运维体系的构建
Posted 运维.大白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运维体系的构建相关的知识,希望对你有一定的参考价值。
一.前言
运维的基础工作通常是针对现有系统及项目的,例如服务器、各类云产品,正在运行的项目、监控、账号权限管控,项目上线等等,是宽泛而繁琐的,少有建设性的内容。
那当我们接手一套新的系统,就有必要将它本身及周边进行完善。可能少数公司有较为全面的运维体系,有我们的桌面运维,网络运维,安全运维,研发运维、数据库运维以及系统运维或应用运维等专业团队,而更多的公司运维可能只有1-2个。以上的岗位工作都需要完成,但以下我们着重会聊到应用运维。
在接触新环境时,面对的是上任留下的坑,这比开发接手代码要更加严峻。交接的资料其实不应该只是账号密码、工作流程,工作注意事项,更重要的是操作维护文档,因为系统很少有简单的环境,即便有,也会存在一些微妙的项目逻辑关系,稍有不慎,就有可能酿成线上问题,现在大多都是微服务的结构,增加了系统维护的复杂性。
例如接手后领导要你部署使用docker部署一个java服务 , 从正式环境复制一个到测试环境,结果启动后出问题了,可能是启动参数与目前环境不匹配,可能是连接权限未放开,可能是启动后连接的是生产的数据库,如果程序启动后清空或者修改了一些历史数据,令人细思极恐。
这种问题很常见,就我目前就遇到不少,好多配置信息写的很模糊,项目与项目之间耦合度非常高,没准就牵扯到哪个系统了,牵一发而动全身,是关也不敢关,改也不敢改,作为一名运维工程师,我们居然会不敢动一个项目!
所以要打造一个铁桶出来,这是一个创造性的过程,也是我们深入项目的过程。只有更深入的了解项目,才能更好的去维护项目。
做好一个运维的基础:
对自己当前的环境和任何东西都应该非常清楚;
要有监控,切实有用的可以发现问题的监控;
任何东西都要有备份,可以用于快速恢复,也要做恢复演练。
进阶∶
针对系统做优化处理;
针对工作流程做优化处理
这就是上述大纲了,后续会详细说明的,其实也是大众路线,先标准化、流程化,再自动化。
二.基础
2.1 项目摸底
在接手系统后,先要确保能日常维护,对整套系统做一个摸底,一般包括以下几项:
项目简介
账号密码表
项目资源管理配置清单
各种结构流程图
部署维护文档
项目监控策略汇总表
项目应急操作手册
项目简介
我们可以从当前项目的业务范围,即项目的功能是什么?以及项目负责人及相关人员是谁,方便我们后面更好的项目对接。
账号密码表
账号密码表中应详细记载各服务器、平台、系统的登录用户名及密码,另外还应该有权限记录表,记录给谁开过权限,登录账号又是什么,以上种种,此处仅是距离,需要记录的东西很多,切记一定要准确清晰。
项目资源管理配置清单
这里面我觉得至少包含但不限于4个sheet表:服务器清单,项目域名信息,项目服务信息,第三方服务资源清单,每种信息都应该列出项目所有环境的信息,例如正式和测试环境等。
各种结构项目流程图
例如此项目的网络拓扑图,系统架构图,从这个拓扑图中我们可以看到此架构使用了多少台服务器,整个逻辑流程是怎样的。例如我们可以从域名开始摸,域名对应的Ddos防护,下面是负载均衡,再下面是每个模块的服务。每个服务需要连接哪个库,又需要和哪个服务进行交互。
部署维护文档
此文档可包含详细的安装步骤,配置文件中的数据库等地址指向都要写清楚,那么如何检验此文档的实用性呢?将此文档交接给另外的同事,可以达到迁移恢复,复制项目的目的。
项目监控策略汇总表
主要包含目前的监控策略,可分为基础监控和业务监控。基础监控为CPU、内存、网络带宽等服务器基础资源监控;业务监控则是针对服务本身的监控,此监控可暴露出当前的项目问题。此表可方便与项目负责人对接项目监控问题,或方便以后查询监控是否有遗漏等。
项目应急操作手册
项目已知的问题,经常发生的问题的处理方法,解决方案等。
可能很多小伙伴认为上面部分内容是业务上的东西了,觉得运维没必要去学,开发让扩展部署几个服务,部署就是了,反正这块是开发要负责的,出了业务问题开发排查即可。
2.2 做一个好辅助
那这根本没有体现运维的价值。相信很多人玩过LOL,当时也着迷其中,记得有句话,在LOL小队5人中,通常由队长来担任辅助。因为辅助空闲时间更多,可以看到全局的内容,这句话放到运维身上也同样适用。
开发、测试都忙着对禅道中满屏的任务清单进行工作,需求、测试任务源源不绝,相信很多程序员都面临过产品或者运营作死的需求,尤其是互联网公司,项目需要进行快速迭代,有多个需求归类到一个版本中,大约2周一个版本,要在12天内开发完成,2天内进行预发布环境的发版测试,这段测试期需要一边解决bug,一边完成新的需求。
项目版本需求的排期都到3个月后了,并不是开发写完就可以休息了,后面任务只不过稍微提前了而已。测试也是一样,紧跟着开发进行功能验证,也是忙得不行。
那出现问题后,其它岗位并没有太多精力排查和关注性能等方面,都着眼于当前任务的开发,赶工期。那运维其实可以作为一个指挥官,并非是可有可无的角色,现在不被重视只是因为大多数运维并没有意识到这个重要性。
开发除非是全栈业务都熟练,就一个小团队20开发2测试1运维来说,开发都只研究自己的模块,每当出现问题就很难定位具体点,需要运维对整体系统要了解,系统+业务才能更好管理和排查。
2.3 学习业务
对于具体业务如何清楚了解,最好的方式是直接顺着现有资料捋顺它,遇到不明白的地方去问开发,将相应结构进行画图和文档进行维护好,那在公司中你的价值会成倍增加的。相信也会让领导更多的看到你落地的工作,且也会让同事们愿意相信你的能力。专业精神比知识更加重要。
当然不仅是为了更好维护系统,也是为了未来优化做准备。不用明白代码方面的,只要知道整体流程。
我们现在就有这种问题,某个模块连接哪个库都不知道,有时候突然发现测试的服务器竟然连接着生产的某个库,还用的公网连接(环境间VPC或安全组隔离),这要不一开始搞清楚,不去主动了解,那带来的问题、安全隐患会在后面某个时刻让你难受。
一个简单例子是有个老旧的电商项目,几台应用服务机器+一个mysql数据库,当时问了一圈人大家都说应该是不用了,已经到新的上面了。也没有去保存备份直接删除了,没过几天就有使用者联系说还在用。。。
这种盲区在我们快300台服务器里还有大量的存在,要是运维人员不主动去了解,那开发也没时间去看的,这个隐患会无限期搁置,还是上面说的,会在某个时刻咬你一口。
在我们大致了解整体结构后,以文档进行驱动,先建立好空白文档页。重点中的重点是我们的拓扑图、服务配置清单,起码项目的架构,是什么服务要了解清楚。
具体要了解哪些,我这里只能大致描述,再具体一些的地方应当根据你的项目情况再去统计。
了解域名走向,请求走向;
了解各服务之间的搭配,例如rabbitmq哪些程序在用,用来做什么;
每个模块程序之间如何通信的,需要如何进行交互;
了解各服务作用,当出现问题后,我们可以快速准确地判断出大概是哪个服务的原因。
但业务还是要了解的,流程图也依然要画,画图我目前用的在线工具:processon,如果你觉得免费的可用文件数量不够,上面可以付费购买团队模式,不是很贵。
2.4 标准与流程
做好图后,开始到系统里去整理,做标准化、流程化。建立好以下几个标准:
服务名称命名:可根据项目环境或用途进行命令
端口规范:可根据项目环境或用途进行划分
IP地址规划:可根据项目环境及区域进行划分
服务部署目录
日志输出目录
备份存放目录
工具包存放目录
数据存放目录
脚本存放目录等其它常用目录固定位置
流程:
各服务资源预算制作流程
服务器购买交付流程
服务部署/上线/维护流程
账号&权限添加流程
备份定期恢复验证演练流程
定期检查项目资源使用流程
故障报告管理流程
其实凡是资源都做规范了,凡是要多次重复做的都流程化,防止遗忘。这两样也是为了后面自动化打基础,将重复操作自动执行。
这两块整完,说明对系统做维护没有任何问题了,只要不是新东西,起码现有项目都可以管理好。
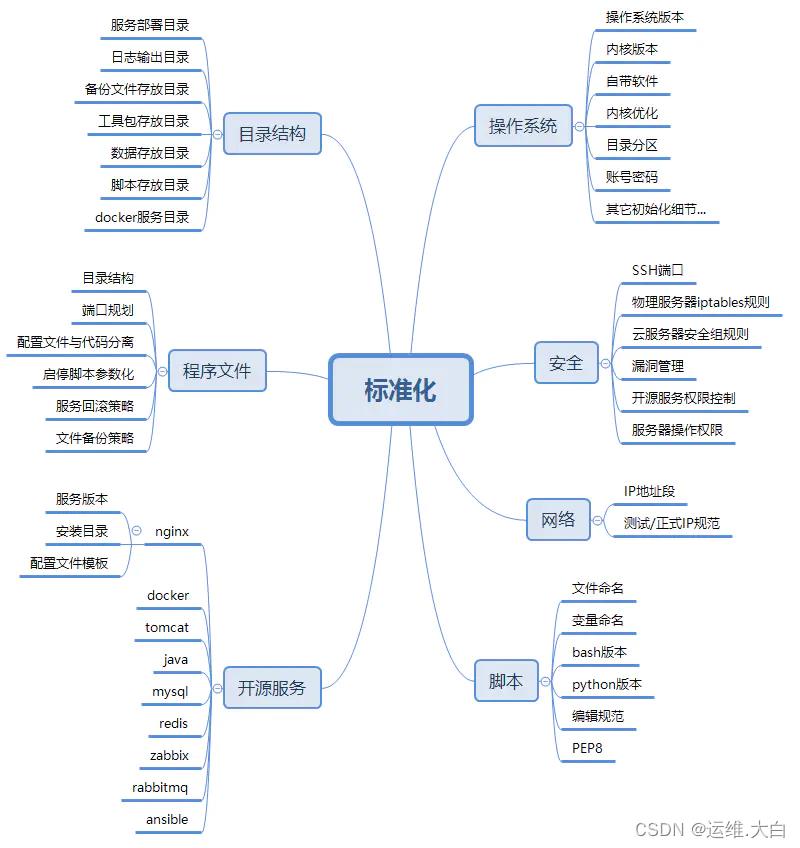
简单画个思维导图,标准化的范畴主要包含但不限于以下内容:
运维体系思维导图
2.5 维护
在项目不扩展优化的情况下,要维护好当前资源,需要用到监控与备份的帮助。有效的监控可以及时发现问题,避免人力重复巡检。完善的备份可以在出现任何系统问题的时候(非功能BUG),立刻进行恢复,简单方便快速有效。
监控具体可以针对业务做技术选型,一般是zabbix,容器或k8s就Prometheus,需要图形展示监控数据就grafana,另外还有小米的运维监控服务Open-Falcon。
备份如果用云服务就简单很多,可以使用脚本定时备份传到OSS里。物理机可可以写一些脚本,将任何有状态的东西都备份出来。例如数据库、配置文件、日常脚本、服务日志、等等和纯净系统有差异的东西。
三.进阶
3.1 系统&服务优化
系统或服务的优化比较常见,一般是更改配置文件,使得服务可以承接更多并发,可以抗更多压力。
这些有大把的文档可以看,这里不重复了,主要提几点注意的地方。
每次使用新服务器前,应进行系统初始化配置;
优化并不是改改配置就行,需要对每个参数及整套系统都有深入理解;
改配置的时候要慎重,不要想当然,很可能你这里为了减少图片的带宽占用开启了压缩,结果改完就崩溃了,线上的图片显示不完全了;
做优化方案的时候,要有层次,可以从最简单便宜的地方来。例如从结构上优化、去掉一些没用的模块,可以释放很多资源;
做安全方案也是,VPN+堡垒机(如jumpserver)可以解决99%日常安全隐患,而不是去从花费高、细节的地方先去实现。
3.2 工作流程优化
上面说了,其它岗位很繁忙,很难有精力做其它事,这里除了系统还有流程上的。他们遇到一些工作流程性问题,即使可以解决,但也很难停下脚步。
运维的用户是内部人员和服务器,所以工作可以分为可见和不可见(相对于部门)。所以在维护设备和服务器之余(服务器不会总出问题),可以将精力放到维护devops上,也就是工作方法。
例如当我们需要统计我们云服务资源时,如果我们使用人工采集,就需要单独一个人花费可能数天的时间进行统计。 那解决这个问题很简单,做一个自动采集云服务的工具,再由我们进行检查及表格美化即可。
再比如工作中大量的zabbix报警,可能相对没有那么紧急,会不会污染我们的报警工具,钉钉或微信等。那么对于业务不可用的情况做一个电话报警是不是更好呢,这样也不用时时刻刻盯着钉钉报警。
看着差别不大,盯着也不碍事,实际是运维价值的体现。再说几个例子,当前登录zabbix啊,jenkins、gitlab或禅道、OA或其他各种系统等都是单独账号,那搞LDAP是不是更好。或者做一个内部使用的常用网址导航页,这样会不会使用更加便捷。
SQL语句的执行,经常需要DBA在服务器中执行,那么做一个SQL审核平台,例如archer,随时随地都能审核开发人员提交的SQL进行执行。同样对于开发人员而言,测试或开发在正式或测试环境查询数据时用WEB版的数据库在线审计平台是不是比每个人用navcita更加安全和可控方便?
那jenkins发版后在钉钉加一个提醒是不是好点?开发提交代码后,自动发布更新项目是不是更加简单高效?
这些看似没有也没事,但当你发现某个开发遇到一些麻烦的影响时,你去解决,这就是内部的贡献,就像LOL中的辅助,在总揽大局,在推动devops的发展。
devops的概念炒了这么多年,更多人也在追求这种更高层次的工作方式,看内容基本都是运维的,开发的很少。这也和开发埋头工作不无关系,所以还是辅助最强!
当然人家用SVN好好的,你换gitlab当然不爱用,虽然SVN各种麻烦,但他熟悉了。如果大家不支持,可以去和领导谈,写一写计划书,整体运维体系规划这种。如果你真的有想法,领导也许真的 对你的想法有兴趣,但如果领导懒得看,那可以换下一家了,这家真的不值得付出,因为往后余生,都很痛苦。如果支持的不多,关注不到你(很常见,好多公司没运维主管,就CTO),那可以将计划书拆分几个小块,一点点改革,尽量和效果关联上。
例如现在要推广kubernets,那你首先要研究明白kubernets,也要懂docker,找到痛点才行。再去说这个kubernets的好处,找到kubernets的特点,例如它的资源调度、故障迁移更有利于项目运行,对公司效率的变化。或者往盈利方面贴。一套测试环境可以省下xxxx钱,那数十个项目,一个月就可以节省xxx钱,写的务实一点,效果还是很震撼的。
做任何工作不是只埋头做,还要和领导多交流,我们应该主动打破上下级之间的沉默,将我们的想法讲给里领导听,获得领导的想法,虽然很多事情小公司不注重,但你做了和没做是两码事。你比别的同事多提出了一些概念,你在公司就是先驱者,大家会觉得你挺厉害,技术大牛,一直在推动发展。这里讲开发他们也不是傻子,devops人家都听过的,随意你推动,大家都会欢迎的。职场之路困难与机遇并行。
3.3 规矩
开发人员写代码的时候,都会探讨一下怎么写,出一个方案,画一个流程图,用什么技术。新临时增加的需求也是如此,起码接到的个人会先想好思路。
但到运维这里好像就随意起来了,加安全组直接通知下就添加了,备注随意写写,当对方不用的时候也忘记了删除。“规矩”也是要建立的,这样才能让人信服,而不是谁都能指挥你,然后加出问题、改出问题了,锅又到你身上。
当然不能傻傻的和别人对着做,大家都讨厌规矩太多,那要在方便的基础上建立一些流程即可,例如申请白名单可以发一封申请邮件,备注一定要清晰明了,利用python脚本定时检查采集安全组规则进行检查,防患于未然。
3.4 运维管理平台
运维自动化平台的建设本质是运维团队服务化能力的变现过程,它让我们从大量重复无规律的人肉操作中解放出来,专注于运维服务质量的提升。
由于文章篇幅所限,就不和大家全面介绍整个自动化平台的设计思路,简单说一下我个人的一些心得:
第一是循序渐进的原则,在自动化运维体系建设过程中,我们首先可以构建一个基础的服务器批量操作平台,先把一部分需要重复执行的工作搬到平台上来,再依据运维的需求丰富这个操作平台的功能和提升效率,最后把周边的系统打通,相互对接,形成完整的自动化运维体系。
第二是考虑可扩展性。设计系统的时候,功能或者设计方面可能不用考虑那么多,但是要考虑当服务器数量发生比较大的扩张时,系统是否还能支撑,比如数量级从十到百,或者上千了,这个系统是否还是可用的。
第三是以实用为目的。这在我们系统中也是有体现的。可以考虑借鉴市面上比较成熟的工具进行自研。为什么不建议直接使用呢?因为目前常见的开源运维管理平台并不是有团队专人维护,如果使用过程中出现问题,排查难度将非常高。当然不可否认的是参考的价值。所以建议优先考虑开源方案加一部分二次开发。
原文参考 https://www.jianshu.com/p/d66a8f1222c2
4. 运维标准文档
通过运维的标准化,可以实现对“运维最佳实践”的归纳和总结,从而实现对“运维最佳实践”的统一规范和执行。所以标准化是提高团队效率的重要方式,是梳理运维杂乱问题的重要依据。
4.1 适用范围
多地线上ecs服务器的维护和日常管理,各个业务线以及相关中间件的维护。
4.2 运维标准化实施原则
ecs服务器维护原则
ecs服务器申请原则(根据应用的并发量和资源占用比来申请配置服务器的规格)
服务器的初始化原则(命名规范,配置dingding普通用户,应该和内核参数的调优,配置阿里云,安装logstali日志插件,zabbix-agent等)
3.2 应用部署原则
3.3 应用监控原则
阿里云监控(基本资源监控)
zabbix监控(基本资源监控+端口监控)
sls日志监控(根据日志输出关键字监控)
接口监控(根据特定接口返回值判断)
3.4 告警原则
根据应用监控设置触发告警阈值,当触发告警阈值后通过(钉钉,飞书,邮件,短信,电话)方式触发告警
3.5 中间及平台件维护原则
jenkins流水线维护原则(应用的命名原则脚本配置原则应用关闭原则)
jumpserver平台维护原则(机器分组添加原则,授权原则)
cmdb平台维护原则()
Archery数据库审计平台维护原则
apollo配置中心维护原则(添加修改配置原则)
zabbix管理配置原则(新服务器添加,端口监控)
rabitmq管理原则
阿里云账号平台管理原则(权限,ecs,rds,中间件,slb,sls,oss,域名等)
故障处理原则
一般问题处理原则(30分钟内响应处理)
重要问题处理原则(10分响应钟响应处理)
紧急重要问题处理原则(5分钟内响应处理)
4.3最佳实践原则
最佳实践不一定是最高效的,但一定是最贴合实际的,最佳实践理应是在企业组织中施行的、最没有痛点的一种方式。举个例子:很多公司现在还没有实现自动化运维,依靠人力+工具的方式维护着系统,效率还不低。对于他们来说这就是最佳实践。但随着时间的推移,人员的更替,最佳实践的表现方式会被打破。新的成熟的技术可能会被尝试和使用,比如puppet配置系统的引入,最佳实践也会有更新。所以标准化文档的拟定会是长期的不断迭代的过程。
4.4模块化原则
运维工作在不同的公司定位不一,所涉及到的内容也不同,管理的内容多且繁杂,很难梳理出一个整体的脉络。通过树状图造篮子,树状图完成后,就可以很简单地把我们最经常处理的问题,提炼出来放进篮子里,从而实现细微到小处的最佳实践。以产品服务为中心,将产品服务划分为三个层次: 基础服务器服务,中间层支撑服务,与应用服务。
在这里插入图片描述
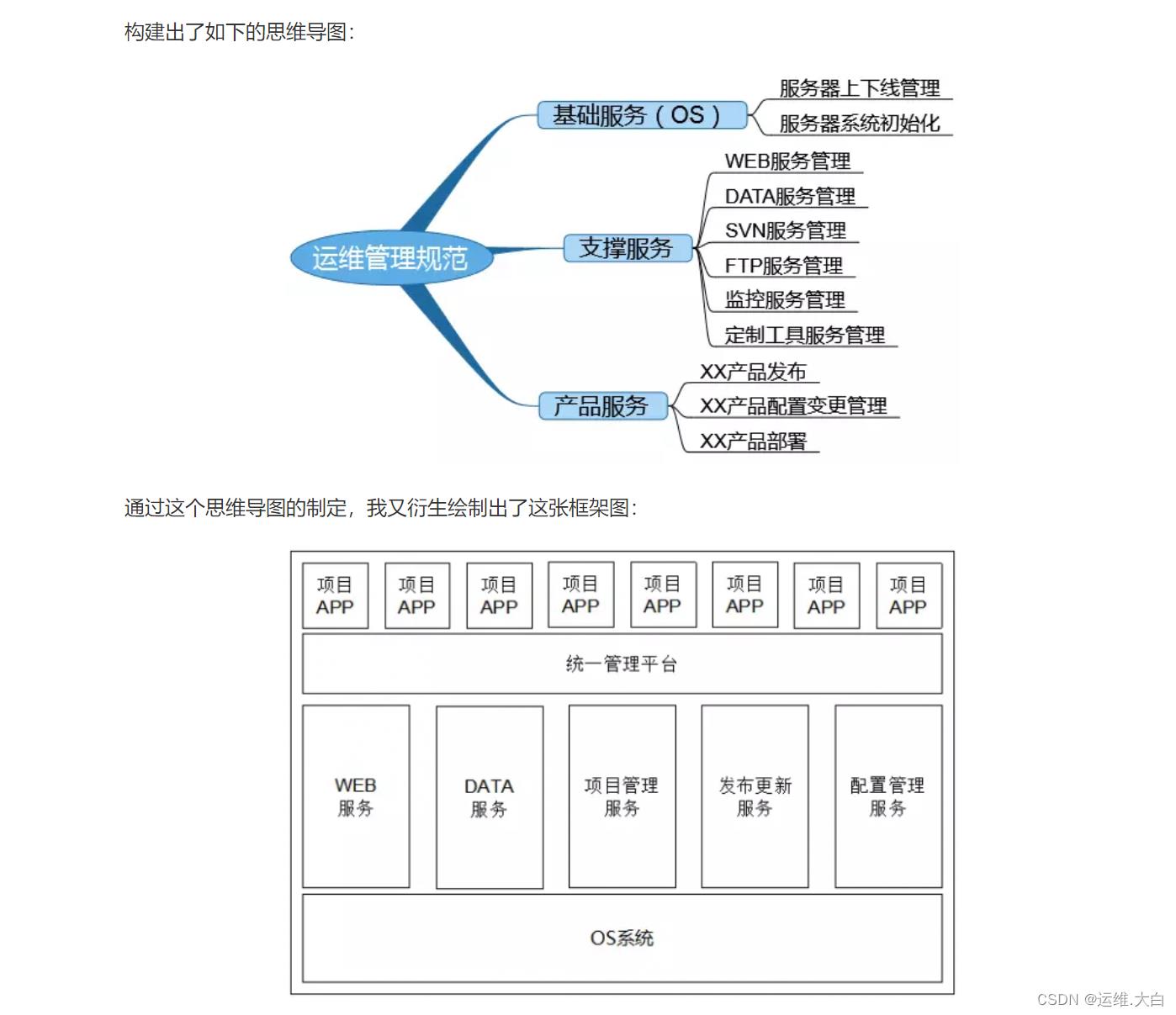
4.5 模板化原则
从每个人的实践经验中来整理标准,到每个人手里去寻找最佳实践,汇集整理起来。建议在标准的前言里就把标准化的组织方式写入进去,对全文进行约束,由专人审核评估,这样标准的标准化文档就能在团队中协同来编写,使得运维体系修订的更加完善。


以上是关于运维体系的构建的主要内容,如果未能解决你的问题,请参考以下文章