Flink高手之路:Flink流批一体API开发
Posted 平平无奇秃头小天才
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink高手之路:Flink流批一体API开发相关的知识,希望对你有一定的参考价值。
目录
1)MySQL:可以把经过Flink处理的数据保存到MySQL中
一、流处理相关概念
1.数据的时效性
日常工作中,我们一般会先把数据存放在表中,然后对数据进行加工和分析。这就有时效性
的问题。
如果以年、月、天为单位的级别的数据处理,进行统计分析,个性化推荐,这样的数据一般
称之为批数据。如果以小时、分钟、秒这样的单位进行处理,这样的数据一般称之为流数据。
比如对网站的实时监控、日志的处理等。在这样的场景下,如果还要收集数据存储到数据库
中,再取出来统一进行处理,就无法满足高时效性的需求
2.流处理和批处理
1)批处理
BatchAnalytics,统一收集数据->存储到数据库->对数据进行批量处理,例如MP、Hive、
FlinkDataSet、SparkBatch等,生成离线报表
2)流处理
StreamingAnalytics,就是对数据流进行处理,例如Storm、FlinkStream、SparkStreaming
实时处理分析数据,应用场景如实时大屏、实时报表等
3)流处理与批处理对比
- 数据的时效性不同:流处理实时、低延迟,批处理非实时、高延迟
- 数据特征不同:流处理的数据一般是动态的、没有边界,而批处理的数据一般是静态
的
- 应用场景不同:流处理应用在实时场景,批处理对实时性要求不高
- 运行方式不同:流处理的任务是持续进行,批处理的任务是一次性完成
3.流批一体API
Flink的DataStreamAPI既支持批处理模式,又支持流处理模式,可以认为批处理是流处理
的一种特例。
流批一体的好处:
- 可复用性:作业可以在流、批两种模式之间自由切换,而无需重写代码。
- 维护简单:统一的api,维护简单
二、流批一体编程模型

三、Data-Source
1.预定义的source
1)基于集合的source
API
- env.fromElements(可变参数)
- env.fromCollection(各种集合)
- env.generateSequence(开始,结束)
- env.fromSequence(开始,结束)
演示



2)基于文件的source
API
env.readTextFile(本地/HDFS/文件夹/压缩文件)
演示

准备gz压缩文件


查看结果

3)基于socket的source
socket是指网络通讯,需要有一个发送端一个接送端,类似于插头和插座(socket),用于
和一些智能硬件的对接。比如门禁的人脸机就是一个智能设备,每个人脸机都有一个ip地
址,也有一个端口,根据ip地址和端口号就可以和这个人脸机进行通讯
a.模拟socket通讯,安装nc
nc是netcat的简称,可以利用它向某台主机的某个端口发送数据,模拟socket通讯的发送
端,也就是作为source

b.启动nc,发送数据,相当于socket通讯的发送端

c.使用telnet来接收数据,测试socket是否工作正常
在windows主机安装telnet


d.linux主机下,也可以安装telnet进行

e.找到端口进程杀死
[root@hadoop001 ~]# netstat -nap | grep 9999

f.编写flink代码,作为socket通讯的接收端,接收发送的数据进行处理

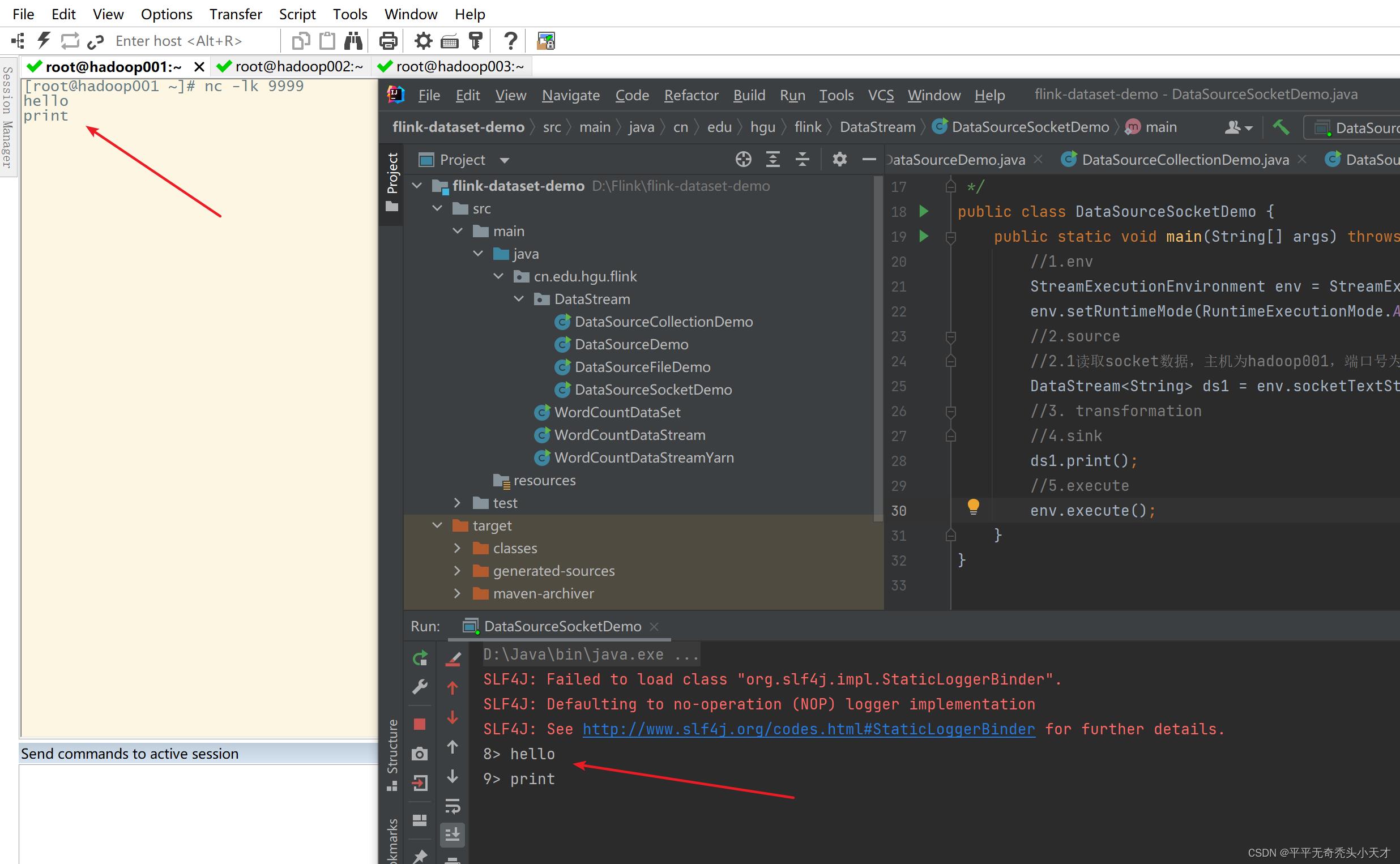
g.案例-利用基于socket的source实时统计单词数量



2.自定义的source
1)随机生成数据
API
SourceFunction:非并行的随机数据源(并行度为1)
RichSourceFunction:丰富的非并行的随机数据源(并行度为1)
ParallelSourceFunction:并行的随机数据源(并行度可以大于等于1)
RichParallelSourceFunction:丰富的并行的随机数据源(并行度可以大于等于1)
需求
每隔1秒随机生成一条订单信息(订单ID,用户ID,订单金额,时间戳)
要求:
随机生成订单ID(UUID):UUID是通用唯一识别码(UniversallyUniqueIdentifier)的缩写
随机生成用户ID(0-2)
随机生成订单金额(0-100)
时间戳为当前系统时间
编程实现
引入lombok依赖,使用注解@Data自动生成getter和setter




启动并查看结果

2)mysql
从mysql中提取数据进行处理
Sqoop数据迁移:可以把mysql中的数据迁移到hdfs、hive、hbase中
Kettle:ETL工具,也可以将mysql中的数据抽取到hdfs、hive中,并进行处理
Flink:api方式读取mysql中的数据,并进行处理
a.需求
从mysql中实时加载数据
b.启动mysql
本地MySQL
远程MySQL

c.准备睡觉
准备表

设置字段

添加记录

d.代码实现




e.在pom文件中添加java连接mysql的依赖

f.运行查看结果

四、Transformations
官网api地址
Apache Flink 1.12 Documentation: Operators
1.整体分类
1)对单条记录的操作
filter过滤,map映射
2)对多条记录的操作
统计一个小时内的订单的总成交量,需要使用window将需要的记录关联到一起进行处理
3)对多个流进行操作并转换为单个流(合并)
union联合、join连接、connection连接
4)把一个流拆分成多个流(拆分)
split拆分,拆分后的每个流是原来流的有一个子集,可以对每个子集进行不同的操作
2.基本操作
1)Map
映射,将操作作用在集合中的每一个元素上,并返回作用后的结果y=f(x)
2)flatMap
扁平化映射,将集合中的每个元素转换为一个或多个元素,并返回扁平化之后的结果
3)KeyBy
分组,安装指定的key来对流中的数据进行分组,注意在流处理中没有groupBy,而是keyBy
4)filter
过滤,按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
5)sum
求和,按照指定的字段对集合中的元素进行求和
6)reduce
聚合,对集合中的元素进行聚合
3.合并拆分
1)union和connect
union算子可以合并多个同类型的数据流,并生成一个同类型的数据流,数据按照先进先出(FirstInFirstout)的模式合并,并且不去重。
connect提供了和union类似的功能,用来连接两个数据流,,但是与union区别:
connect只能连接两个数据流,而union可以连接多个数据流
connect连接的两个数据流的数据类型可以不一致,union所连接的数据流的数据类型必须一致
两个DataStream经过connect之后被转换为一个ConnectedStreams,并且会对两个流的数据应用不同的处理方法,而且双流之间可以共享状态。
2)需求
将两个String类型的流进行union
将一个String类型的流和一个Long类型的流信息connect
3)代码实现


4)结果展示

5)Select和SideOutputs
Select就是获取分流后对应的数据
SideOutputs可以使用process方法对流中的数据进行处理,并针对不同的处理结果将数据
收集到不同OutputTag中
6)需求
对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
7)代码实现


8)结果展示


4.分区
1)rebalance重平衡分区
类似与spark中的repartition,但是功能更强大,可以直接解决数据倾斜问题。
2)代码实现


3)结果展示

4)其他分区
global:全部发往第一个task
broadcast:广播
forward:上下游并发度一样时一对一发送
suffle:随机均匀分配
recale:本地轮流分配
partitionCustom:自定义分区
五、Data Sink
1.预定Sink
1)基于控制台和文件的Sink
print:直接输出到控制台
printToErr:直接输出到控制台,用红色
writeAsText(本地/HDFS):输出到本地或者hdfs上,说明:如果并行度为1输出为文件,
如果并行度>1,输出为文件夹,如果不加并行度,则使用默认的并行度8,输出也为文
件夹
2.自定义Sink
1)MySQL:可以把经过Flink处理的数据保存到MySQL中
2)代码实现
主程序

自定义数据下沉类


3)结果展示

六、Connector
官网api
Apache Flink 1.12 Documentation: JDBC Connector
1.JDBCConnector
Exampleusage:

以上是关于Flink高手之路:Flink流批一体API开发的主要内容,如果未能解决你的问题,请参考以下文章