Solr 6.0 学习(十七)SolrCloud
Posted yvan1115
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr 6.0 学习(十七)SolrCloud相关的知识,希望对你有一定的参考价值。
参考:
SolrCloud中文讲解
windows下基于zookeeper发布solrcloud
官方文档
solrcloud wiki
solr中文文档
什么是solrcloud
官方文档的解释:
SolrCloud is designed to provide a highly available, fault tolerant environment for distributing your indexed content and query requests across multiple servers.
It’s a system in which data is organized into multiple pieces, or shards, that can be hosted on multiple machines, with replicas providing redundancy for both scalability and fault tolerance, and a ZooKeeper server that helps manage the overall structure so that both indexing and search requests can be routed properly.
中文解释(来自google翻译)
SolrCloud旨在提供高度可用的容错环境,用于在多个服务器之间分发索引内容和查询请求。
这是一个将数据组织成多个部分或碎片的系统,可以托管在多台机器上,副本为可扩展性和容错性提供冗余,以及一个ZooKeeper服务器,可帮助管理整个结构,以便索引和搜索 请求可以正确路由。
也可以说,SolrCloud是Solr的一种部署方式,除SolrCloud之外,Solr还可以以单机方和多机Master-Slaver方式进行部署。分布式索引是指当索引越来越大,一个单一的系统无法满足磁盘需求的时候,或者一次简单的查询实在要耗费很多时间的时候,我们就可以使用solr的分布式索引了。在分布式索引中,原来的大索引,将会分成多个小索引,solr可以将这些小索引返回的结果合并,然后返回给客户端。
为什么要使用SolrCloud
单机的solr部署就不再说明,但当业务的推荐,数据量的增加,要求的吞吐量越高,就必须得考虑集群分布式的方案。
master-slave 主从模式
1、master负责接收索引数据,最好不要列入solr数据提供的集群中,因为索引的创建有开销会影响效率,一旦master down机,有会部分连接到master机器上的用户无法正常查询。
2、slave从机可配置什么动作(如所以commit时),什么时间(如每隔10分钟),向master请求。然后经过比对版本号,索引大小,分发数据等操作后复制主机上的索引。solrcloud
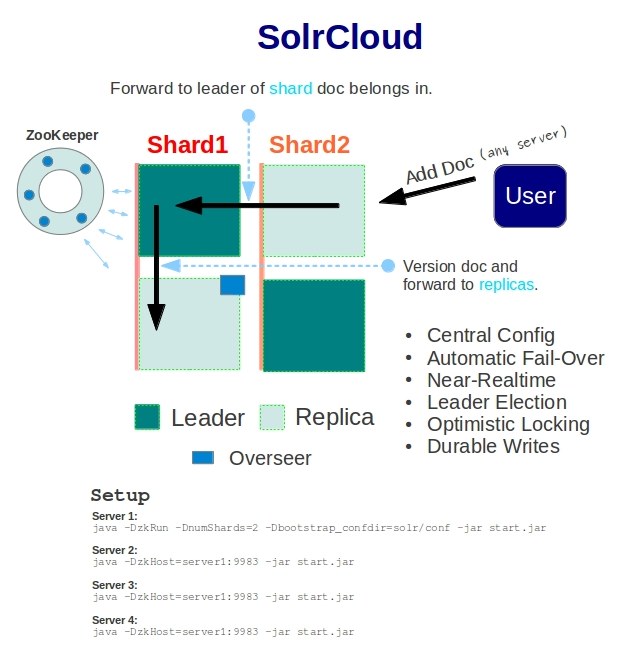
先说明几个关键的组件和概念
1、Cluster集群:Cluster是一组Solr节点,逻辑上作为一个单元进行管理,整个集群必须使用同一套schema和SolrConfig。
2、Node节点:一个运行Solr的JVM实例。
3、Collection:在SolrCloud集群中逻辑意义上的完整的索引,常常被划分为一个或多个Shard,这些Shard使用相同的Config Set,如果Shard数超过一个,那么索引方案就是分布式索引。SolrCloud允许客户端用户通过Collection名称引用它,这样用户不需要关心分布式检索时需要使用的和Shard相关参数。
4、Core: 也就是Solr Core,一个Solr中包含一个或者多个Solr Core,每个Solr Core可以独立提供索引和查询功能,Solr Core的提出是为了增加管理灵活性和共用资源。SolrCloud中使用的配置是在Zookeeper中的,而传统的Solr Core的配置文件是在磁盘上的配置目录中。
5、Config Set: Solr Core提供服务必须的一组配置文件,每个Config Set有一个名字。最小需要包括solrconfig.xml和schema.xml,除此之外,依据这两个文件的配置内容,可能还需要包含其它文件,如中文索引需要的词库文件。Config Set存储在Zookeeper中,可以重新上传或者使用upconfig命令进行更新,可使用Solr的启动参数bootstrap_confdir进行初始化或更新。
6、Shard分片: Collection的逻辑分片。每个Shard被分成一个或者多个replicas,通过选举确定哪个是Leader。
7、Replica: Shard的一个拷贝。每个Replica存在于Solr的一个Core中。换句话说一个SolrCore对应着一个Replica,如一个命名为“test”的collection以numShards=1创建,并且指定replicationFactor为2,这会产生2个replicas,也就是对应会有2个Core,分别存储在不同的机器或者Solr实例上,其中一个会被命名为test_shard1_replica1,另一个命名为test_shard1_replica2,它们中的一个会被选举为Leader。
8、 Leader: 赢得选举的Shard replicas,每个Shard有多个Replicas,这几个Replicas需要选举来确定一个Leader。选举可以发生在任何时间,但是通常他们仅在某个Solr实例发生故障时才会触发。当进行索引操作时,SolrCloud会将索引操作请求传到此Shard对应的leader,leader再分发它们到全部Shard的replicas。
9、Zookeeper: Zookeeper提供分布式锁功能,这对SolrCloud是必须的,主要负责处理Leader的选举。Solr可以以内嵌的Zookeeper运行,也可以使用独立的Zookeeper,并且Solr官方建议最好有3个以上的主机。
这里总结几个比较重要的
1、集中管理配置文件
实际上就是将solrconfig.xml、schema.xml等配置文件交给zookeeper管理,统一配置
2、自动容错
动态选举leader,会通过watcher探测集群上的机器是否发生故障,如果发生故障那么在创建索引或者查询数据的时候就会跳过故障机器,如果是leader机器发生故障,会推举一个新的机器
3、NRT(near real time)近实时搜索
实际上就solr提供了软提交(autoSoftCommit),将索引先提交到内存,index可见,用户可以查询到索引内容,但是并没有提交到硬盘上,显而易见如果机房停电,那么这部分索引就会消失。实时是相对的,主要还是要根据业务和索引的数据量来正确使用。
一般的配置如下:
// 配置每隔5分钟硬提交
<autoCommit>
<maxTime>$solr.autoCommit.maxTime:300000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
// 配置每隔一秒中软提交
<autoSoftCommit>
<maxTime>$solr.autoSoftCommit.maxTime:1000</maxTime>
</autoSoftCommit>4、扩容更加方便
solrcloud支持webapi方式
collection api
准备环境
这里以windows下发布为例,linux系统下发布网上教程很多,一步步跟着发布即可
zookeeper zookeeper-3.4.11
发布单机的tomcat见之前的文章即可
搭建solrCloud
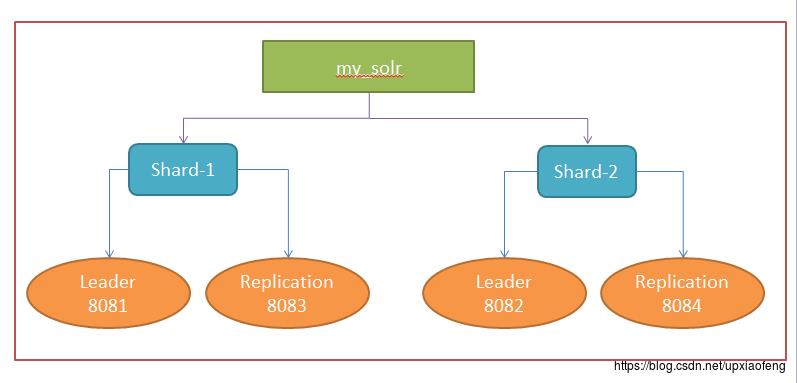
- 整体solrcloud结构
- zookeeper配置
解压后文件如下
将conf下的zoo_sample.cfg改名为zoo.cfg,修改其中的dataDir为刚刚新建的data文件夹,注意这里的路径是正斜杠,和windows默认的不一样

- tomcat配置
注:因为我这里是在同一台机器中搭建solrcloud,准备了4个tomcat,同时运行的时候需要配置不同的端口,修改其server.xml即可,这里不多赘述
这里我们选端口为8081的tomcat作为leader,配置其初始化启动操作。在tomcat的bin文件夹下找到catalina.bat文件设置运行参数
set
JAVA_OPTS=-Dbootstrap_confdir=D:\\solr\\server\\solrhome-8081\\my_solr\\conf
-Dcollection.configName=clusterconf -DzkRun -DzkHost=localhost:2181 -DnumShards=2
1、Dbootstrap_confdir ZooKeeper需要准备一份集群配置的副本,这个参数是告诉SolrCloud这些配置是放在哪里,同时作为整个集群共用的配置文件。
2、Dcollection.configName 指定你的配置文件上传到zookeeper后的名字
3、DzkRun 在Solr中启动一个内嵌的zooKeeper服务器,该服务会管理集群的相关配置。
4、DzkHost 跟上面参数的含义一样,允许配置一个ip和端口来指定用哪个Zookeeper服务器进行协调。
5、DnumShards=2 配置分片的个数,实际就是降索引分别存储到多少个分片中
其他三个tomcat(8082 、8083、8084)的catalina.bat配置如下:
set JAVA_OPTS=-DzkRun -DzkHost=localhost:2181 -DnumShards=2
- web.xml配置
分别修改solr项目的web.xml指定solrhome的路径,这里以8081为例
<!-- 配置solr home位置 -->
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:\\solr\\server\\solrhome-8081</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>- solr.xml配置
这里以8081为例截取其中,其他参考配置
<!-- 结合zookeeper配置solrColound start -->
<solrcloud>
<str name="host">$host:localhost</str>
<int name="hostPort">$port:8081</int>
<str name="hostContext">$hostContext:solr</str>
<bool name="genericCoreNodeNames">$genericCoreNodeNames:true</bool>
<int name="zkClientTimeout">$zkClientTimeout:30000</int>
<int name="distribUpdateSoTimeout">$distribUpdateSoTimeout:600000</int>
<int name="distribUpdateConnTimeout">$distribUpdateConnTimeout:60000</int>
</solrcloud>
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">$socketTimeout:600000</int>
<int name="connTimeout">$connTimeout:60000</int>
</shardHandlerFactory>
<!-- 结合zookeeper配置solrColound end -->项目文件整体结构
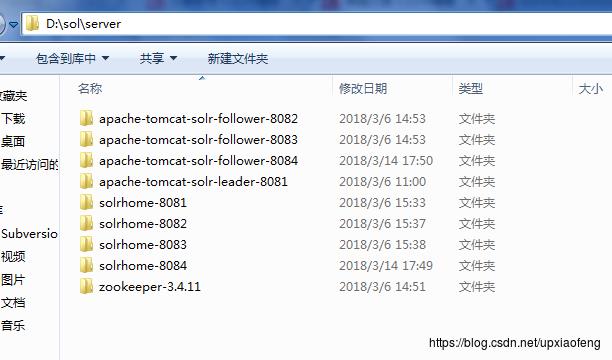
- 运行
运行zookeeper
.\\zookeeper-3.4.11\\bin下的zkServer.cmd
访问8081或者任意一个发布的solr,进入如下界面
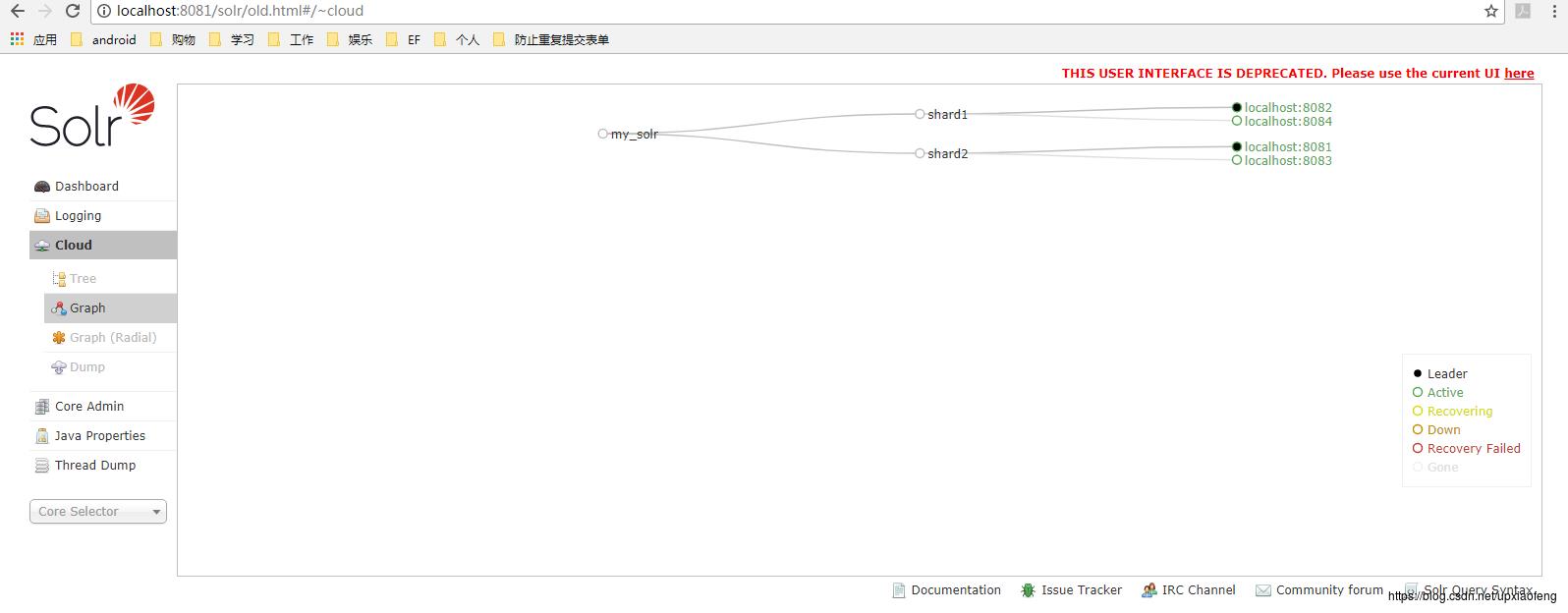
可以看到,已经产生两个分片,并且8081和8082分别为两个分片的leader
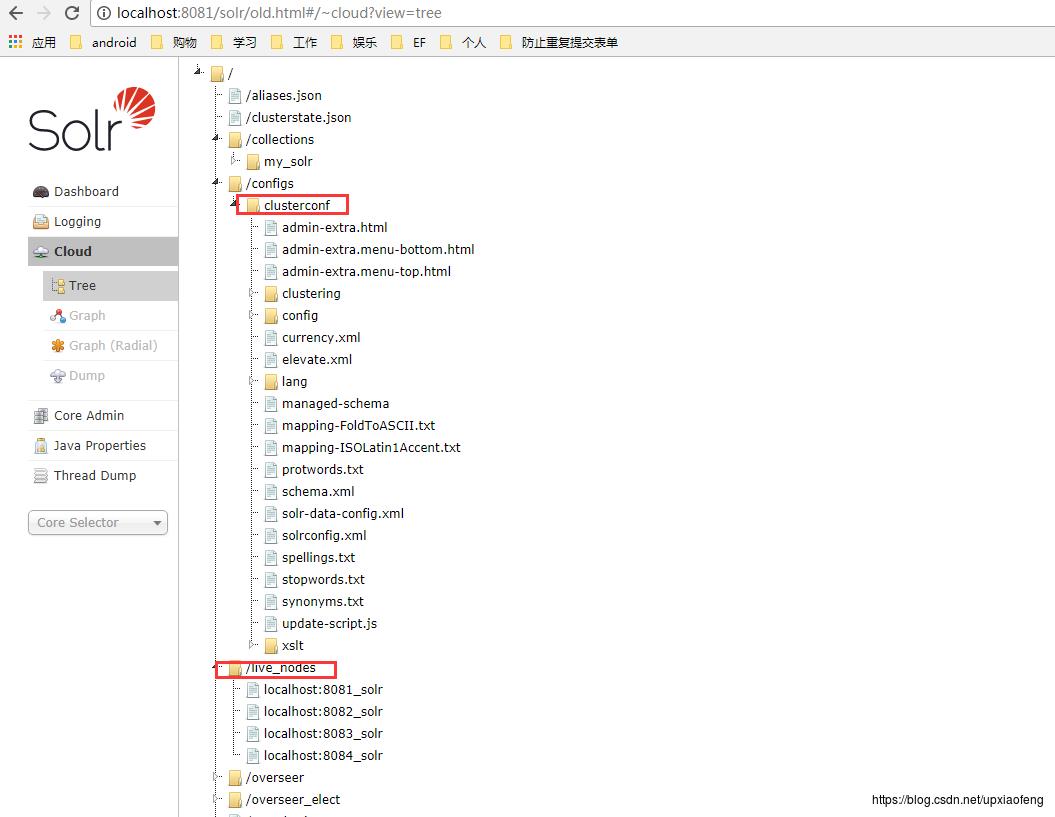
查看由zookeeper帮我们统一管理的文件,可以看到存活的节点、当前所有collection,以及我们交给zookeeper管理的clusterconf文件(这个文件夹的名称实际上对应之前我们配置JVM系统参数给zookeeper管理文件副本的名称)
solrcloud如何创建索引
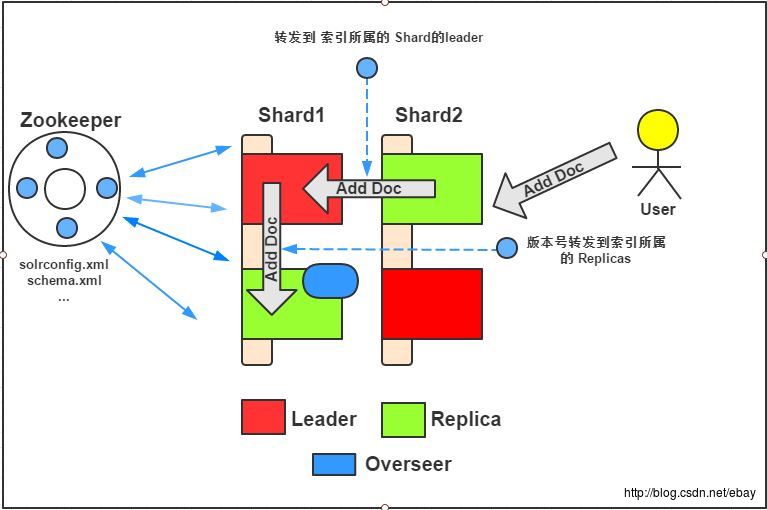
如图中所示,当我们添加索引到solrcloud中时,关键在于我们的索引最终写入哪里,如何写入的。
搭建好的solrcloud,每个shard对应着一个hash区间,以本文中的搭建为例。
shard-1对应的hash区间为0-7fffffff shard-2对应的hash区间为80000000-ffffffff,那么solrcloud会根据添加索引数据doc的唯一标识ID算出一个hash值,那么就可以确认这个索引应该分布在那个shard上。
SolrCloud对于Hash值的获取提出了以下两个要求:
1、hash计算速度必须快,因为hash计算是分布式建索引的第一步。
2、hash值必须能均匀的分布于每一个shard,如果有一个shard的document数量大于另一个shard,那么在查询的时候前一个shard所花的时间就会大于后一个,SolrCloud的查询是先分后汇总的过程,也就是说最后每一个shard查询完毕才算完毕,所以SolrCloud的查询速度是由最慢的shard的查询速度决定的。
基于以上两点,SolrCloud采用了MurmurHash 算法以提高hash计算速度和hash值的均匀分布。
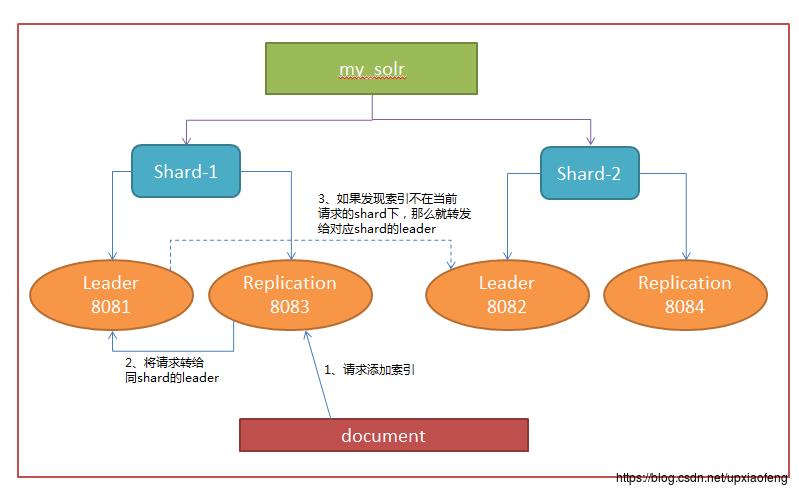
- 这里我总结步骤为3个
1、任意replica接收到一个索引数据添加请求
2、将这个请求转给同shard的leader
3、如果索引的请求不在当前shard的hash分布区间下,那么就会将请求转发到对应的shard下
注:这里省略的就是shard中leader和replica之间的路由
- 使用solrj添加索引
package com.yvan.solrcloud;
import java.io.IOException;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.apache.solr.client.solrj.response.UpdateResponse;
import org.apache.solr.common.SolrInputDocument;
/**
* CloudSolrClient 会在内部路由请求leader节点
* 这样避免开销
* @author yvan
*
* 2018年3月26日 下午6:23:27
*/
public class AppMain
@SuppressWarnings("resource")
public static void main(String[] args) throws SolrServerException, IOException
// CloudSolrClient添加索引
// 127.0.0.1:2181 为zookeeper的host
CloudSolrClient client = new CloudSolrClient("127.0.0.1:2181");
// 对应的collection名称,对应就是solr core
final String defaultCollection = "my_solr";
final int zkClientTimeout = 20000;
final int zkConnectTimeout = 1000;
System.out.println("The Cloud SolrServer Instance has benn created!");
client.setDefaultCollection(defaultCollection);
client.setZkClientTimeout(zkClientTimeout);
client.setZkConnectTimeout(zkConnectTimeout);
client.connect();
SolrInputDocument document = new SolrInputDocument();
document.addField("productcode", "123321");
UpdateResponse ur = client.add(document);
System.out.println(ur.getStatus()==0?"index add success":"index add fail");
client.commit();
solrcloud如何检索索引
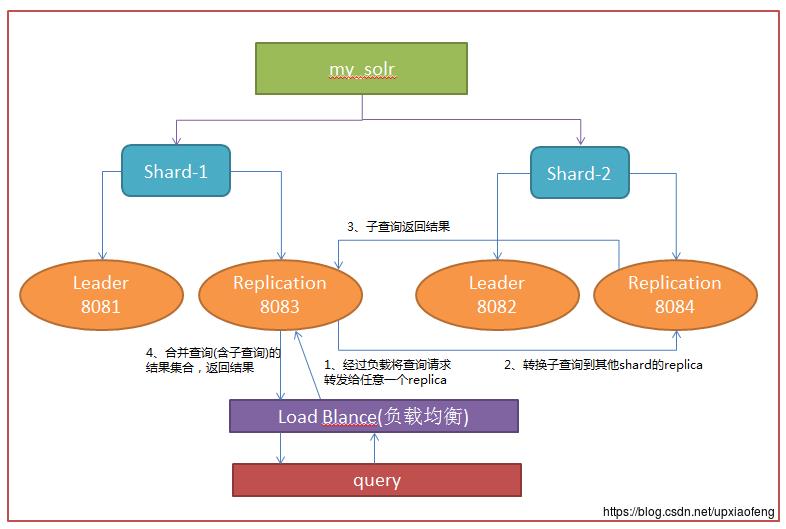
整个查询步骤分为:
1、索引查询请求路由到任意一个shard的replica中
2、replica会通过查找路由信息,建立和其他shard replica之间的子查询
3、子查询返回查询结果
4、合并查询结果,并返回请求结果
刚刚我们添加了一个ID为’123321’的doc,现在我们搜索一下,打开debug模式
我们请求端口为8082的,发生能够查询到这个索引
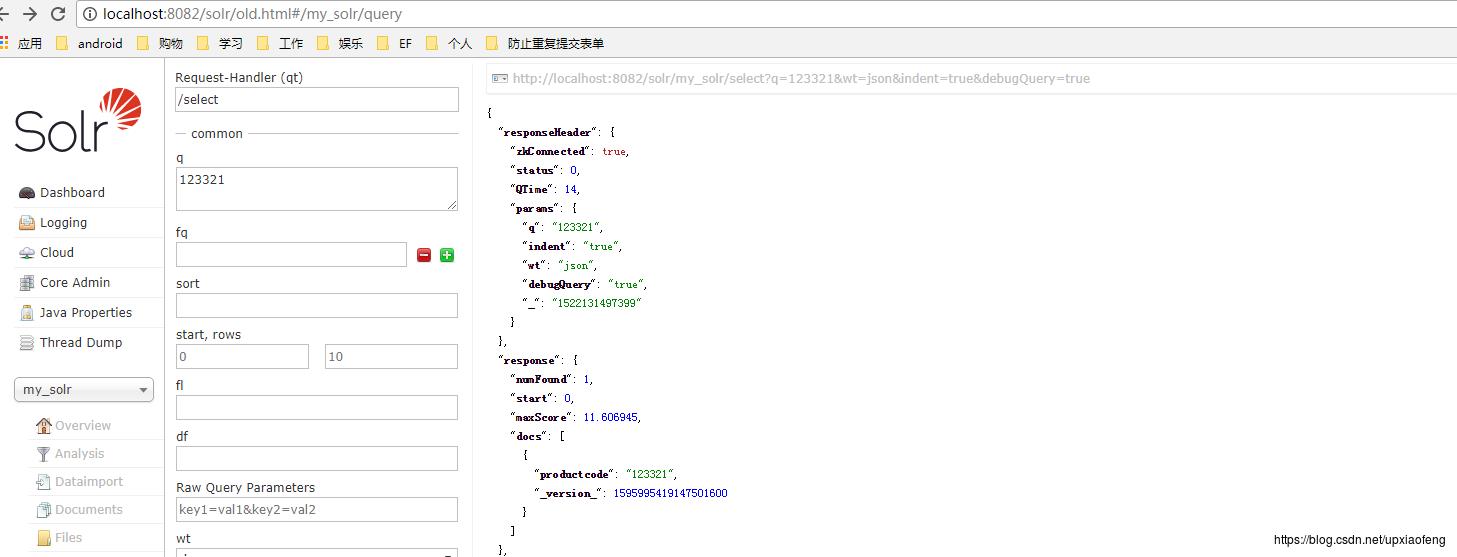
我们看下debug信息

可以看见EXECUTE_QUERY,说明两个shard都请求过,而实际上看 GET_FIELDS 是通过8081、8083这个所在的shard返回的,说明这个索引是分布在这个shard区间
如何管理zookeeper中的配置文件
上传文件:
1、通过配置-Dbootstrap_confdir参数设置启动时上传副本
2、通过configsets api 上传配置文件
3、通过调用CloudSolrClient.uploadConfig方法(不同的solrj版本方法可能不同)上传配置文件
4、org.apache.solr.cloud.ZkCLI 上传文件
java -classpath server/solr-webapp/webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -zkhost localhost:2181 -cmd upconfig -confname 上传到zookeeper上别名 -confdir 本地需要上传配置文件的路径
管理单个文件:
利用solr core中org.apache.solr.cloud.ZkCLI 执行putfile命令 windows 下替换文件 linux 下同理,只是改变一下路径
java -classpath
D:/solr/server/apache-tomcat-solr-leader-8081/webapps/solr/WEB-INF/lib/*
org.apache.solr.cloud.ZkCLI -zkhost localhost:2181 -cmd putfile
/configs/clusterconf/synonyms.txt C:/Users/yvan/Desktop/synonyms.txt
/configs/clusterconf/synonyms.txt // 为zookeeper内存数据中替换文件路径
C:/Users/yvan/Desktop/synonyms.txt //为本地文件路径
关于solrcloud的其他应用还在研究中,后续会结合工作过程中更新。
以上是关于Solr 6.0 学习(十七)SolrCloud的主要内容,如果未能解决你的问题,请参考以下文章