世界500强是如何解决千亿流量留存问题的,《Ceph分布式存储架构》-使用CentOS 7部署 Ceph分布式存储架构-为他们解决什么问题。
Posted 极客事纪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了世界500强是如何解决千亿流量留存问题的,《Ceph分布式存储架构》-使用CentOS 7部署 Ceph分布式存储架构-为他们解决什么问题。相关的知识,希望对你有一定的参考价值。
文章目录
一、Ceph概述

1.1 Ceph介绍
Ceph是一个开源的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。它还是一个可靠、自动重均衡、自动恢复的分布式存储系统。主要优点是分布式存储,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡,不存在传统的单点故障的问题,可以水平扩展。
ceph官方文档 http://docs.ceph.org.cn/
ceph中文开源社区 http://ceph.org.cn/
数据大小和对应的存储介绍关系:
| 大小 | 存储介质 |
|---|---|
| 2T | 一块硬盘 |
| 10T | 一块硬盘 |
| 50T | raid0,1,5 / 存储服务器 |
假如B站有20000T数据
20000T 一台服务器不行。 一台存储服务器200T*100台服务器。 使用的技术:ceph 分布
Ceph是一个开源的分布式文件系统。因为它还支持块存储、对象存储,所以很自然的被用做云计算框架openstack或cloudstack整个存储后端。当然也可以单独作为存储,例如部署一套集群作为对象存储、SAN存储、NAS存储等。
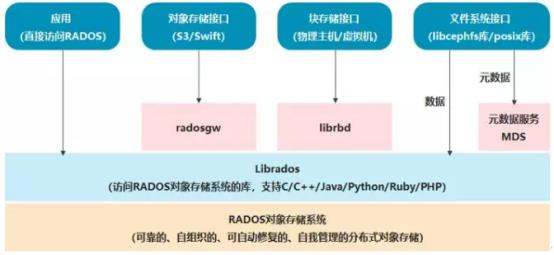
RADOS自身是一个完整的分布式对象存储系统,它具有可靠、智能、分布式等特性,Ceph的高可靠、高可拓展、高性能、高自动化都是由这一层来提供的,用户数据的存储最终也都是通过这一层来进行存储的,RADOS可以说就是Ceph的核心组件。
RADOS系统主要由两部分组成,分别是OSD和Monitor。
基于RADOS层的上一层是LIBRADOS,LIBRADOS是一个库,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言,比如C、C++、Python等。
基于LIBRADOS层开发的又可以看到有三层,分别是RADOSGW、RBD和CEPH FS。3个功能如下:
1、RADOSGW:RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。
2、RBD:RBD通过Linux内核客户端和QEMU/KVM驱动来提供一个分布式的块设备。
3、CEPH FS:CEPH FS通过Linux内核客户端和FUSE来提供一个兼容POSIX的文件系统,就像NFS一样,共享文件。
ceph支持
1、对象存储:即radosgw,兼容Swift和S3接口。通过rest api上传、下载文件。
2、块存储:即rbd。有kernel rbd和librbd两种使用方式。支持快照、克隆。相当于一块硬盘挂到本地,用法和用途和硬盘一样。
3、文件系统:posix接口。可以将ceph集群看做一个共享文件系统挂载到本地。
Ceph相比其它分布式存储有哪些优点?
1、统一存储
虽然ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口。所以在开源存储软件中,能够一统江湖。
2、高扩展性
扩容方便、容量大。能够管理上千台服务器、EB级的容量。
3、可靠性强
支持多份强一致性副本。副本能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自动管理、自动修复。无单点故障,容错性强。
4、高性能
因为是多个副本,因此在读写操作时候能够做到高度并行化。理论上,节点越多,整个集群的IOPS和吞吐量越高。另外一点ceph客户端读写数据直接与存储设备(osd) 交互。
1.2 Ceph各组件介绍
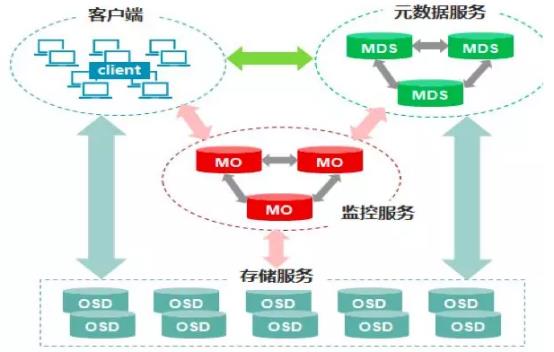
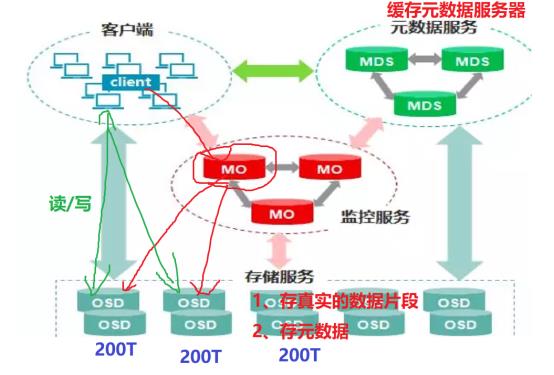
Ceph的核心组件包括Client客户端、MON监控服务、MDS元数据服务、OSD存储服务,各组件功能如下:
1、Client客户端:负责存储协议的接入,节点负载均衡。
2、MON(Monitor)监控服务:监控整个集群Cluster map的状态,维护集群的cluster MAP二进制表,保证集群数据的一致性,维护集群状态的映射,包括监视器映射,管理器映射,OSD映射,MDS映射和CRUSH映射。这些映射是Ceph守护程序相互协调所需的关键群集状态。监视器还负责管理守护程序和客户端之间的身份验证。通常至少需要三个监视器才能实现冗余和高可用性。
注:元数据:保存了子目录和子文件的名称 及inode编号的数据,通过元数据,可以找到对应的真实的数据,及真实数据所在的服务器。有点像字典前面的索引或yum源的缓存
3、MDS元数据服务(可选):是元数据的内存缓存,为了加快元数据的访问。保存了文件系统的元数据(对象里保存了子目录和子文件的名称和inode编号) ,还保存cephfs日志journal,日志是用来恢复mds里的元数据缓存 ,重启mds的时候会通过replay的方式从osd上加载之前缓存的元数据。
在ceph中,元数据是存储在osd节点中的,mds类似于元数据的内存缓存服务器,加快访问速度。
4、OSD(对象存储守护程序):主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与通过检查其他Ceph OSD守护程序的心跳来向Ceph监视器和管理器提供一些监视信息。通常至少需要3个Ceph OSD才能实现冗余和高可用性。
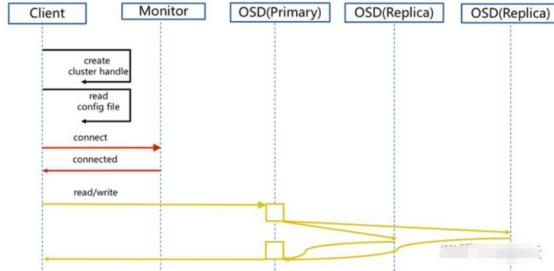
Ceph要求必须是奇数个Monitor监控节点,一般建议至少是3个(如果是自己私下测试玩玩的话,可以是1个,但是生产环境绝不建议1个)用于维护和监控整个集群的状态,每个Monitor都有一个Cluster Map,只要有这个Map,就能够清楚知道每个对象存储在什么位置了。客户端会先tcp连接到Monitor,从中获取Cluster Map,并在客户端进行计算,当知道对象的位置后,再直接与OSD通信(去中心化的思想)。OSD节点平常会向Monitor节点发送简单心跳,只有当添加、删除或者出现异常状况时,才会自动上报信息给Monitor。
MDS是可选的,只有需要使用Ceph FS的时候才需要配置MDS节点。在Ceph中,元数据也是存放在OSD中的,MDS只相当于元数据的缓存服务器。
在Ceph中,如果要写数据,只能向主OSD写,然后再由主OSD向从OSD同步地写,只有当从OSD返回结果给主OSD后,主OSD才会向客户端报告写入完成的消息。如果要读数据,不会使用读写分离,而是也需要先向主OSD发请求,以保证数据的强一致性。
专业术语缩写总结:
1、OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。
2、MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
3、PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
4、RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
5、RBD全称RADOS block device,是Ceph对外提供的块设备服务。
6、RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
7、CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
二、ceph集群部署实验
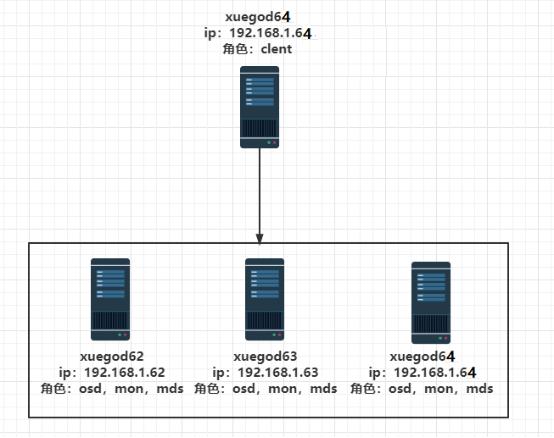
主机准备 (禁用selinux, 关闭防火墙)
xuegod63 192.168.1.63 osd,mds,mon,admin部署节点
xuegod62 192.168.1.62 osd,mds,mon
xuegod64 192.168.1.64 osd,mds,mon
xuegod64 192.168.1.64 client挂载节点,可以单独一台服务器
注:1、admin角色代表ceph部署管理节点,其他节点通过ceph部署结点进行安装。
2、xuegod62、xuegod63、xuegod64 各添加一块硬盘,每个磁盘20G。搭建ceph时会使用新加的磁盘。
编辑hosts文件(所有节点需要操作):
(规范系统主机名添加hosts文件实现集群主机名与主机名之间相互能够解析(host 文件添加主机名不要使用fqdn方式)可用hostnamectl set-hostname name设置
分别打开各节点的/etc/hosts文件,加入这四个节点ip与名称的对应关系
[root@xuegod63 ~]# vim /etc/hosts
192.168.1.63 xuegod63 xuegod63.cn
192.168.1.62 xuegod62 xuegod62.cn
192.168.1.64 xuegod64 xuegod64.cn
注:/etc/hosts中必须有xueogd63这种短域名,因为后期部署ceph时,ceph安装程序默认只使用xueogd63域名,不使用xueogd63.cn
[root@xuegod63 ~]# scp /etc/hosts root@xuegod62:/etc/
[root@xuegod63 ~]# scp /etc/hosts root@xuegod64:/etc/
SSH免密码登录(所有节点需要操作)
在管理节点使用ssh-keygen 生成ssh keys 发布到各节点
[root@xuegod63 ~]# ssh-keygen #所有的输入选项都直接回车生成。
[root@xuegod63 ~]# ssh-copy-id xuegod63
[root@xuegod63 ~]# ssh-copy-id xuegod62
[root@xuegod63 ~]# ssh-copy-id xuegod64
配置好网络源
3台主机上,都更新Centos内核,Ceph的iscsi网关组件最低需要4.16版本的linux内核。 最好离线安装
导入Public Key
[root@xuegod63 ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
[root@xuegod62 ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
[root@xuegod64 ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
安装elrepo源,通过elrepo源安装新内核
[root@xuegod63 ~]# yum install https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm -y
[root@xuegod62 ~]# yum install https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm -y
[root@xuegod64 ~]# yum install https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm -y
安装新版本内核(ml主线版本,lt长期支持版本)
[root@xuegod63 ~]# yum --enablerepo=elrepo-kernel install kernel-lt-devel kernel-lt -y
时间可能会比较长(3分钟左右)
[root@xuegod62 ~]# yum --enablerepo=elrepo-kernel install kernel-lt-devel kernel-lt -y
[root@xuegod64 ~]# yum --enablerepo=elrepo-kernel install kernel-lt-devel kernel-lt -y
查看安装的内核版本:
[root@xuegod63 yum.repos.d]# rpm -qa | grep kernel-lt
kernel-lt-5.4.127-1.el7.elrepo.x86_64
kernel-lt-devel-5.4.127-1.el7.elrepo.x86_64
配置使用新版本内核启动系统:
[root@xuegod63 ~]# grub2-set-default "kernel-lt-5.4.127-1"
[root@xuegod62 ~]# grub2-set-default "kernel-lt-5.4.127-1"
[root@xuegod64 ~]# grub2-set-default "kernel-lt-5.4.127-1"
[root@xuegod63 ~]# reboot
[root@xuegod62 ~]# reboot
[root@xuegod64 ~]# reboot
[root@xuegod63 ~]# uname -r
5.4.127-1.el7.elrepo.x86_64
同步时间:
使用互联网上提供的NTP服务,把3台主机时间保持一致(主机需要可以访问互联网)
统一安装ntp
[root@xuegod62 ~]# yum install -y ntp
[root@xuegod63 ~]# yum install -y ntp
[root@xuegod64 ~]# yum install -y ntp
指定阿里云时间服务器,进行时间同步:
[root@xuegod63 ~]# ntpdate ntp.aliyun.com
[root@xuegod62 ~]# ntpdate ntp.aliyun.com
[root@xuegod64 ~]# ntpdate ntp.aliyun.com
添加计划任务定期同步
[root@xuegod63 ~]# echo "*/30 * * * * ntpdate ntp.aliyun.com " >> /var/spool/cron/root
[root@xuegod62 ~]# crontab -l
[root@xuegod64 ~]# echo "*/30 * * * * ntpdate ntp.aliyun.com " >> /var/spool/cron/root
[root@xuegod62 ~]# echo "*/30 * * * * ntpdate ntp.aliyun.com " >> /var/spool/cron/root
2.1 配置Ceph安装源
方法1:离线安装
创建本地yum源
[root@xuegod63 ~]# rz
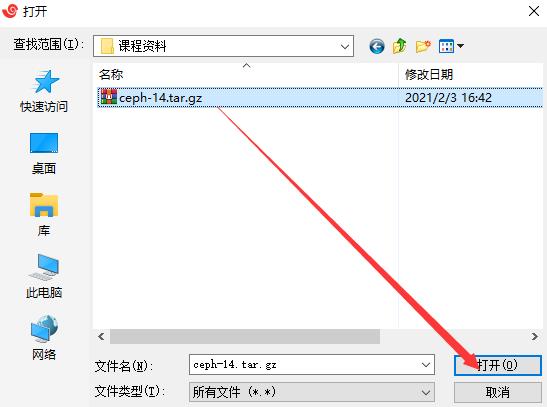
[root@xuegod63 ~]# tar xf ceph-14-v2.tar.gz -C /opt/
[root@xuegod63 ~]# tee /etc/yum.repos.d/ceph.repo << EOF
[ceph]
name=ceph
baseurl=file:///opt/ceph-14
enable=1
gpgcheck=0
EOF
复制离线yum仓库至xuegod62
[root@xuegod63 ~]# scp -r /opt/ceph-14/ root@xuegod62.cn:/opt/
[root@xuegod63 ~]# scp /etc/yum.repos.d/ceph.repo root@xuegod62.cn:/etc/yum.repos.d/
复制离线yum仓库至xuegod64
[root@xuegod63 ~]# scp -r /opt/ceph-14/ root@xuegod64.cn:/opt/
[root@xuegod63 ~]# scp /etc/yum.repos.d/ceph.repo root@xuegod64.cn:/etc/yum.repos.d/
方法2:配置在线ceph源
在线安装
[root@xuegod63 ~]# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
gpgcheck=0
priority=1
enable=1
[ceph-noarch]
name=cephnoarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
gpgcheck=0
priority=1
enable=1
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS/
gpgcheck=0
priority=1
enable=1
[root@xuegod63 ~]# scp /etc/yum.repos.d/ceph.repo root@xuegod62:/etc/yum.repos.d/
[root@xuegod63 ~]# scp /etc/yum.repos.d/ceph.repo root@xuegod64:/etc/yum.repos.d/
在线安装必须安装epel源
[root@xuegod63 ~]# yum install -y epel-release
2.2 在xuegod63上安装ceph-deploy管理工具
[root@xuegod63 ~]# yum install python-setuptools ceph-deploy -y
开始部署新的集群
[root@xuegod63 ~]# mkdir /etc/ceph && cd /etc/ceph
使用ceph-deploy new 命令快速部署3个ceph结点
[root@xuegod63 ceph]# ceph-deploy new xuegod62.cn xuegod63.cn xuegod64.cn
[root@xuegod63 ceph]# ls #在当前目录下生成,有3个节点的配置文件
ceph.conf # Ceph主配置文件; ceph-deploy-ceph.log #日志文件 ;
ceph.mon.keyring #monitor密钥
[root@xuegod63 ceph]# cat ceph.conf #查看配置文件
[global]
fsid = 31051ba5-3210-441f-ae10-be6f70859d30
mon_initial_members = xuegod62, xuegod63, xuegod64 #指定了后期要对哪些节点进行monitor初始化,注:这里写的是短域名,后期自动部署时,也会使用短域名
mon_host = 192.168.1.62,192.168.1.63,192.168.1.64 #monitor 节点IP
查看monitor密钥,后期客户端挂载ceph时,通过这个密钥来认证:
[root@xuegod63 ceph]# cat ceph.mon.keyring
[mon.]
key = AQAqgf5gAAAAABAAPJV2+TPknwAl5RY9bK6rAA==
caps mon = allow *
修改pool的副本数
pool概述:pool是ceph存储数据时的逻辑分区,它起到namespace的作用。其他分布式存储系统。每个pool包含一定数量的PG,PG里的对象被映射到不同的OSD上,因此pool是分布到整个集群的。除了隔离数据,我们也可以分别对不同的POOL设置不同的优化策略,比如副本数、数据清洗次数、数据块及对象大小等。
[root@xuegod63 ~]# vim /etc/ceph/ceph.conf #配置文件的默认副本数从3改成2,这样只有两个osd也能达到active+clean状态,把下面这行加入到[global]段(可选配置)
[global]
fsid = 31051ba5-3210-441f-ae10-be6f70859d30
mon_initial_members = xuegod62, xuegod63, xuegod64
mon_host = 192.168.1.62,192.168.1.63,192.168.1.64
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = 2
mon clock drift allowed = 0.500
mon clock drift warn backoff = 10
注:
osd_pool_default_size = 2 #设置pool的副本数为2个
mon clock drift allowed #监视器之间,允许的时钟漂移量,改为,0.5秒。默认值0.05秒
mon clock drift warn backoff #时钟偏移警告的退避指数。默认值5
ceph对每个mon之间的时间同步延时默认要求在0.05s之间,这个时间有的时候太短了。所以如果ceph集群出现clock问题,就检查ntp时间同步或者适当放宽这个误差时间。
2.3 离线安装ceph
在所有节点上安装ceph和ceph-radosgw。RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。
[root@xuegod62 ~]# yum -y install ceph ceph-radosgw
[root@xuegod63 ~]# yum -y install ceph ceph-radosgw
[root@xuegod64 ~]# yum -y install ceph ceph-radosgw
2.4 安装ceph monitor
1、安装ceph monitor
[root@xuegod63 ~]# cd /etc/ceph/
[root@xuegod63 ceph]# ceph-deploy mon create-initial #在3台节点上安装monitor。
[root@xuegod63 ceph]# ls *.keyring # keyring是各组件之间秘钥文件
注:初始化monitor成员,根据置文件中mon initial members中的monitors。进行部署,直到它们形成表决团,然后搜集keys,并且在这个过程中报告monitor的状态。

2、分发配置文件
(用ceph-deploy把配置文件和admin密钥拷贝到所有节点,这样每次执行Ceph命令行时就无需指定monitor地址和ceph.client.admin.keyring了)
[root@xuegod63 ceph]# ceph-deploy admin xuegod62.cn xuegod63.cn xuegod64.cn
将client.admin的key push到远程主机。将ceph-admin节点下的client.admin keyring push到远程主机/etc/ceph/下面。
查看复制过来的文件:
[root@xuegod62 ~]# ls /etc/ceph/
ceph.client.admin.keyring ceph.conf rbdmap tmp8xZmUE
2.5 部署osd服务
使用 create 命令一次完成准备 OSD 、部署到 OSD 节点、并激活它。
将/dev/sdb磁盘准备为OSD,并把部署到相应的OSD节点上。
[root@xuegod63 ceph]# cd /etc/ceph/ #必须在这个目录下执行
[root@xuegod63 ceph]# ceph-deploy osd create --data /dev/sdb xuegod62.cn
[root@xuegod63 ceph]# ceph-deploy osd create --data /dev/sdb xuegod63.cn
[root@xuegod63 ceph]# ceph-deploy osd create --data /dev/sdb xuegod64.cn
查看状态:
[root@xuegod63 ceph]# ceph-deploy osd list xuegod63 xuegod62 xuegod64
2.6 创建ceph文件系统
创建mds
[root@xuegod63 ceph]# ceph-deploy mds create xuegod62.cn xuegod63.cn xuegod64.cn
查看ceph当前文件系统
[root@xuegod63 ceph]# ceph fs ls

一个cephfs至少要求两个librados存储池,一个为data,一个为metadata。当配置这两个存储池时,注意:
- 为metadata pool设置较高级别的副本级别,因为metadata的损坏可能导致整个文件系统不用
- 建议,metadata pool使用低延时存储,比如SSD,因为metadata会直接影响客户端的响应速度。
创建pool存储池
pg概述:PG,Placement Group,归置组,
Placement [ˈpleɪsmənt] 安置 归置
例1: 创建名为cephfs_data,pg_num为128的pool
[root@xuegod63 ceph]# ceph osd pool create cephfs_data 128
pool 'cephfs_data' created
例2:创建名为cephfs_metadata,pg_num为128的pool
[root@xuegod63 ceph]# ceph osd pool create cephfs_metadata 128
pool 'cephfs_metadata' created
注:通常在创建pool之前,需要覆盖默认的pg_num,官方推荐:
*少于 5 个 OSD 时可把 pg_num 设置为 128
*OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
*OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
*OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
*自己计算 pg_num 取值时可借助 pgcalc 工具。
创建文件系统
创建好存储池后,你就可以用 fs new 命令创建文件系统了
[root@xuegod63 ceph]# ceph fs new xuegod cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
注:metadata pool 编号为:2 ;data pool 编号为:1
其中:new后的fsname 可自定义
[root@xuegod63 ceph]# ceph fs ls #查看创建后的cephfs
name: xuegod, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@xuegod63 ceph]# ceph mds stat #查看mds节点状态
xuegod:1 0=xuegod62.cn=up:active 2 up:standby
active是活跃的,另1个是处于热备份的状态
2.7 部署mgr监控
安装mgr用于后面我们配置dashboard监控,而且避免挂载ceph时可能会提示warring信息。
[root@xuegod63 ceph]# ceph-deploy mgr create xuegod62.cn xuegod63.cn xuegod64.cn
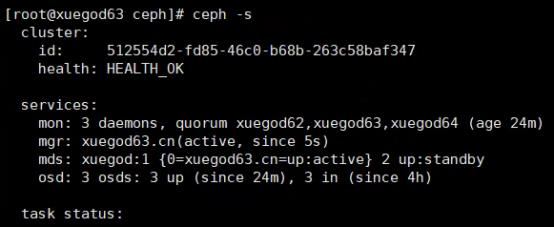
安装后查看集群状态正常
[root@xuegod63 ceph]# ceph -s
三、多种Ceph挂载方式
3.1 内核驱动挂载Ceph文件系统
1、查看存储密钥(如果没有在管理节点使用ceph-deploy拷贝ceph配置文件)
[root@xuegod63 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQDNBQFca7UYGxAA6wOfoZR4JWdP5yM56S8DeQ==
2、将key对应的值复制下来保存到客户端xueogd64的/etc/ceph/admin.secret中。如果已经有了,就不用复制了。
[root@xuegod64 ~]# vim /etc/ceph/admin.secret #写入以下内容
AQDNBQFca7UYGxAA6wOfoZR4JWdP5yM56S8DeQ==
例1:将ceph挂载到/root/test2目录下
[root@xuegod64 ceph]# mkdir /root/test2
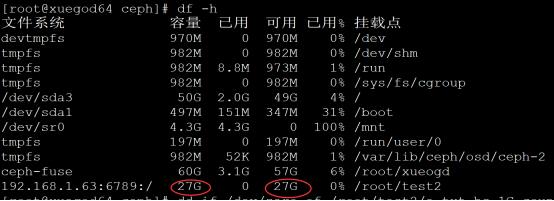
[root@xuegod64 ceph]# mount -t ceph 192.168.1.63:6789:/ /root/test2/ -o name=admin,secretfile=/etc/ceph/admin.secret
[root@xuegod64 ceph]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 970M 0 970M 0% /dev
tmpfs 982M 0 982M 0% /dev/shm
tmpfs 982M 8.8M 973M 1% /run
tmpfs 982M 0 982M 0% /sys/fs/cgroup
/dev/sda3 50G 2.0G 49G 4% /
/dev/sda1 497M 151M 347M 31% /boot
/dev/sr0 4.3G 4.3G 0 100% /mnt
tmpfs 197M 0 197M 0% /run/user/0
tmpfs 982M 52K 982M 1% /var/lib/ceph/osd/ceph-2
192.168.1.63:6789:/ 27G 0 27G 0% /root/test2
要取消挂载
[root@xuegod64 ceph]# umount /root/test2 # 先不卸载
3.2 使用ceph-fuse命令挂载Ceph文件系统
登录xuegod64,安装ceph-fuse
[root@xuegod64 ceph]# yum install -y ceph-fuse
[root@xuegod64 ceph]# mkdir /root/xueogd #必须创建一个空目录,不能直接挂载有文件的目录下
挂载
[root@xuegod64 ceph]# ceph-fuse -m 192.168.1.63:6789 /root/xueogd/

取消挂载
[root@xuegod64 ceph]# fusermount -u /root/xueogd/ #先不取消挂载
测试两种挂载,显示的存储大小为什么不一样:
没有写入数据时查看大小:
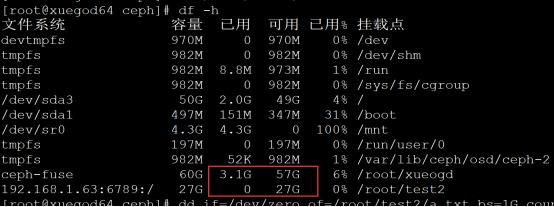
写入1G文件
[root@xuegod64 ceph]# dd if=/dev/zero of=/root/test2/a.txt bs=1G count=1
[root@xuegod64 ceph]# df -h
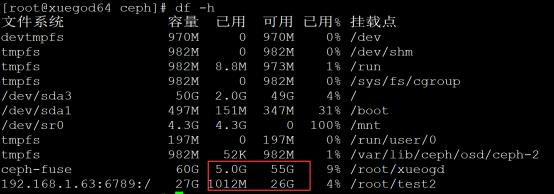
文件系统 容量 已用 可用 已用% 挂载点
ceph-fuse 60G 5.0G 55G 9% /root/xueogd
192.168.1.63:6789:/ 27G 1012M 26G 4% /root/test2
注:当写入1G文件时,fusermount查看大小,已用空间直接增加2G左右,mount查看大小只增加1G左右。
总结:由此可以看到mount挂载显示是的用户真实可以使用的磁盘空间大小, fusermount显示的ceph
OSD一共的空间,不用户可以使用的大小。我们设置了OSD存储数据,存2个副本,60G/2=27G左右,因为MSD还要占用一些空间。
排错汇总:
排错1:如查要在新节点xuegod65.cn上挂载,需要将配置文件以及密钥文件拷贝至客户端节点,
用ceph-deploy把配置文件和admin密钥拷贝到新节点,这样每次执行Ceph命令行时就无需指定monitor地址和ceph.client.admin.keyring了)
[root@xuegod63 ceph]# ceph-deploy admin xuegod65.cn #分发配置文件
不然会报以下错:
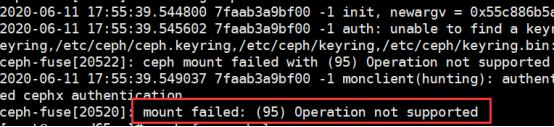
排错2:
[root@xu直播双11千亿流量高并发秒杀架构设计
黑马程序员
QQ号:1967401436
传智播客旗下互联网资讯,学习资源免费分享平台

明天就是双11,播妞温馨提示:记得定好今晚的闹钟,不然等你明天醒来,你会发现什么也没有了!
已经付了2波尾款的播妞,购物车还有一大波东西,准备等双11当天秒杀抢购!(拼手速的时候到啦!!!)

作为一名程序员,我们都知道秒杀在电商项目中是属于技术挑战最大的业务,很多高并发问题需要解决,那你知道以下技术问题该如何解决吗?
a.在双11场景下的亿级流量要如何控制?
b.如何打造一套具备亿级流量自适应调节能力秒杀系统,实现快速分流?
c.百万QPS压秒级响应的设计原则有哪些?
d.队列削峰填谷在高并发场景下如何投入实战使用?
e.大数据分析安全风控怎么落实?
f.如何实时发现并发极高的链接?哪些措施能有效隔离并发极高的请求?
g.数据安全级别的风控又该如何实现?
如果以上问题你都不清楚,但很想知道应该如何去解决,那你一定不要错过今晚19:00《双11千亿流量高并发秒杀架构设计》直播课程!
扫描下方二维码
进入直播交流群
↓↓↓

【课程名称】
双11千亿流量高并发秒杀架构设计
【课程时间】
今晚(11月10日)19:00
【课程简介】
采用独特的模块化设计,在基础电商业务基础上,深入讲解海量数据高并发解决方案,融入熔断限流技术解决方案、秒杀高并发抗压能力解决方案、实时热点数据发现、实时热点数据隔离、抢单流程隔离方案,实现了一套能跟随高并发波动自动调控抢单处理模式的企业级秒杀系统。
【主讲内容】
1.亿级流量百万QPS并发秒杀架构设计;
2. 数据实时同步最高效的解决方案;
3.效率最高的脚本语言Lua实战使用;
4.大数据实时收集用户访问日志。
【主讲教师】沈老师
一线城市8年开发经验,先后在三维度、中润四方、中保鸿业担任项目经理或技术总监,精通Java企业平台技术,熟练掌握企业搜索引擎、分布式架构、SOA架构、微服务架构。曾研发广西税务系统、易迅网络发票、三维度商城、三维度支付系统,主导B2B2C大型电商,神州培训网、万语网、金融平台的研发与重构。
扫描下方二维码
直达直播间
↓↓↓

-END-
推荐阅读:
分享、点赞、在看三连下
不错过黑马程序员编程资源
我就知道你会
“在看”
“阅读原文”直达直播间!
以上是关于世界500强是如何解决千亿流量留存问题的,《Ceph分布式存储架构》-使用CentOS 7部署 Ceph分布式存储架构-为他们解决什么问题。的主要内容,如果未能解决你的问题,请参考以下文章