V8 工作原理之栈空间和堆空间
Posted 王乔治威尔金斯玛格丽特汤姆森希尔德萨拉阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了V8 工作原理之栈空间和堆空间相关的知识,希望对你有一定的参考价值。
V8 工作原理之栈空间和堆空间
首先抛出一个问题:“javascript 中的数据是如何存储在内存中的”
在解释问题之前,先来看两段代码
function foo()
var a = 1
var b = a
a = 2
console.log(a) // 2
console.log(b) // 1
foo()
function foo()
var a = name: '张三'
var b = a
a.name = '李四'
console.log(a) // name: '李四'
console.log(b) // name: '李四'
foo()
会发现第二段代码和第一段代码打印出来的表现不太一致。要彻底弄清楚这个问题,我们就得先从“JavaScript 是什么类型的语言”讲起。
JavaScript 是什么类型的语言
每种编程语言都具有内建的数据类型,但它们的数据类型常有不同之处,使用方式也很不一样,比如 C 语言在定义变量之前,就需要确定变量的类型,你可以看下面这段 C 代码:
int main()
int a = 1;
char* b = "";
bool c = true;
return 0;
上述代码声明变量的特点是:在声明变量之前需要先定义变量类型。**我们把这种在使用之前就需要确认其变量数据类型的称为静态语言。相反地,我们把在运行过程中需要检查数据类型的语言称为动态语言。**比如我们所讲的 JavaScript 就是动态语言,因为在声明变量之前并不需要确认其数据类型。
虽然 C 语言是静态,但是在 C 语言中,我们可以把其他类型数据赋予给一个声明好的变量,如:
c = a
前面代码中,我们把 int 型的变量 a 赋值给了 bool 型的变量 c,这段代码也是可以编译执行的,因为在赋值过程中,C 编译器会把 int 型的变量悄悄转换为 bool 型的变量,我们通常把这种偷偷转换的操作称为隐式类型转换。而**支持隐式类型转换的语言称为弱类型语言,不支持隐式类型转换的语言称为强类型语言。**在这点上,C 和 JavaScript 都是弱类型语言。
对于各种语言的类型,你可以参考下图:
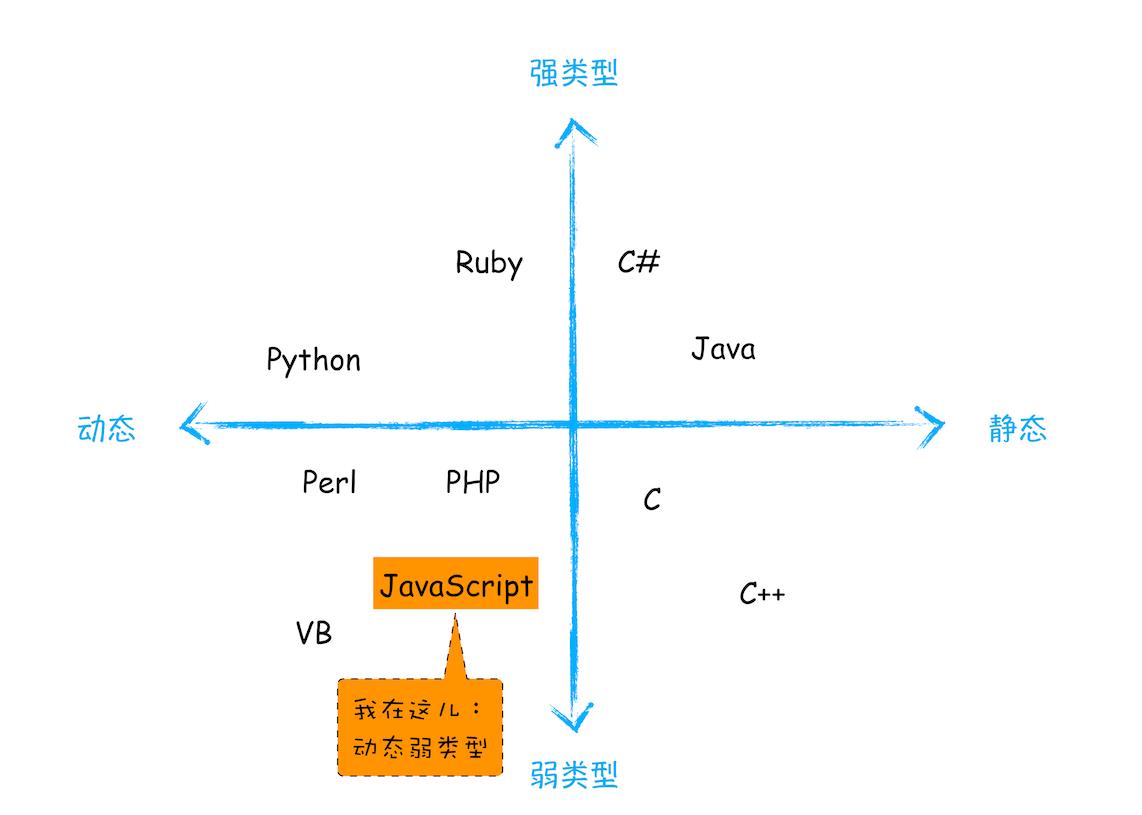
JavaScript 的数据类型
**JavaScript 是一种弱类型的、动态的语言。**那这些特点意味着什么呢?
- 弱类型,意味着你不需要告诉 JavaScript 引擎这个或那个变量是什么数据类型,JavaScript 引擎在运行代码的时候自己会计算出来。
- 动态,意味着你可以使用同一个变量保存不同类型的数据。
在 JavaScript 中,如果你想要查看一个变量到底是什么类型,可以使用“typeof”运算符。具体使用方式如下所示:
var bar
console.log(typeof bar) //undefined
bar = 12
console.log(typeof bar) //number
bar = ''
console.log(typeof bar) //string
bar = true
console.log(typeof bar) //boolean
bar = null
console.log(typeof bar) //object
bar = name: ''
console.log(typeof bar) //object
bar = []
console.log(typeof bar) //object
其实 JavaScript 中的数据类型一种有 8 种,它们分别是:
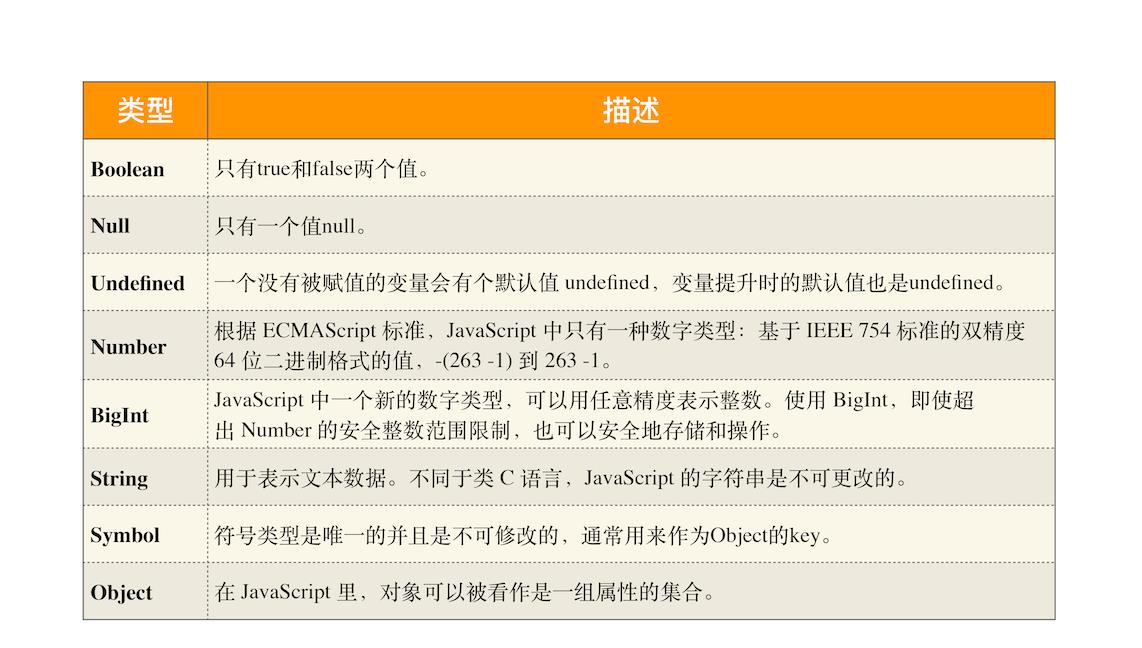
有以下三点需要注意:
- 使用 typeof 检测 Null 类型时,返回的是 Object。这是当初 JavaScript 语言的一个 Bug,一直保留至今,之所以一直没修改过来,主要是为了兼容老的代码。
- Object 类型比较特殊,它是由上述 7 种类型组成的一个包含了 key-value 对的数据类型。Object 是由 key-value 组成的,其中的 vaule 可以是任何类型,包括函数,这也就意味着你可以通过 Object 来存储函数,Object 中的函数又称为方法。
- 我们把前面的 7 种数据类型称为原始类型,把最后一个对象类型称为引用类型,之所以把它们区分为两种不同的类型,是因为它们在内存中存放的位置不一样。具体怎么不一样,需要知道 JavaScript 的原始类型和引用类型到底是怎么储存的
内存空间
要理解 JavaScript 在运行过程中数据是如何存储的,你就得先搞清楚其存储空间的种类。下面是 JavaScript 的内存模型:

从图中可以看出, 在 JavaScript 的执行过程中, 主要有三种类型内存空间,分别是代码空间、栈空间和堆空间。
其中的代码空间主要是存储可执行代码的,这个我们后面再做介绍,今天主要来说说栈空间和堆空间。
栈空间和堆空间
这里的栈空间就是我们之前反复提及的调用栈,是用来存储执行上下文的。为了搞清楚栈空间是如何存储数据的,我们还是先看下面这段代码:
function foo()
var a = '极客时间'
var b = a
var c = name: '极客时间'
var d = c
foo()
当执行一段代码时,需要先编译,并创建执行上下文,然后再按照顺序执行代码。那么下面我们来看看,当执行到第 3 行代码时,其调用栈的状态,你可以参考下面这张调用栈状态图:
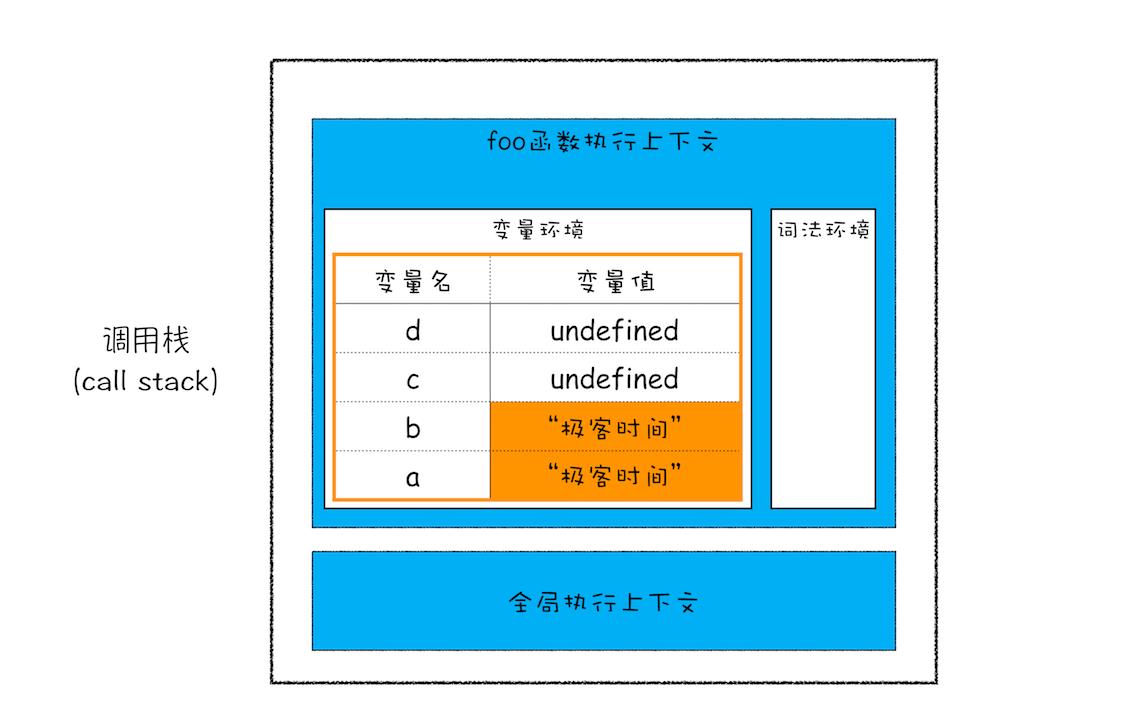
从图中可以看出来,当执行到第 3 行时,变量 a 和变量 b 的值都被保存在执行上下文中,而执行上下文又被压入到栈中,所以你也可以认为变量 a 和变量 b 的值都是存放在栈中的。
接下来继续执行第 4 行代码,由于 JavaScript 引擎判断右边的值是一个引用类型,这时候处理的情况就不一样了,JavaScript 引擎并不是直接将该对象存放到变量环境中,而是将它分配到堆空间里面,分配后该对象会有一个在“堆”中的地址,然后再将该数据的地址写进 c 的变量值,最终分配好内存的示意图如下所示:
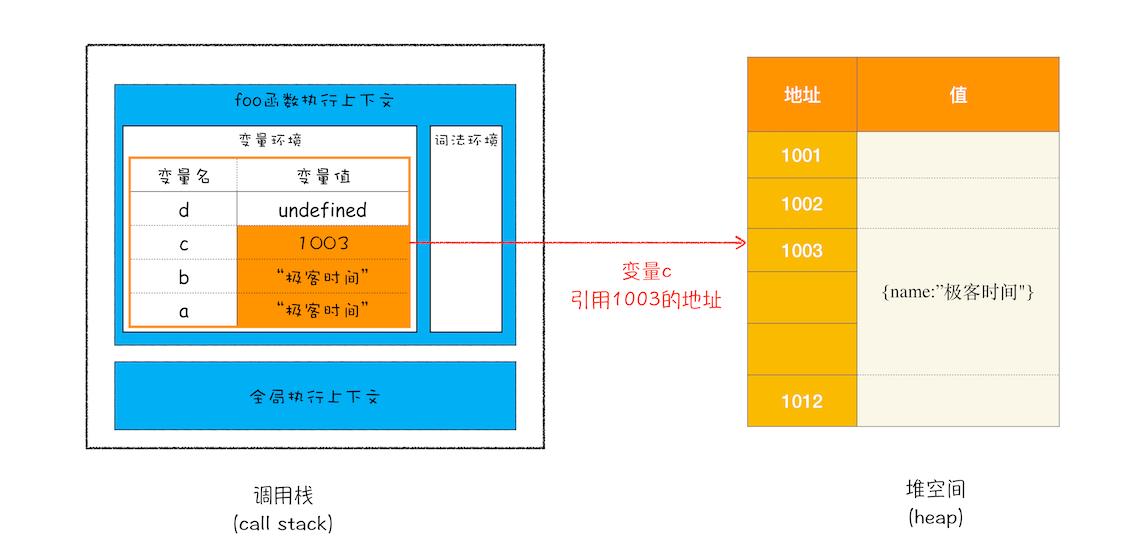
从上图你可以清晰地观察到,对象类型是存放在堆空间的,在栈空间中只是保留了对象的引用地址,当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。
现在就知道了原始类型的数据值都是直接保存在“栈”中的,引用类型的值是存放在“堆”中的。为什么一定要分“堆”和“栈”两个存储空间呢?所有数据直接存放在“栈”中不就可以了吗?
答案是不可以的。这是因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。比如文中的 foo 函数执行结束了,JavaScript 引擎需要离开当前的执行上下文,只需要将指针下移到上个执行上下文的地址就可以了,foo 函数执行上下文栈区空间全部回收,具体过程你可以参考下图:
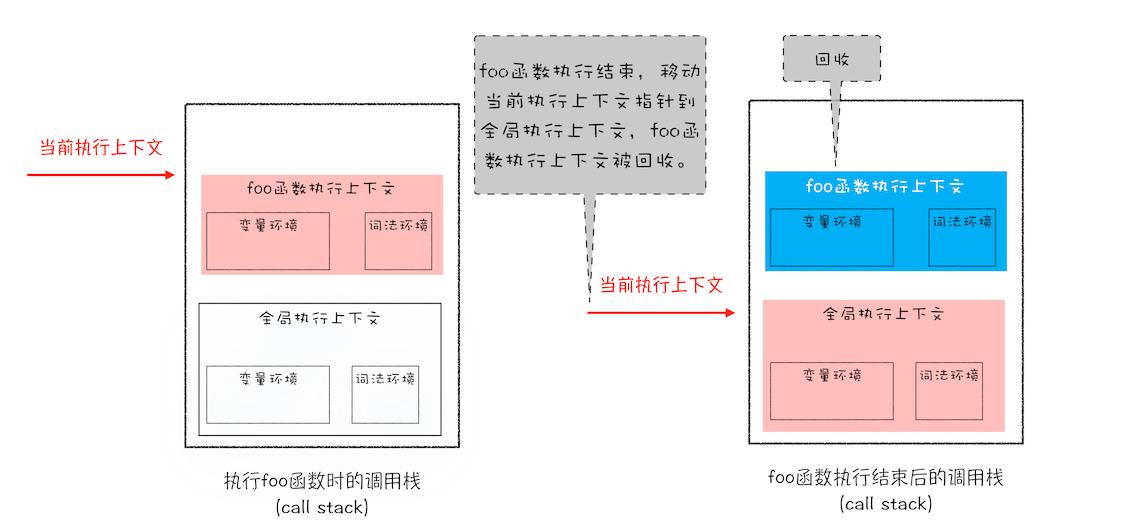
所以通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。
现在回到示例代码那里,看看它最后一步将变量 c 赋值给变量 d 是怎么执行的
在 JavaScript 中,赋值操作和其他语言有很大的不同,原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址。
所以 d=c 的操作就是把 c 的引用地址赋值给 d,你可以参考下图:
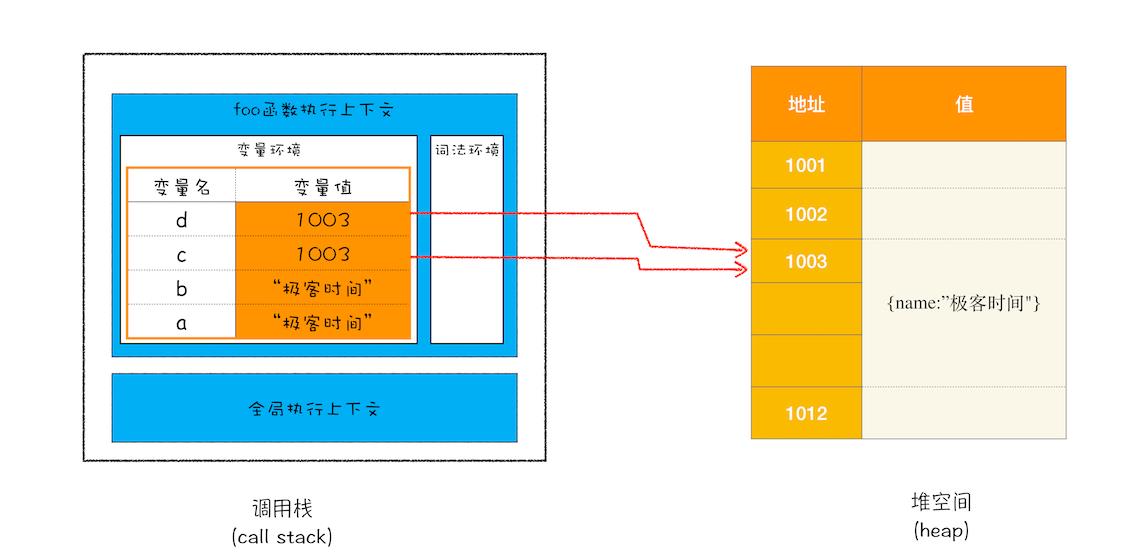
从图中可以看到,变量 c 和变量 d 都指向了同一个堆中的对象,所以这就很好地解释了文章开头的那个问题,通过 c 修改 name 的值,变量 d 的值也跟着改变,归根结底它们是同一个对象。
闭包
以下列代码为例:
function foo()
var myName = ' 极客时间 '
let test1 = 1
const test2 = 2
var innerBar =
setName: function (newName)
myName = newName
,
getName: function ()
console.log(test1)
return myName
return innerBar
var bar = foo()
bar.setName(' 极客邦 ')
bar.getName()
首先我们看看当执行到 foo 函数内部的 return innerBar 这行代码时调用栈的情况
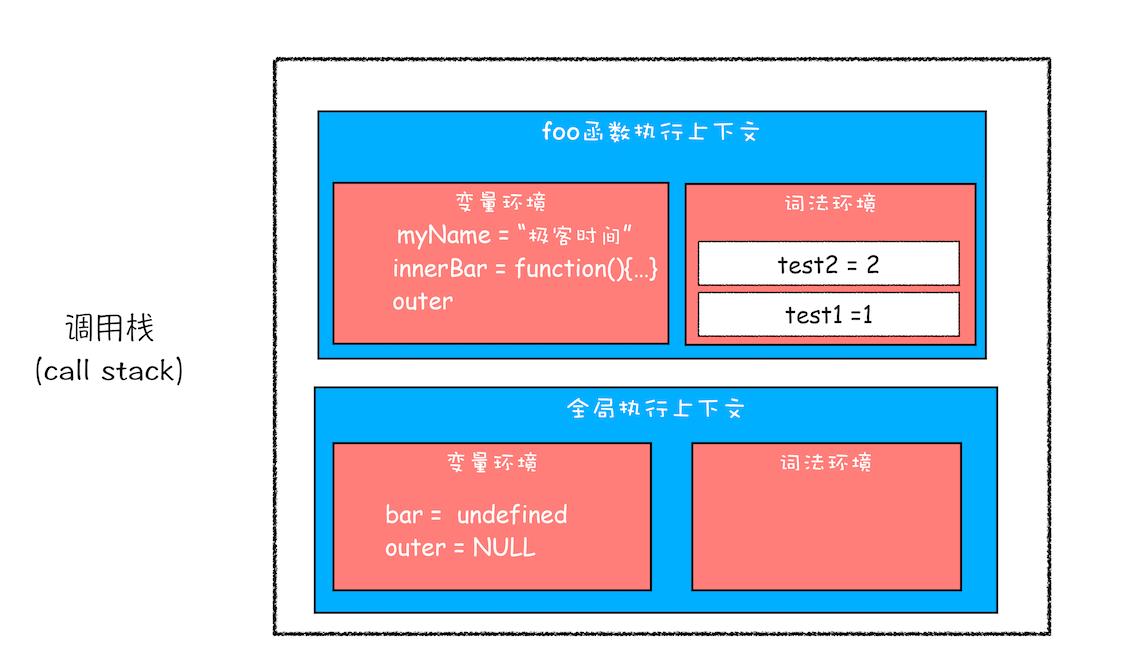
从上面的代码可以看出,innerBar 是一个对象,包含了 getName 和 setName 的两个方法。可以看到,这两个方法都是在 foo 函数内部定义的,并且这两个方法内部都使用了 myName 和 test1 两个变量。
根据词法作用域的规则,内部函数 getName 和 setName 总是可以访问它们的外部函数 foo 中的变量,所以当 innerBar 对象返回给全局变量 bar 时,虽然 foo 函数已经执行结束,但是 getName 和 setName 函数依然可以使用 foo 函数中的变量 myName 和 test1。所以当 foo 函数执行完成之后,其整个调用栈的状态如下图所示:
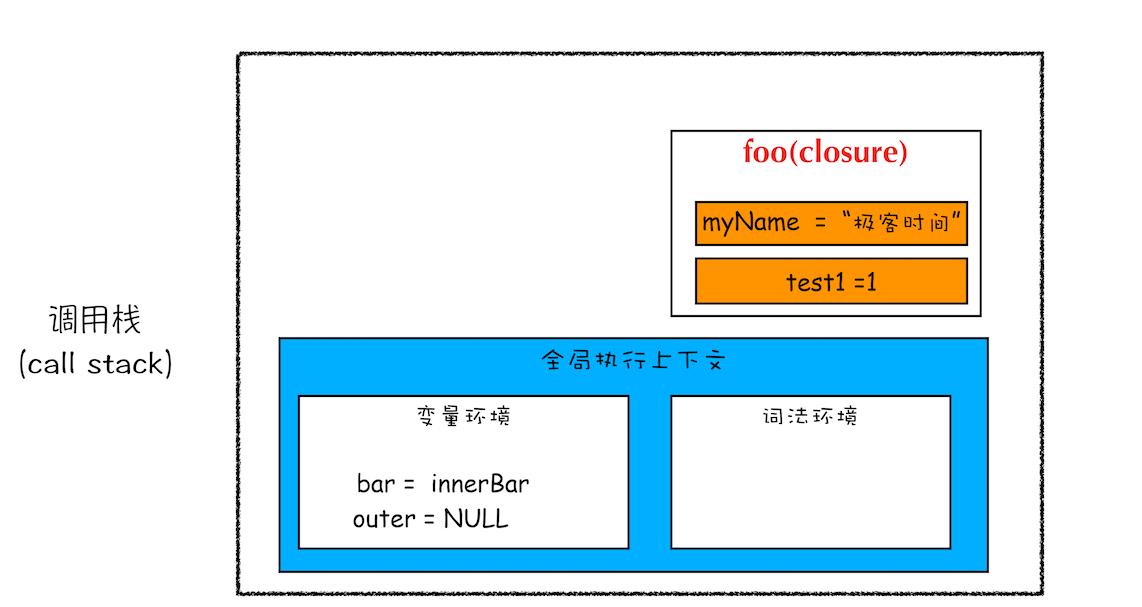
从上图可以看出,foo 函数执行完成之后,其执行上下文从栈顶弹出了,但是由于返回的 setName 和 getName 方法中使用了 foo 函数内部的变量 myName 和 test1,所以这两个变量依然保存在内存中。这像极了 setName 和 getName 方法背的一个专属背包,无论在哪里调用了 setName 和 getName 方法,它们都会背着这个 foo 函数的专属背包。
之所以是专属背包,是因为除了 setName 和 getName 函数之外,其他任何地方都是无法访问该背包的,我们就可以把这个背包称为 foo 函数的闭包。
现在终于可以给闭包一个正式的定义了。在 JavaScript 中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包。
数据结构之栈——多栈共享技术
多栈共享技术的应用:经常会发生一个程序使用多个栈的情况,然而若使用顺序栈,因为难以对每个栈的空间准确估计,所以会发生有的栈已经溢出,有的栈却还很空闲的状况,解决方案是:可以让多个栈共享一个足够大的数组空间,通过利用栈的动态特性来使其存储空间相互补充,这就是多栈的共享技术
双端栈:
首先申请一个共享的一位数组空间S[M],将两个栈的栈底分别放在数组的两端,即:0,M-1栈顶动态变化,从而多栈共享,提高空间利用率
双端栈的定义
typedef char ElemType;
typedef struct{
ElemType elem[M];
int top[2];
}ShareStack;
定义一个较大数组存放数据,下标用来表示他们在栈中的位子,定义一个较小数组(长度为2)分别存放两个栈顶位置
双端栈的初始化
//初始化
void Init(ShareStack *s)
{
s->top[0]=-1;
s->top[1]=M;
}
-1和M分别赋空
双端栈的入栈操作
//入栈:i表示栈号
bool PushStack(ShareStack *s,ElemType x,int i)
{
if(s->top[0]+1==s->top[1])
return false;
else
{
switch(i)
{
case 0:
s->top[0]++;
s->elem[s->top[0]]=x;
break;
case 1:
s->top[1]--;
s->elem[s->top[1]]=x;
break;
default:
return false;
}
}
return true;
}
先判断栈是否已满,若未满,根据i值(栈号)记住,先更改栈顶指示器top,在进行赋值操作
双端栈的出栈
bool PopStack(ShareStack *s,ElemType x,int i) { switch(i) { case 0: if(s->top[0]==-1) return false; else { x=s->elem[s->top[0]]; s->top[0]--; break; } case 1: if(s->top[1]==M) return false; else { x=s->elem[s->top[1]]; s->top[1]++ ; break; } default: return false; } return true; }
先根据i值(栈号),判断入哪一个栈,再分别判断栈是否为空,若未空,则先赋值,后更改top
以上是关于V8 工作原理之栈空间和堆空间的主要内容,如果未能解决你的问题,请参考以下文章