使用Redis解决高并发方案 以及 思路讲解
Posted WINGZINGLIU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Redis解决高并发方案 以及 思路讲解相关的知识,希望对你有一定的参考价值。
NoSQL
Not Only SQL的简称。NoSQL是解决传统的RDBMS在应对某些问题时比较乏力而提出的。
即非关系型数据库,它们不保证关系数据的ACID特性,数据之间一般没有关联,在扩展上就非常容易实现,并且拥有较高的性能。
Redis
redis是nosql的典型代表,也是目前互联网公司的必用技术。
redis是键值(Key-Value)存储数据库,主要会使用到哈希表。大多数时候是直接以缓存的形式被使用,使得请求不直接访问到磁盘,所以效率方面是很不错的,完全能满足中小型企业的使用需求。
常用数据类型
- 字符串string
- 散列hash
- 列表list
- 集合sets
- 有序集合sort set
使用频率上string和hash会高一些,各个类型有各自的操作命令,无非增删改查,具体的命令后面我会整理一份。
痛点
web应用在众多请求同时发生时,可能会导致数据读取、存储上出现错误,即发生脏读、脏数据生成。
在分布式项目下,会出现更多的问题。
思路
并发时,本质其实就是多个请求同时进来了,没办法正确的去进行处理。
可以将所有的请求放在 一个队列,让请求们按照一个顺序,挨个进来执行业务逻辑。目前成熟的解决方案就是使用消息队列,下次我会整理一篇消息队列处理高并发的;
还有一个方法是直接将并行转为串行,Java提供了synchronized,即同步,不过这个在效率要求比较苛刻的地方 或者 分布式项目下还是不太合适的方案,这里就引出了使用redis来实现分布式锁,从而解决并发问题。
分布式锁
在分布式项目中,使用一个唯一、通用、效率高的标识,来表示上锁和解锁。
redis实现起来很简单,即对一个key是否存在来表示是否上锁、是否解锁。
以string类型举例:
Integer stock = goodsMapper.getStock();
if (stock > 0)
stock =- 1;
goodsMapper.updateStock(stock);
以上是最简单的秒杀伪代码,我们尝试用redis实现分布式锁。
// 这里是错误代码,只是一个思考过程,请耐心看完哦
String key = "REDIS_DISTRIBUTION_LOCKER"; // 分布式锁名称
String value = jedisUtils.get(key);
if (value != null) // 未上锁
// wingzingliu
jedisUtils.set(key, 1); // 上锁
Integer stock = goodsMapper.getStock();
if (stock > 0)
stock =- 1;
goodsMapper.updateStock(stock);
jedisUtils.del(key); // 释放锁
以上代码可能会出现一个问题,就是当同时多个请求进来,某次多个请求都拿到value为空,线程A进入if 走到// wingzingliu这里的时候,还未上锁,其他请求也进来了,这样就会出现脏数据了。
这里的代码问题就是出在没有考虑原子性问题。
所以我们要使用到redis的一个setNx命令,本质也是设置值,但是这是一个原子操作,执行之后会返回是否设置成功。
redis> SETNX job "programmer" # job 设置成功
(integer) 1
redis> SETNX job "code-farmer" # 尝试覆盖 job ,失败
(integer) 0
redis> GET job # 没有被覆盖
"programmer"重点关注 当有值时,会失败,返回0。所以我们的代码会改造成以下这个样子。
// 这里是错误代码,只是一个思考过程,请耐心看完哦
String key = "REDIS_DISTRIBUTION_LOCKER"; // 分布式锁名称
Long result = jedisUtils.setNx(key, 1);
if (result > 0) // 上锁成功,进入逻辑
// wingzingliu1
Integer stock = goodsMapper.getStock();
if (stock > 0)
stock =- 1;
goodsMapper.updateStock(stock);
System.out.println("购买成功!");
else
System.out.println("没有库存了!");
// wingzingliu2
jedisUtils.del(key); // 释放锁
以上我们就可以保证原子性,能正确的按照顺序去处理。
可是还有一个隐藏的问题,就是当某个线程执行上锁成功后,在wingzingliu1到wingzingliu2之间时,程序抛异常了,那么程序终止了,就无法释放锁,其他线程也都进不来了。
解决方案是加上try catch finally块,在finally里面去释放锁。
可是那如果是宕机呢?上锁之后宕机了,finally里面的依然不会执行,锁没有得到释放,不手动处理的情况下,以后所有线程也无法进入。
所以引入了redis的过期时间,到了某个时间自动解锁。
// 这里是不够完善的代码,请耐心看完哦
try
String key = "REDIS_DISTRIBUTION_LOCKER"; // 分布式锁名称
Long result = jedisUtils.setNx(key, 1, 30); // 假设处理逻辑需要20s左右,设置了30秒自动过期
if (result > 0) // 上锁成功,进入逻辑
Integer stock = goodsMapper.getStock();
if (stock > 0)
stock =- 1;
goodsMapper.updateStock(stock);
System.out.println("购买成功!");
else
System.out.println("没有库存了!");
catch (Exception e)
finally
jedisUtils.del(key); // 释放锁
以上是比较完善的分布式锁了,但是还有一个小瑕疵,就是假设某一次请求A处理的很慢,预计20s但是跑了35s,到了30s的时候锁过期了,其他请求就自然进来了。
这不仅仅会导致一次并行,当请求A处理完时,依然会执行释放锁,这实际上是下一个线程上的锁。以此类推,整个并发控制就乱了。
理论上可以设置一个更大的key过期时间,但是并不是最好的解决方案。这里就引出一个概念:锁续命。
锁续命
如其名,给锁续命。实现就是 当锁快过期的时候,去延长锁的时间。假设一个30s的锁,每个10s去检测一下,锁是否还在 如果在就重新延长至30s。这样就避免掉了上面的这个可能出现的问题。
这里使用一个定时任务,周期性的调用即可。
扩展
刚刚对key设置的value是1,其实能使用请求ID来进行保存,这样就能知道锁是由哪个请求上的,在解锁的时候 也可以避免解锁了其他线程上的锁。具体由前端传递,或者由服务端以某种规则生成都可以。
结语
至此我们就使用redis,一步一步的解决了在分布式项目下的并发问题。redis不是唯一的解决方案,但是对于大部分互联网公司来说,是一个很成熟、性能不错、便捷的方案。
还可以使用synchronized(非分布式项目)、mq 、zookeeper等方案去实现分布式锁 以 解决高并发问题。
高并发架构系列:Redis并发竞争key的解决方案详解
需求由来
1.Redis高并发的问题
Redis缓存的高性能有目共睹,应用的场景也是非常广泛,但是在高并发的场景下,也会出现问题:缓存击穿、缓存雪崩、缓存和数据一致性,以及今天要谈到的缓存并发竞争。
这里的并发指的是多个redis的client同时set key引起的并发问题。
2.出现并发设置Key的原因
Redis是一种单线程机制的nosql数据库,基于key-value,数据可持久化落盘。由于单线程所以Redis本身并没有锁的概念,多个客户端连接并不存在竞争关系,但是利用jedis等客户端对Redis进行并发访问时会出现问题。
比如:同时有多个子系统去set一个key。这个时候要注意什么呢?
3.举一个例子
多客户端同时并发写一个key,一个key的值是1,本来按顺序修改为2,3,4,最后是4,但是顺序变成了4,3,2,最后变成了2。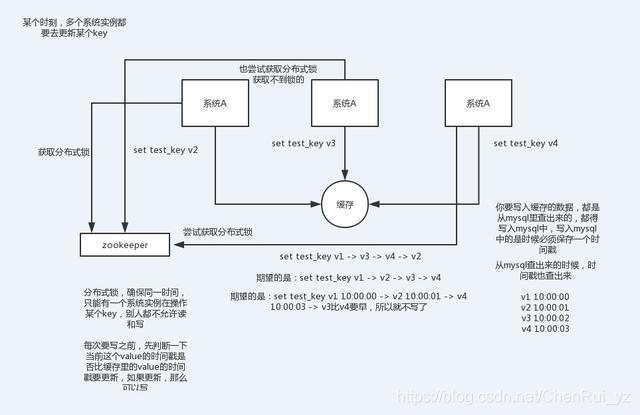
如何解决redis的并发竞争key问题呢?下面给到2个Redis并发竞争的解决方案。
第一种方案:分布式锁+时间戳
1.整体技术方案
这种情况,主要是准备一个分布式锁,大家去抢锁,抢到锁就做set操作。
加锁的目的实际上就是把并行读写改成串行读写的方式,从而来避免资源竞争。
2.Redis分布式锁的实现
主要用到的redis函数是setnx()
用SETNX实现分布式锁
利用SETNX非常简单地实现分布式锁。例如:某客户端要获得一个名字youzhi的锁,客户端使用下面的命令进行获取:
SETNX lock.youzhi<current Unix time + lock timeout + 1>
如返回1,则该客户端获得锁,把lock.youzhi的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
3.时间戳
由于上面举的例子,要求key的操作需要顺序执行,所以需要保存一个时间戳判断set顺序。
系统A key 1 ValueA 7:00
系统B key 1 ValueB 7:05
假设系统B先抢到锁,将key1设置为ValueB 7:05。接下来系统A抢到锁,发现自己的key1的时间戳早于缓存中的时间戳(7:00<7:05),那就不做set操作了。
4.什么是分布式锁
因为传统的加锁的做法(如java的synchronized和Lock)这里没用,只适合单点。因为这是分布式环境,需要的是分布式锁。
当然,分布式锁可以基于很多种方式实现,比如zookeeper、redis等,不管哪种方式实现,基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
第二种方案:利用消息队列
在并发量过大的情况下,可以通过消息中间件进行处理,把并行读写进行串行化。
把Redis.set操作放在队列中使其串行化,必须的一个一个执行。
这种方式在一些高并发的场景中算是一种通用的解决方案。
以上就是Redis并发竞争key技术方案详解,相关的Redis高并发问题具体还可以参考:高并发架构系列:如何解决Redis雪崩、穿透、并发等5大难题
参考:高并发架构系列:Redis并发竞争key的解决方案详解
以上是关于使用Redis解决高并发方案 以及 思路讲解的主要内容,如果未能解决你的问题,请参考以下文章