OSDI 2021 PET 论文解读
Posted just_sort
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OSDI 2021 PET 论文解读相关的知识,希望对你有一定的参考价值。
今天来阅读一篇OSDI 2021的论文,《PET: Optimizing Tensor Programs with Partially Equivalent Transformations
and Automated Corrections》。
- 论文链接:https://pacman.cs.tsinghua.edu.cn/~whj/pubs/Pet.pdf
- 开源代码链接: https://github.com/thu-pacman/PET
之前也读过OSDI 2020的 《Ansor : Generating High-Performance Tensor Programs for Deep Learning》这篇论文,如果说Ansor是在更微观的角度做代码生成,那么这篇PET就可以说是在更宏观的角度做代码生成了。
无论是 Ansor 还是 PET 我个人认为都相当惊艳,我之前对 Ansor 的论文解读在这个仓库中:https://github.com/BBuf/tvm_mlir_learn 。感兴趣的小伙伴可以读一下,而本篇文章就来阅读一下 PET 。
0x1. 标题和作者

标题可以翻译为:基于部分等价变换和自动校正来优化张量化程序。作者团队来自清华,CMU和FaceBook等。这篇论文的一作王豪杰来自清华大学。后面会介绍到这篇论文在生成突变程序集合时,要维护K个效率最高的突变程序时,使用了ASO中的代价模型和评估方式,所以作者有贾志豪大神也不奇怪。
0x2. 摘要
现有的框架在图层做优化一般都是基于等价变换,也就时说变换前后的程序是完全等价的。这里等价的意思是给定相同的输入,那么变换前后的程序一定可以得到相同的输出。而这篇论文挖了一个新坑,即做了一个新的框架PET,在优化过程中允许出现部分等价的变换,并且设计了一个高效的搜索算法去组合完全等价以及部分等价的变换以探索更大的搜索空间。并且最终结果也比较好。
0x3. 介绍
这里需要先说明一个名词的含义,统计特性。统计特性的意思就是变换前后程序是完全数学等价的特性。目前TVM,以及TensorFlow,PyTorch,TensorRT等框架的变换优化或者叫 Pass 都是满足这个特性的。而部分等价变换不要求变换前后的程序保持这个统计特性,也就是允许变换后的程序和原程序在相同输入时输出的某些位置的元素是不等的。支持部分等价变换可以 (1)改变输入Tensor的shape和排列顺序以提高计算效率(2)使用效率更高的算子代替效率更低的算子(3)对图结构进行变换获得更多的高效优化机会。但要支持部分等价变换也有两个挑战。第一个就是如果直接使用部分等价变换会降低模型精度,因此有必要校正那些不等的张量区域,但是快速识别哪些区域是不等的并且产生校正Kernel是一项很难的任务并且要标注出输出的哪些位置在变换前后是不等的也是一个难题。第二个就是应用了部分等价比变换之后张量程序的搜索空间扩大了,生成候选的张量化程序的算法必须仔细管理其计算复杂度。程序优化器(后面有单独的一节讲)必须平衡部分等价变换带来的好处以及因为它引入的额外开销,并结合完全等价变换来获得高性能的张量化程序。
这篇论文提出了一个全新的部分等价变换来优化张量化程序的框架PET,PET主要由3部分组成。
- Mutation generator。突变产生器。对于一个输入张量化程序,这是用来产生部分等价变换的输出张量化程序的。每一个突变程序和输入程序在相同输入的情况下,输出Tensor的形状都是一样的,但某些区域的值可以不一样。
- Mutation corrector。突变校正器。PET的突变矫正器检查原始程序和突变程序之前等价性并自动生成校正Kernel。并将校正Kernel应用于输出张量以保证整个变换是符合统计特性的。另外PET也尽可能的融合校正Kernel和张量计算Kernel,以减少因为引入校正Kernel带来的额外开销。检查和校正部分等价变换是非常困难的,因为输出张量可能包含多达百万个元素,并且每个输出元素可能都和大量的输入元素有关。如果挨个去验证,开销会非常大。PET的一个关键贡献就是发现了一套严谨的数学理论,大大简化了这个验证过程(将这个过程的复杂度降低到了常数级别)。不是测试输出张量的所有位置,PET只需要测试几个有代表性的位置就可以完成验证。
- **Program Optimizer。**首先一个模型被切分成多个子图,然后对每个子图应用部分等价变换来获得更多的优化机会。最后在整个模型的各个子图的边界部分应用一系列后优化,包括冗余消除和算子融合等以达到整体的最佳性能。
贡献方面其实就是上面这三点,我们先提一下PET在几个模型上进行评估的性能。对于ResNet-18提升了1.2倍,对于CSRNet和BERT提升了2.5倍。
0x4. 背景和想法来源
这一节没什么好讲的,感觉和Introduction有一点重复,我们只讲讲图1,帮助大家理解什么是部分等价变换。首先图1长这样:
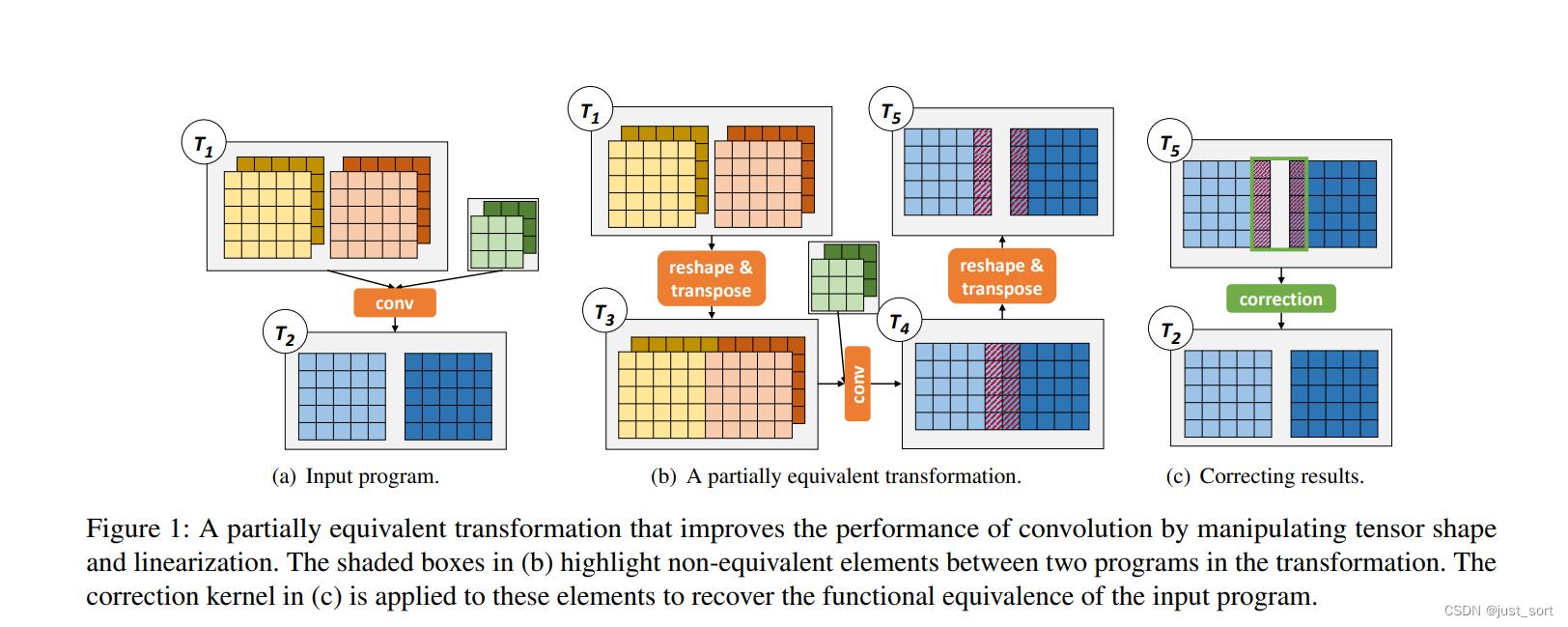
首先(a)代表一个普通的卷积操作,其中 T 1 T_1 T1是输入Tensor,它的数据排布可以记作:[b, c, h, w],即批量大小,输入通道数,输入特征图长度和宽度。然后部分等价变换也就是图(b)通过一个reshape和transpose把图中批量方向的相邻两个特征图拼起来了,也就是这样:[b, c, h, w] -> reshape -> [b / 2, 2, c, h, w] -> transpose -> [b / 2, c , h, w, 2] 。也就是图中的 T 1 − > T 3 T_1->T_3 T1−>T3 ,然后和原卷积核做卷积操作之后得到 T 4 T_4 T4,再利用reshape和transpose将输出特征图还原为原始的输入特征图大小。注意经过这个变换之后我们发现输出Tensor在边界部分存在和原始卷积的输出Tensor数值不相等的情况,所以还需要对不相等的边界部分进行校正,即©图展示的意思。
后面几节我们会详细讲解如何确定数值不相等的部分是哪些以及如何对这些数值不相等的区域进行校正,现在不理解也没关系。
0x5. 设计总览
PET是第一个利用部分等价变换去优化张量化程序的框架,它利用了张量化程序的多线性性质。这里首先要解释一下什么是Multi-linear tensor programs (MLTPs) 即多线性张量化程序,后面我们一律用MLTPs的说法。一个拥有n个输入张量 I 1 , . . . , I n I_1, ..., I_n I1,...,In的Op,如果对于每一个输入 I k I_k Ik都是线性的那么就称这个Op是多线性的:
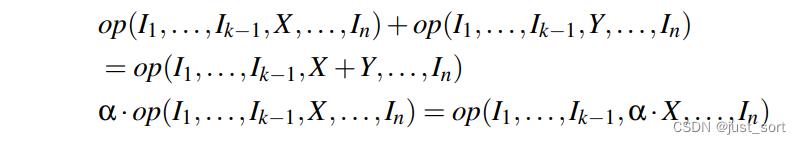
其中X和Y是具有和 I k I_k Ik相同形状的任意张量, α \\alpha α是任意标量。深度学习模型一般由线性(Conv,MatMul)和非线性(例如ReLU,Sigmoid)的算子所组成,PET框架中使用的线性算子如Table1所示:
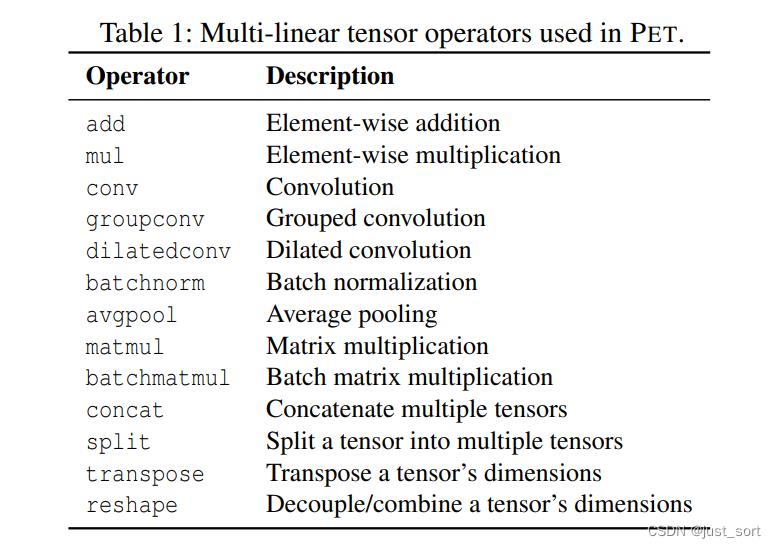
注意这个表是可以扩展的。一个程序是多线性张量化程序(MLTP)当且仅当程序中的所有的Op都是多线性的。接下来我们讲讲PET的设计总览,也就是Figure2。
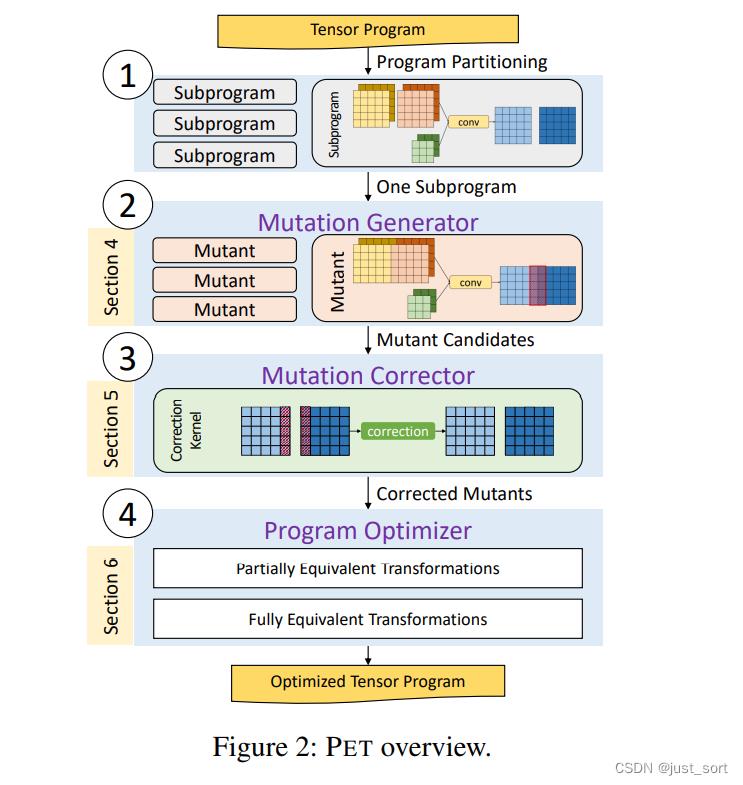
首先原始的张量化程序输入到PET框架中,然后PET首先把这个程序分解成一些小的子程序来降低每个子程序的搜索复杂度。对于每一个子程序,PET的Mutation Generator会通过为子程序的MLTPs产生可能的变体来发现部分等价变换变体程序。每个变体程序和原子程序拥有相同的输入输出Shape。为了保持端到端的数值正确性,PET的Mutation Corrector检查原始程序和突变程序有哪些区域是不等的,并自动生成校正Kernel进行校正,PET利用了严格的数学理论来简化了这个富有挑战性的任务。
校正后的突变体被发送到 PET 的程序优化器,它将现有的完全等价变换与部分等价变换结合起来,构建一个程序优化的综合搜索空间。 优化器为每个子程序评估一组丰富的突变体,并在它们的边界上应用后期优化,以便在搜索空间中发现高度优化的候选程序。
0x6. Mutation Generator
这一节主要描述了Mutation Generator的算法实现流程并描述了几种生成的典型突变模式。Mutation Generator的算法如下图所示:

首先有一个原始的多线性张量化程序MLTP P 0 P_0 P0,以及一个算子集合O。需要输出的是一个合法的突变程序集合 M M M。接下来,定义了一个 I 0 I_0 I0表示原始的MLTP中的所有输入Tensor。然后M初始化为空的集合。接下来执行BUILD这个DFS算法进行突变程序集合的生成。然后看到第8-9行也就是DFS算法的返回条件,当 P P P和 P 0 P_0 P0的输入输出形状完全相同时说明当前的突变程序是合法的,可以将这个突变程序 P P P加入到集合 M M M中。然后当n<depth,这个depth是DFS递归的深度可以继续遍历集合O中的op进行突变也即第11行,然后再遍历每一个输入Tensor i i i,如果输入Tensor i i i对于当前op来说是合法的,就将op添加到集合 P P P中然后就是DFS的常规操作了。
接下来介绍了三种典型的变体程序,我们简单介绍一下。
- Reshape + Transpose。 上面的Figure1我们已经讲解了这种变体,通过Reshape和Transpose的结合可以改变Tensor的数据排布,比如让输入特征图的宽度更大对并行计算有好处。另外reshape和transpose经常连用,所以在PET里面将这两个操作合成一个叫作 reshape & transpose 。这个融合减少了突变体的大小并允许探索更大,更复杂的突变体。
- Single-operator mutants。 PET可以将不高效的算子替换成高效的算子,比如将Dilated Conv变成普通的卷积以大大加速其计算效率。如Figure3所示:
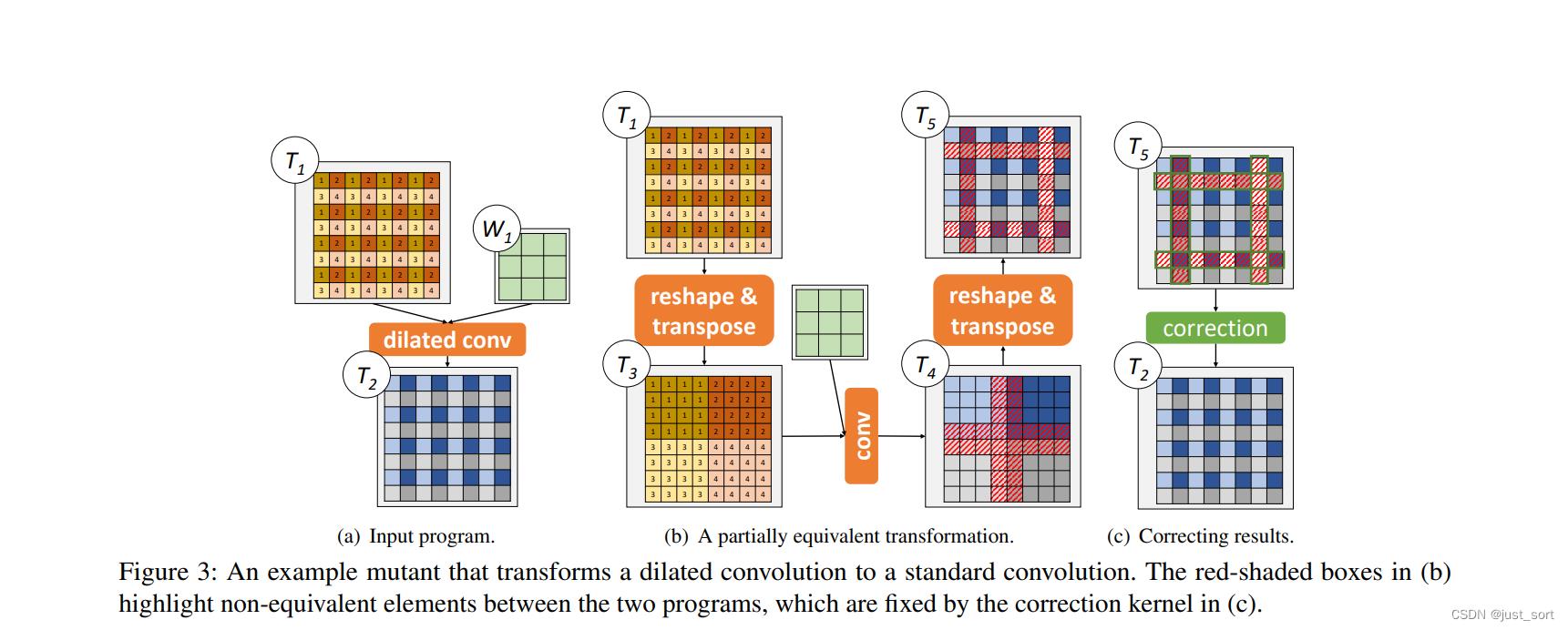
这里可以获得加速的原因是因为Dilated Conv在一些加速库中一般没有得到太大的优化,而普通的卷积则被深度优化过,所以加速效果会十分明显。注意到这里仍然有校正的过程。
- Multi-operator mutants。 这里就是将个算子集合替换为另外一个高效的算子集合。比如InceptionV3里面一些具有相似的输出形状的张量对应的算子可以被组合成一个更大的卷积以提高GPU的利用率并减少Kernel Launch的开销。
0x7. Mutation Corrector
PET中最重要的一环应该就是这个Mutation Corrector。设计突变校正器主要有两个挑战。第一:输出张量可能会非常大,可能涉及多达数百万个需要等价验证的元素。单独验证输出张量的每个元素是不可行的。第二:每个输出元素的验证可能依赖大量的输入元素比如矩阵乘算子中一个输出元素是两个输入矩阵的一行和一列的内积,两者的数量都可能达到上千。为了解决这两个挑战,PET提出了2个数学理论。
0x7.1 理论基础
我这里不完全按照论文的写作来讲,而是按照我自己的理解来讲,讲得更加通俗不那么理论化。首先我们可以看一下一个 3 × 3 3\\times 3 3×3的卷积可以由如下公式进行表示:
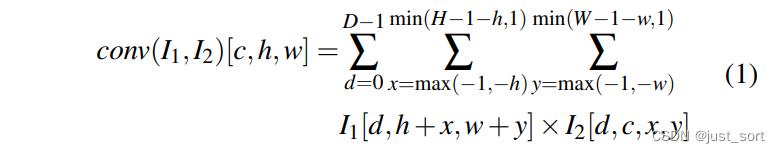
其中 I 1 I_1 I1和 I 2 I_2 I2分别表示输入Tensor和卷积Kernel,然后 D , H , W D, H, W D,H,W 分别表示输入Tensor I 1 I_1 I1通道数,长宽。求和符号上方和下方的数字分别表示求和区间的上限和下限。然后对于这个卷积的输出Tensor来讲每一个元素都对应了一个求和区域。对于上面定义的卷积算子,计算左上角的输出位置即 h = 0 , w = 0 h = 0, w = 0 h=0,w=0只涉及一个 2 × 2 2\\times 2 2×2的Kernel,即 0 < = x < = 1 , 0 < = y < = 1 0<=x<=1, 0<=y<=1 0<=x<=1,0<=y<=1,因为该位置没有左邻居或者上邻居。论文将求和区域相同的位置叫作一个Box,对于这个卷积例子来说所有的Box可以表示为Figure 4。
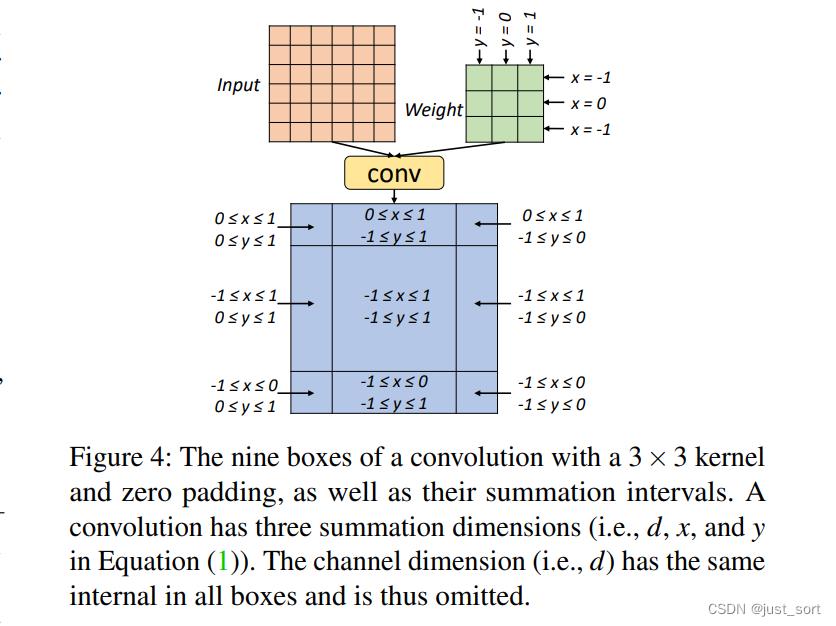
同一个Box的所有输出位置具有相同的求和区间并且共享相似的数学性质,PET在检查程序等效性时会利用这些属性。PET不需要在所有单独的位置上验证2个MLTP的等价性,只需要验证它们在每个Box的m+1个特性位置的等价性即可,其中m表示输出张量的维数 。这个定理的证明论文提到是通过对比 P 1 P_1 P1以及 P 2 P_2 P2关于输入变量的系数矩阵完成的,我们这里不关心具体的证明过程,只需要知道基于这个定理在做等效性验证时就可以避免检查所有的输出元素即可,者大大降低了校正检查的复杂度。
第二个定理的意思是如果两个拥有 n n n个输入张量的MLTPs在特定位置 v 不等效,那么在一个范围为F的分布下进行随机采样作为输入时这个位置v对这个两个MLTPs产生相同的输出值的概率是 n / p n / p n/p,其中 p p p表示F的范围,在这个论文中 p p p是一个很大的素数即 2 32 − 1 2^32-1 232−1。
有了上述两个定理,PET只需要在很少的位置进行验证就可以确定哪些位置是和原始程序不等价的了。下图展示了定理1和定理2对需要验证的输入元素数量的影响。

0x7.2 Mutation Correction算法
有了上述两个定义就可以引出Mutation Correction算法。此算法分为以下三个步骤:
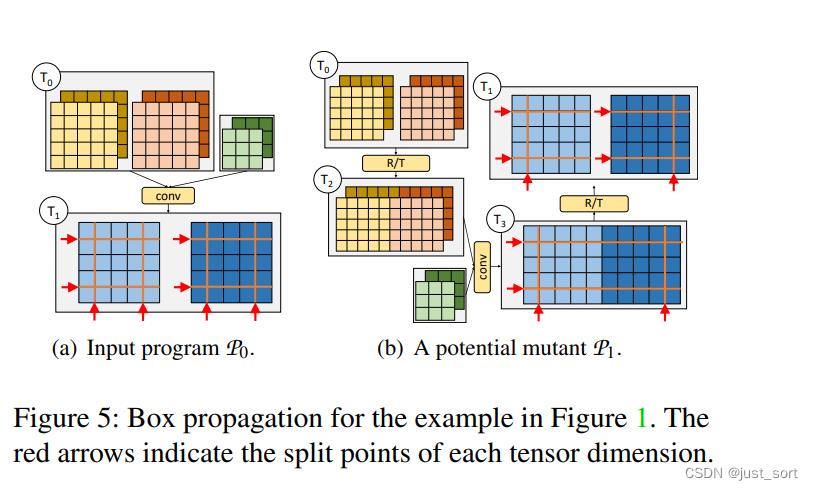
- Step 1: Box propagation。第一步通Box Propagation计算给定MLTP的值。PET为张量的每个维度维护一组分割点,以识别Box的边界。对于多线性算子,根据输入张量的分割点以及算子类型和超参数来推断输出张量的分割点,Figure5展示了Figure1中的突变例子的Box传播过程。
- Step 2: Random testing for each box pair。第二步就是对于输入MLTP P 1 P_1 P1和它的变体 P 2 P_2 P2应用上一小节介绍的定理来判断哪些区域是数值等效的。根据定理1首先要选取m+1个位置,对于Figure5中的例子m=4。然后对于m+1个位置都要基于随机数据检查 t t t次,这样误判的可能性就变成 ( n / p ) t (n/p)^t (n/p)t,其中 p = 2 32 − 1 p=2^32-1 p=232−1, t t t是一个可调的超参数用来平衡程序检查的开销和出错的可能性。
- Step 3: Correction kernel generation。最后一步就是对于所有输出Tensor数值不等的区域自动生成校正Kernel。为了减少校正Kernel的开销,PET尽可能的将校正Kernel和已有的计算Kernel融合起来。
0x7.3 融合Correction Kernels
这里就是对上面Step3的一个解释。请看Figure6:
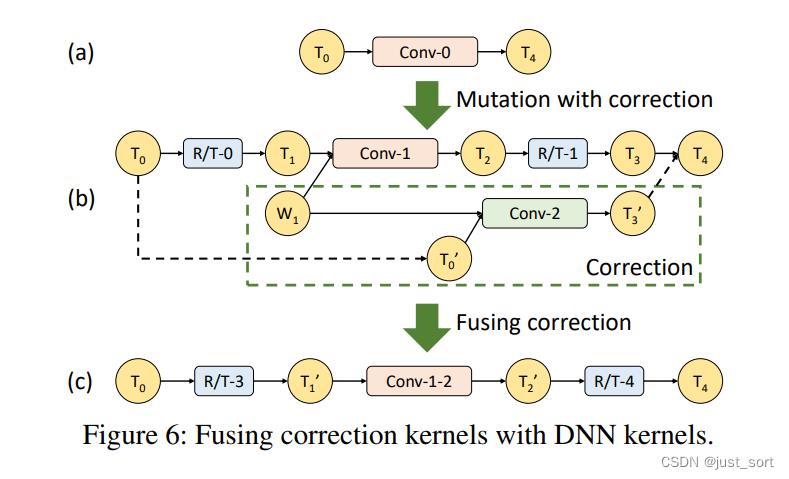
Figure6(a)表示一个标准的卷积过程。然后Figure6(b)表示在Figure6(a)上应用一个部分等效变换。Conv-2是校正Kernel,这里和Conv-1是共享权重的,所以我们可以把conv1-conv2融合起来变成一个conv-1-2,如Figire6©所示。具体来说这个融合操作就是将 T 1 T_1 T1和 T 0 ′ T_0^' T0′ 联合到一个单独的Tensor并将Conv-1-2的输出结果分解成 T 2 T^2 T2和 T 3 ′ T_3^' T3′。这里的联合和分解只包含数据拷贝,可以用reshape和transpose来做到。
0x8. Program Optimizer
这一节介绍了PET中的程序优化器,它可以通过将等效变换和部分等效变换结合起来探索一个更大的程序优化搜索空间。首先程序优化器将输入程序分解成几个更小尺寸的子程序并传给Mutation Generator。然后为了优化每个子程序,PET在一个丰富的搜索空间中通过调整参与突变的Op集合以及DFS搜索算法的迭代次数找到最好的变体程序。最后,把所有优化后的子程序缝合到一起的时候会跨边界应用额外的后优化包括算子融合,消除冗余Op等等。下面的算法2描述了程序优化器的整个流程:

整个算法流程并不复杂,首先第8行把整个程序切开,切成一些子程序。对于每一个子程序
S
S
S我们都使用GETMUTANTS函数为这个子程序产生突变程序集合记作mutants(对应第9行),然后初始化一个新的栈
H
n
e
w
H_new
Hnew。再遍历原始的栈
H
H
H,对其中的每个程序
P
P
P,基于刚才获得的突变结果
M
M
M,对
P
P
P中的子程序进行突变获得一个新的突变程序
P
n
e
w
P_new
Pnew,再把
P
n
e
w
P_new
Pnew推导新的栈
H
n
e
w
H_new
Hnew中。最后再更新原始的栈
H
H
H为
H
n
e
w
H_new
Hn 以上是关于OSDI 2021 PET 论文解读的主要内容,如果未能解决你的问题,请参考以下文章