HBase 架构
Posted 梁辰兴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase 架构相关的知识,希望对你有一定的参考价值。
文章目录
一,HBase 架构简介
hbase架构拓扑图
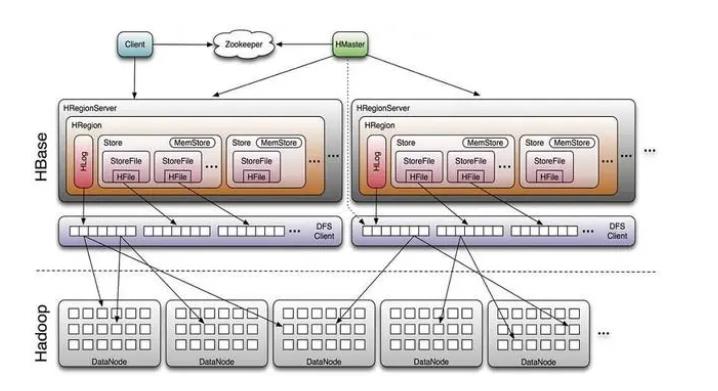
Client
包含访问HBase的接口并维护cache来加快对HBase的访问。
Zookeeper
保证任何时候,集群中只有一个master存贮所有Region的寻址入口。实时监控Region server的上线和下线信息。并实时通知Master存储HBase的schema和table元数据。
Master
- 为Region server分配region。
- 负责Region server的负载均衡。
- 发现失效的Region server并重新分配其上的region。
- 管理用户对table的增删改操作。
RegionServer
Region server维护region,处理对这些region的IO请求,负责切分在运行过程中变得过大的region。
HLog(WAL log)
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和 region名字外,同时还包括sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系 统中sequence number。
HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的 KeyValue。
Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会 两个新的region(裂变);当table中的行不断增多,就会有越来越多的region。这样一张完整的表 被保存在多个Regionserver上。
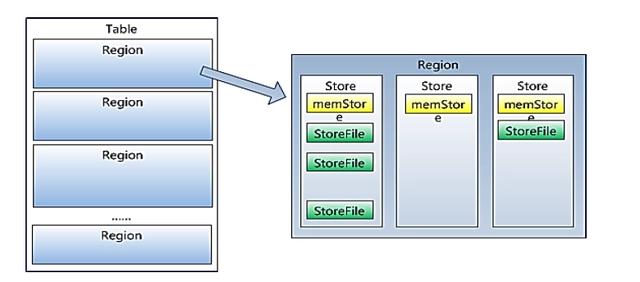
Memstore 与 storefile
一个region由多个store组成,一个store对应一个CF(列族)store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 majorcompaction),在合并过程中会进行版本合并和删除工作 (majar),形成更大的storefile。
当一个region所有storefile的大小和超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
客户端检索数据,先在memstore找,找不到再找storefile HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的HRegion server上。
HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。
HBase和HDFS的对比
| HBase | HDFS |
|---|---|
| 建立在HDFS之上的数据库 | 适用于存储大容量文件的分布式文件系统 |
| 提供在较大的表快速查找 | 不支持快速单独记录查找 |
| 提供了数十亿条记录低延迟访问单个行记录(随机存储) | 提供了高延迟批量处理;没有批处理概念 |
| 内部使用哈希表和提供随机接入,并且其存储随机索引,可对在HDFS文件中的数据进行快速查找 | 提供的数据只能顺序访问 |
二,HBase数据的读/写流程
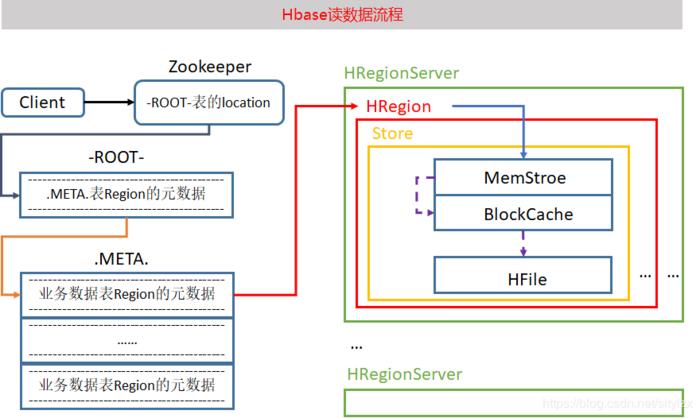
Hbase读取数据的流程
1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接
2)从zookeeper中获取一个hbase:meta表位置信息,被哪一个regionserver所管理着
hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些reguion,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。
3)连接这个meta表对应的regionserver,从meta表中获取当前你要读取的这个表对应的regionsever是谁。
当一个表多个region怎么办呢?
如果我们获取数据是以get的方式,只会返回一个regionserver
如果我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。
4)连接要读取表的对应的regionserver,从regionserver上的开始读取数据:
读取顺序:memstore–>blockcache–>storefile–>Hfile中
注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。
HBase写入数据的流程
1-4步是客户端写入数据的流程
1)由客户端发起写数据请求,首先会与zookeeper建立连接。
2)从zookeeper中获取hbase:meta表被哪一个regionserver所管理。
3)连接hbase:meta表中获取对应的regionserver地址 (从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址。
4)与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
5-7步是服务器内部的操作
异步操作
5)随着客户端不断地写入数据,memstore中的数据会越来多,当内存中的数据达到阈值(128M/1h)的时候,放入到blockchache中,生成新的memstore接收用户过来的数据,然后当blockcache的大小达到一定阈值(0.85)的时候,开始触发flush机制,将数据最终刷新到HDFS中形成小的Hfile文件。
6)随着不断地刷新,storefile不断地在HDFS上生成小HFIle文件,当小的HFile文件达到阈值的时候(3个及3个以上),就会触发Compaction机制,将小的HFile合并成一个大的HFile。
7)随着不断地合并,大的HFile文件会越来越大,当达到一定阈值(最终10G)的时候,会触发分裂机制(split),将大的HFile文件进行一分为二,同时管理这个大的HFile的region也会被一分为二,形成两个新的region和两个新的HFile文件,一对一的进行管理,将原来旧的region和分裂之前大的HFile文件慢慢地就会下线处理。
三,任务实施
启动HBase之后,使用HBase Shell命令进入HBaseShell窗口,然后可以使用help命令浏览帮助文档,查看每个具体参数的使用方法。命令如下:
$ hbase shell
在hbase(main):001:0>后面直接输入help,会出现如下信息:
通过help命令,可以学习到怎样引用表名、行键、列名。
HBase存储架构
参考技术A上图是HBase的存储架构图。
由上图可以知道,客户端是通过Zookeeper找到HMaster,然后再与具体的Hregionserver进行沟通读写数据的。
具体到物理实现,细节包括以下这些:
首先要清楚HBase在hdfs中的存储路径,以及各个目录的作用。在hbase-site.xml 文件中,配置项 <name> hbase.rootdir</name> 默认 “/hbase”,就是hbase在hdfs中的存储根路径。以下是hbase0.96版本的个路径作用。1.0以后的版本请参考这里: https://blog.bcmeng.com/post/hbase-hdfs.html
1、 /hbase/.archive
HBase 在做 Split或者 compact 操作完成之后,会将 HFile 移到.archive 目录中,然后将之前的 hfile 删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
2、 /hbase/.corrupt
存储HBase损坏的日志文件,一般都是为空的。
3、 /hbase/.hbck
HBase 运维过程中偶尔会遇到元数据不一致的情况,这时候会用到提供的 hbck 工具去修复,修复过程中会使用该目录作为临时过度缓冲。
4、 /hbase/logs
HBase 是支持 WAL(Write Ahead Log) 的,HBase 会在第一次启动之初会给每一台 RegionServer 在.log 下创建一个目录,若客户端如果开启WAL 模式,会先将数据写入一份到.log 下,当 RegionServer crash 或者目录达到一定大小,会开启 replay 模式,类似 MySQL 的 binlog。
5、 /hbase/oldlogs
当.logs 文件夹中的 HLog 没用之后会 move 到.oldlogs 中,HMaster 会定期去清理。
6、 /hbase/.snapshot
hbase若开启了 snapshot 功能之后,对某一个用户表建立一个 snapshot 之后,snapshot 都存储在该目录下,如对表test 做了一个 名为sp_test 的snapshot,就会在/hbase/.snapshot/目录下创建一个sp_test 文件夹,snapshot 之后的所有写入都是记录在这个 snapshot 之上。
7、 /hbase/.tmp
当对表做创建或者删除操作的时候,会将表move 到该 tmp 目录下,然后再去做处理操作。
8、 /hbase/hbase.id
它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。
9、 /hbase/hbase.version
同样也是一个文件,存储集群的版本号,貌似是加密的,看不到,只能通过web-ui 才能正确显示出来
10、 -ROOT-
该表是一张的HBase表,只是它存储的是.META.表的信息。通过HFile文件的解析脚本 hbase org.apache.hadoop.hbase.io.hfile.HFile -e -p -f 可以查看其存储的内容,如下所示:
以上可以看出,-ROOT-表记录的.META.表的所在机器是dchbase2,与web界面看到的一致:
11、 .META.
通过以上表能找到.META.表的信息,该表也是一张hbase表,通过以上命令,解析其中一个region:
以上可以看出,adt_app_channel表的数据记录在dchbase3这台reginserver上,也与界面一致,如果有多个region,则会在表名后面加上rowkey的范围:
通过以上描述,只要找到-ROOT-表的信息,就能根据rowkey找到对应的数据,那-ROOT-在哪里找呢?从本文一开始的图中可以知道,就是在zookeeper中找的。进入zookeeper命令行界面:
可以看出-ROOT-表存储在 dchbase3 机器中,对应界面如下:
以上就是HBase客户端根据指定的rowkey从zookeeper开始找到对应的数据的过程。
那在Region下HBase是如何存储数据的呢?
以下就具体操作一张表,查询对应的HFile文件,看HBase的数据存储过程。
在HBase创建一张表 test7,并插入一些数据,如下命令:
查看wal日志,通过 hbase org.apache.hadoop.hbase.regionserver.wal.HLog --dump -p 命令可以解析HLog文件,内容如下:
查看HFile文件,内容如下:
由此可见,HFile文件就是存储HBase的KV对,其中Key的各个字段包含了的信息如下:
由于hbase把cf和column都存储在HFile中,所以在设计的时候,这两个字段应该尽量短,以减少存储空间。
但删除一条记录的时候,HBase会怎么操作呢?执行以下命令:
删除了rowkey为200的记录,查看hdfs,原来的HFile并没有改变,而是生成了一个新的HFile,内容如下:
所以在HBase中,删除一条记录并不是修改HFile里面的内容,而是写新的文件,待HBase做合并的时候,把这些文件合并成一个HFile,用时间比较新的文件覆盖旧的文件。HBase这样做的根本原因是,HDFS不支持修改文件。
以上是关于HBase 架构的主要内容,如果未能解决你的问题,请参考以下文章