SimCLR v2算法笔记
Posted AI之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SimCLR v2算法笔记相关的知识,希望对你有一定的参考价值。
论文:Big Self-Supervised Models are Strong Semi-Supervised Learners
链接:https://arxiv.org/abs/2006.10029
这篇是发表于NIPS2020的SimCLR V2,有非常漂亮的结果。
流程是这样的(参考Figure3):先在一个无标签数据集上做自监督训练,这部分其实和SimCLR没有太大区别,就是对网络复杂度和非线性变换层做了调整,但是效果大增;然后在一个有标签的小数据集上做fine tune;最后将fine tune的模型作为teacher model做蒸馏,数据集采用的是无标签数据集。
这篇论文在一开始就放出了一个非常重要的结论,那就是在自监督训练(包括fine-tune)过程中,网络结构的复杂性对效果影响很大,具体来说网络结构越宽越深,则效果越好,尤其是当有标签的数据越少时,这种影响越明显。这部分其实在SimCLR论文中也有体现了,参考SimCLR论文中的Figure7,只不过在SimCLR V2中对这方面做了更多的实验(比如fine tune),注:SimCLR中用的网络主要是ResNet-50(4✖️),SimCLR V2中用的主要是ResNet-152(3✖️+SK),注意这个SK。
SimCLR V2引入了蒸馏,也就是将fine tune后的复杂模型当做teacher model,蒸馏到简单的student model上,这部分做法的主要初衷应该是在引入复杂网络后出于对模型效率的考虑(当然论文中也做了相同网络的蒸馏,也就是self-distilled,也能进一步提升效果),而且蒸馏本身就是Hinton老爷子的工作,所以结合起来就比较自然。另外蒸馏时候可以仅用无标签的数据(默认),或者联合使用有标签和无标签的数据,这样整个训练过程就结束了,如Figure3所示。
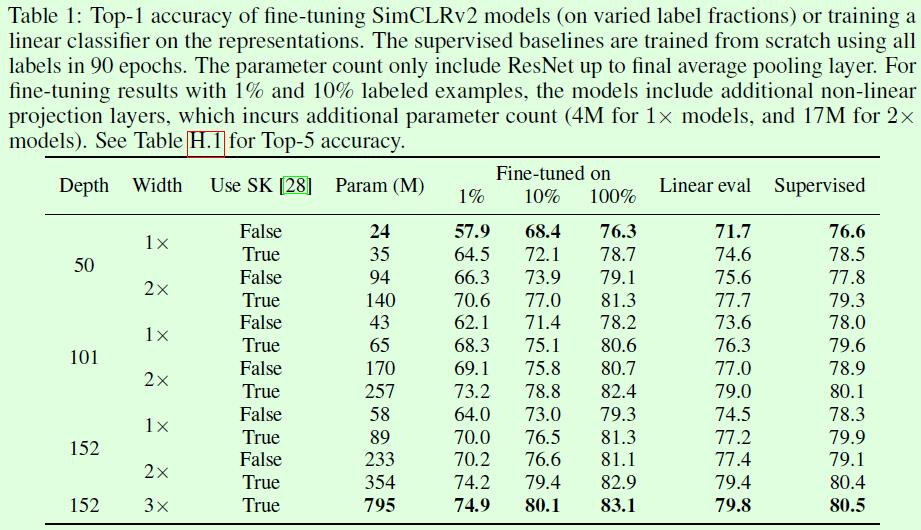
Table1很重要的一个信息就是网络深度和宽度对自监督和fine-tune阶段效果的影响还挺大的,尤其当有标签的数据较少时,这种影响更明显(参考Figure1),但是看最后一列有监督的结果可以发现这些改变对有监督训练的影响并没有那么大,或许是因为模型复杂度和数据复杂度没有对齐的原因,有监督训练中数据复杂度已经到达瓶颈了。
其次是SK,从表格来看,是否用SK对结果的影响也很大,这一点值得探究原因,至少说明在网络结构方面还有很多可探索的空间。另外还有一个点,fine-tuned on 100%这一列的效果是要普遍优于supervised的,也就是相同的数据和网络结构,不同的训练方式下,最终会相差2个点左右,这个在SimCLR论文附录的TableB.1中也有类似结果,这或许就是半监督的魅力。最后还有一个点是在有标签数据仅有1%的时候,fine tune的网络结构越复杂,却似乎没有出现明显的过拟合现象,指标上升依旧非常稳健,这一点也比较有意思,这部分如果可以给出训练阶段的指标对比就更好了。
SimCLR V2和SimCLR还有一个不同点是非线性层的数量和fine tune时候的起始层位置,这部分在论文中的Figure5有非常清晰的对比,分别是a和b。结论就是非线性层数量为3(SimCLR的非线性层数量是2),fine tune的时候从第一层开始效果最好(SimCLR在fine tune的时候是完全丢掉非线性层的)。这结果确实有点魔性,因为在有标签数据占比较少时对指标的影响还是比较大的,而且其他一些自监督算法中也能看到类似的影子,比如BYOL。
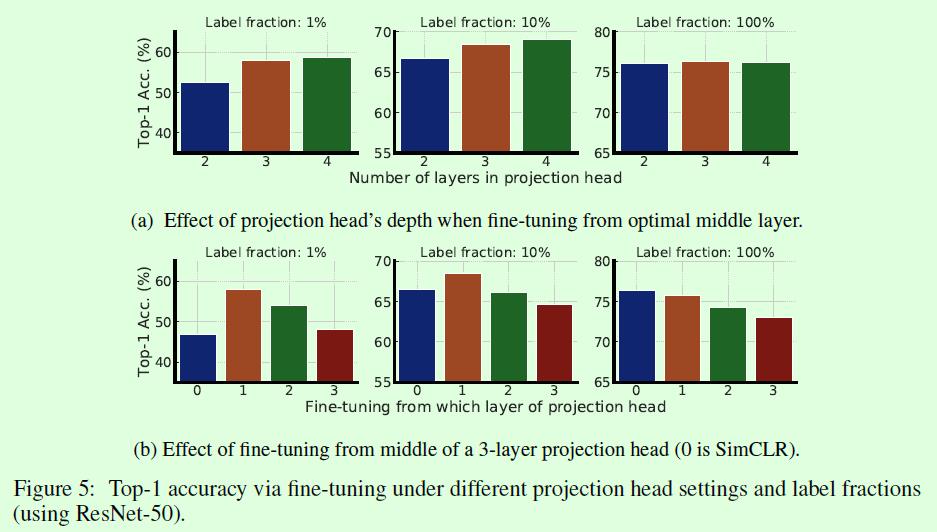
Table2是蒸馏相关的,变量包括损失函数的构成和数据集构成,损失函数部分最后默认使用蒸馏损失,而不考虑有监督的损失;数据集部分有些疑惑,论文中有些部分写的是只有无标签数据,但是这里又包含有标签数据,但其实有标签数据占比较小,所以影响应该也不大。
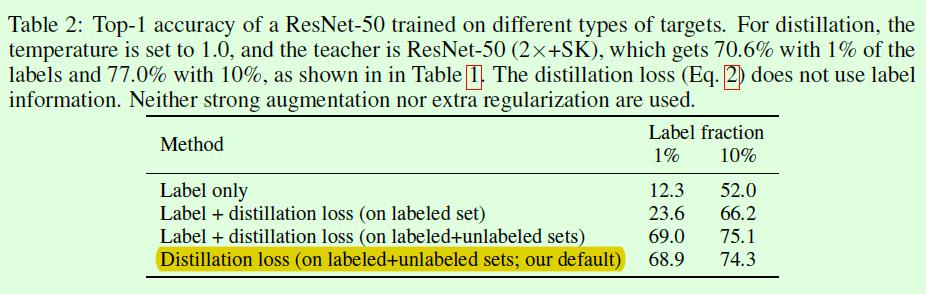
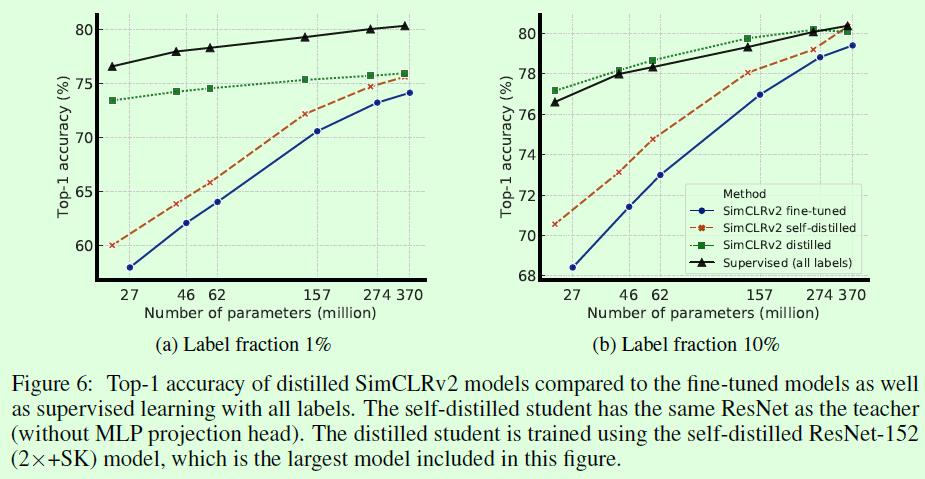
Figure6这个蒸馏相关的实验也很有借鉴意义。从图例来看,黑色线、蓝色线(参考Table1)和红色线(student和teacher一样)都比较好理解,这部分重点还是红色线和蓝色线的对比,可以看出self-distilled(学生网络和教师网络一样)可以进一步提升模型的效果,因此论文中在做常规的蒸馏(学生网络比教师网络简单)之前,会先做一次self-distilled,进一步提升教师网络的效果。绿色线的含义应该是固定了teacher是ResNet-152(2✖️+SK),如果是这样的话绿色线和红色线的最后一个点应该是重合的,从图中看好像只是差不多重合而已。
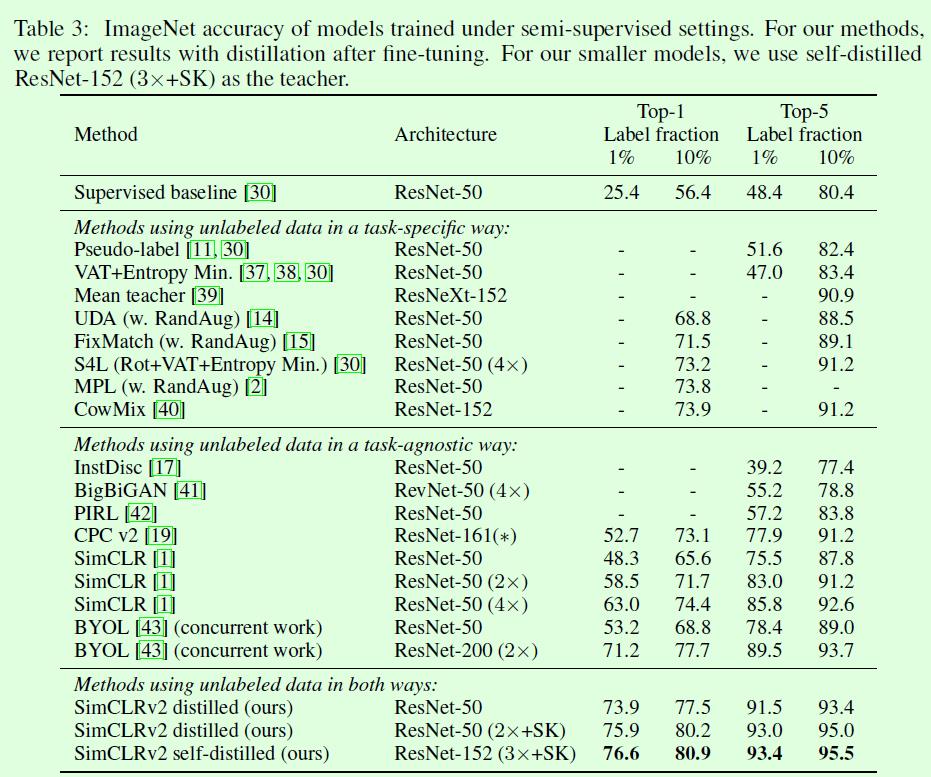
最后Table3是和现有算法的对比,最后3行的teacher model都是self-distilled的ResNet-152(3✖️+SK),可以看到仅用10%数据训的ResNet-50的效果(77.5%)已经超过了有监督的ResNet-50了(76.6%),amazing。同时从这个表格的3段式划分也可以大概窥见目前相关领域算法的大致情况,纯粹task-agnostic的算法要在指标上超过SimCLR v2还是有点困难的,所以可以在这一系列算法中添加fine tune的操作,应该会有不错的结果。而纯task-specific的论文主要还是围绕伪标签来的,整体上也有不错的结果,值得跟进。SimCLR系列算法在训练阶段都要求大batch size(复杂网络的前提下要千级别),这一点对机器资源要求比较高,应该会成为后续很多算法突破的方向。
以上是关于SimCLR v2算法笔记的主要内容,如果未能解决你的问题,请参考以下文章