简易的站内搜索引擎 (万字长文!!绝对值得一看!!)
Posted S for N
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简易的站内搜索引擎 (万字长文!!绝对值得一看!!)相关的知识,希望对你有一定的参考价值。
搜索引擎的实现
项目简介
这里所实现的并非如同百度、谷歌一样的全网搜索,我们的硬件条件达不到,并且技术实力也不够,但是我们可以按照搜索引擎的基本原理,来实现一个站内搜索,实现原理也算是大同小异,此项目分为四个模块:预处理模块、索引模块、搜索模块、服务器模块

项目背景
想要写一个搜索引擎也是源于偶然,在知乎上看到一篇文章,说是百度搜索为什么可以那么快?回答里说了很多方面的技术,其中最核心的就是倒排索引,这让我产生了浓厚的兴趣,但是因为实力和设备都有欠缺,没法做一个像是百度和搜狗一样的全网搜索,但我可以做一个站内搜索,来理解相应的技术。
项目开始前
虽然我们要实现的是站内搜索,但是与全网搜索大同小异,那么我们可以看一看搜索应该要包含什么

我们可以看到当我们在上面的文本框输入关键字之后点击搜索,在下面会显示出许多具有相关性的搜索结果,而这些搜索结果中至少需要包含以下四个部分:
标题
描述(网页正文摘要出一部分)
展示url
点击url,点击标题会跳转到另外一个url中
因此我们可以仿照百度的方式,来实现我们的搜索引擎
开始前的准备
httplib
g++版本必须得是4.9以上
jieba分词的库
用这个库的时候直接用include是不够的,需要将deps目录下的limonp也拷贝到include目录下
boost: yum install boost-devel.x86_64
jsoncpp: yum install jsoncpp-devel.x86_64
创建这样的一个目录结构
四个模块
预处理模块
这里就要提一下我为什么会选择boost网站来实现站内搜索了,
- 我们暂时无法实现一个全网搜索,只能完成站内搜索
- boost官方文档没有一个搜索功能,但是boost文档很常用,没有搜索功能比较麻烦
- boost文档提供了两个版本,
离线版本,在线版本
boost提供了离线版本,那么我们就可以基于离线版本,分析文档页面的内容,为搜索功能提供支持。点击搜索结果的标题的时候,就能够跳转到在线版本的文档上,而如果网站内容无法直接下载,就必须使用爬虫来抓取页面到本地。
我为什么选择1.53版本的boost呢?其实主要是因为我用的Linux版本是contos7,它默认就是1.53
那么我们现在得到了boost文档的离线版本之后需要干什么呢?
我们下载下来的boost文档,其实就是一个个的html,而这些html里面是有很多内容和标签混合在一起的,而我们需要的只是其中的标题,正文,url,而我们预处理阶段所要做的就是读取原始的html文档内容,提取我们所要的,整理成一个行文本,以供下面的模块使用
接下来我们就开始写预处理模块的代码了
首先我们需要定义两个变量来表示从哪里读数据和要把最后生成的行文本放到哪个路径下面展示一些 内联代码片。
这个变量表示从哪个目录中读取boost文档的html
string g_input_path ="../data/input";
这个变量表示预处理模块输出结果放到哪里
string g_output_path ="../data/tmp/raw_input";
我们还需要一个结构体,来表示一个个的html
struct DocInfo
string title;//文档的标题
string url;//文档的url
string content;//文档的正文
;
既然我们要将所有的html都解析成行文件,那么我们首要做的就是将所下载的所有html都枚举加载进来,那么我们就可以封装一个函数
bool EnumFile(const string &input_path, vector<string> *file_list)
其中input_path为输入参数,file_list是输出参数,将上面定义的输入变量传进来,然后将所有的html都枚举到输出参数file_list中。我们的枚举过程中是会遇到目录的,而我们只要枚举html,C++的标准库中没有能做到这个的,但是boost库中可以。
//把boost::filesystem这个命名空间定义一个别名
39 namespace fs = boost::filesystem;
40 fs::path root_path(input_path);
41 if(!fs::exists(root_path))
42 std::cout << "当前的目录不存在" << std::endl;
43
44
45 //递归目录迭代器,迭代器使用循环实现的时候可以自动完成递归
46
47 fs::recursive_directory_iterator end_iter;
48 for(fs::recursive_directory_iterator begin_iter(root_path); begin_iter != end_iter; ++begin_iter)
49 //需要判定当前的路径对应的是不是一个普通文件
50 //如果是目录直接跳过
51 if(!fs::is_regular_file(*begin_iter))
52
53 continue;
54
55 //当前路径对应的文件是不是一个html文件,如果不是也跳过
56 if(begin_iter->path().extension() != ".html")
57 continue;
58
59
60 //把得到的html加入到最终结果的vector中
61 file_list->push_back(begin_iter->path().string());
接下来就是遍历vector里面的html了,打开每一个html,然后解析其中的内容,解析出标题、正文、url,对应我们之前创建好的结构体
找到标题
70 //找到html中的title标签
71 bool ParseTitle(const string& html, string *title)
72 size_t beg = html.find("<title>");
73 if(beg == string::npos)
74 std::cout << "标题未找到" << std::endl;
75 return false;
76
77 size_t end = html.find("</title>");
78 if(end == string::npos)
79 std::cout <<"标签未找到" <<std::endl;
80 return false;
81
82 beg += string("<title>").size();
83 if(beg >= end)
84 std::cout <<"标题位置不合法" <<std::endl;
85 return false;
86
87 *title = html.substr(beg, end-beg);
88 return true;
89
90
获取url
70 //找到html中的title标签
71 bool ParseTitle(const string& html, string *title)
72 size_t beg = html.find("<title>");
73 if(beg == string::npos)
74 std::cout << "标题未找到" << std::endl;
75 return false;
76
77 size_t end = html.find("</title>");
78 if(end == string::npos)
79 std::cout <<"标签未找到" <<std::endl;
80 return false;
81
82 beg += string("<title>").size();
83 if(beg >= end)
84 std::cout <<"标题位置不合法" <<std::endl;
85 return false;
86
87 *title = html.substr(beg, end-beg);
88 return true;
89
90
找到正文
101 //获取正文
102 bool ParseContent(const string& html, string* content)
103 //这里引入一个bool变量,当进入标签之后,此值为false
104 //判断这个变量就能知道是在标签内还是在标签外了
105 bool is_content = true;
106 for(auto c : html)
107 if(is_content)
108 //当前是正文
109 if(c == '<')
110 is_content = false;
111
112 else
113 //当前是普通字符,就把结果写入到content中
114 if(c == '\\n')
115 c = ' ';
116
117 content->push_back(c);
118
119
120 else
121 //当前是在标签内
122 if(c == '>')
123
124 //标签结束
125 is_content = true;
126
127 //标签里的其他内容都直接忽略掉
128
129
130 return true;
131
最后只需要将我们解析出来的结果写入到我们最开始设置好的输出文件中就可以了,不过要记得选择一个不可见分隔符对标题、正文、url进行分割!!不然会出现粘包问题!!
以上就是预处理模块的全部内容了,可以编译运行一下,看看输出文件中是否如愿解析出来了。
索引模块
现在我们已经有了解析好的行文本了,那么我们接下来就要进入索引模块了,索引模块是最核心的部分,在这个模块我们就要引入倒排索引了!!!
不管是站内搜索还是全网搜索,面对大量的数据,最核心的点就是效率,我们需要在大量的数据中,快速而准确的找出我们所要的数据,那么解决这个问题,最核心的就是倒排索引。
那么什么是倒排索引呢?
我们来看一个经典的例子,我所学习倒排索引的时候,就是看的这个例子

中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列所组成,然后对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。
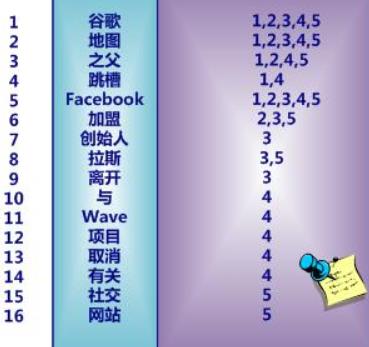
我们可以概括性的理解为:正排索引就是利用文档id来得到文本内容,倒排索引就是根据文本内容来得到文本id
那么我们的基本逻辑就是构建出正排索引,并且对字符串进行分词切割,然后切分出来的单词,再根据切分的单词和正排索引构建倒排索引,通过倒排索引找到对应的文档id,再通过文档id查找正排索引,从正排索引找到文档的内容。
因此我们现在要做的就是:构建正排索引,构建倒排索引,进行分词,查找倒排索引,查找正排索引
下面我们构建一下正排索引和倒排索引的基本结构体
23 struct DocInfo
24 int64_t doc_id;
25 string title;
26 string url;
27 string content;
28 ;
29
30 // 倒排索引是给定词, 映射到包含该词的文档 id 列表. (此处不光要有文档 id,
31 // 还得有权重信息, 以及该词的内容)
32 struct Weight
33 // 该词在哪个文档中出现
34 int64_t doc_id;
35 // 对应的权重是多少
36 int weight;
37 // 词是什么
38 string word;
39 ;
这就是我们需要做的所有操作
37 typedef vector<Weight> InvertedList;
38
39 // Index 类用于表示整个索引结构, 并且提供一些供外部调用的 API
40 class Index
41 private:
42 // 索引结构
43 // 正排索引, 数组下标就对应到 doc_id
44 vector<DocInfo> forward_index;
45 // 倒排索引, 使用一个 hash 表来表示这个映射关系
46 unordered_map<string, InvertedList> inverted_index;
47
48 public:
49 Index();
50 // 提供一些对外调用的函数
51 // 1. 查正排
52 const DocInfo* GetDocInfo(int64_t doc_id);
53 // 2. 查倒排
54 const InvertedList* GetInvertedList(const string& key);
55 // 3. 构建索引
56 bool Build(const string& input_path);
57 // 4. 分词函数
58 void CutWord(const string& input, vector<string>* output);
59
60 private:
61 DocInfo* BuildForward(const string& line);
62 void BuildInverted(const DocInfo& doc_info);
63
64 cppjieba::Jieba jieba;
65 ;
接下来就具体实现一下,咱们先挑简单的查正排和查倒排来实现一下
28 const DocInfo* Index::GetDocInfo(int64_t doc_id)
29 if (doc_id < 0 || doc_id >= forward_index.size())
30 return nullptr;
31
32 return &forward_index[doc_id];
33
34
35 const InvertedList* Index::GetInvertedList(const string& key)
36 auto it = inverted_index.find(key);
37 if (it == inverted_index.end())
38 return nullptr;
39
40 return &it->second;
41
这俩就是查找正排和倒排,查不到就返回nullptr,查到了就返回对应的指针即可
接下来要做的就是构建索引了
43 bool Index::Build(const string& input_path)
44 // 1. 按行读取输入文件内容(上个环节预处理模块生成的 raw_input 文件)
45 // 每一行又分成三个部分, 使用 \\3 来切分, 分别是标题, url, 正文
46 std::cerr << "开始构建索引" << std::endl;
47 std::ifstream file(input_path.c_str());
48 if (!file.is_open())
49 std::cout << "raw_input 文件打开失败" << std::endl;
50 return false;
51
52 string line;
53 while (std::getline(file, line))
54 // 2. 解析成 正排结构的DocInfo 对象, 并构造为正排索引
55 DocInfo* doc_info = BuildForward(line);
56 if (doc_info == nullptr)
57 std::cout << "构建正排失败!" << std::endl;
58 continue;
59
60 // 3.构造成倒排索引.
61 BuildInverted(*doc_info);
62
63 //此时需要知道进度是多少,但是如果每一个都进行打印
64 //每个数据都进行I/O操作的话过于影响效率
65 if (doc_info->doc_id % 100 == 0)
66 std::cerr << doc_info->doc_id << std::endl;
67
68
69 std::cerr << "结束构建索引" << std::endl;
70 file.close();
71 return true;
72
这是整体的构建思路,我们接下来就分别完成倒排索引和正排索引
=正排索引=
我们要做的核心操作: 按照 设定的分隔符 对 行文本 进行切分, 第一个部分就是标题, 第二个部分就是 url, 第三个部分就是正文,然后将这三个部分填充到正排索引对应的结构体中即可。
77 DocInfo* Index::BuildForward(const string& line)
78 // 1. 先把 line 按照 \\3 切分成 3 个部分
79 vector<string> tokens;
80 common::Util::Split(line, "\\3", &tokens);
81 if (tokens.size() != 3)
82 return nullptr;
83
84 // 2. 把切分结果填充到 DocInfo 对象中
85 DocInfo doc_info;
86 doc_info.doc_id = forward_index.size();
87 doc_info.title = tokens[0];
88 doc_info.url = tokens[1];
89 doc_info.content = tokens[2];
90 forward_index.push_back(std::move(doc_info));
91 return &forward_index.back();
92
这里的切分,在C++的标准库中并没有,但是boost库中是有的,因此我们用boost库中的split函数,不过这里我将split封装了一下,比boost库中的split函数少了一个参数,也就是boost::token_compress_on:将连续多个分隔符当一个,默认没有打开,当用的时候一般是要打开的。
boost:: token_compress_off:不会压缩分割结果,连续的分隔符时会返回 ""字符串
我默认选择了compress_off因为也许有的html中的字段是空的,那我们也不能将其压缩。
并且最后我选择了将doc_info转化成了右值(将亡值)进行了右值引用(效率就是一点点省出来的哦)
接下来就是构建倒排索引了,而我们构建倒排索引要做的首先就是构建正排和分词,现在正排已经构建完毕了,那我们就需要分词了,分词我们选择了cppjieba分词库来帮我们完成
147 void Index::CutWord(const string& input, vector<string>* output)
148 jieba.CutForSearch(input, *output);
149
那么我们现在终于可以开始期待已久的倒排索引了
97 void Index::BuildInverted(const DocInfo& doc_info)
98 // 创建专门用于统计词频的结构
99 struct WordCnt
100 int title_cnt;
101 int content_cnt;
102 WordCnt() : title_cnt(0), content_cnt(0)
103
104 ;
105 unordered_map<string, WordCnt> word_cnt_map;
106 // 针对标题进行分词
107 vector<string> title_token;
108 CutWord(doc_info.title, &title_token);
109 // 遍历分词结果, 统计每个词出现的次数
110 for (string word : title_token)
111 //将只是大小写不同的词当作同一个词来处理
112 //因此都转化成小写
113 boost::to_lower(word);
114 ++word_cnt_map[word].title_cnt;
115
116 // 针对正文进行分词
117 vector<string> content_token;
118 CutWord(doc_info.content, &content_token);
119 // 遍历分词结果, 统计每个词出现的次数
120 for (string word : content_token)
121 boost::to_lower(word);
122 ++word_cnt_map[word].content_cnt;
123
124 // 填充Weight对象
125 for