Spring项目中如何接入Open AI?
Posted 叶 秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring项目中如何接入Open AI?相关的知识,希望对你有一定的参考价值。
前言
最近随着ChatGPT的爆火,很多人都坐不住了,OpenAI API 允许开发人员访问该模型并在其自己的应用程序中使用。那么它能给我们我们Java开发带来那些好处呢?又该怎么接入Open AI呢?
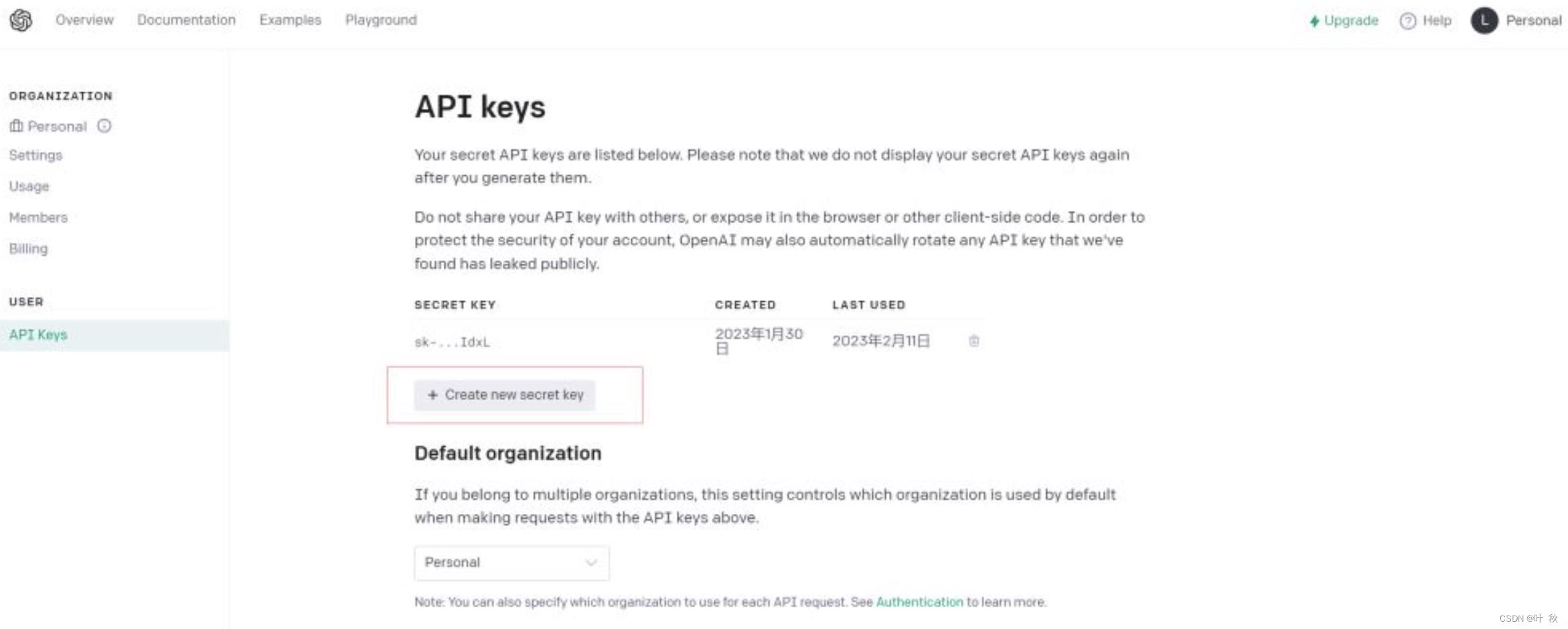
在开始之前,我们需要在 OpenAI 网站 https://beta.openai.com/account/api-keys 上注册 API 密钥。只有拥有了 API 密钥,我们才可以开始向 API 发送请求。
注意:这里的API KEYS创建好以后一定要妥善保存,创建以后,第二次就无法再查看了,想要再看,只能删除了API KEYS然后重新创建。
Java中如何调用ChatGPT
既然ChatGPT这么智能,那么我们可以问它自己,Java该如何调用ChatGPT?如图所示:

从图中可以看出,OpenAI回答的很笼统,并不是程序员们所想要的,那么换一种方式问可以看到:
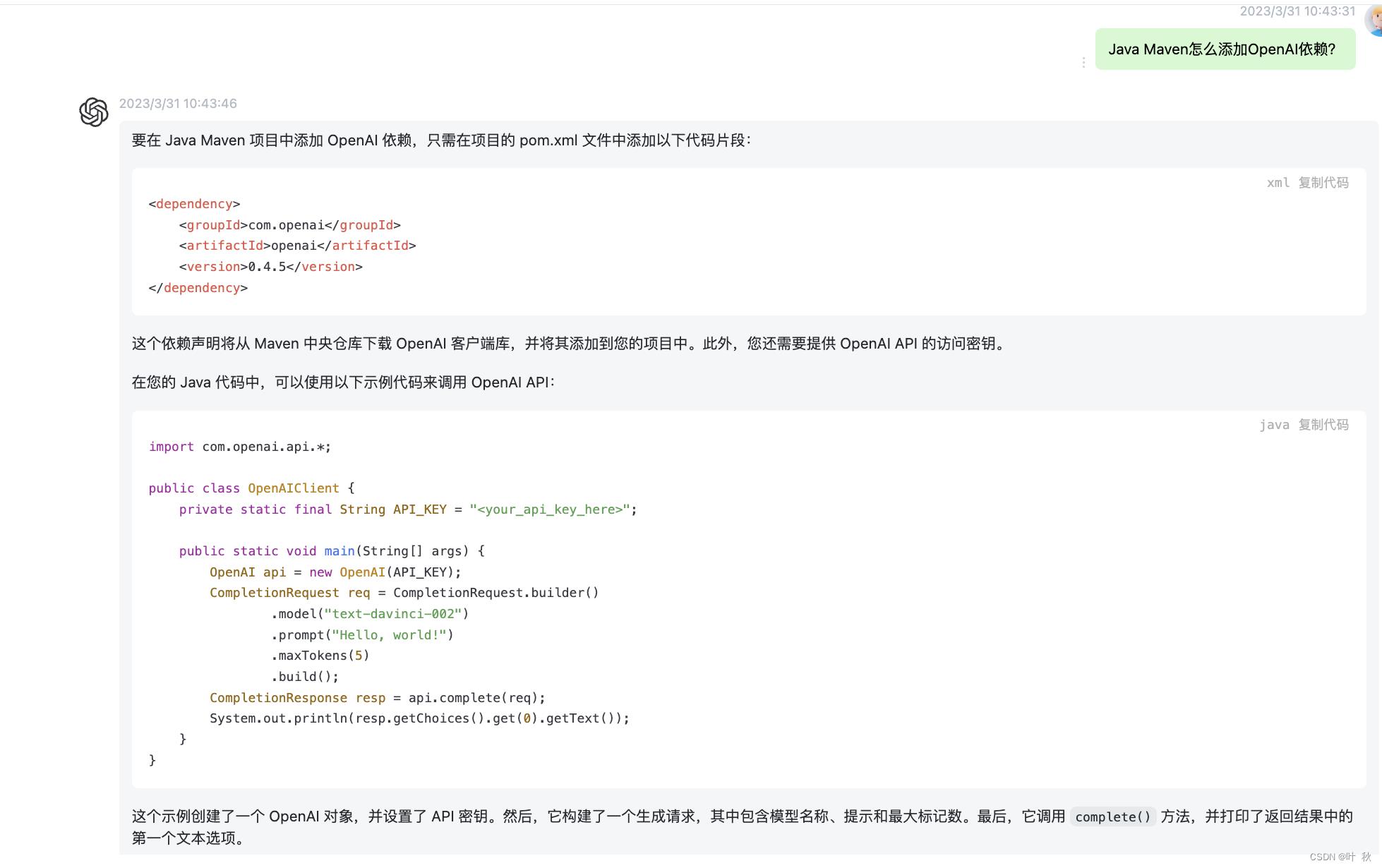
可以看出,是因为我们第一次问的过于笼统了,针对具体的需求,还是回答的很棒的。
那么我们根据它的答案来进行实操,看看是否有问题。
代码如下:
添加依赖和调用OpenAI API
<dependency>
<groupId>com.openai</groupId>
<artifactId>openai</artifactId>
<version>0.4.5</version>
</dependency>
import com.openai.api.*;
public class OpenAIClient
private static final String API_KEY = "<your_api_key_here>";
public static void main(String[] args)
OpenAI api = new OpenAI(API_KEY);
CompletionRequest req = CompletionRequest.builder()
.model("text-davinci-002")
.prompt("Hello, world!")
.maxTokens(5)
.build();
CompletionResponse resp = api.complete(req);
System.out.println(resp.getChoices().get(0).getText());
修改配置文件
在application.yml文件中配置chatgpt相关参数:
chatgpt:
model: text-davinci-003
token: sk-xxxxxxxxxxxxxxxxxxx
retries: 10
这里的model是选择chatgpt哪个模型,默认填好的是最优的模型了。
token就是上面申请的API KEYS。
retries指的是当chatgpt第一次请求回答失败时,重新请求的次数(增加该参数的原因是因为大量访问的原因,在某一个时刻,chatgpt服务将处于无法访问的情况)
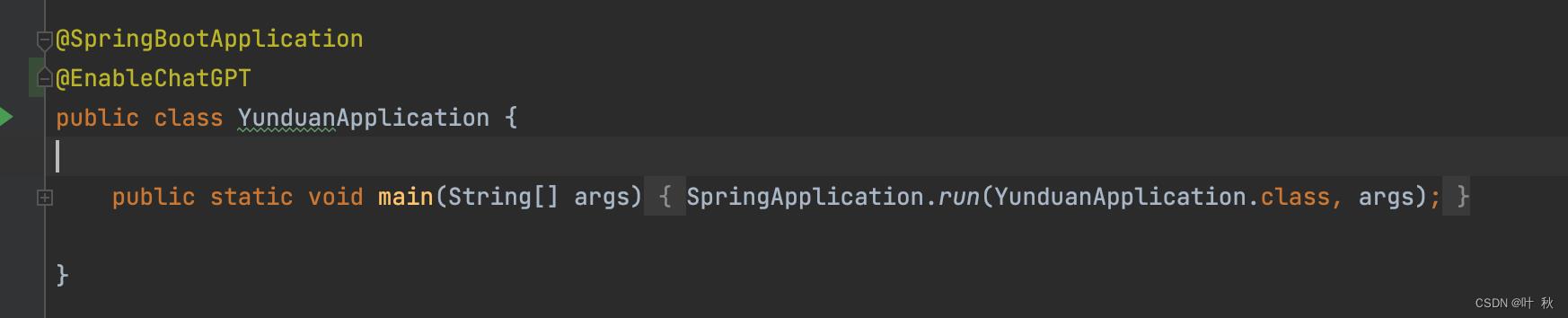
将ChatGPT服务注入到Spring中
启动类上加入 @EnableChatGPT 注解则将ChatGPT服务注入到Spring中。
@SpringBootApplication
@EnableChatGPT
public class YunduanApplication
public static void main(String[] args)
SpringApplication.run(YunduanApplication.class, args);
ChatGPT测试
关于测试代码,我们就来问问chatGPT如何回答:

import org.junit.Test;
import static org.junit.Assert.assertEquals;
import com.openai.api.*;
public class ChatGptTest
private static final String API_KEY = "<your_api_key_here>";
@Test
public void testChatGpt()
OpenAI api = new OpenAI(API_KEY);
CompletionRequest req = CompletionRequest.builder()
.model("text-davinci-002")
.prompt("Hello, world!")
.maxTokens(5)
.build();
CompletionResponse resp = api.complete(req);
assertEquals("Hi there!", resp.getChoices().get(0).getText());
在运行该测试之前,请将 API_KEY 替换为您的 OpenAI API 密钥。
如有需要体验ChatGPT链接的,点赞收藏+关注,即可私信博主哦~免费体验ChatGPT 🤗
传统Java Web(非Spring Boot)非Java语言项目接入Spring Cloud方案
技术架构在向spring Cloud转型时,一定会有一些年代较久远的项目,代码已变成天书,这时就希望能在不大规模重构的前提下将这些传统应用接入到Spring Cloud架构体系中作为一个服务以供其它项目调用。我们需要使用原生的Eureka/Ribbon手动完成注册中心、查询服务列表功能。如果是非Java项目,可以使用 Spring Sidecar 项目接入Spring Cloud形成异构系统。
JDK版本的选择
强烈建议使用JDK8, 因为Eureka Client的最新版本已经要求JDK8起了,JDK8以下的版本会出现No such method运行时错误。如果不能使用JDK8, 可以选择较早版本的eureka client, 但最低也只能支持到JDK7。对于老项目来说,在不动代码的前提下升级JDK不会有太大的风险,除非你使用了JDK特定版本的功能。风险最大的其实是升级开发框架(如Spring3到Spring4)。
服务列表查询
非Spring Cloud要调用Cloud体系内的服务接口,核心问题就是如何获取到目标服务地址。我们可以直接使用原生的eureka, ribbon库实现这一功能:
package com.dfs.pos.gateway.cloud; import java.io.IOException; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class ServiceAddressSelector { /** * 默认的ribbon配置文件名, 该文件需要放在classpath目录下 */ public static final String RIBBON_CONFIG_FILE_NAME = "ribbon.properties"; private static final Logger log = LoggerFactory.getLogger(ServiceAddressSelector.class); private static RoundRobinRule chooseRule = new RoundRobinRule(); static { log.info("开始初始化ribbon"); try { // 加载ribbon配置文件 ConfigurationManager.loadPropertiesFromResources(RIBBON_CONFIG_FILE_NAME); } catch (IOException e) { e.printStackTrace(); log.error("ribbon初始化失败"); throw new IllegalStateException("ribbon初始化失败"); } // 初始化Eureka Client DiscoveryManager.getInstance().initComponent(new MyDataCenterInstanceConfig(), new DefaultEurekaClientConfig()); log.info("ribbon初始化完成"); } /** * 根据轮询策略选择一个地址 * * @param clientName * ribbon.properties配置文件中配置项的前缀名, 如myclient * @return null表示该服务当前没有可用地址 */ public static AlanServiceAddress selectOne(String clientName) { // ClientFactory.getNamedLoadBalancer会缓存结果, 所以不用担心它每次都会向eureka发起查询 DynamicServerListLoadBalancer lb = (DynamicServerListLoadBalancer) ClientFactory .getNamedLoadBalancer(clientName); Server selected = chooseRule.choose(lb, null); if (null == selected) { log.warn("服务{}没有可用地址", clientName); return null; } log.debug("服务{}选择结果:{}", clientName, selected); return new AlanServiceAddress(selected.getPort(), selected.getHost()); } /** * 选出该服务所有可用地址 * * @param clientName * @return */ public static List<AlanServiceAddress> selectAvailableServers(String clientName) { DynamicServerListLoadBalancer lb = (DynamicServerListLoadBalancer) ClientFactory .getNamedLoadBalancer(clientName); List<Server> serverList = lb.getReachableServers(); if (serverList.isEmpty()) { log.warn("服务{}没有可用地址", clientName); return Collections.emptyList(); } log.debug("服务{}所有选择结果:{}", clientName, serverList); return serverList.stream().map(server -> new AlanServiceAddress(server.getPort(), server.getHost())) .collect(Collectors.toList()); } }
使用方法很简单:
// 选择出myclient对应服务全部可用地址 List<AlanServiceAddress> list = AlanServiceAddressSelector.selectAvailableServers("myclient"); System.out.println(list); // 选择出myclient对应服务的一个可用地址(轮询), 返回null表示服务当前没有可用地址 AlanServiceAddress addr = AlanServiceAddressSelector.selectOne("myclient"); System.out.println(addr);
这样就获取到了目标服务的URL,然后可以通过Http Client之类的方式发送HTTP请求完成调用。当然这样远没有Spring Cloud体系中使用Feign组件来的方便,但是对于代码已经变成天书的老项目来说这不算什么了。
上面这个类工作的前提是提供ribbon.properties文件,该文件指定了eureka地址和服务名相关信息:
# myclient对应的微服务名 myclient.ribbon.DeploymentContextBasedVipAddresses=S3 # 固定写法,myclient使用的ribbon负载均衡器 myclient.ribbon.NIWSServerListClassName=com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerList # 每分钟更新myclient对应服务的可用地址列表 myclient.ribbon.ServerListRefreshInterval=60000 # 控制是否注册自身到eureka中 eureka.registration.enabled=false # eureka相关配置 eureka.preferSameZone=true eureka.shouldUseDns=false eureka.serviceUrl.default=http://x.x.x.x:8761/eureka eureka.decoderName=JacksonJson
另外,DiscoveryManager.getInstance().initComponent()方法已经被标记为@Deprecated了,但是ribbon的DiscoveryEnabledNIWSServerList组件代码中依然是通过DiscoveryManager来获取EurekaClient对象的:
DiscoveryClient discoveryClient = DiscoveryManager.getInstance()
.getDiscoveryClient();
因此这里只能用过时方法,否则ribbon获取不到Eureka Client,程序跑不通。
使用原生Feign调用HTTP接口
如果你的老项目有幸可以使用Feign, 那就能大大简化HTTP调用流程。我们可以使用原生Feign代替Http Client。先定义Feign接口:
public interface ClientIdRemoteService { @RequestLine("POST /client/query") @Headers("Content-Type: application/x-www-form-urlencoded") @Body("uuid={uuid}") String getClientId(@Param("uuid") String uuid); }
下面是Spring配置类:
@Configuration public class NonCloudFeignConfig { private static final Logger log = LoggerFactory.getLogger(NonCloudFeignConfig.class); @Autowired private ObjectFactory<HttpMessageConverters> messageConverters; @Bean public ClientIdRemoteService clientIdRemoteService() { log.info("初始化获取uuid服务的Feign接口"); return Feign.builder() .encoder(new SpringEncoder(messageConverters)) .decoder(new SpringDecoder(messageConverters)) .target(ClientIdRemoteService.class, "http://xxxx.com"); } }
这时在代码中就可以通过
@Autowired private ClientIdRemoteService service; String result = service.getClientId("uuid");
的方式调用了。做异常处理的话可以自定义Feign的ErrorDecoder,然后在调用Feign.builder()的时候将你的ErrorDecoder传进去。
如果你项目的Spring版本不支持注解式配置,那么也可以通过编程的方式手动将Feign代理对象放到上下文中。
非Java应用接入Spring Cloud的技术方案
正是因为Spring Cloud Netflix架构体系中所有的服务都是通过HTTP协议来暴露自身,利用HTTP的语言无关性,我们才有了将老项目甚至非Java应用纳入到该体系中的可能。假如某个使用Node.js实现的项目想将自己变成服务供其它服务调用(或自己去调用别人的服务),可选择的方案有:
-
Spring Sidecar项目
原理是启动一个node.js对应的代理应用sidecar, sidecar本身是用spring cloud实现的,会将自身注册到eureka中,此时这个sidecar应用逻辑上就代表使用nodejs实现的服务,并且它同时也集成了ribbon, hystrix, zuul这些组件。 其他服务在调用node.js时,eureka会返回sidecar的地址,因此请求会发到sidecar,sidecar再将你的请求转发到node.js。当node.js想要调用别人的服务时,node.js需要向sidecar发请求, 由sidecar替node.js发HTTP请求,最后再将结果返回给node.js。 -
直接使用eureka的HTTP接口
由于eureka也是通过HTTP协议的接口暴露自身服务的,因此我们可以在node.js中手动发送HTTP请求实现服务的注册、查询和心跳功能。eureka接口描述信息可以在官方github的wiki中找到。
总结
通过HTTP协议的语言无关性优势,我们得到了非java应用接入Spring Cloud架构体系中的能力。但带来的其实是性能上的开销,毕竟HTTP是基于字符的协议,它的解析速度不如二进制协议。同时Spring Boot基于Tomcat和SpringMVC也是比较臃肿笨重的。但近几年Spring Boot的流行说明Java web正在向着简单化、轻量化的方向发展,说不定以后可能会彻底淘汰Servlet容器,转而使用Netty这样的通讯框架代替。
转自:http://blog.csdn.net/neosmith/article/details/70049977
以上是关于Spring项目中如何接入Open AI?的主要内容,如果未能解决你的问题,请参考以下文章