RNN循环神经网络(过程解析)
Posted 月疯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RNN循环神经网络(过程解析)相关的知识,希望对你有一定的参考价值。
RNN的引出:时间序列如何表达?
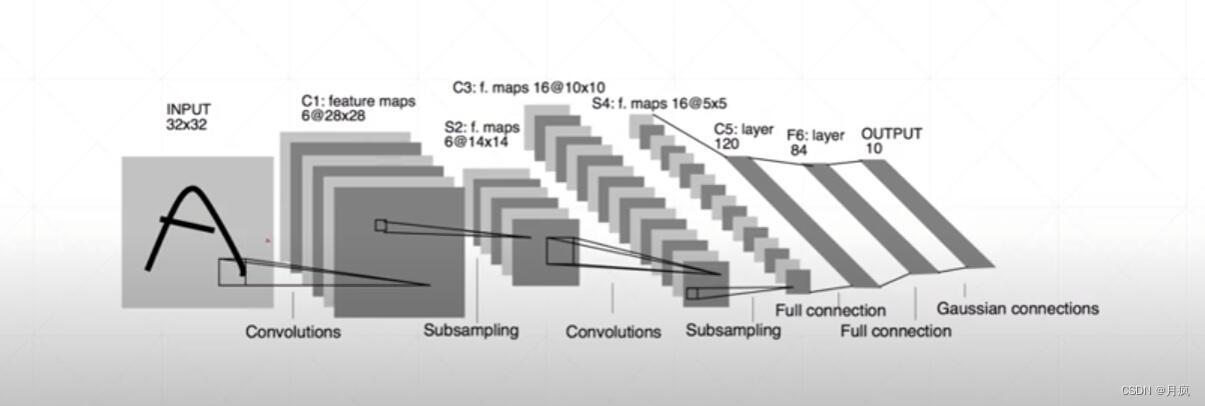
卷积神经网络是位置上上进行提取特征,比如语音和翻译都是在时间上缠身的,如何提取时间序列的特征。
对于序列问题的研究:咋么把文字编程一个数据类型或者数值,这个研究方案就是embedding。
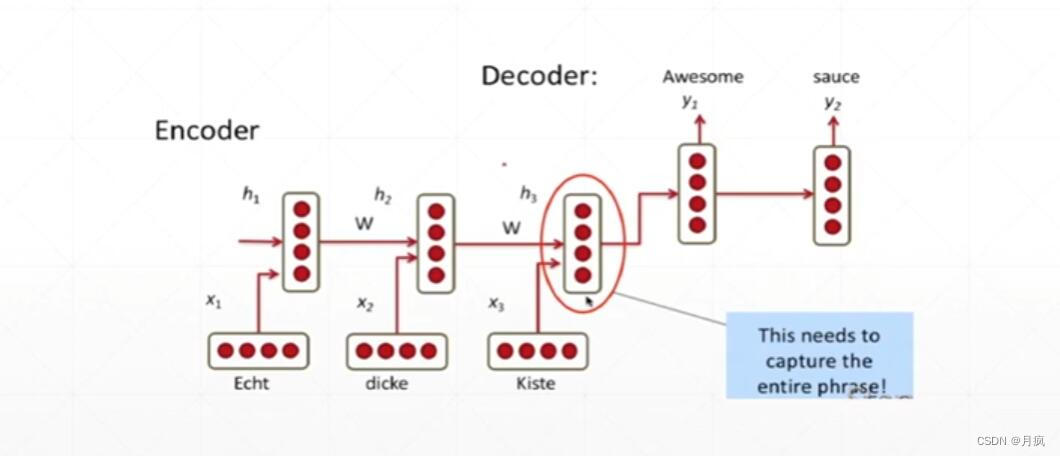

单个股票价格的表示方法,每个时间点上都是一个对应的价格值。

多个股票价格的表示方法。
这个思想使用到图片上也是这样,按照行读取数值,作为序列的特征


one-hot表示方法。

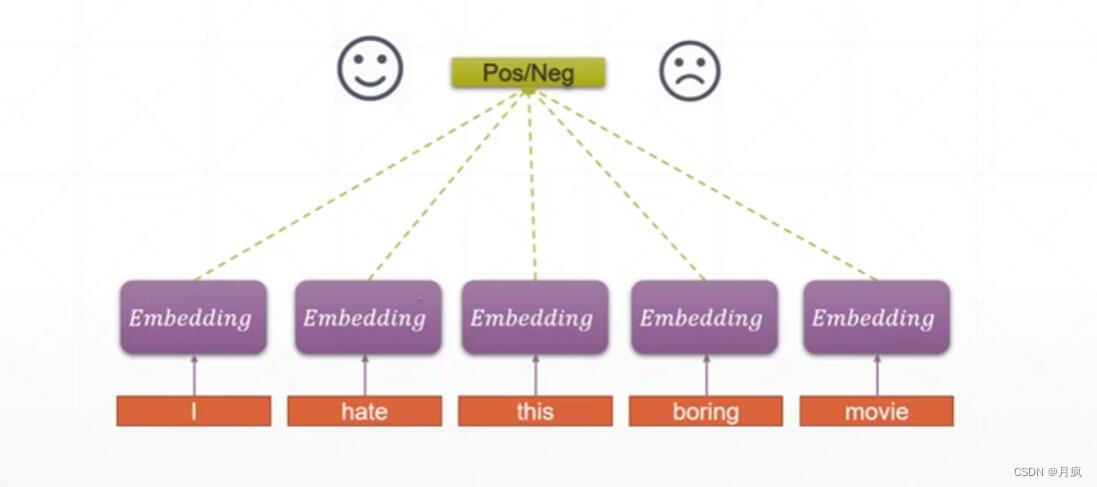
通过具体问题来分析一下,判断一下评价是积极的还是消极的这样一个工作,当我们输入是I hate this boring movie,可以看出来一个Embedding就是一个单词。

每一个单词是一个输入,有多少单词就有多少全连接层,每个全连接层处理一个单词,通过全连接层把每个单词当前的语义信息给提取出来,然后做一个分类就知道,当前评价是好评还是差评。这种方法比较直观,但是存在一个问题,如果一个比较长的评语,100个单词需要引进100个全连接层,更关键的是我们只是获取到每个单词的语义信息,对于100个单词,我们没有整体的语义相关性。如果我们把100个单词打乱,也不会影响结果,但是结果打乱会影响的整体的语义相关性。
我们需要把整体综合起来,整体分析,要处理这个问题?
参数量大在卷积网络是如何解决的,我们用一个卷积核,卷积核大小不变,内部值发生变化,得到解决。我们只使用一个神经网络来解决,不断的输入和输出。我们的参数量只有w和b。解决参数量过大的问题。
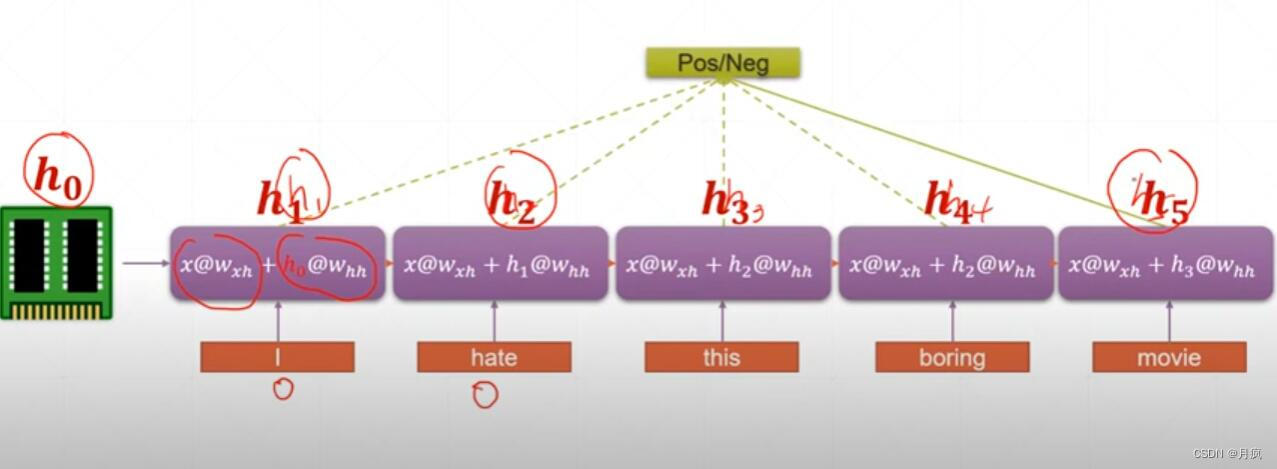
如何解决语义信息的整体分析呢?
我们加入一个memory层或者state状态层,就是每经过一次全连接层,后面的都会记录前面的信息。这样我们得到整个语句的最后一个memory,是记录了全体的信息的,我们只对最后一次得到的信息做处理就能获取所有的语义信息。
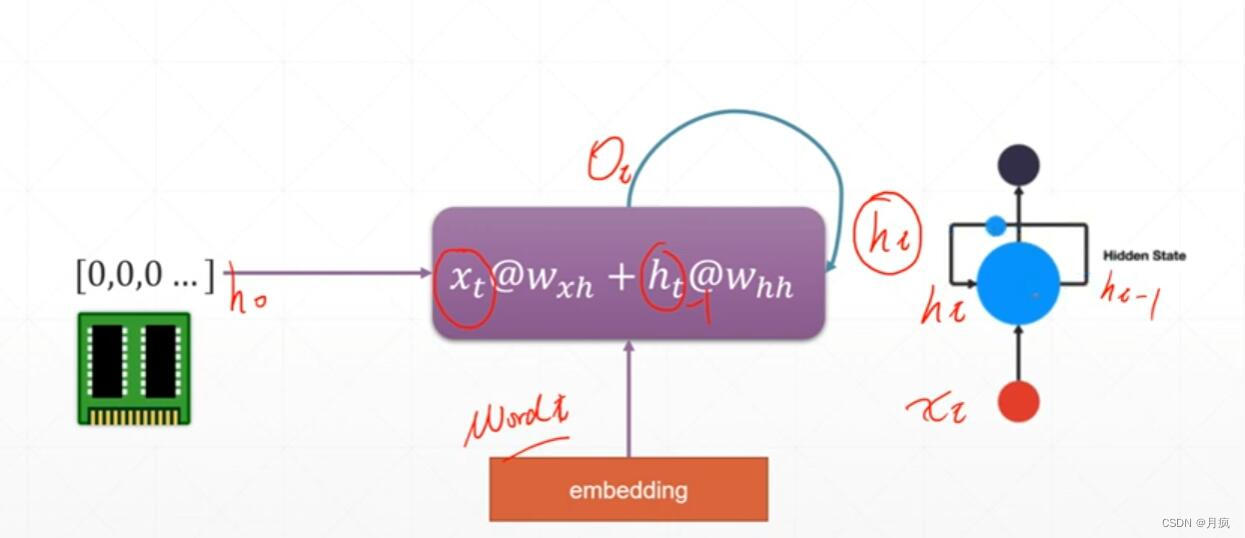
时间轴上有多少个采样就需要走多少次,采样和时间相关。我们对时间周做一个折叠,初始状态h0,然后对信息不断聚合,当前的输入就是上一次的语境信息。 这样通过不断的聚合,最后一个就包含了所有的语境信息。这就是最简单的RNN循环网络的原理。综合起来就是一个神经网络不断聚合的结果。

这是RNN的数学表达:代码演示
# _*_ coding =utf-8 _*_
import tensorflow as tf
from tensorflow.keras import layers,optimizers,datasets,Sequential
import os
#Xt@Wxh + ht@Whh
cell =layers.SimpleRNNCell(3)
#[b,embeding]4输入的维度
cell.build(input_shape=(None,4))
#打印cell的参数
print(cell.trainable_variables)
#kernel:0表示Wxh,recurrent_kernel:0表示Whh
# [<tf.Variable 'kernel:0' shape=(4, 3) dtype=float32, numpy=
# array([[ 0.87822306, 0.8071407 , -0.20742077],
# [-0.5177747 , -0.0864749 , 0.87705004],
# [-0.8141298 , 0.32291627, -0.329014 ],
# [-0.05522245, -0.5882717 , 0.74687743]], dtype=float32)>, <tf.Variable 'recurrent_kernel:0' shape=(3, 3) dtype=float32, numpy=
# array([[ 0.29745793, 0.9037314 , 0.30787772],
# [-0.9194169 , 0.35804993, -0.16270511],
# [-0.25727728, -0.23467004, 0.9374105 ]], dtype=float32)>, <tf.Variable 'bias:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>]Wxh是上一次的权值,Whh是本次的权值,会产生下一个新的Yt,Ht是对上一次语境信息激活,计算梯度的时候保证连续可导。

如果输出是[b,64],那么[b,100]@[100,64] +[b,64]@[64,64]=[b,64]
Xt@Wxh + ht@Whh 这就是一个SampleRNNCell (要和LSTM和GRU不一样)
# #获取4个句子,每个句子80个单词,每个单子100位向量
# x = tf.random.normal([4,80,100])
# #获取第一个单词
# xt0 = x[:,0,:]
# #中间维度是64
# cell = tf.keras.layers.SimpleRNNCell(64)
# #初始状态xt0,返回俩个相同的状态[b,64] 输出
# out,xt1 = cell(xt0,[tf.zeros([4,64])])
#
# print(out.shape,xt1[0].shape)
梯度的弥散和梯度爆炸:

Whh的k次,如果Whh>1,那么结果会趋近于无穷大,会出现梯度爆炸
如果Whh<1的话,那么结果会趋近于0,会出现梯度弥散



RNN情感分析实战:单层RNN
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from keras.preprocessing.sequence import pad_sequences
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
embedding_len=100#表示100个句子
batchsz = 128
#
total_words = 10000
max_review_len = 80 #80个单词
(x_train,y_train),(x_test,y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train[b,80] 每个句子80个单词
# x_test[b,80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train,maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train))
#最后一个bach给drop掉
db_train = db_train.shuffle(1000).batch(batchsz,drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test = db_test.batch(batchsz,drop_remainder=True)
print('x_train shape:',x_train.shape,tf.reduce_max(y_train),tf.reduce_min(y_train))
print('x_test:',x_test.shape)
class MyRNN(keras.Model):
def __init__(self,units):
super(MyRNN, self).__init__()
#初始化状态[b,64],b个句子,每个句子64维的状态
self.state0 = [tf.zeros([batchsz,units])]
#网络总共三层,第一层就是把数字编码转换为embedding编码,b个句子,每个句子80个单词,每个单词100维向量来表示
# [b,80] => [b,80,100]
#total_words输入维度10000,embedding_len 输出是100维,input_length每个句子的长度是80
self.embedding = layers.Embedding(total_words,embedding_len,input_length=max_review_len)
#[b,80,100],h_dim:units(100维进行转换为64)
#RNN:cell0,cell1,cell2
#SimpleRNN
#第二层是语义提取,就是利用SimapleRNN提取语义,dropout防止过拟合
self.rnn_cell0 = layers.SimpleRNNCell(units,dropout=0.2)
#fc,[b,80,100] => [b,64] => [b,1]
self.outlayer = layers.Dense(1)
def call(self,inputs,training=None):
"""
net(x),net(x, training=True)
:param inputs: [b,80]
:param training:
:return:
"""
#[b,80]
x = inputs
#embedding:[b,80] => [b,80,100]
x = self.embedding(x)
#rnn cell compute
# [b,80,100] =>[b,64]
state0 = self.state0
#x在第一维上进行展开
for word in tf.unstack(x,axis=1):# word [b,100]
# x*wxh + h*whh #上一个状态会获取下一个状态
out,state1 = self.rnn_cell0(word,state0)
#新的state赋值给上一个state
state0 = state1
# out: [b,64]=>[b,1]二分类转换为b和1
x = self.outlayer(out)
#p(y is pos|x) 计算概率
prob = tf.sigmoid(x)
return prob #完成了前向计算的信息
def main():
units =64
epochs =4
model =MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics = ['accuracy'])
model.fit(db_train,epochs=epochs,validation_data=db_test)
model.evaluate(db_test)
if __name__ =='__main__':
main()多层RNN:
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from keras.preprocessing.sequence import pad_sequences
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
embedding_len=100#表示100个句子
batchsz = 128
#
total_words = 10000
max_review_len = 80 #80个单词
(x_train,y_train),(x_test,y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train[b,80] 每个句子80个单词
# x_test[b,80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train,maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train))
#最后一个bach给drop掉
db_train = db_train.shuffle(1000).batch(batchsz,drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test = db_test.batch(batchsz,drop_remainder=True)
print('x_train shape:',x_train.shape,tf.reduce_max(y_train),tf.reduce_min(y_train))
print('x_test:',x_test.shape)
#以单个层训练,现在再增加一个层,提高训练准确度
class MyRNN(keras.Model):
def __init__(self,units):
super(MyRNN, self).__init__()
#初始化状态[b,64],b个句子,每个句子64维的状态
self.state0 = [tf.zeros([batchsz,units])]
self.state1 = [tf.zeros([batchsz,units])]
#网络总共三层,第一层就是把数字编码转换为embedding编码,b个句子,每个句子80个单词,每个单词100维向量来表示
# [b,80] => [b,80,100]
#total_words输入维度10000,embedding_len 输出是100维,input_length每个句子的长度是80
self.embedding = layers.Embedding(total_words,embedding_len,input_length=max_review_len)
#[b,80,100],h_dim:units(100维进行转换为64)
#RNN:cell0,cell1,cell2
#SimpleRNN
#第二层是语义提取,就是利用SimapleRNN提取语义,dropout防止过拟合
self.rnn_cell0 = layers.SimpleRNNCell(units,dropout=0.2)
self.rnn_cell1 = layers.SimpleRNNCell(units,dropout=0.2)
#fc,[b,80,100] => [b,64] => [b,1]
self.outlayer = layers.Dense(1)
def call(self,inputs,training=None):
"""
net(x),net(x, training=True)
:param inputs: [b,80]
:param training:
:return:
"""
#[b,80]
x = inputs
#embedding:[b,80] => [b,80,100]
x = self.embedding(x)
#rnn cell compute
# [b,80,100] =>[b,64]
state0 = self.state0
state1 = self.state1
#x在第一维上进行展开
for word in tf.unstack(x,axis=1):# word [b,100]
# x*wxh + h*whh #上一个状态会获取下一个状态
out0,state0 = self.rnn_cell0(word,state0)
out1,state1 = self.rnn_cell1(out0,state1)
# out: [b,64]=>[b,1]二分类转换为b和1
x = self.outlayer(out1)
#p(y is pos|x) 计算概率
prob = tf.sigmoid(x)
return prob #完成了前向计算的信息
def main():
units =64
epochs =4
model =MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics = ['accuracy'])
model.fit(db_train,epochs=epochs,validation_data=db_test)
model.evaluate(db_test)
if __name__ =='__main__':
main()结果展示:
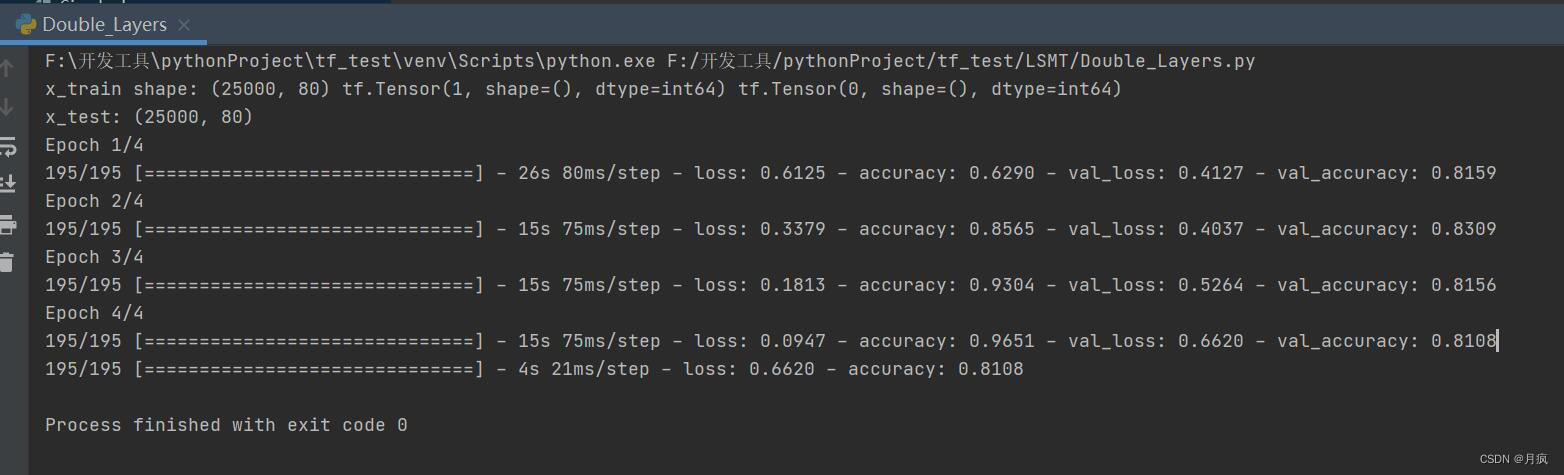
以上是关于RNN循环神经网络(过程解析)的主要内容,如果未能解决你的问题,请参考以下文章