B+树索引是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了B+树索引是啥?相关的知识,希望对你有一定的参考价值。
什么是B+树索引?
有人可以帮忙解释解析下吗?
最好带图带下列子。。。。
B+ 树最大的几个特点:
1. 非叶子节点只保留 KEY,放弃 DATA;
2. KEY 和 DATA一起,在叶子节点,并且保存为一个有序链表(正序,反序,或者双向);
3. B+ 树的查找与 B 树不同,当某个结点的 KEY 与所查的 KEY 相等时,并不停止查找,而是沿着这个 KEY 左边的指针向下,一直查到该关键字所在的叶子结点为止。
MySQL:索引B+树和数据是啥关系?
MySQL(1):索引、B+树和数据是啥关系?
索引和数据的关系就是目录和具体的书页的关系,只是在搜索的时候起作用;这句话没有任何问题,但是看下一句话:每个索引在InnoDB里面对应一棵B+树,数据库的数据是存在B+树里面的?
这就糊涂了,一个索引对应一棵B+树,数据又存在B+树里面,那多建几个索引就要多建几棵树,那数据岂不是也要复制几份?并不会!!!
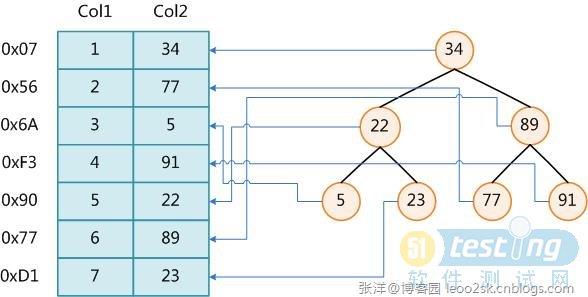
直接用大佬的图了,数据是在磁盘里面的可以说是死的,不会因为多几个索引就复制几份!!!
数据存在磁盘的一个文件里面——》ibd文件,ibd里面既有索引数据(飞叶子节点Page),也有具体的数据(叶子结点Page)。索引数据和具体数据一起组成了B+树,所以说数据存在B+树里面。
每一个Page里面有好多条数据(记录)。
ibd文件被分为连续的大小相同的区域,称为页(Page),大小默认值为16KB,可以设置。页的大小固定,格式固定。
多个Page在一起构成一颗多路平衡树, Page作为树的节点, 在平衡树的基础上, 同一层的节点左右相连, 所以称为B+树;
树中: 非叶子节点保存主键和子节点的位置, 叶子节点保存完整的记录;
mysql叶子结点存储的什么_B+树叶子结点到底存储了什么?
数据和主键索引是混合在一起存储的!每个表是一个ibd文件
总结
很关键的一点,数据是存在ibd文件里面的,和主键索引一起存,构成了B+树!InnoDB数据是存在B+树这一点没错,只不过是存在主键索引构成的B+树!
以上是关于B+树索引是啥?的主要内容,如果未能解决你的问题,请参考以下文章