java实现网络爬虫之链接初筛选策略
Posted xxniuren
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java实现网络爬虫之链接初筛选策略相关的知识,希望对你有一定的参考价值。
java实现网络爬虫之链接初筛选策略
Web链接信息虽然很多,但是仔细分析其中结构,会发现其存在一定的规律性,为了对爬虫链接进行初步筛选,需要对链接进行分析。
URL的组成为:http://<host>:<port>/<path>?<searchpath>;host表示的是主机的名字(IP或域名),<port>是端口号,<path>表示是站内结构;
对Web结构进行分析:
页面之间的链接可以分为五种类型:
Downward --下行链,表示当前页面的下一级页面;
Upward -- 上行链,表示当前页面的上一级页面;
Horizontal -- 水平链,表示当前页面的同一级目录的链接;
Crosswise -- 交叉链,表示非当前页面同一级目录的链接;
Outwise -- 外向链,表示非当前网页同一站点的链接;
从内容上看,下行链是对当前网页的详细的介绍,上行链是对当前网页的概述(其中可能会含有更多的有效平行或近似信息),水平链是与当前网页涉及到的领域同一样的内容。交叉链和外链接是主要指向和锚点信息相关的网页,每一个链接的存在都有其理由。所以可以通过对链接进行划分,来调整网页爬取的方向。
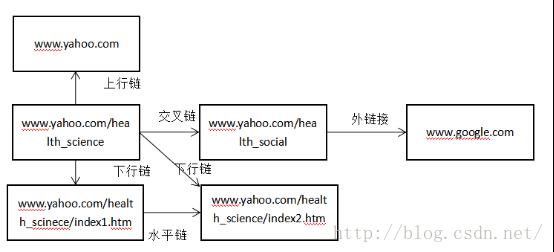
上行链接、下行链接、交叉链接和水平链接可以当做为站内链接,主要是以该网站为中心的一个发散的行为,而外链接相当于链接到与该网页不相关的地方,所以可以当做站间链接,站内链接主要是指向同一网站内部的不同部件(网页或者是其他的信息),或同一部件的不同部分,上行链、下行链、水平链都是该网页相关的链接,交叉链接可能是该网站的一个补充,也可能是另一个非主题相关网站的链接,该目的很大程度上是丰富该网站要传达的信息,是网页具备一定的完备性,站间链接主要是丰富网页内容、广告、非主题关联信息表达等,所以很多都是对主题爬虫无意义的链接。所以可以找到链接相互之间的关系,对链接进行有针对性的处理。
可以对链接主题进行粗筛选机制,采用如下链接过滤机制:
1、分析URL,将其划分为上链接、下链接、水平链接、交叉链接、外链接五块;
2、筛出下行链接和水平链接,水平链接时为了共同表述完备一个内容,下行链接是为了把当前内容表述的更为详细,所以这两部分链接为重要链接,需要全部保存;
3、过滤上行链接。上行链接是当前页面的一个概括,可能保存有一定的主题相关信息,由于上行链接有更广泛的主题内容,所以不一定和当前的主题内容存在相关,基于概率上的考虑,对上行链接进行0.5倍的随机筛选;
4、过滤交叉链接。交叉链接的内容很大程度上是由锚信息内容决定的,所以可以获得该链接的锚信息,然后分析是否与预设主题相关,如果相关则保存下来,不相关则滤除该链接(如果链接不存在锚信息,则进行舍弃)。
5、过滤外链接。外链接包括站内链接和站间链接两种,从URL中取出域名部分和当前页面的URL进行对比,如果两个URL只是最低一级域名不一样,而其他部分相同的话,那可以判断该网页是站内链接,否则判断该网页是站间链接,由于是主题爬虫,所以站间链接无需处理(只关心某些主题网页,这样的网页一定是站内链接)。然后再去考虑栈内链接的锚信息是否与主题相关,如果与主题相关,则滤除,否则就丢弃;
整个链接滤除流程图如下:
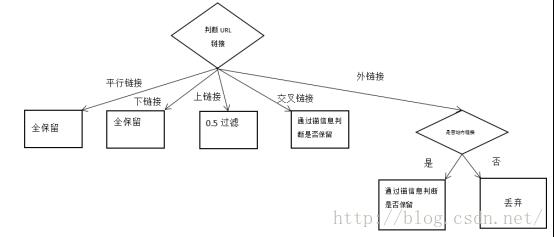
通过滤除操作,可以滤除很多无意义链接,从而降低服务器的爬取链接负荷。
以上是关于java实现网络爬虫之链接初筛选策略的主要内容,如果未能解决你的问题,请参考以下文章