HDL4SE:软件工程师学习Verilog语言(十六)
Posted 饶先宏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDL4SE:软件工程师学习Verilog语言(十六)相关的知识,希望对你有一定的参考价值。
16 实用化的RISC-V CPU
前面我们在FPGA开发板上实现了一个RISC-V的CPU,可以跑工具链编译出来的应用。然而感觉没有实用性,本次我们对CPU的设计做一些总结性的讨论,然后对这个RISC-V的CPU核进行改造,减少它的指令执行周期,增加一个外部设备,提供一个交互式的软件,让它可以用在一些FPGA的应用项目中,作为FPGA项目调试或者配置的一个手段,通过提供一个终端软件来读写FPGA内部的存储器和寄存器状态,甚至可以来设置某些寄存器的值,对FPGA应用进行调试,总比用JTAG来调试得简单。
16.1 CPU设计的一些问题
CPU,或者外推一下,包括DSP,GPU以及一些专用芯片中的处理器,其实称之为可编程通用状态机,可能更加贴切一些,后面还是用CPU来指称了。CPU设计其实是非常宽带的一件事情,下面列出我所了解的一些问题:
- 指令集:指令集关乎到软件的效率,指令集背后有工具链支撑,所谓效率一方面是指单位芯片面积和单位能耗下的每周期指令数,这个比较好统计,另一方面是指完成应用需要的指令数,这个比较模糊,具体跟应用相关,大概可以这么理解,如果指令比较简单,那么完成同样的事情需要执行的指令数目就多一些,反而则少一些。指令简单时,实现起来要容易,每周期指令数就多一些。可以看出所谓指令集的效率,跟应用场合紧密相关,离开应用背景谈指令集的优劣是没有意义的,因此不同的应用中可能采用的指令集就很不同。
- 精简指令集(RISC)与复杂指令集(CISC):精简指令集是指指令比较简单,一条指令只做一个单一的计算,基本可以与编译器中生成的四元组<op, dst, s1, s2>对应起来,可以表达二元计算,LOAD/STORE, 分支等功能,一元计算甚至可以用二元计算来模拟,s1和s2中可能包括立即数,寻模式也简单,支持与PC相对偏移寻址,也支持基于用寄存器的偏移寻址,RISC-V就是一种精简指令集,精简指令集电路和工具链实现相对简单一些。复杂指令集中一条指令可以表达几个计算,比如可以在一条指令中包括LOAD/STORE功能,多个计算功能(比如多分量矢量计算,包括分量预处理及后期处理等)和分支(条件)功能,这样指令的运行效率会比较高,当然一条指令的长度也比较长,工具链和电路实现比较复杂,一般在专用的DSP或者GPU处理器中使用,其工具链需要做非常专业化的优化,才能发挥出指令集的优势。我们举个例子说明这个问题,比如数据处理过程中经常使用的乘累加计算代码:
#define LEN 1024
unsigned int coeff[LEN];
unsigned int buf[LEN];
static void testmad()
int i;
int total;
total = 0;
clear_all_counter();
for (i = 0; i < LEN; i++)
total += coeff[i] * buf[i];
stop_all_counter();
liststatus();
clear_all_counter();
其中我们用CSR来对各类指令进行计数,首先各个计数器清零,然后做一个乘累加计算,然后显示各个计数器的计数值。用RISC-V的工具链编译后,得到的代码是:
000014bc <testmad>:
14bc: fe010113 addi sp,sp,-32
14c0: 00112e23 sw ra,28(sp)
14c4: 00812c23 sw s0,24(sp)
14c8: 02010413 addi s0,sp,32
14cc: fe042423 sw zero,-24(s0)
14d0: df9ff0ef jal ra,12c8 <clear_all_counter>
14d4: fe042623 sw zero,-20(s0)
14d8: 0500006f j 1528 <testmad+0x6c>
14dc: 000037b7 lui a5,0x3
14e0: 50878713 addi a4,a5,1288 # 3508 <coeff>
14e4: fec42783 lw a5,-20(s0)
14e8: 00279793 slli a5,a5,0x2
14ec: 00f707b3 add a5,a4,a5
14f0: 0007a703 lw a4,0(a5)
14f4: 000047b7 lui a5,0x4
14f8: 50878693 addi a3,a5,1288 # 4508 <buf>
14fc: fec42783 lw a5,-20(s0)
1500: 00279793 slli a5,a5,0x2
1504: 00f687b3 add a5,a3,a5
1508: 0007a783 lw a5,0(a5)
150c: 02f70733 mul a4,a4,a5
1510: fe842783 lw a5,-24(s0)
1514: 00f707b3 add a5,a4,a5
1518: fef42423 sw a5,-24(s0)
151c: fec42783 lw a5,-20(s0)
1520: 00178793 addi a5,a5,1
1524: fef42623 sw a5,-20(s0)
1528: fec42703 lw a4,-20(s0)
152c: 3ff00793 li a5,1023
1530: fae7d6e3 bge a5,a4,14dc <testmad+0x20>
1534: dcdff0ef jal ra,1300 <stop_all_counter>
1538: e01ff0ef jal ra,1338 <liststatus>
153c: d8dff0ef jal ra,12c8 <clear_all_counter>
1540: 00000013 nop
1544: 01c12083 lw ra,28(sp)
1548: 01812403 lw s0,24(sp)
154c: 02010113 addi sp,sp,32
1550: 00008067 ret
其中的计算乘累加的循环,在14dc到1530之间,22条指令,只完成了一个乘累加计算。测试结果如下(每行两个数字,前一个是执行的指令数量,后一个是占的百分比,由于是整数运算,百分比不是很准确):
total : 23057, 102
add/sub : 3072, 13
mul : 1024, 4
div : 0, 0
ld : 7172, 31
st : 2053, 9
jmp : 3, 0
j : 1025, 4
alui : 6149, 27
alu : 4096, 18
可以看出,执行过程中27%的指令是用来计算各种数组寻址以及循环变量等,40%的指令在执行load/store,只有17%的指令在执行我们期望的乘累加计算。注意这个统计与CPU核的实现无关。如果是复杂指令集,比如DSP中,乘累加包括地址递增和load/store,都表达在一条指令中,因此执行效率会高很多。同样的主频,同样流水线实现方式下无限接近平均每周期一条指令,DSP的执行效率可以达到RISC-V的十倍以上,当然,CPU现在轻松可以设计到2GHz主频,DSP似乎主频很难上去,再加上CPU采用一些比如硬件多线程的处理,可以提高ALU单元的执行效率,所以综合的执行效率,还真是难说得很呐。
我们稍微修改一下源代码,不采用数组操作,情况要好点:
static void testmad()
int i;
int total;
unsigned int* pcoeff = coeff;
unsigned int* pbuf = buf;
total = 0;
clear_all_counter();
for (i = 0; i < LEN; i++)
total += *pcoeff++ * *pbuf++;
stop_all_counter();
liststatus();
clear_all_counter();
编译的结果是:
00001488 <testmad>:
1488: fe010113 addi sp,sp,-32
148c: 00112e23 sw ra,28(sp)
1490: 00812c23 sw s0,24(sp)
1494: 02010413 addi s0,sp,32
1498: 000037b7 lui a5,0x3
149c: 50878793 addi a5,a5,1288 # 3508 <coeff>
14a0: fef42223 sw a5,-28(s0)
14a4: 000047b7 lui a5,0x4
14a8: 50878793 addi a5,a5,1288 # 4508 <buf>
14ac: fef42023 sw a5,-32(s0)
14b0: fe042423 sw zero,-24(s0)
14b4: e15ff0ef jal ra,12c8 <clear_all_counter>
14b8: fe042623 sw zero,-20(s0)
14bc: 0400006f j 14fc <testmad+0x74>
14c0: fe442783 lw a5,-28(s0)
14c4: 00478713 addi a4,a5,4
14c8: fee42223 sw a4,-28(s0)
14cc: 0007a703 lw a4,0(a5)
14d0: fe042783 lw a5,-32(s0)
14d4: 00478693 addi a3,a5,4
14d8: fed42023 sw a3,-32(s0)
14dc: 0007a783 lw a5,0(a5)
14e0: 02f70733 mul a4,a4,a5
14e4: fe842783 lw a5,-24(s0)
14e8: 00f707b3 add a5,a4,a5
14ec: fef42423 sw a5,-24(s0)
14f0: fec42783 lw a5,-20(s0)
14f4: 00178793 addi a5,a5,1
14f8: fef42623 sw a5,-20(s0)
14fc: fec42703 lw a4,-20(s0)
1500: 3ff00793 li a5,1023
1504: fae7dee3 bge a5,a4,14c0 <testmad+0x38>
1508: df9ff0ef jal ra,1300 <stop_all_counter>
150c: e2dff0ef jal ra,1338 <liststatus>
1510: db9ff0ef jal ra,12c8 <clear_all_counter>
1514: 00000013 nop
1518: 01c12083 lw ra,28(sp)
151c: 01812403 lw s0,24(sp)
1520: 02010113 addi sp,sp,32
1524: 00008067 ret
主循环只有18条指令,效率提高了20%,执行后的统计结果如下:
total : 18452, 100
add/sub : 1024, 5
mul : 1024, 5
div : 0, 0
ld : 7172, 38
st : 4101, 22
jmp : 3, 0
j : 1025, 5
alui : 4101, 22
alu : 2048, 11
当然这可能与编译器相关,有汇编高手来试试看用汇编程序优化一下这个过程不看看能否提高效率,个人认为,不管如何优化,每个循环过程中,两个LD指令,一个ST指令,一个乘法指令,一个加法指令,还有循环控制的一个比较,一个跳转,一个循环参数递增,两个地址递增指令应该是必要的,这样一次乘累加计算也得有10条指令,汇编的效率能提高两倍。DSP高手做核心算法实现时,往往也时直接写汇编的。
用x86的gcc编译器编译的结果是:
0000000000401c55 <testmad>:
401c55: 55 push %rbp
401c56: 48 89 e5 mov %rsp,%rbp
401c59: 48 83 ec 20 sub $0x20,%rsp
401c5d: 48 c7 45 f0 40 51 40 movq $0x405140,-0x10(%rbp)
401c64: 00
401c65: 48 c7 45 e8 40 61 40 movq $0x406140,-0x18(%rbp)
401c6c: 00
401c6d: c7 45 f8 00 00 00 00 movl $0x0,-0x8(%rbp)
401c74: b8 00 00 00 00 mov $0x0,%eax
401c79: e8 e1 fe ff ff callq 401b5f <clear_all_counter>
401c7e: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
401c85: eb 2d jmp 401cb4 <testmad+0x5f>
401c87: 48 8b 45 f0 mov -0x10(%rbp),%rax
401c8b: 48 8d 50 04 lea 0x4(%rax),%rdx
401c8f: 48 89 55 f0 mov %rdx,-0x10(%rbp)
401c93: 8b 08 mov (%rax),%ecx
401c95: 48 8b 45 e8 mov -0x18(%rbp),%rax
401c99: 48 8d 50 04 lea 0x4(%rax),%rdx
401c9d: 48 89 55 e8 mov %rdx,-0x18(%rbp)
401ca1: 8b 00 mov (%rax),%eax
401ca3: 0f af c8 imul %eax,%ecx
401ca6: 89 ca mov %ecx,%edx
401ca8: 8b 45 f8 mov -0x8(%rbp),%eax
401cab: 01 d0 add %edx,%eax
401cad: 89 45 f8 mov %eax,-0x8(%rbp)
401cb0: 83 45 fc 01 addl $0x1,-0x4(%rbp)
401cb4: 81 7d fc ff 03 00 00 cmpl $0x3ff,-0x4(%rbp)
401cbb: 7e ca jle 401c87 <testmad+0x32>
401cbd: b8 00 00 00 00 mov $0x0,%eax
401cc2: e8 9f fe ff ff callq 401b66 <stop_all_counter>
401cc7: b8 00 00 00 00 mov $0x0,%eax
401ccc: e8 9c fe ff ff callq 401b6d <liststatus>
401cd1: b8 00 00 00 00 mov $0x0,%eax
401cd6: e8 84 fe ff ff callq 401b5f <clear_all_counter>
401cdb: 90 nop
401cdc: c9 leaveq
401cdd: c3 retq
循环核心代码在401c87到401cbb之间,共16条指令,X86指令集不算是RISC指令集,因此似乎效果要好点,不过没有根本区别了,这点好处其实还不如RISC-V实现简单带来的好处呢(意味着同样的面积和功耗下预期的主频更容易提高)。主要得益于它的寻址方式中自己带了一个地址计算单元,在RISC-V中地址计算也是通过alu来做的。
当然,如果硬要RISC-V实现DSP的功能,干脆扩展一个DSP指令子集好了。不过这个就不是RISC-V指令集的问题范畴了。
3. 流水线实现方式,前面我们做的是用状态机是实现,一个指令分为取指令状态,读RS1状态,读RS2状态,执行状态,回写结果寄存器状态,读操作数(LD指令)状态,写结果(ST指令)状态,等待除法结果状态,最简单的指令需要执行其中前五个状态,也就是说至少五个周期才能执行一条指令。这当然是一种为了提高可读性的做法,实际的CPU实现不大可能采用这么低效的实现方式。实际上实现方法有两种:一种是单周期实现,一个周期内完成指令执行和结果修改,同时送出读下条指令的命令,这种方式有可能对运行频率有影响,也要求寄存器必须实现为当前拍能够读到结果的部件,对很多要求高频率运行的场合是有限制的。另一种方式就是所谓的流水线实现方式,一条指令可以在多个状态,但是不需要等前一条指令执行完成,才执行另一条指令,可以把取指,指令译码,执行,回写等操作流水起来,每一个周期都执行取指,译码,执行回写等操作,这样实现平均每个周期可期望达到1条指令。当然这样实现也存在存储器冲突,跳转指令带来的流水线损失(跳转指令执行时,后续指令的取值及译码的结果可能会失效),指令之间寄存器依赖(比如前面一条的目的寄存器是后面一条的源寄存器,此时两条指令就有寄存器依赖。)。这些问题的处理方式直接影响实际的运行效果。为了处理跳转指令,可能有分支预测的处理方式,为了处理寄存器依赖,可能有所谓的乱序执行的处理手段,减少对流水线造成的影响。设置为了处理存储器的速度匹配,还引入了高速缓冲,或者干脆引入硬件多线程,充分发挥CPU中各个组件的应用效率。
4. 中断处理和异常处理,这个需要CPU能够响应外部的信号,执行事先规定好的代码,此时需要有诸如保护现场等操作,比如可以支持时钟中断和软中断。
5. 多任务支持,能够在一个CPU中实现多个任务分时运行。
6. SIMD支持,多个核共享一个指令流,可以用在大规模数据处理的场合,比如GPU。
7. 高速缓存支持,这已经不是CPU核需要考虑的了,但是一般的CPU设计都会考虑这方面的支持。
总之,CPU设计涉及到很多方面的考虑和权衡,只有在指定的应用场合下提供最合适的实现方式,才是最优的方案,离开应用考核CPU实现都不合适。
16.2 CPU核的完善
前面一章实现的在FPGA上运行的版本,功能还不完全,由于是演示性质的,性能方面也没有过多追求,为了让这个核有一定的使用价值,我们做如下改进:
- 实现了不对齐情况下的LOAD/STORE指令,比如代码:
unsigned int test = 0;
const unsigned char testdata[] = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10;
*(unsigned int*)(&testdata[1]) = 0x99887766;
test = *(unsigned int*)(&testdata[2]);
对&testdata[1]地址进行32为整数写操作,就是一个非对齐地址的操作,我们内部增加了一个状态,如果遇上非对齐的写,就再写一个字,用写操作的字节使能实现部分写。对&testdata[2]的读则是一个非对齐地址的读操作,此时我们读两个字,然后拼装出一个正确的读结果出来。
-
实现了CSR指令和几个基本的寄存器。支持的CSR寄存器包括:
reg [31:0] misa; /0301/
reg [31:0] ucycle; /0c00/
reg [31:0] utime; /0c01/
reg [31:0] uinstret; /0c02/
reg [31:0] ucycleh; /0c80/
reg [31:0] utimeh; /0c81/
reg [31:0] uinstreth; /0c82/
reg [31:0] mcycle; /0b00/
reg [31:0] minstret; /0b02/
reg [31:0] mcycleh; /0b80/
reg [31:0] minstreth; /0b82/
后面是CSR地址,使用时如果需要更多的CSR寄存器,可以自行扩展。 -
减少了几个状态,主要是回写结果的状态合并在执行中,并将非存储访问指令的读指令周期合并在执行完成的状态中。注意到我们的实现中,寄存器是放在核外用一个ram实现的,指令存储器和数据存储器则共享一个存储读写接口,没有实现流水线模式,因此一条指令最少要两个周期,一个周期读指令,一个周期读寄存器,指令译码和执行则穿插在两个周期中间。如果是访问存储器(外设)指令,则还需要增加一个存储数据存储器周期,那就要三个周期,如果是非对齐地址访问,则要额外增加一个周期。如果是除法指令,我们采用12级流水实现,除法(取余数)指令需要12个周期才能执行一条指令。我们还把读两个源寄存器的两个状态合并到一个状态中,办法是用两个一模一样的RAM来实现寄存器文件,读的时候可以分别不同的地址从两个存储体中读,写的时候则两个存储体同时写一模一样的值,这样可以用一个单口的RAM来实现一写二读的接口(当然读写不能同时),代价是存储空间需要两倍。我们坚持使用单端口的RAM实现寄存器文件,主要是为了减少对FPGA的依赖,在某些FPGA中或AISC的工艺中,实际上是不提供双端口RAM的,当然也可以用寄存器来实现,但是代价要高很多。
这样处理的目的,主要是保持核的简单性,并保证主频,目前在CycloneV的器件上(DE1-SOC开发板)能够综合到60MHz。核也比较小, 下面是在DE1-SOC上综合的结果:
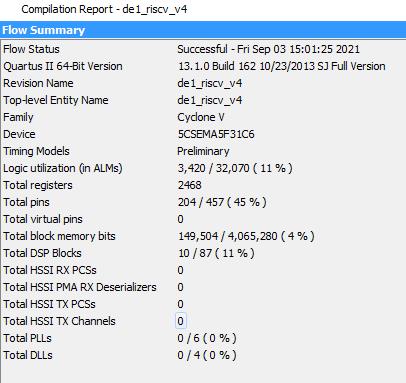
最坏情况的时序能达到60MHz,此时关键路径在乘法器上,如果把乘法器用4拍流水线实现,则可以综合到Worst Case 80MHz,实际上常温跑到100MHz是没有问题的,然而此时增加了寄存器占用,并增加了指令执行的周期数(跑调试程序应用的话,大概从3.18增加到3.36,可以根据应用场景衡量是否合算了):

-
尝试过将寄存器放在核内,单周期实现,但是此时主频下降很厉害,而且占用了宝贵的片内逻辑单元,所以还是放在核外来实现,将来如果想通过增加多组寄存器实现多个hart(硬件多线程),扩展起来也是 比较简单的。
-
软件支持方面,在编译过程中如果使用scanf, printf,sprintf等newlib的库,编译后的代码会增加很多,至少需要128KB的存储器,一般的FPGA项目有点用不起了。因此为了减少内存占用,我们干脆不用newlib中的相关的函数,自己做一些支持性的函数,这样做内存只需要16KB,就能做一个可以交互的调试终端出来。软件应用程序编译之后,作为一个数据文件直接综合到FPGA的烧录文件中(作为RAM的初始化数据文件),这样做简化了软件的存放处理。可以做成一个比较成熟通用的调试程序,编译成数据文件的方式在不同的项目中复用。
这么修改之后,代码量增加了不少,CPU核部分verilog已经有800多行了。主要是实现CSR以及非对齐访问。
16.3 增加串口设备
为了支持一个通过串口连接的调试应用,我们为这个应用提供了一个串口设备。串口的核直接采用Altera的Quartus II直接生成,生成的代码比较长,下面是它的接口信号:
module altera_uart (
// inputs:
address,
begintransfer,
chipselect,
clk,
read_n,
reset_n,
rxd,
write_n,
writedata,
// outputs:
dataavailable,
irq,
readdata,
readyfordata,
txd
);
这是一个通过读写内部寄存器能够实现收发以及控制的电路实现。它也提供了dataavailable核readyfordata信号来指示数据可读以及可写。由于我们的CPU没有支持中断,这样软件只能能用轮询的方式来访问这个核,为了不丢数据并提高发送效率,我们为这个核外面包装一层,并增加发送缓冲区和接收缓冲区(FIFO实现)。包装过程如下:
module uart_ctrl(
input wClk,
input nwReset,
input wRead,
input [31:0] bReadAddr,
input wWrite,
input [31:0] bWriteAddr,
input [31:以上是关于HDL4SE:软件工程师学习Verilog语言(十六)的主要内容,如果未能解决你的问题,请参考以下文章