大型系统架构设计-阿里淘宝天猫双十一数据库核心技术介绍
Posted passionSnail
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型系统架构设计-阿里淘宝天猫双十一数据库核心技术介绍相关的知识,希望对你有一定的参考价值。
目录
(2)热点问题,2012 年出现热点数据并发更新,导致MySQL Thread running 飙升
零、双十一是什么?

那么双11到底是什么呢?
- 总理 : 消费的时间点
- 马云 : 中国消费者和厂家的感恩节
- 淘宝 : 购物狂欢节
- DBA : 系统大考
一、2013 双十一数据库指导思想
总体指导思想
- 知己知彼,百战不殆
- 平时多流汗,战时少流血
- 决不在同一个地方跌倒两次
- 尽最大的努力,做最坏的打算
1、知己知彼,百战不殆
(1)如何做到知己
如何准确评估数据库集群自身支撑能力
问题 :
同样硬件配置运行不同的业务,体现出来的能力上限完全不同
方案 :
Mytest 工具,针对不同硬件不同业务场景,使用真实硬件环境,真实业务数据,真实业务SQL,通过压测获得数据库能力模型,指导各个集群的扩容规模
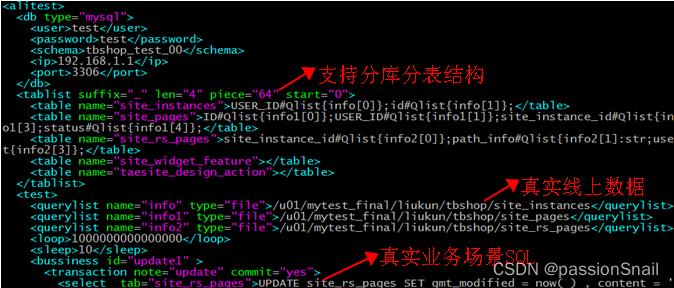
Mytest 工具特点:
- C 语言编写
- 压测采用C/S架构
- 支持分库分表逻辑
- 支持多表压测
- SQL语句可定制
- 支持多SQL事物模型
- 支持事物提交方式定制
- SQL 拼接变量全随机
- 支持多个SQL 不同比例配置
- 自动生成多种数据类型
(2)如何做到知彼
问题 :
业务要求系统能够支撑的交易创建能力,如何把这个指标向各个数据库集群分解,商品集群,交易集群等分别需要多少支撑能力
方案 :
a. 业务指标通过数据挖掘分析,分配创建指标到各个交易入口
b. 通过各个交易入口的浏览转化率,功能点点击率,获得各个应用系统的业务压力指标
c. 通过分布式追踪系统的统计数据,将业务系统压力转换为数据库集群压力
业务指标如何向数据库指标转换
- 基于历史成交数据分析,如购物车下单用户比例,立即购买用户比例
- 基于用户行为特点分析,多少次浏览会产生一次购买,多少人中会有一个人在购买时修改收货地址
- 基于淘宝自研的鹰眼系统将应用压力向数据库压力转换
- 缓存命中率在大促期间的特点,及可能出现的缓存失效问题
- 淘宝自研鹰眼系统,基于Google Dapper 论文研发,大型分布式追踪系统
2、平时多流汗,战时少流血
(1)真实环境压测之缓存穿透
问题 :
按照Mytest压测结果及业务指标转换后,数据库集群进行了适当的扩容,扩容后的集群的支撑能力上限是多少,在真实的业务场景中是否可以达到Mytest 压测获得的能力上限
方案 :
a. 关闭Put 缓存功能,逐步减低缓存命中率,让线上真实访问压力直接打在数据库上
b. 在关闭Put 缓存功能后,一次性手动清空所有缓存集群
c. 仅针对单个DB 关闭Put 缓存功能
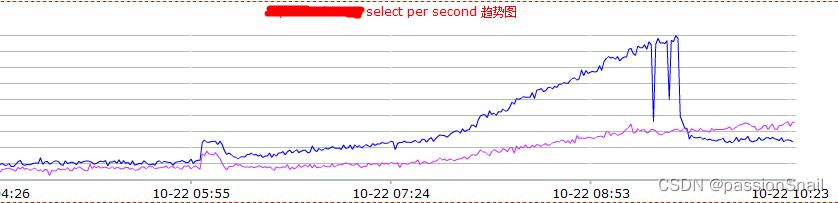
(2)MetaQueue 消息积压
问题 :
按照Mytest压测结果及业务指标转换后,数据库集群进行了适当的扩容,扩容后的集群的支撑能力上限是多少,在真实的业务场景中是否可以达到Mytest 压测获得的能力上限
方案 :
针对通过收发消息的系统,人为造成短暂消息积压,通过大量消息瞬间涌入,实现系统支撑能力压测
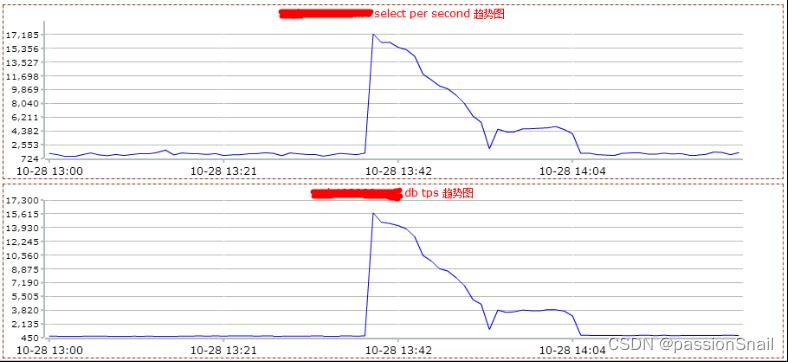
3、决不在同一个地方跌倒两次
(1)网卡瓶颈问题,2012年 出现数据库集群网卡接近上限
a. Mytest进行压测的过程中,加入网卡容量指标
b. 核心集群升级至万兆网络环境
c. 普通集群网络环境升级到双A工作模式
(2)热点问题,2012 年出现热点数据并发更新,导致mysql Thread running 飙升
a. 引入MySQL并发控制Patch
b. 引入MySQL 自我保护机制
(3)大卖家倒订单问题
a.超大卖家走订单中心
b.一般卖家订单信息从ISV各自拉取,改为主动推送
c.独立第三套卖家读库,支撑倒订单服务
4、尽最大的努力,做最坏的打算
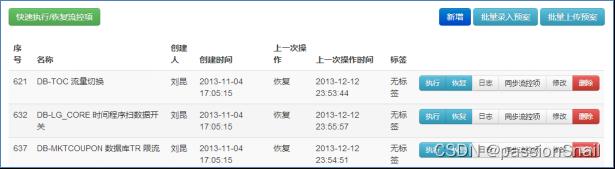
(1)243条双十一数据库预案
(1)243条详尽的数据库大促预案,按照功能维度分:
a. 应用降级预案
b. 流量分配预案
c. 限流保护预案
d. 主备切换预案
e. 全网公共预案
(2)预案线上环境业务低峰期真实演练
(3)预案管控系统,上下游联动,自动实时通知机制
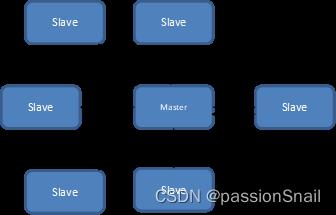
(2)主多备切换预案
- 部分集群采用一主库多读库结构,提高集群读支撑能力
- 集群采用星形主备结构,简化异常切换场景
- 当主库出现问题时,先将所有备库指向新主库,新主库再放开写流量
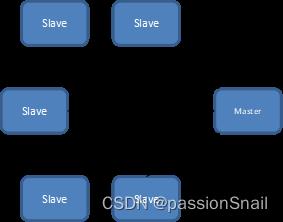
二、2013 双十一数据库核心技术介绍
1、核心技术介绍
| TDDL |
|
| ADHA |
|
| DBFree |
|
| AliMySQL 分支 |
|
2、DB Free - DBA Free
- 增加读库
- 实例迁移
- 实例拆分
- 实例扩容


3、数据库限流
(1)超出数据库容量的自我保护
a. 数据库自身保护机制,不再依赖应用保护
b. 根据预设的容量阀值进行限流,保护DB
c. 更新开发观念,数据库限流常态化
(2)对异常SQL语句进行限制
a. 一条异常SQL会影响整个DB,甚至整个系统
b.可以对特定SQL语句限流
c. 慢查询自动超时功能
4、热点数据更新排队
(1)减库存操作场景,热点商品库存更新排队
a.量更新同一条记录并发到达数据库
b.由于行锁机制全部进入排队队列
c.Innodb 内部维护队列锁争用及死锁检测机制性能消耗
d.原生MySQL单行更新的性能会跌到500以下
(2)并发控制Patch
a.淘宝MySQL内核组根据业务特点定制化开发
b.Innodb内部排队队列受innodb_thread_concurrency 限制
c.其他请求在MySQL Server 层面排队,不占用Innodb 资源
d.受大事物影响明显,需要应用配合保证
e.并发控制Patch 提升单行更新能力到4000 左右
5、并行复制
- 解决主备库复制延迟问题
- 通过动态参数配置开启及并行度
- 支持数据库,表级别,事物级并行
三、2013 双十一数据库案例分享
1、Cache 失效线上压测抖动
- 线上压测远远低于4W QPS 的目标
- 整个系统会Hang住2秒左右,同时CPU飙升,MySQL卡住,应用大面积报警
- 解决方法
- 数据库进一步拆分,降低连接数
- MySQL替换为AliMySQL限流版本
2、硬件导致抖动问题
- 正常压力下集群内各个单机表现稳定
- 压力摸高的过程中发现一台主机,RT 比集群内其他主机多400us
- 经排查确认原因为主机维修后Bios参数未调整
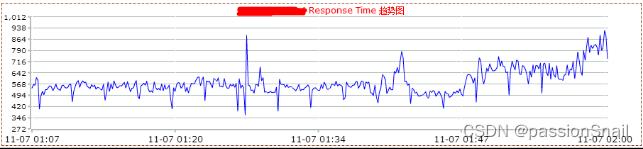
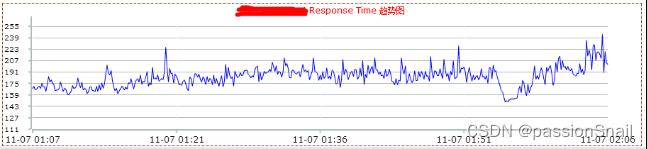
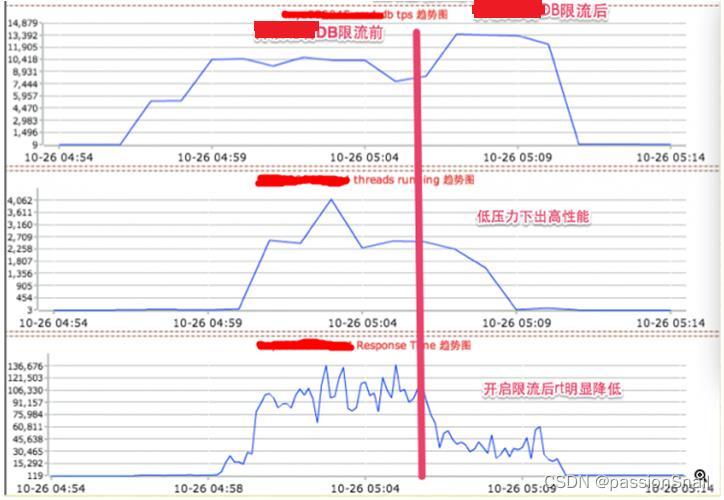
3、降低并发 提升性能
四、2013 双十一当天的故事
1、全网公共预案
- 读写分流,各个读业务按照不同比例分配读流量到备库,降低主库压力,让主库有更多余量来抗写入
- 数据库集群开启自我保护
- 写入型数据库修改双一参数
- sync_binlog
- flush_log_at_trx_commit
- 零点高峰前调大修改脏页比例
- innodb_max_dirty_pages_pct
2、核心系统双十一零点高峰指标
- 单机峰值最高达到 1.5W QPS / 1.2W TPS
- 单机网络达到 75MB
- 交易创建数据库响应时间 500us
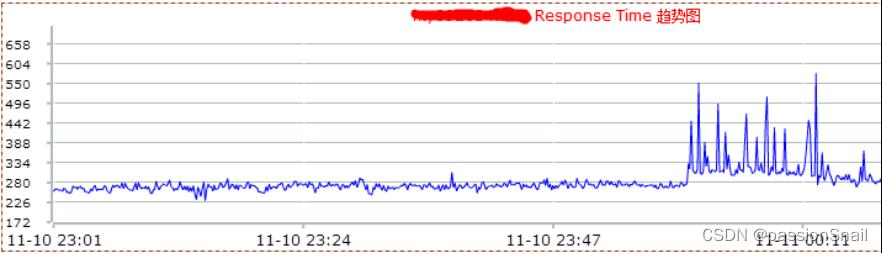
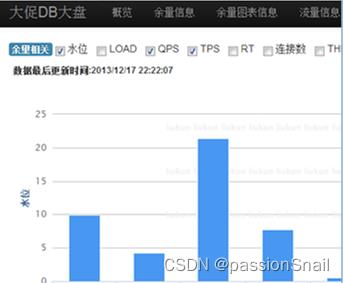
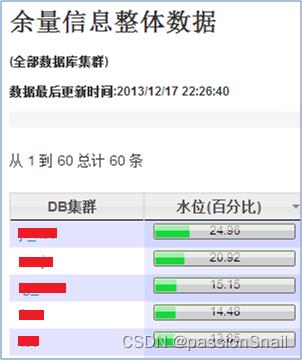
3、DCP 大盘监控系统
- 实时展现性能采集数据
- 图形化展示核心集群水位状态
- 详细指标信息精确到每个实例
- 网络包流量自动异常监控
没看够?下载原始PPT继续学习吧!
更多web系统架构设计相关资料↓↓↓
大型应用系统设计Flash存储设备在淘宝的应用实践共12页.pptx-Java文档类资源-CSDN下载大型应用系统设计Flash存储设备在淘宝的应用实践共12页.pptx更多下载资源、学习资料请访问CSDN下载频道. https://download.csdn.net/download/qq_27595745/85594469大型应用系统架构设计淘宝分布式调用跟踪系统介绍共60页.pptx-Java文档类资源-CSDN下载1.埋点和输出日志>中间件埋点,基于ThreadLoca>异步写,采样2.收集更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/qq_27595745/85594382
https://download.csdn.net/download/qq_27595745/85594469大型应用系统架构设计淘宝分布式调用跟踪系统介绍共60页.pptx-Java文档类资源-CSDN下载1.埋点和输出日志>中间件埋点,基于ThreadLoca>异步写,采样2.收集更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/qq_27595745/85594382
大型应用系统架构设计系统稳定性设计新浪微博稳定性经验谈共37页.pptx-Java文档类资源-CSDN下载大型应用系统架构设计系统稳定性设计新浪微博稳定性经验谈共37页.pptx更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/qq_27595745/85594012大型应用系统架构设计与优化高性能队列Fqueue的设计和使用实践共25页.pptx_fqueue使用-Java文档类资源-CSDN下载【目录】FQueue简介Fqueue的存储设计Fqueue的使用实践Q&Afqueue使用更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/qq_27595745/85593496
大型网站系统架构演化之路
一个成熟的大型网站(如淘宝、天猫、腾讯等)的系统架构并不是一开始设计时就具备完整的高性能、高可用、高伸缩等特性的,它是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随着业务的扩展而逐步完善的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝要解决海量的商品信息的搜索、下单、支付;例如腾讯要解决数亿用户的实时消息传输;百度它要处理海量的搜索请求;他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段广泛运用在大型网站系统的架构中,下面就通过介绍大型网站系统的演化过程,来认识这些技术和手段。
一、最开始的网站架构
最初的架构,应用程序、数据库、文件都部署在一台服务器上,如图:
二、应用、数据、文件分离
随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。
三、利用缓存改善网站性能
在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。
缓存常见的实现方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Memcached、Redis。
四、使用集群改善应用服务器性能
应用服务器作为网站的入口,会承担大量的请求,我们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,根据分发策略将请求分发到多个应用服务器节点。
常用的负载均衡技术硬件的有F5,价格比较贵,软件的有LVS、Nginx、HAProxy。LVS是四层负载均衡,根据目标地址和端口选择内部服务器,Nginx和HAProxy是七层负载均衡,可以根据报文内容选择内部服务器,因此LVS分发路径优于Nginx和HAProxy,性能要高些,而Nginx和HAProxy则更具配置性,如可以用来做动静分离(根据请求报文特征,选择静态资源服务器还是应用服务器)。
五、数据库读写分离和分库分表
随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分库分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切分则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务的不同来切分,如用户业务、商品业务相关的表放在不同的数据库中。
六、使用CDN和反向代理提高网站性能
假如我们的服务器都部署在成都的机房,对于四川的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。比较专业的CDN运营商有蓝汛、网宿。
而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有缓存数据才会继续访问应用服务器获取,这样做减少了获取数据的成本。反向代理有Squid,Nginx。
七、使用分布式文件系统
用户一天天增加,业务量越来越大,产生的文件越来越多,单台的文件服务器已经不能满足需求,这时就需要分布式文件系统的支撑。常用的分布式文件系统有GFS、HDFS、TFS。
八、使用NoSql和搜索引擎
对于海量数据的查询和分析,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb、hbase、redis,搜索引擎有lucene、solr、elasticsearch。
九、将应用服务器进行业务拆分
随着业务进一步扩展,应用程序变得非常臃肿,这时我们需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信或者共享数据库来实现。
十、搭建分布式服务
这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这些服务抽取出来利用分部式服务框架搭建分布式服务。阿里的Dubbo是一个不错的选择。
以上是关于大型系统架构设计-阿里淘宝天猫双十一数据库核心技术介绍的主要内容,如果未能解决你的问题,请参考以下文章