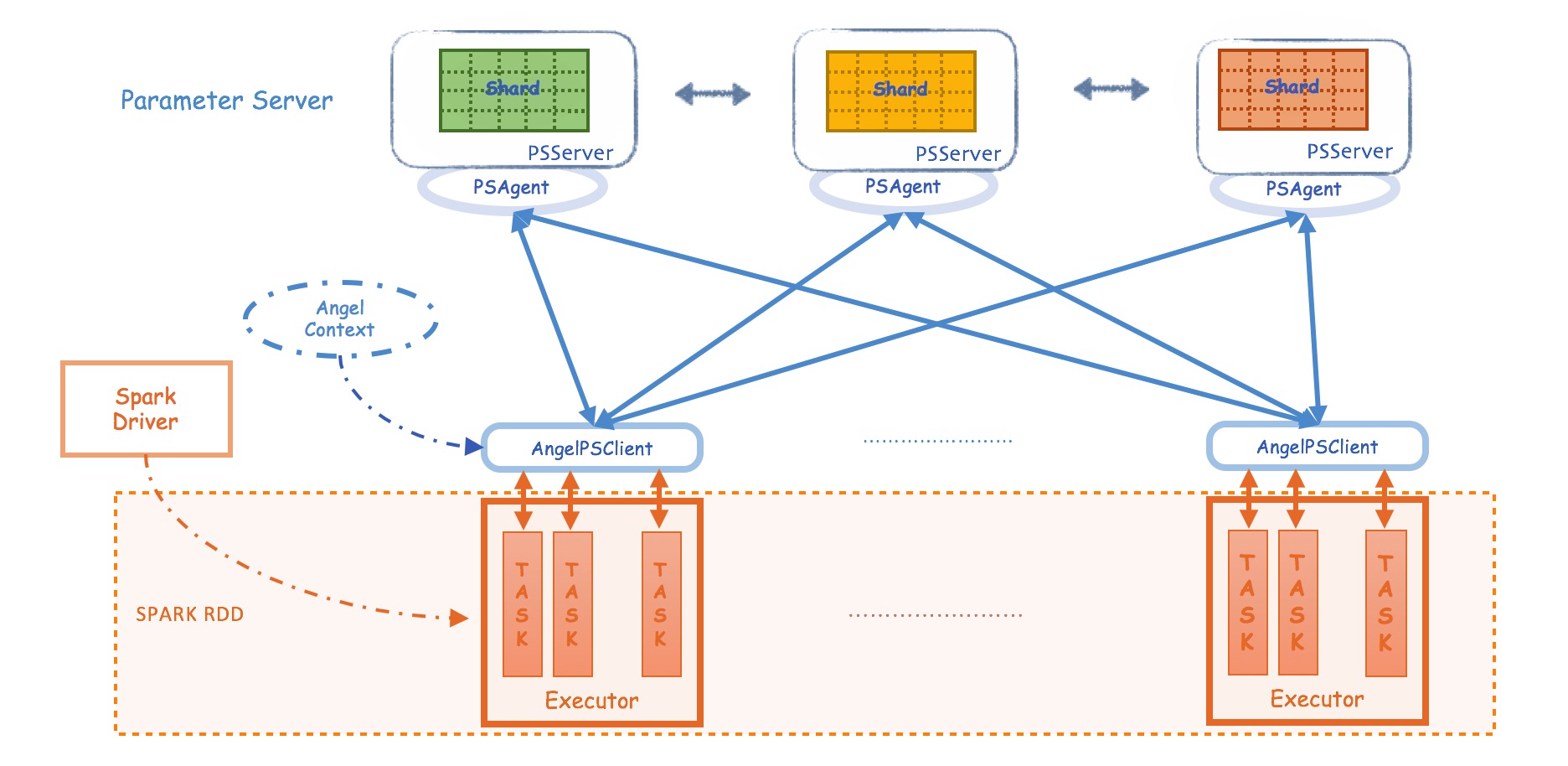
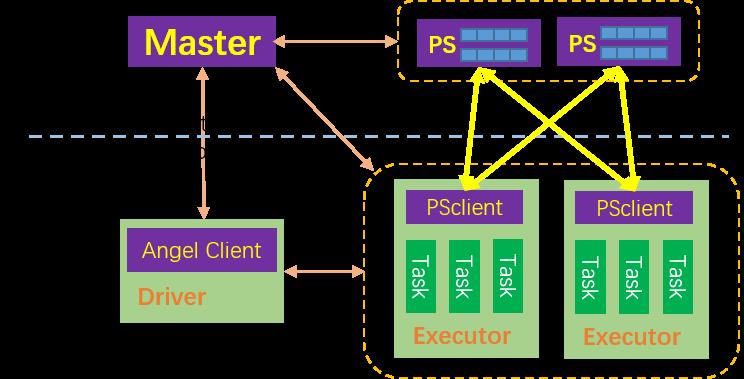 核心实现:
核心实现:
- PSContext:利用spark的Context和angel的配置,创建AngelContext,在Driver端负责全局的初始化和启动工作
- PSModel:PSModel是PS server上PSVector/PSMatrix的总称,包含着PSClient对象,PSModel是PSVector和PSMatrix的父类
- PSVector:PSVector的申请通过PSVector.dense(dim:Int, capacity: Int=50, rowType:RowType.T_DENSE_DOUBLE)申请PSVector,会创建一个维度为dim,容量为capacity,类型为Double的VectorPool,同一个VectorPool内的两个PSVector可以做运算,通过PSVector.duplicate(psVector)申请一个与psVector在同一个VectorPool的PSVector。
- PSMatrix:PSMatrix的创建和销毁,通过PSMatrix.dense(rows: Int, cols:Int)创建,当PSMatrix不再使用后,需要手动调用destory销毁该Matrix
- 启动SparkSession
- 启动PSCont
- 申请PSVector/PSMatrix
- 执行算法逻辑
- 终止PSContext和SparkSession
- 启动PSContext
- 执行driver分配的task
- matrixId:矩阵ID
- rowType:矩阵类型,可参考RowType类
- row:矩阵行数
- blockRow:矩阵分区块行数
- col:矩阵列数
- blockCol:矩阵分区块列数
- matrixName:矩阵名字
- formatClassName:矩阵存储格式
- options:其他矩阵参数
- partMetas:矩阵分区索引
- startRow:分区起始行行号
- endRow:分区结束行行号
- startCol:分区起始列列号
- endCol:分区结束列列号
- nnz:分区非零元素个数
- fileName:分区数据所在文件名
- offset:分区数据在文件中的位置
- length:分区数据长度(字节数)
- saveRowNum: 分区中保存的行数
- saveColNum:分区中保存的列数(只在列主序格式中有用)
- saveColElemNum:每一列保存的元素个数(只在列主序格式中有用)
- rowMetas:分区行索引
- rowId:行号
- offset:行数据在文件中的位置
- elementNum:该行包含的元素个数
- saveType:该行保存的文件格式
- ValueBinaryRowFormat:二进制格式,只包含模型的值,只适合单行稠密的模型,数据文件中没有列号(特征索引),需要从模型元数据中获取索引范围, 格式:| value | value | 。。。|
- ColIdValueBinaryRowFormat:二进制格式,包含特征索引和对应的值。适合单行模型例如LR等, 格式: | index | value | index | value| 。。。|
- RowIdColIDValueBinaryRowFormat:二进制格式,包含模型行号,特征索引和对应的值,可以表示多行模型,格式: | rowid | index | value | rowid | index | value | … |
- ValueTextRowFormat:文本格式,只包含模型的值,每个值是一个单独的行,与ValueBinaryRowFormat类似,只适合单行稠密的模型,数据文件中没有列号(特征索引),需要从模型元数据中获取索引范围,格式:value\\n value\\n value\\n 。。。。
- ColIdValueTextRowFormat:文本格式,包含特征索引和对应的值,每一行是一个特征id和值的对,特征id和值之间的分隔符默认是逗号。适合单行模型,如LR等, 格式: index,value\\n index,value\\n index,value\\n …..
- RowIdColIdValueTextRowFormat: 文本格式,包含行号,特征索引和对应的值,每一行是一个行号,特征id和值的三元组。行号,特征id和值之间以逗号分隔,可以表示 多行模型 格式:rowid,index,value\\n rowid,index,value\\n rowid,index,value\\n …..
- BinaryColumnFormat:二进制格式,以列主序输出一个矩阵,目前只用于embedding相关的输出(例如DNN,FM等算法中的embedding层)。模型格式为:| index | row1 value | row2 value | ….. | index | row1 value | row2 value | …. |
- TextColumnFormat: 文本格式,这种格式以列主序输出矩阵,目前只用于embedding相关的输出(例如DNN,FM等算法中的embedding层),每一行是一列数据,默认逗号分隔,格式:index,row1 value, row2 value, …. \\n index, row1 value, row2 value, …. \\n index, row1 value, row2 value,...
- LR,线性回归,SVM:默认的模型保存格式为ColIdValueTextRowFormat
- GBDT:RowIdColIdValueTextRowFormat
- FM:线性部分使用的是ColIdValueTextRowFormat,Embedding层使用的TextColumnFormat
- DeepFM,DNN,Wide&Deep,PNN,NFM等:线性部分使用的是ColIdValueTextRowFormat,Embedding层使用的是TextColumnFormat,全连接部分使用的是RowIdColIdValueTextRowFormat
- ml.simpleinputlayer.matrix.output.format:SimpleInputLayer使用的输出格式
- ml.embedding.matrix.output.format:Embedding使用的输出格式
- ml.fclayer.matrix.output.format:FClayer使用的输出格式
 要注意的点:
要注意的点:
- 对于用户来说,入口类是PSModel,尽量通过它操作
- 默认的模型分区算法类RangePartitioner,但是它可以被替换
- 分区(Partition)是最小的单位,每个分区对应着PSServer上具体的Model Shard
- 尽量将一个模型平均分配到所有PS节点上
- 对于非常小的模型,将它们尽量放在一个PS节点上
- 对于多行的模型,尽量将同一行放在一个PS节点上
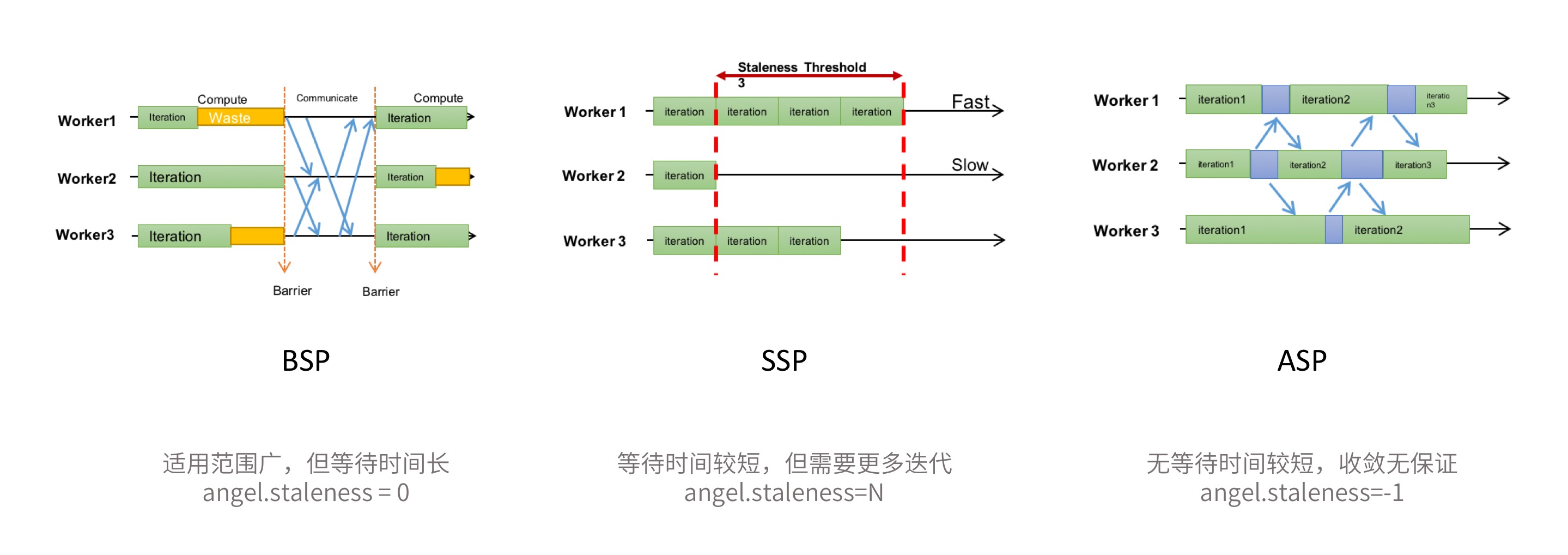 协议介绍:
1.BSP:默认的同步协议。也是一般的分布式计算采用的同步协议,每一轮迭代中都需要等待所有的task计算完成。
协议介绍:
1.BSP:默认的同步协议。也是一般的分布式计算采用的同步协议,每一轮迭代中都需要等待所有的task计算完成。
- 优点:适用范围广;每一轮迭代收敛质量高
- 缺点:但是每一轮迭代都需要等待最慢的task,整体任务计算时间长。
- 使用方式:默认的同步协议
- 优点:一定程度减少了task之间的等待时间,计算速度较快
- 缺点:每一轮迭代的收敛质量不如BSP,达到同样的收敛效果可能需要更多轮的迭代,适用性也不如BSP,部分算法不适用
- 使用方式:配置参数angel.staleness=N, 其中N为正整数
- 优点:消除了等待慢task的时间,计算速度快
- 缺点:适用性差,在一些情况下并不能保证收敛性
- 使用方式:配置参数angel.staleness=-1
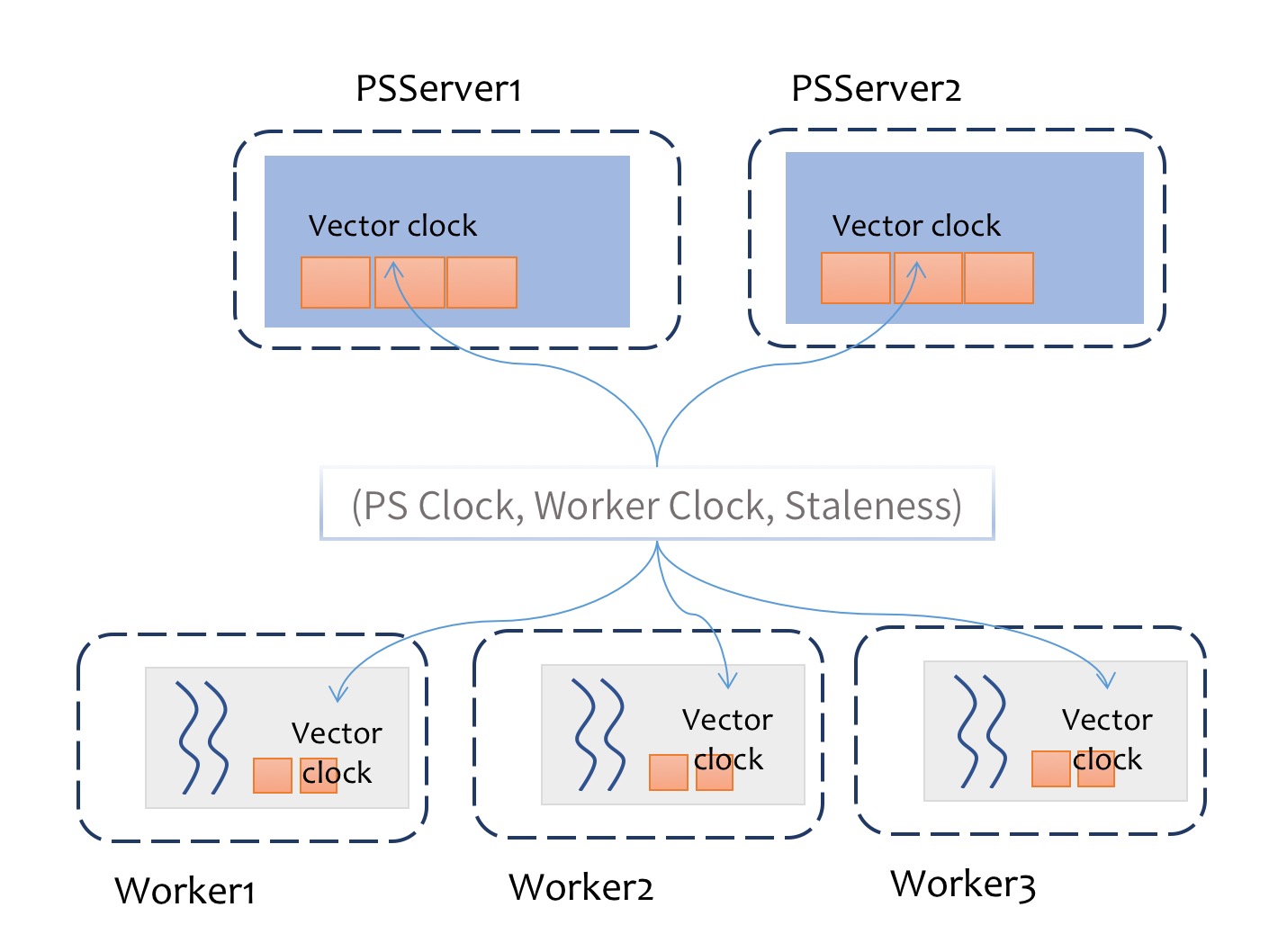 步骤如下:
步骤如下:
- 在server端为每个分区维护一个向量时钟,记录每个worker在该分区的时钟信息
- 在worker端维护一个后台同步线程,用于同步所有分区的时钟信息
- task在对PSModel进行get或其他读取操作时,根据本地时钟信息和staleness进行判断,选择是否进行等待操作
- 每次迭代完,算法调用PSModel的Clock方法,更新向量时钟
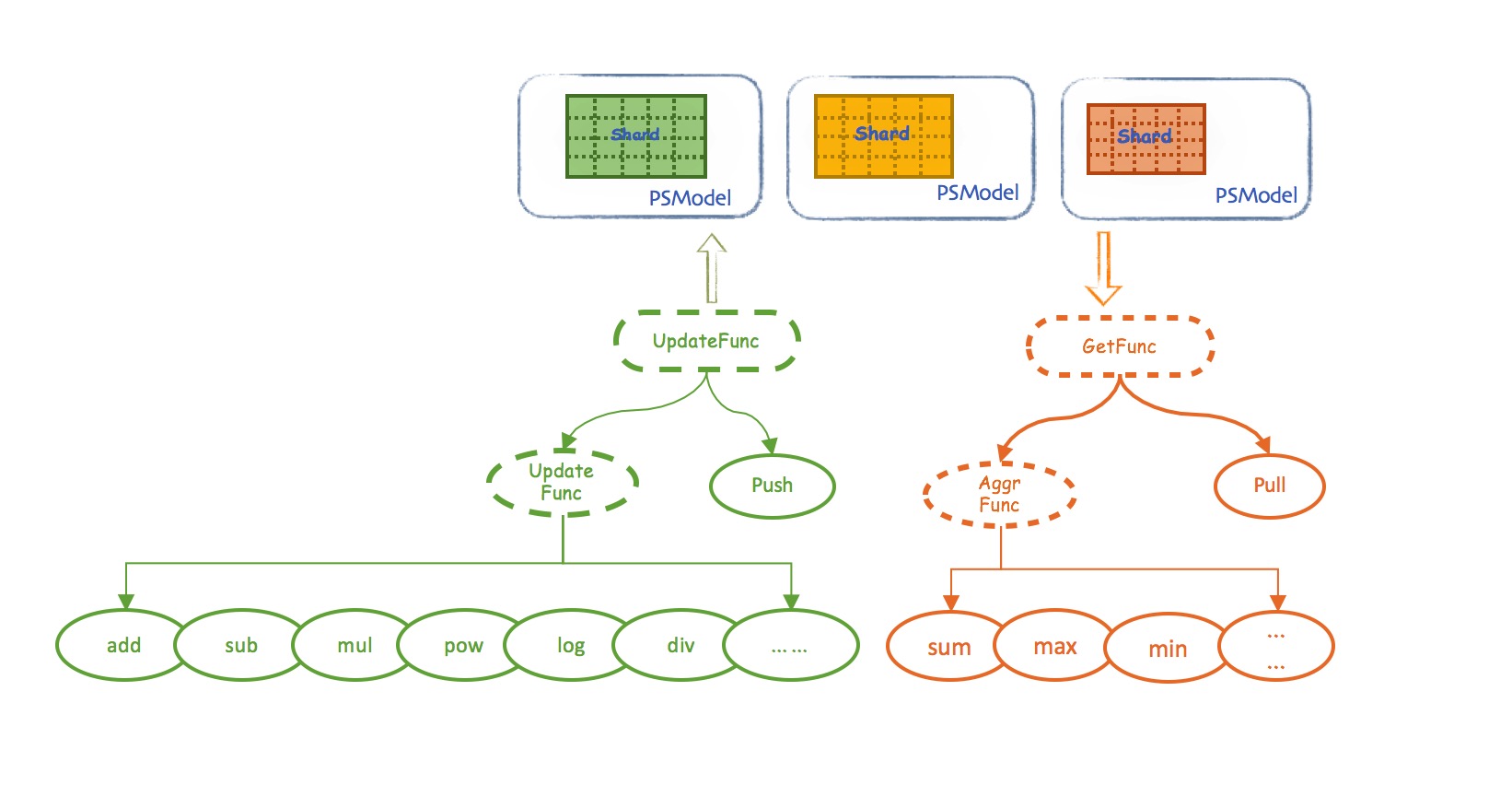 随着psFunc的引入,模型的计算,也会发生在PSServer端,PSServer也有一定的模型计算职责,而不是单纯的模型存储功能。合理的设计psFunc,可以大大加速算法的运行。
随着psFunc的引入和强化,在很多复杂的算法实现中,降低了worker要把模型完整的拖回来进行整体计算的可能性,从而间接地实现了
模型并行。
分类
angel的psFunc分成两大类,一类是获取型,一类是更新型
随着psFunc的引入,模型的计算,也会发生在PSServer端,PSServer也有一定的模型计算职责,而不是单纯的模型存储功能。合理的设计psFunc,可以大大加速算法的运行。
随着psFunc的引入和强化,在很多复杂的算法实现中,降低了worker要把模型完整的拖回来进行整体计算的可能性,从而间接地实现了
模型并行。
分类
angel的psFunc分成两大类,一类是获取型,一类是更新型
- GetFunc(获取类函数)
- UpdateFunc(更新类函数)
- worker-to-PSServer是指worker的数据和PSServer的数据做运算。如Push、Pull,将worker本地的Vector PUSH给PS,或者将PS上的Row Pull到worker上。
- PSServer-to-PSServer是指PSServer上的Matrix内部row直接发生的运算。如Add,copy等。Add是将matrix两行数据相加,将结果保存在另外一行;Copy是将某行的内容copy到另外一行。
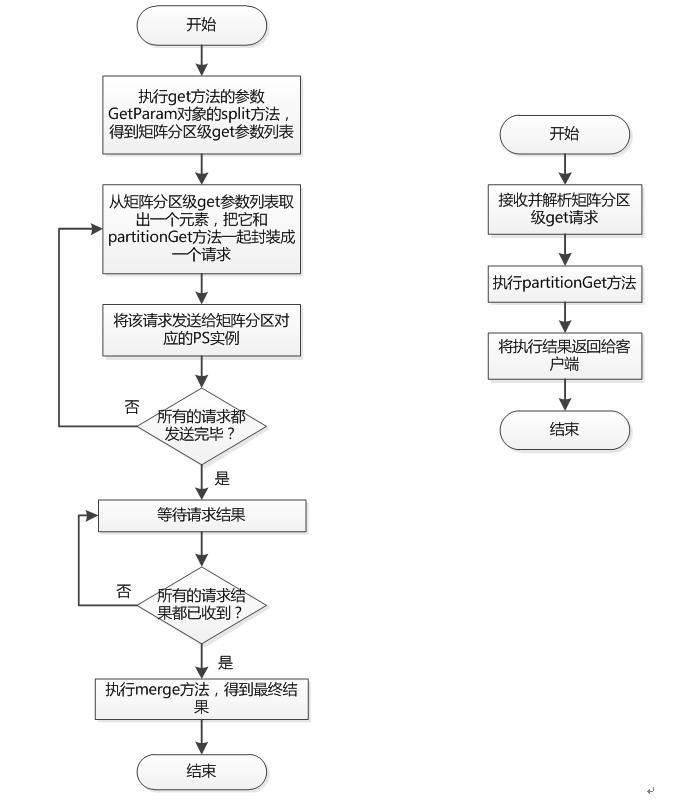
- 请求划分
- PS client(参数服务器客户端)进行请求划分,生成一个请求列表,其中每个请求都和一个模型参数分区对应
- 请求发送
- angel将请求列表中的所有请求,发送给模型参数分区所在的PS实例
- PS实例以模型参数分区为单位执行参数获取和更新操作,并返回相应的结果
- 结果合并
- 合并所有的模型分区级别结果,得到最终的结果并返回
- GetParam实现了ParamSplit接口,ParamSplit接口定义了一个split方法,该方法的含义是将一个针对整个矩阵的全局的参数划分成一个矩阵分区参数列表
- GetParam类型提供了一个默认的split接口实现,即针对该矩阵的每一个分区都生成一个矩阵分区的参数
- get psf的矩阵分区参数是一个PartitionGetParam类型
- partitionGet方法定义了从一个矩阵分区获取所需结果的具体流程,它的返回结果类型为PartitionGetResult
- merge方法定义了如何将各个矩阵分区的结果合并得到完整结果的过程,完整的结果类型为GetResult
- 参数划分和merge方法在worker端执行
- partitionGet是在PS端执行
 由于getFunc的接口太底层,建议普通用户从AggrFunc开始继承编写psFunc,这样需要cover的细节比较少
将代码编译后打成jar包,在提交任务时通过参数—angel.lib.jars上传该jar包,然后就可以在应用程序中调用了。
UpdateFunc(更新型函数)
原理
由于getFunc的接口太底层,建议普通用户从AggrFunc开始继承编写psFunc,这样需要cover的细节比较少
将代码编译后打成jar包,在提交任务时通过参数—angel.lib.jars上传该jar包,然后就可以在应用程序中调用了。
UpdateFunc(更新型函数)
原理
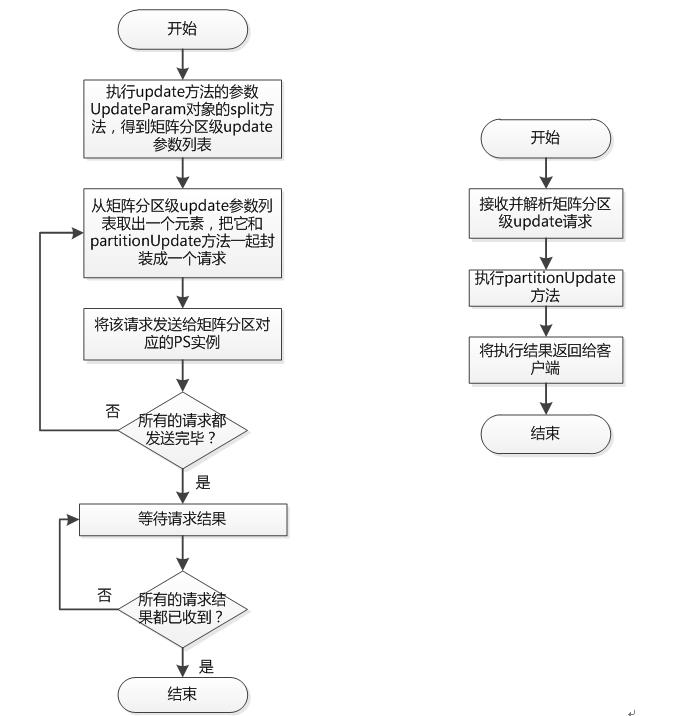
- PS client(参数服务器客户端)进行请求划分,生成一个请求列表,其中每个请求都和一个模型参数分区对应
- 将请求列表中的所有请求发送给模型参数分区所在的PS实例。PS实例以模型参数分区为单位执行参数获取和更新操作,并返回相应的结果。
- 等待所有请求完成后返回
- 即以矩阵分区为单位分别进行update操作,这个过程由partitionUpdate方法执行
- UpdateParam划分是在Worker执行
- partitionUpdate方法在PSServer端执行
 核心接口类
核心接口类
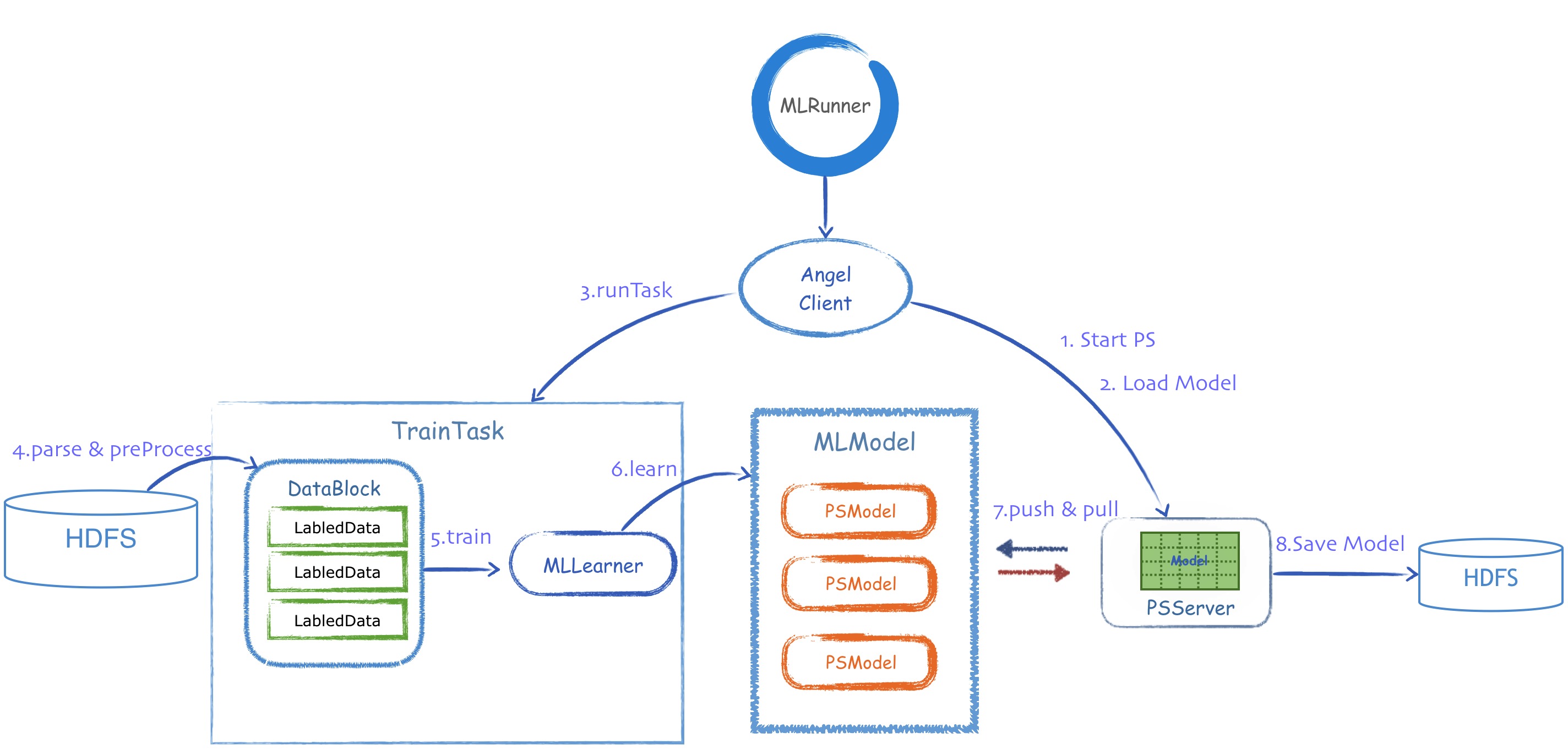 如上图所示,angel的核心接口类,在train的过程中,按照调用的流程,分为:
1、MLRunner(启动器)
如上图所示,angel的核心接口类,在train的过程中,按照调用的流程,分为:
1、MLRunner(启动器)
- MLRunner根据Conf,从工厂类,创建AngelClient,按照标准的Train流程开始依次调用AngelClient的各个接口
- 所有的算法的启动入口类,定义了启动angel任务的标准流程,封装了对AngelClient的使用
- 在angel中,启动类需要继承MLRunner,并实现train和predict两个方法
- 一般情况,应用程序直接调用它的默认实现,不必重写
- 启动PSServer
- 在PSServer上进行初始化,加载空白的模型,启动worker运行指定任务
- 训练完成后,将模型从多个PSServer,保存到HDFS
- 被Angel Client调用后,开始train过程
- 作用类似mapper和reducer,将任务封装好,传给远程的worker去分布式启动和执行
- 这两个task都是BaseTask的子类,angel会负责透明的数据切分和读取,并feed给这些task类,用户需要定义2个公共操作:
- 解析数据(parse):将单行数据解析为算法所需的数据结构(如用于LR/SVM算法的LabeledData),必须实现
- 预处理(preProcess):读取原始数据集,按行调用parse方法,将数据进行简单预处理,包括切分训练集和检验集
- task是angel的元计算类,所有的机器学习算法都要通过继承它实现训练或者预测过程,它运行于worker之内,task可以共享一个worker的某些资源
- task中,完成对数据的读取和训练两个动作,一个Task只负责它自己读取到的数据的训练
- 中间结果不落地,不对外界开放,不同的task计算时不会互相传输数据,它们都只和PSServer打交道
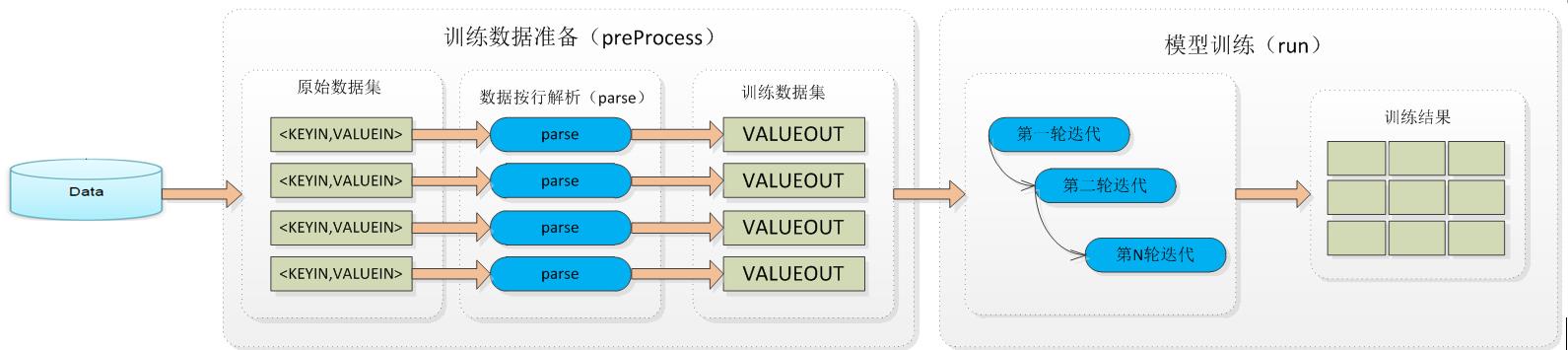 task基本流程主要有2步:
task基本流程主要有2步:
- 训练数据读取:原始的数据存在分布式文件系统之上,且格式一般不能直接被机器学习算法使用。所以angel抽象出了训练数据准备这一过程:在这个过程中,task将分布式系统上的数据拉取到本地,然后解析并转换成所需的数据结构,放入DataBlock中。这一步包括preProcess和parse
- 计算(训练or预测):对于一般的模型训练,这一步会进行多轮的迭代计算,最后输出一个模型;对于预测,数据只会被计算一次,输出预测结果。这一步一般叫run
- 数据块管理和存储的基类,提供基本的数据存取接口,适合一次写入,多次读取的场景
- 可以看做是一个可以动态增长的数组,新加入的对象只能放置在数组的末尾,它在内部维护了读写索引信息
- TrainTask调用parse和preProcess方法,将数据从HDFS中读取,并组装成多个LabeledData组成的DataBlock
- TrainTask调用Train方法,创建MLLearner对象,并将DataBlock传给MLLearner
- 模型训练的核心类,理论上,angel所有模型训练核心逻辑,都应该写在这个类中。通过这个类实现和调用,它是train的核心类
- MLLearner调用自己的Learn方法,不断读取DataBlock,计算出模型的更新,并通过MLModel中的PSModel,和PSServer进行不停的Push和Pull,最终得到一个完整的MLModel
- 根据算法的需要,创建并容纳多个PSModel,MLModel表示一个机器学习算法中,需要用到的完整模型集合,是angel所有模型的基类
- 一个复杂的机器学习算法,往往需要多个远程模型PSModel协作,需要一个类,来对这些模型进行统一操作
- 作为一个容器类,管理具体算法中的所有PSModel,作为一个整体模型被加载,训练和保存
- 整体性的操作,包括predict,setSavePath,。。。都是统一通过MLMole进行,但算法对远程模型的具体操作,都是通过PSModel来进行的
- 封装了AngelClient中和PSServer的所有通信接口,方便MLLearner调用,也是angel的核心抽象
- 封装了远程参数服务器的Context和client细节,提供了常用的远程矩阵(Matrix)和向量(Vector)的获取和更新接口,使得算法工程师可以如同操作本地对象一样的操作参数服务器上的分布式矩阵和向量,是一个可以进行反复迭代更新的可变模型对象
- 是一个远程模型的概念,对于client来说是一个类似模型代理的类,PSModel是分布式可变的,这种可变是线程安全的。
- 通过它可以在每个worker上像操作本地模型一样操作模型,但实际上是一个均匀切分在远程多个PSServer上的分布式模型切片,所有操作透明并发
- PSModel中包含了MatrixContext,MatrixClient,TaskContext这3个核心类,可以对远程的参数服务器进行任意的操作。
- 粗粒度:angel的计算图中的节点是层(layer),而不是TensorFlow中的操作(operator)
- 特征交叉:对于推荐系统相关的算法,特征embedding后往往要通过一些交叉处理后再输入DNN,angel直接提供了这种特征交叉层
- 自动生成网络:angel可以读取json文件生成深度网络,借鉴Caffe,不编写代码就可以生成网络,减轻工作量
- status:angel计算图中的节点是有状态的,用一个状态机处理
- input:用以记录本节点/层的输入,用一个ListBuffer表示,一个层可以有多个输入层,可以多次调用addInput(layer:Layer)加入
- outputDim:在Angel中最多只能有一个输出,outputDim用于指定输出的维度
- consumer:层虽然只有一个输出,但输出节点可以被多次消费,因此用ListBuffer表示,在构件图时调用input层的addConsumer(layer : Layer)告诉输出层哪些层消费了它
- inputLayer:这类节点的输入是数据,AngelGraph中存储这类节点是方便反向计算,只要依次调用inputLayer的calBackward。在InputLayer的基类中都会调用AngelGraph的addInput方法将自己加入AngelGraph
- lossLayer:目前Angel不支持多任务学习,所以只有一个lossLayer,这类节点主要方便前向计算,只要调用它的predict或calOutput即可。由于lossLayer是linearlayer的子类,所以用户自定义lossLayer可手动调用setOutput(layer: LossLayer),但用户新增lossLayer的机会不多,更多的是增加lossfunc
- 特征,特征维度,标签,batchsize,特征索引
- Null:初始状态,每次feedData后都会将Graph置于这一状态
- Forward:这一状态表示前向计算已完成
- Backward:表示后向计算已完成,但还没计算参数的梯度
- Gradient:表示梯度已经计算完成,并且梯度已经推送到PS上了
- Update:表示模型更新已经完成
 状态机的引入主要是为了保证计算的顺序进行,减少重复计算,例如有多个层消费同一层的输出,在计算时,可以根据状态进行判断,只要计算一次。
Angel中Graph的训练过程
步骤如下:
状态机的引入主要是为了保证计算的顺序进行,减少重复计算,例如有多个层消费同一层的输出,在计算时,可以根据状态进行判断,只要计算一次。
Angel中Graph的训练过程
步骤如下:
- feedData:这个过程会将Graph的状态设为Null
- 拉取参数:会根据数据,只拉取当前mini-batch计算所需要的参数,所以angel可以训练非常高维的模型
- 前向计算:从LossLayer开始,级联地调用它的inputLayer的calOutput方法,依次计算output,计算完后将它的状态设为forward。对于状态已是forward的情况,则直接返回上一次计算的结果,避免重复计算
- 后向计算:依次调用Graph的inputLayer,级联调用第一层的CalGradOutput方法,完成后向计算。计算完成后将它的状态设为backward。对于状态已经backward的情况,则直接返回上一次计算的结果,避免重复计算
- 梯度计算与更新:计算backward只计算了网络节点的梯度,并没有计算参数的梯度。这一步计算参数的梯度,只需调用trainable的pushGradient即可。这个方法会先计算梯度,再讲梯度推送到PS上,最后将状态设为gradient
- 梯度更新:梯度更新在PS上进行,只要发送一个梯度更新的PSF即可,因此只需一个worker发送(Spark on Angel中是通过Driver发送)。不同的优化器的更新方式不一样,在angel中,优化器的核心本质是一个PSF。参数更新前要做一次同步,保证所有的梯度都推送完成,参数更新完成也要做一次同步,保证所有worker拉取的参数是最新的,参数更新完成后状态被设成update
- verge:边缘节点,只有输入或输出的层,如输入层与损失层,输入层主要由SimpleInputLayer,embedding,损失层主要是SimpleLossLayer,SoftmaxLossLayer
- linear:有且仅有一个输入与一个输出的层,主要由全连接层(FCLayer),各种特征交叉层
- join:有两个或多个输入,一个输出的层,主要有ConcatLayer,SumPooling,MulPooling,DotPooling
- SimpleInputLayer
- Embedding
- ConcatLayer:将多个输入层拼接起来,输入一个Dense矩阵
- SumPooling:将输入元素对应相加后输出
- MulPooling:将输入元素对应相乘后输出
- DotPooling:先将对应元素相乘,然后按行相加,输出n行一列的矩阵
- 每个layer都有一个名称(name)和一个类型(type),name是layer的唯一标识不能重复,type是layer的类型,实际就是Layer对应的类名
- 除了输入层(DenseInputLayer,SparseInputLayer,Embedding)外,linear或loss层要指定“inputLayer”参数,值是输入层的name,对于join layer有多个输入,用“inputlayers”一个列表指定,值是输入层的name
- 除Loss层外,其他层都有输出,但angel中不用显式指出,因为指定了输入关系就同时指定了输出关系,但要显式指定输出维度outputdim
- 对于trainable层,由于它有参数,所以可以指定优化器,以“optimizer”为key,值与“default_optimizer”一样
- 对于某些层,如DenseInputLayer,SparseInputLayer,FCLayer还可以有激活函数,以“transfunc”为key,值与“default_transfunc”一样
- 对于loss层,需要“lossfunc”指定损失函数
以上是关于sona:Spark on Angel大规模分布式机器学习平台介绍的主要内容,如果未能解决你的问题,请参考以下文章