Tachyon与Ignite系统对比
Posted ystu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tachyon与Ignite系统对比相关的知识,希望对你有一定的参考价值。
1. Alluxio(原Tachyon)内存文件系统
1.1 系统概述
Alluxio(原Tachyon)是以内存为中心(memory-centric)的虚拟的分布式存储系统,拥有高性能和容错能力,能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。Tachyon诞生于UC Berkeley的AMPLab,由该实验室的李浩源初创。2012年12月,Tachyon发布了第一个版本0.1.0。目前,Alluxio已发展为一个通用的分布式存储系统,将不同的计算框架和存储系统紧密联系起来。
自2013年4月开源以来,已有超过50个组织机构的200多位贡献者参与到Alluxio的开发中。其中包括阿里巴巴、百度、IBM、Intel、Red Hat、Yahoo、南京大学、卡内基梅隆大学和UC Berkeley。如图1所示。
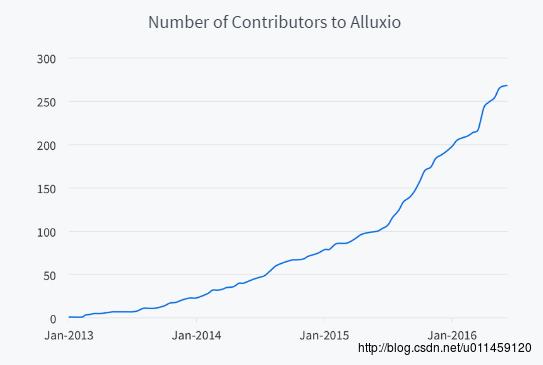
图1 Alluxio贡献者数量
Tachyon系统主要是为了解决以下3个方面的问题:
- 传统大数据分析流水线中通过磁盘文件系统(如HDFS)来共享数据成为影响分析性能的瓶颈;
- 大数据计算引擎的处理进程(Spark的Executor,MapReduce的Child JVM等)崩溃出错后,缓存的数据也会全部丢失;
- 基于内存的系统存储数据冗余,对象太多导致Java GC时间过长;
Tachyon针对以上几个方面问题给出了3个解决方法:
- Alluxio为大数据分析流水线提供内存级数据共享服务;
- 内存中的数据存放在Alluxio中,即使计算引擎处理进程崩溃,内存中的数据仍然不会丢失;
- 存放在Alluxio内存中的数据不会冗余,同时GC开销大大减小;
1.2 系统框架与原理
整体架构
与其他诸如HDFS、HBase、Spark等大数据相关框架一致,Alluxio也是一个主从结构的系统,如图2所示。它的主节点为Master,负责监控各个Worker以及管理全局的文件系统元数据,比如文件系统树等。而从节点为Worker,负责管理本节点数据存储服务(本地的MEM、SSD和HDD)。另外,Alluxio还有一个组件为Client,向用户和应用提供访问接口,以及向Master和Worker发送请求。Under File System主要负责文件的备份。
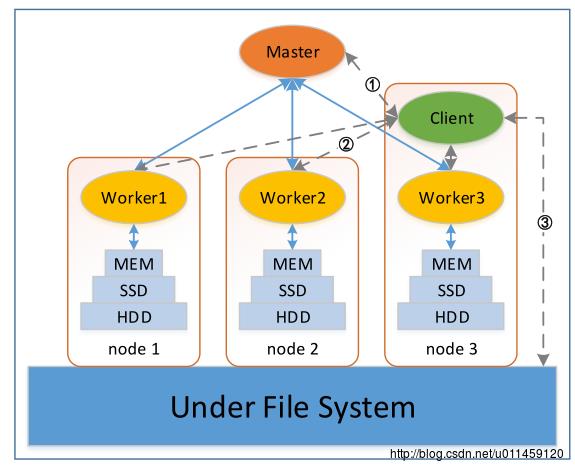
图2 整体架构
Master-Worker:定时心跳通信,管理系统状态。
Worker内部:利用Cache机制,将热数据置于MEM。
Alluxio-UFS:定期备份数据。
Client-Alluxio:Client从Master获得文件元数据信息,若文件数据在Alluxio中,从本地或远程Worker上读取,若文件不在Alluxio中,从UFS上读取。
文件组织
如图3所示,元数据为Inode Tree形式存储,文件和目录都为一个Inode节点。文件属性包括构成Inode的基本信息、块信息、备份信息,其中Inode基本信息包括id、名称、长度、创建/修改时间等。
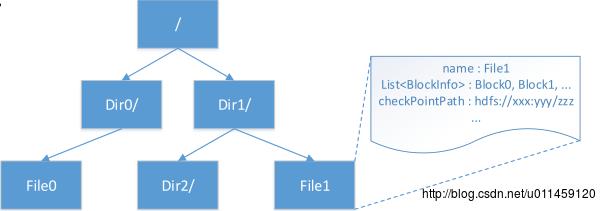
图3 Inode Tree
在Alluxio中,文件数据按块的形式组织,其中文件&块信息保存在Master中,块数据保存在Worker中。Worker中以块为粒度进行存储和管理,UFS以文件为粒度进行存储和管理。如图4,所示。

图4 文件存储
读写行为
Alluxio使用读写类型控制数据的存储层位置,ReadType控制读数据时行为,WriteType控制写数据时的行为。如表一所示。

表一 数据存储
Alluxio使用定位策略控制目标Worker,需要向Worker中写数据块时,决定使用哪个Worker。

表二 控制策略
容错机制
作为分布式文件系统,Tachyon具有良好的容错机制,Master和Worker都有自己的容错方式。Master支持使用ZooKeeper进行容错。同时,Master中保存的元数据使用Journal进行容错,具体包括Editlog—记录所有对元数据的操作,以及Image—持久化元数据信息。此外,Master还对各个Worker的状态进行监控,发现Worker失效时会自动重启对应的Worker。对于具体的文件数据,使用血统关系(Lineage)进行容错。文件元数据中记录了文件之间的依赖关系,当文件丢失时,能够根据依赖关系进行重计算来恢复文件数据。此外,还采用了Checkpoint。如图5所示。
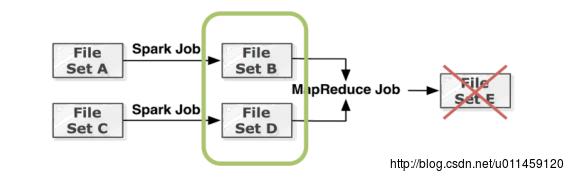
图5 Lineage
1.3 重要特性与使用场景
分层存储
由于内存大小有限,所以需要分层存储。这里有两个概念一个是StorageTier,是指存储层,对应存储介质,如内存、SSD、硬盘。另一个是StorageDir,数据块存放在Alluxio Worker的本地目录,通常对应一块磁盘设备,一个StorageTier包括一个或多个StorageDir。如图6所示。数据块管理分为Allocator和Evictor两种。其中Allocator,根据策略选择分配StorageDir里的空间,有GreedyAllocator、MaxFreeAllocator、RoundRobinAllocator。Evictor根据策略选择撤销StorageDir里的数据块,有GreedyEvictor、LRUEvictor、LRFUEvictor、PartialLRUEvictor。

图6 分层存储
接下来就是读写文件。先谈一下写文件,Client写一个数据块,首先申请x MB的空间,如果空闲空间小于x MB,则Evictor撤销内存中的部分数据块,然后Allocator选择一个存储目录分配x MB空间;否则空闲空间不小于x MB,则直接Allocator选择一个存储目录分配x MB空间。再说一下读文件,Client读一个数据块,如果读类型是CACHE_PROMOTE,首先将数据块从SSD或者HDD移动到MEM,然后再读取MEM中的数据块;否则读类型不是CACHE_PROMOTE,从存放该数据块的存储层直接读取数据。
Pining经常访问的文件在内存,永远不会被替换。Space reserver保留部分空闲空间,提升突发性写的性能。
分层存储使用场景:
第一,提升大部分应用的I/O性能,在充分利用内存的同时保证了存储容量,不同的分配/替换策略适用于不同的访问模式。
第二,充分利用多种存储设备,除内存外,也能利用SSD进行加速,使用多个存储层目录进行负载均衡。
更多底层存储系统
首先,Alluxio支持不同的底层存储,用于备份,例如GlusterFS、(secure) HDFS、NFS、Amazon S3、AliyunOSS、OpenStack Swift、Google Cloud Storage。其次,通用的接口,能够扩展更多底层存储系统,像UnderFileSystemFactory , UnderFileSystem。
底层存储系统的适用场景:
第一,对Alluxio中的重要数据进行备份,结合ASYNC_THROUGH的写类型,异步备份数据,既保证了性能,又提供了可靠性。
第二,将数据从原先基于磁盘的存储迁移至Alluxio,利用内存加速。
统一命名空间
Alluxio采用透明的命名机制,保证其和底层存储系统的命名空间是一致的,用户使用统一路径访问。此外,Alluxio采用统一命名空间,能够将多个数据源中的数据挂载到Alluxio中;多个数据源使用统一的命名空间;用户使用统一路径访问。
统一命名空间适用场景:
第一,将数据迁移至Alluxio中。将数据从原先基于磁盘的存储迁移至Alluxio,利用内存加速;在应用中使用统一路径访问Alluxio和底层存储系统。
第二,管理不同数据源中的数据。将数据从不同数据源迁移至Alluxio,利用内存加速;在应用中使用统一路径访问不同数据源中的数据;实现不同数据源之间的数据共享。
Alluxio-FUSE
在Linux的本地文件系统中,能够挂载Alluxio。利用Linux中的libfuse功能包,挂载为Linux本地文件系统中的一个目录。方便快捷的适用,就像使用本地文件系统一样,支持open、read、lseek、write。
Alluxio-FUSE适用场景:
第一,将传统并行计算迁移至Alluxio,利用内存加速,例如CephFS、Glusterfs、Lustre等。
第二,对单机应用使用多节点内存进行加速。
第三,为普通用户提供一个大容量的内存文件系统。
与计算框架相结合
使用Alluxio作为计算框架的存储系统,像Spark、Hadoop MapReduce、Flink、H2O、Impala等,不需要改动现有应用源代码,存储路径由“hdfs://ip:port/xxx”改为“alluxio://ip:port//xxx”即可。Zeppelin默认集成了Alluxio,使用Alluxio作为解释器。
与计算框架结合的适用场景:
第一,加速大数据应用,充分利用本地内存加速,原有应用能够直接使用Alluxio作为数据源,原有的数据能够被自动迁移至Alluxio中。
第二,在不同计算框架间共享数据,多个应用/平台使用统一的命名空间。
键值存储库
Alluxio还实现了键值(key-value)存储功能。创建一个键值存储库并且把键值对放入其中,键值对放入存储后是不可变的,键值存储库完整保存后,打开并使用该键值存储库。
API样例:
KeyValueSystemkvs = KeyValueSystem
.Factory().create();
KeyValueStoreWriter writer = kvs.createStore(
new AlluxioURI("alluxio://path/my-kvstore"));
writer.put("100", "foo");
writer.put("200", "bar");
writer.close();
KeyValueStoreReader reader = kvs.openStore(
new AlluxioURI("alluxio://path/kvstore/"));
reader.get("100");
reader.get(“300”); //null
reader.close();键值存储库适用场景:
第一, 提供结构化数据的存储,例如键值对结构、表结构、图结构。
第二,优化现有应用,以键值对方式存储中间结果,避免复杂的文件解析过程,为现有的键值应用提供更大的内存存储空间。
Web界面
Alluxio可以以可视化方式便于用户查看和管理。Master、Worker的基本运行状态和信息,Alluxio系统的配置信息,浏览文件系统,文件内容和文件块信息。使用浏览器打开,Master WebUI [http://:19999],Worker WebUI [http://:30000]。
Web界面适用场景:
第一,方便快捷的查看整个系统状态,运行状态,节点个数,系统版本等基本信息,整个容量使用情况,每个Worker的状态,容量使用等。
第二,浏览文件系统,快速查看文件/目录结构,预览文件内容,下载Alluxio文件到本地。
其他特性
命令行
文件系统API:
// 创建、写文件
FileSystem fs = FileSystem.Factory.get();
AlluxioURI path = new AlluxioURI("/myFile");
FileOutStream out = fs.createFile(path);
out.write(...);
out.close();
// 读文件:
FileSystem fs = FileSystem.Factory.get();
AlluxioURI path = new AlluxioURI("/myFile");
FileInStream in = fs.openFile(path);
in.read(...);
in.close();世系关系API
安全性配置设置
度量指标系统
1.4 实际应用案例
Barclays的应用需求:
数据来源:银行事务数据,存储在关系型数据库中
计算任务:批量处理某一时间段的数据,多个应用使用同一批数据
时间需求:日常应用,每天都要对前一天的数据进行分析
使用Spark进行计算:
并行的JDBC从数据库中读取数据,使用DataFrame格式进行计算和分析。数据读取过程称为瓶颈,将大规模的数据表从JDBC读入,转换成DataFrame耗时巨大,不同Spark任务间不能共享内存,每个应用都要从JDBC读一遍数据。
使用Alluxio(Tachyon)管理数据:
输入的大规模数据表存储在Alluxio中,所有应用共享,计算中产生的中间结果也存储在Alluxio中,Spark任务间共享。使用Alluxio对Spark任务本身进行加速。
示例:
// 将DataFrame存储到Alluxio
dataframe.write.save(“alluxio://master_ip:port/mydata/mydataframe.parquet”)
val dataframe : DataFrame =
sqlContext.read.load(“alluxio://master_ip:port/mydata/mydataframe.parquet”)
//将Spark RDD存储到Alluxio
rdd.saveAsObjectFile(“alluxio://master_ip:port/mydata/myrdd.object”)
val rdd : RDD[MyCaseClass] = sc.objectFile[MyCaseClass]
(“alluxio://master_ip:port/mydata/myrdd.object”)2. Apache Ignite内存文件系统
2.1 系统概述
Apache Ignite 内存数组组织框架是一个高性能、集成和分布式的内存计算和事务平台,用于大规模的数据集处理,比传统的基于磁盘或闪存的技术具有更高的性能,同时他还为应用和不同的数据源之间提供高性能、分布式内存中数据组织管理的功能。
Apache Ignite 的功能之一,就是分布式的内存文件系统(IGFS)。IGFS 与Hadoop HDFS 提供类似的功能,但是只是在内存而已。事实上,除了自己的 API,IGFS 实现了 HDFS 的 API,并且可以嵌入到 Hadoop 或 Spark 部署中。IGFS 把每个文件数据分成多个数据块,并存储到分布式内存缓存中。与 HDFS 不同的是,并不需要 NameNode 节点,而是使用 Hash 函数分发文件数据。IGFS 可以独立部署,也可以部署在 HDFS 之上,在这种情况下,它就变成了 HDFS 的缓存层。
- 代替Tachyon
在Spark部署中,IGFS可以很容易的替代Tachyon文件系统。鉴于IGFS基于底层Ignite数据网格技术,与Tachyon相比,在读写方面展示出了更好的优势,并且更加稳定。(来源官网的说法,具体性能没测) - Hadoop文件系统
如果你计划使用IGFS作为Hadoop文件系统,你必须视Hadoop为一个整体的文件。在这种情况下,使用IGFS与使用HDFS没有什么不同。 - Ignite文件系统特点
Ignite内存文件系统特点,如表三所示。
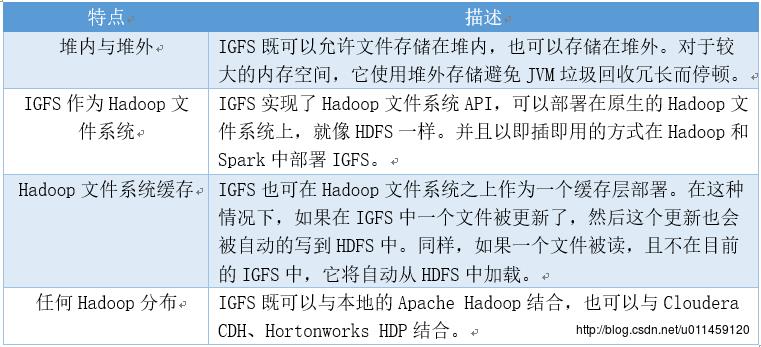
表三 Ignite特点
2.2 系统框架与原理
Apache Iginte是一个很完善的内存计算平台,由于研究需要,这里着重谈一下其内存文件系统。Ignite有一个独特的功能,叫做Ignite文件系统(IGFS),就是一个分布式的内存文件系统,IGFS提供了和Hadoop HDFS类似的功能,但是只在内存中。事实上,除了他自己的API,IGFS还实现了Hadoop的文件系统API,可以透明地加入Hadoop或者Spark的运行环境。
IGFS将每个文件的数据拆分成独立的数据块然后将他们保存进一个分布式内存缓存中。然而,与Hadoop HDFS不同,IGFS不需要一个name节点,它通过一个哈希函数自动确定文件数据的位置。
IGFS可以独立部署,也可以部署在HDFS之上,这时他成为了一个存储于HDFS中的文件的透明缓存层。如图7所示。
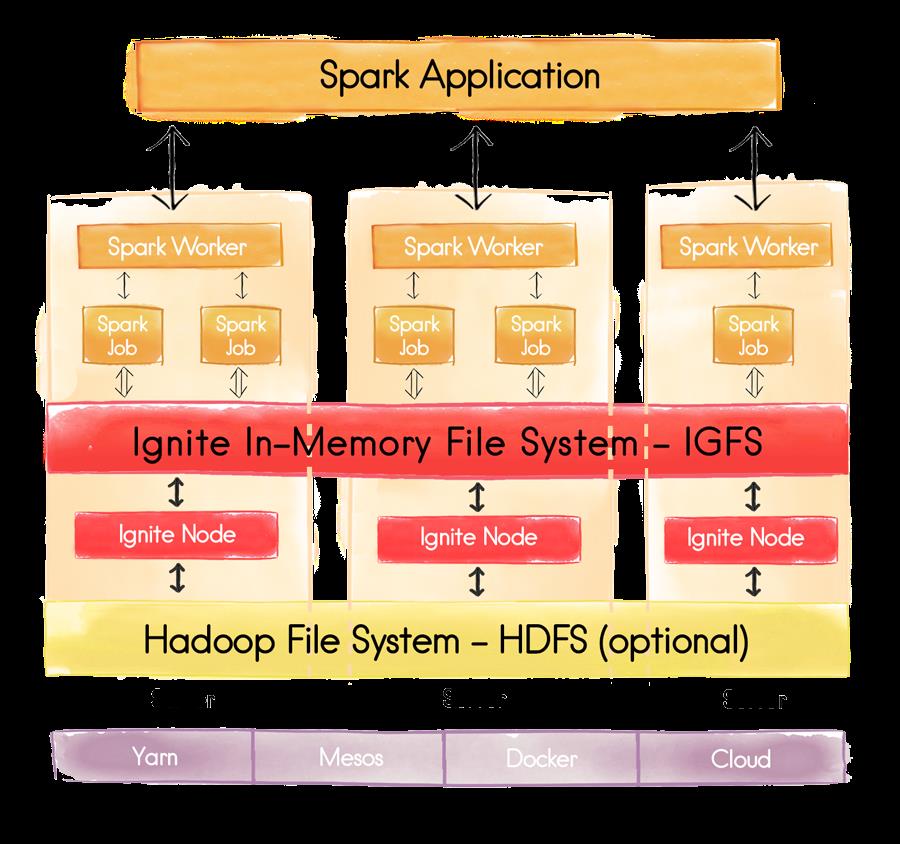
图7 IGFS架构
2.3 IGFS原生Ignite API
Ignite文件系统(IGFS)是一个内存级的文件系统,他可以在现有的缓存基础设施基础上对文件以及文件夹进行操作。
IGFS既可以作为一个纯粹的内存文件系统,也可以委托给其他的文件系统(比如各种Hadoop文件系统实现)作为一个缓存层。
另外,IGFS提供了在文件系统数据上执行MapReduce任务的API。
- IgniteFileSystem
IgniteFileSystem接口是一个进入Ignite文件系统实现的入口,他提供了正常的文件系统操作的方法,比如create,delete,mkdirs等等,以及执行MapReduce任务的方法。
Ignite ignite = Ignition.ignite();
// Obtain instance of IGFS named "myFileSystem".
IgniteFileSystem fs = ignite.fileSystem("myFileSystem");IGFS可以通过Spring XML文件或者编程的方式进行配置。
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="fileSystemConfiguration">
<list>
<bean class="org.apache.ignite.configuration.FileSystemConfiguration">
<!-- Distinguished file system name. -->
<property name="name" value="myFileSystem" />
<!-- Name of the cache where file system structure will be stored. Should be configured separately. -->
<property name="metaCacheName" value="myMetaCache" />
<!-- Name of the cache where file data will be stored. Should be configured separately. -->
<property name="dataCacheName" value="myDataCache" />
</bean>
</list>
</property>
</bean>Java:
IgniteConfiguration cfg = new IgniteConfiguration();
...
FileSystemConfiguration fileSystemCfg = new FileSystemConfiguration();
fileSystemCfg.setName("myFileSystem");
fileSystemCfg.setMetaCacheName("myMetaCache");
fileSystemCfg.setDataCacheName("myDataCache");
...
cfg.setFileSystemConfiguration(fileSystemCfg);- 文件以及目录操作
IgniteFileSystem fs = ignite.fileSystem("myFileSystem");
// Create directory.
IgfsPath dir = new IgfsPath("/myDir");
fs.mkdirs(dir);
// Create file and write some data to it.
IgfsPath file = new IgfsPath(dir, "myFile");
try (OutputStream out = fs.create(file, true))
out.write(...);
// Read from file.
try (InputStream in = fs.open(file))
in.read(...);
// Delete directory.
fs.delete(dir, true);2.4 IGFS作为Hadoop文件系统
Ignite Hadoop加速器提供了一个叫做IgniteHadoopFileSystem的Hadoop兼容IGFS实现,Hadoop可以以即插即用的形式运行在这个文件系统上,然后显著地减少了I/O和改善了延迟和吞吐量。如图8所示。
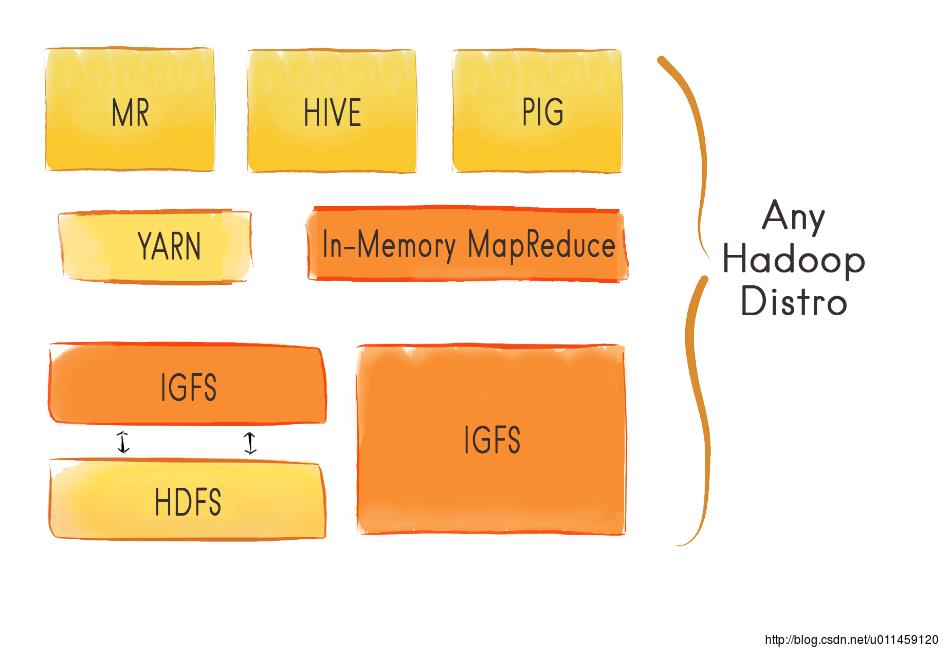
图8 Any Hadoop Distribution
- 配置Ignite
- 运行Ignite
- 配置Hadoop
- 运行Hadoop
- 文件系统URI
访问IGFS的URI具有如下的结构:igfs://[igfs_name@][host]:[port]/,这里:
- igfs_name:可选的要连接的IGFS的名字(通过FileSystemConfiguration.setName(…))指定的),必须以@结尾,如果忽略默认为空;
- host:可选的Ignite主机端点(IgfsIpcEndpointConfiguration.host),默认为127.0.0.1;
- port:可选的Ignite端口端点 (IgfsIpcEndpointConfiguration.port),默认为10500;
URI示例: - igfs://myIgfs@myHost:12345/:连接到运行在指定主机和端口上的名为myIgfs的IGFS;
- igfs://myIgfs@myHost/:连接到运行在指定主机和默认端口上的名为myIgfs的IGFS;
- igfs://myIgfs@/:连接到运行在localhost和默认端口上的名为myIgfs的IGFS;
- igfs://myIgfs@:12345/:连接到运行在localhost和指定端口上的名为myIgfs的IGFS;
- igfs://myHost:12345/:连接到运行在指定主机和端口上的名字为`null的IGFS;
- igfs://myHost/:连接到运行在指定主机和默认端口上的名字为null的IGFS;
- igfs://:12345/:连接到运行在localhost和指定端口上的名字为null的IGFS;
- igfs:///:连接到运行在localhost和默认端口上的名字为null的IGFS。
2.5 Hadoop文件系统缓存
Ignite Hadoop加速器包含了一个IGFS第二文件系统实现IgniteHadoopIgfsSecondaryFileSystem,它可以对任何Hadoop文件系统实现进行通读和通写。 要使用第二文件系统,可以在IGFS配置中指定或者通过编程的方式实现。
2.6 IGFS模式
IGFS可以工作于四种操作模式:PRIMARY,PROXY,DUAL_SYNC和DUAL_ASYNC。这些模式既可以配置整个文件系统,也可以配置特定的路径。他们是在IgfsMode枚举中定义的,默认文件系统操作于DUAL_ASYNC模式。
如果未配置第二文件系统,配置成DUAL_SYNC或者DUAL_ASYNC模式的所有路径都会回退到PRIMARY模式。
- PRIMARY模式 该模式中,IGFS作为基本的独立分布式内存文件系统,不会使用第二文件系统。
- PROXY模式
IGFS对于工作于PROXY模式的路径的操作是受限的,在这些路径上的任何操作都会抛出异常。 - DUAL_SYNC模式
该模式中,当数据被请求并且还没有缓存在内存中时,IGFS会在第二文件系统中进行同步地通读,当数据在IGFS中被更新/创建时对其进行同步地通写。实际上,该模式下IGFS是在第二文件系统之上作为一个智能缓存层的。 - DUAL_ASYNC模式
与DUAL_SYNC相同,但是对于第二文件系统的读写是异步方式执行的。在IGFS更新和第二文件系统更新之间存在一个滞后,但是这个模式下更新的性能显著好于DUAL_SYNC模式。
3. Tachyon与 IGFS对比
Apache Ignite是一个发展成熟的内存计算(IMC)平台。“支持Hadoop生态系统”只是结构的一个组成部分。其中内存文件系统(IGFS)已经比较成熟,支持多数底层文件系统也支持许多上层计算框架。而Alluxio(Tachyon)还比较年轻,在某些方面不是很成熟,有些底层系统和上层系统在当前版本中还不能支持,在性能方面和功能方面也不如IGFS做的好,比如文件的读写速度、以及系统的稳定性等等。因此说,Alluxio(Tachyon)还有许多有待完善的地方。
从内存文件系统的学习和开发角度来说,Alluxio(Tachyon)比IGFS有很大优势,主要有三个方面。第一,Alluxio(Tachyon)的开发者对Alluxio做了详细的描述,不仅涉及系统的原理,还涉及源码的结构,详细到每个类的功能,这样对一个新手来说,上手很容易,而IGFS在这方面就不如Alluxio;第二,Alluxio(Tachyon)系统目前还处于发正阶段,代码量不是特别大,可拓展性还强,可以根据自己的需求很容易去改进系统;第三,虽然IGFS的整个框架对很多底层和上层的都支持,但是IGFS有自己的一套内存计算平台,个人觉得在代码修改方面,工作量会远大于Tachyon系统。
最后,从使用者角度分析一下这两个系统。对上层应用来说IGFS的接口比较丰富,功能也比较强大,能够满足各种各样的用户的需求。但是如果针对OB这样的系统来说,这些强大的功能并没什么优势,反而会使系统性能有所影响,所以我认为应该开一个类似于Tachyon的系统,以内存为中心,提高访存速度,但在为了保证数据的不丢失,在磁盘备份,定期写盘。如果说要是单独做一个功能强大,支持很多应用IGFS是一个不错的选择,毕竟在很多方面,IGFS也已经做的很成熟。
4. 结论
通过使用和对比,发现Alluxio(Tachyon)和Apache Ignite各有千秋。在性能方面,毋庸置疑是Apache Ignite更具优势,在可拓展和改进方面,Alluxio(Tachyon)空间更大,可以根据具体应用和场景实施裁剪,实现更高的性能。
以上是关于Tachyon与Ignite系统对比的主要内容,如果未能解决你的问题,请参考以下文章