FastSpeech2代码理解之模型实现
Posted 象牙塔♛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FastSpeech2代码理解之模型实现相关的知识,希望对你有一定的参考价值。
文章目录
参考
参考项目:FastSpeech2的github实现
FastSpeech2论文
FastSpeech2模型代码分析
FastSpeech2
FastSpeech2是一个基于Transformer的端到端语音合成模型,其结构如下:
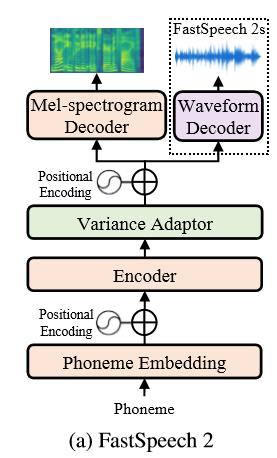
Encoder将音素序列转换到隐藏序列,然后Variance Adaptor将不同的变量信息,如时长、音高、能量加入到到隐藏序列中,最终解码器将隐藏序列转换为梅尔谱序列。
1. FastSpeech2实现
FastSpeech2的实现位于/model/fastspeech2.py中:
class FastSpeech2(nn.Module):
""" FastSpeech2 """
def __init__(self, preprocess_config, model_config):
super(FastSpeech2, self).__init__()
self.model_config = model_config
self.encoder = Encoder(model_config)
self.variance_adaptor = VarianceAdaptor(preprocess_config, model_config)
self.decoder = Decoder(model_config)
self.mel_linear = nn.Linear(
model_config["transformer"]["decoder_hidden"],
preprocess_config["preprocessing"]["mel"]["n_mel_channels"],
)
self.postnet = PostNet()
self.speaker_emb = None
if model_config["multi_speaker"]:
with open(
os.path.join(
preprocess_config["path"]["preprocessed_path"], "speakers.json"
),
"r",
) as f:
n_speaker = len(json.load(f))
self.speaker_emb = nn.Embedding(
n_speaker,
model_config["transformer"]["encoder_hidden"],
)
2. 模型结构
使用如下代码打印参考项目的FastSpeech2模型结构
from model import FastSpeech2
from utils.tools import get_configs_of
preprocess_config, model_config, train_config = get_configs_of("AISHELL3")
print(FastSpeech2(preprocess_config, model_config))
其中get_configs_of是原参考项目没有的,在/utils/tools.py中增加如下代码
import yaml
def get_configs_of(dataset):
config_dir = os.path.join("./config", dataset)
preprocess_config = yaml.load(open(
os.path.join(config_dir, "preprocess.yaml"), "r"), Loader=yaml.FullLoader)
model_config = yaml.load(open(
os.path.join(config_dir, "model.yaml"), "r"), Loader=yaml.FullLoader)
train_config = yaml.load(open(
os.path.join(config_dir, "train.yaml"), "r"), Loader=yaml.FullLoader)
return preprocess_config, model_config, train_config
FastSpeech2结构打印如下,其中postnet模块在FastSpeech2的论文中是没有的,是此参考项目的作者增加的:
FastSpeech2(
(encoder): Encoder(
(src_word_emb): Embedding(361, 256, padding_idx=0)
(layer_stack): ModuleList(
(0): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(1): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(2): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(3): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
)
)
(variance_adaptor): VarianceAdaptor(
(duration_predictor): VariancePredictor(
(conv_layer): Sequential(
(conv1d_1): Conv(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(relu_1): ReLU()
(layer_norm_1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout_1): Dropout(p=0.5, inplace=False)
(conv1d_2): Conv(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(relu_2): ReLU()
(layer_norm_2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout_2): Dropout(p=0.5, inplace=False)
)
(linear_layer): Linear(in_features=256, out_features=1, bias=True)
)
(length_regulator): LengthRegulator()
(pitch_predictor): VariancePredictor(
(conv_layer): Sequential(
(conv1d_1): Conv(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(relu_1): ReLU()
(layer_norm_1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout_1): Dropout(p=0.5, inplace=False)
(conv1d_2): Conv(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(relu_2): ReLU()
(layer_norm_2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout_2): Dropout(p=0.5, inplace=False)
)
(linear_layer): Linear(in_features=256, out_features=1, bias=True)
)
(energy_predictor): VariancePredictor(
(conv_layer): Sequential(
(conv1d_1): Conv(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(relu_1): ReLU()
(layer_norm_1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout_1): Dropout(p=0.5, inplace=False)
(conv1d_2): Conv(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(relu_2): ReLU()
(layer_norm_2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout_2): Dropout(p=0.5, inplace=False)
)
(linear_layer): Linear(in_features=256, out_features=1, bias=True)
)
(pitch_embedding): Embedding(256, 256)
(energy_embedding): Embedding(256, 256)
)
(decoder): Decoder(
(layer_stack): ModuleList(
(0): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(1): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(2): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(3): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(4): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(5): FFTBlock(
(slf_attn): MultiHeadAttention(
(w_qs): Linear(in_features=256, out_features=256, bias=True)
(w_ks): Linear(in_features=256, out_features=256, bias=True)
(w_vs): Linear(in_features=256, out_features=256, bias=True)
(attention): ScaledDotProductAttention(
(softmax): Softmax(dim=2)
)
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=256, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(pos_ffn): PositionwiseFeedForward(
(w_1): Conv1d(256, 1024, kernel_size=(9,), stride=(1,), padding=(4,))
(w_2): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.2, inplace=False)
)
)
)
)
(mel_linear): Linear(in_features=256, out_features=80, bias=True)
(postnet): PostNet(
(convolutions): ModuleList(
(0): Sequential(
(0): ConvNorm(
(conv): Conv1d(80, 512, kernel_size=(5,), stride=(1,), padding=(2,))
)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Sequential(
(0): ConvNorm(
(conv): Conv1d(512, 512, kernel_size=(5,), stride=(1,), padding=(2,))
)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): Sequential(
(0): ConvNorm(
(conv): Conv1d(512, 512, kernel_size=(5,), stride=(1,), padding=(2,))
)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): Sequential(
(0): ConvNorm(
(conv): Conv1d(512, 512, kernel_size=(5,), stride=(1,), padding=(2,))
)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): Sequential(
(0): ConvNorm(
(conv): Conv1d(512, 80, kernel_size=(5,), stride=(1,), padding=(2,))
)
(1): BatchNorm1d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(speaker_emb): Embedding(218, 256)
)
FastSpeech2各模块实现
FastSpeech2使用前馈形的Transformer块FFTBlock作为encoder和mel-spectrogram decoder的基础结构,FFTBlock是由自注意力层slf_attn和前馈神经网络pos_ffn组成的。
FFTBlock的实现位于/transformer/Layers.py,代码如下:
class FFTBlock(torch.nn.Module):
"""FFT Block"""
def __init__(self, d_model, n_head, d_k, d_v, d_inner, kernel_size, dropout=0.1):
super(FFTBlock, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(
d_model, d_inner, kernel_size, dropout=dropout
)
def forward(self, enc_input, mask=None, slf_attn_mask=None):
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask
)
enc_output = enc_output.masked_fill(mask.unsqueeze(-1), 0)
enc_output = self.pos_ffn(enc_output)
enc_output = enc_output.masked_fill(mask.unsqueeze(-1), 0)
return enc_output, enc_slf_attn
1. Encoder
Encoder主要由词嵌入src_word_emb后接4个FFTBlock组成,其实现位于/transformer/Models.py。
class Encoder(nn.Module):
""" Encoder """
def __init__(self, config):
super(Encoder, self).__init__()
n_position = config["max_seq_len"] + 1
n_src_vocab = len(symbols) + 1
d_word_vec = config["transformer"]["encoder_hidden"]
n_layers = config["transformer"]["encoder_layer"]
n_head = config["transformer"]["encoder_head"]
d_k = d_v = (
config["transformer"]["encoder_hidden"]
// config["transformer"]["encoder_head"]
)
d_model = config["transformer"]["encoder_hidden"]
d_inner = config["transformer"]["conv_filter_size"]
kernel_size = config["transformer"]["conv_kernel_size"]
dropout = config["transformer"]["encoder_dropout"]
self.max_seq_len = config["max_seq_len"]
self.d_model = d_model
#词嵌入
self.src_word_emb = nn.Embedding(
n_src_vocab, d_word_vec, padding_idx=Constants.PAD
)
#位置编码
self.position_enc = nn.Parameter(
get_sinusoid_encoding_table(n_position, d_word_vec).unsqueeze(0),
requires_grad=False,
)
#4个FTTBlock
self.layer_stack = nn.ModuleList(
[
FFTBlock(
d_model, n_head, d_k, d_v, d_inner, kernel_size, dropout=dropout
)
for _ in range(n_layers)
]
)
2. Decoder
Decoder主要由6个FFTBlock组成,其实现位于/transformer/Models.py。
class Decoder(nn.Module):
""" Decoder """
def __init__(self, config):
super(Decoder, self).__init__()
n_position = config["max_seq_len"] + 1
d_word_vec = config["transformer"]["decoder_hidden"]
n_layers = config["transformer"]["decoder_layer"]
n_head = config["transformer"]["decoder_head"]
d_k = d_v = (
config["transformer"]["decoder_hidden"]
// config["transformer"]["decoder_head"]
)
d_model = config["transformer"]["decoder_hidden"]
d_inner = config["transformer"]["conv_filter_size"]
kernel_size = config["transformer"]["conv_kernel_size"]
dropout = config["transformer"]["decoder_dropout"]
self.max_seq_len = config["max_seq_len"]
self.d_model = d_model
self.position_enc = nn.Parameter(
get_sinusoid_encoding_table(n_position, d_word_vec).unsqueeze(0),
requires_grad=False,
)
#6个FFTBlock
self.layer_stack = nn.ModuleList(
[
FFTBlock(
d_model, n_head, d_k, d_v, d_inner, kernel_size, dropout=dropout
)
for _ in range(n_layers)
]
)
3. Variance Adaptor
Variance Adaptor的结构如图b所示,由时长预测器duration_predictor、音高预测器pitch_predictor和能量预测器energy_predictor组成,每个predictor的结构都一样,如图c所示。
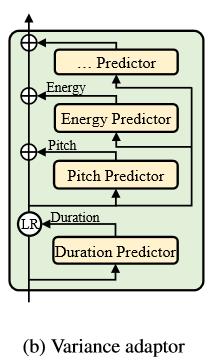
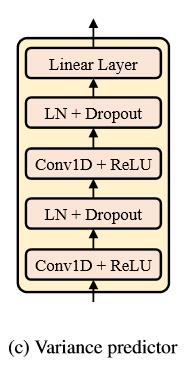
Variance Adaptor的实现位于/model/modules.py,代码如下:
class VarianceAdaptor(nn.Module):
"""Variance Adaptor"""
def __init__(self, preprocess_config, model_config):
super(VarianceAdaptor, self).__init__()
self.duration_predictor = VariancePredictor(model_config)
self.length_regulator = LengthRegulator()
self.pitch_predictor = VariancePredictor(model_config)
self.energy_predictor = VariancePredictor(model_config)
self.pitch_feature_level = preprocess_config["preprocessing"]["pitch"][
"feature"
]
self.energy_feature_level = preprocess_config["preprocessing"]["energy"][
"feature"
]
assert self.pitch_feature_level in ["phoneme_level", "frame_level"]
assert self.energy_feature_level in ["phoneme_level", "frame_level"]
pitch_quantization = model_config["variance_embedding"]["pitch_quantization"]
energy_quantization = model_config["variance_embedding"]["energy_quantization"]
n_bins = model_config["variance_embedding"]["n_bins"]
assert pitch_quantization in ["linear", "log"]
assert energy_quantization in ["linear", "log"]
with open(
os.path.join(preprocess_config["path"]["preprocessed_path"], "stats.json")
) as f:
stats = json.load(f)
pitch_min, pitch_max = stats["pitch"][:2]
energy_min, energy_max = stats["energy"][:2]
if pitch_quantization == "log":
self.pitch_bins = nn.Parameter(
torch.exp(
torch.linspace(np.log(pitch_min), np.log(pitch_max), n_bins - 1)
),
requires_grad=False,
)
else:
self.pitch_bins = nn.Parameter(
torch.linspace(pitch_min, pitch_max, n_bins - 1),
requires_grad=False,
)
if energy_quantization == "log":
self.energy_bins = nn.Parameter(
torch.exp(
torch.linspace(np.log(energy_min), np.log(energy_max), n_bins - 1)
),
requires_grad=False,
)
else:
self.energy_bins = nn.Parameter(
torch.linspace(energy_min, energy_max, n_bins - 1),
requires_grad=False,
)
self.pitch_embedding = nn.Embedding(
n_bins, model_config["transformer"]["encoder_hidden"]
)
self.energy_embedding = nn.Embedding(
n_bins, model_config["transformer"]["encoder_hidden"]
)
Variance Predictor的实现位于/model/modules.py,代码如下:
class VariancePredictor(nn.Module):
"""Duration, Pitch and Energy Predictor"""
def __init__(self, model_config):
super(VariancePredictor, self).__init__()
self.input_size = model_config["transformer"]["encoder_hidden"]
self.filter_size = model_config["variance_predictor"]["filter_size"]
self.kernel = model_config["variance_predictor"]["kernel_size"]
self.conv_output_size = model_config["variance_predictor"]["filter_size"]
self.dropout = model_config["variance_predictor"]["dropout"]
self.conv_layer = nn.Sequential(
OrderedDict(
[
(
"conv1d_1",
Conv(
self.input_size,
self.filter_size,
kernel_size=self.kernel,
padding=(self.kernel - 1) // 2,
),
),
("relu_1", nn.ReLU()),
("layer_norm_1", nn.LayerNorm(self神经网络的理解与实现
github:代码实现之神经网络
本文算法均使用python3实现
1. 什么是神经网络
??人工神经网络(artificial neural network,缩写ANN),简称神经网络(neural network,缩写NN)或类神经网络,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
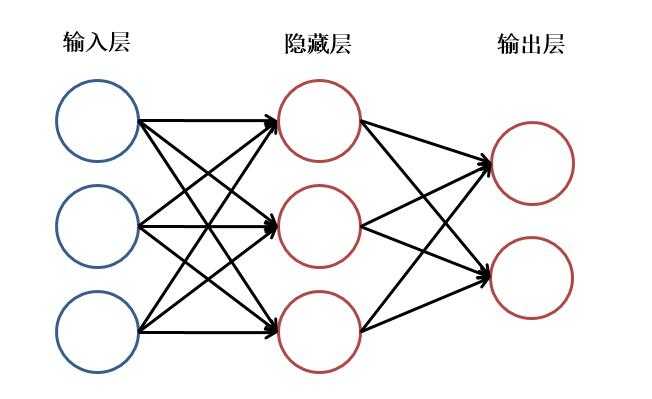
??神经网络主要由:输入层,隐藏层,输出层构成。当隐藏层只有一层时,该网络为三层神经网络,当没有隐藏层时,网络为两层的神经网络。实际中,网络输入层的每个神经元代表了一个特征,输出层个数代表了分类个数,而隐藏层层数以及隐藏层神经元是由人工设定。一个基本的三层神经网络可见下图:
1.1 从逻辑回归到神经元
??为了便于大家理解,我们先回顾一下逻辑回归。逻辑回归模型如下: [ h_ heta(x) = frac{1}{1+e^{- heta^T x}} ]
??其中 $ z = heta^T x = heta_0 + heta_1x_1 + heta_2 x_2 $ , $ h_ heta(x) = g(z) = frac{1}{1+e^{-z}} $
??对此我们可以用以下结构进行理解:
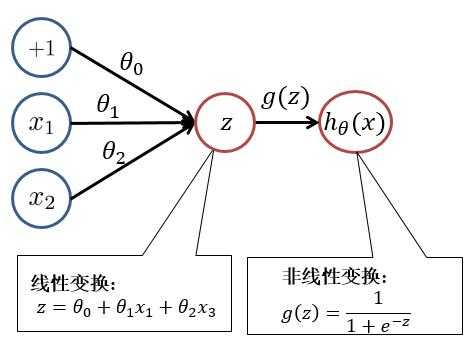
??根据上图,我们可以看出,逻辑回归可以分为线性变换部分与非线性变换部分。而只有输入层与输出层且输出层只有一个神经元的神经网络的结构便于逻辑回归一致。只不过在神经网络中,线性变换(求和)与非线性变换被集成在一个神经元(隐藏层或输出层)中。如下图所示:
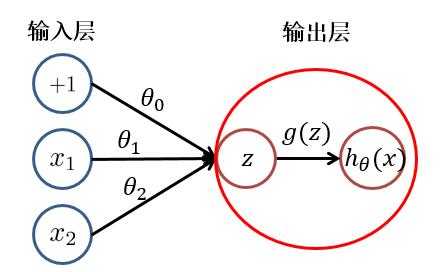
??于是,对于具有多层或多个输出神经元的神经网络就不难理解了。其每个隐藏层神经元/输出层神经元的值(激活值),都是由上一层神经元,经过加权求和与非线性变换而得到的。其中非线性变换函数(又被称为激活函数)可以是: $ sigmoid、tanh、relu $ 等函数。
1.2 神经网络
??根据1.1中所讲述,我们可以得到以下这样一个基本的三层神经网络:
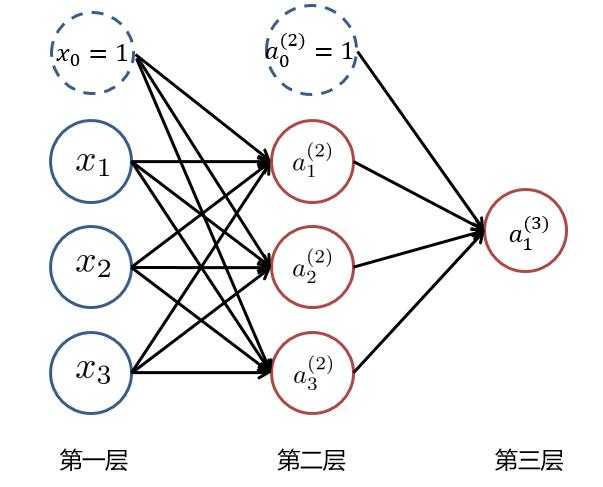
??其中 $ x_i (i=1,2,3) $ 为输入层的值,$ a_i^{(k)} (k=1,2,3...,K;i=1,2,3...,N_k) $ ,表示第 $ k $ 层中,第 $ i $ 个神经元的激活值, $ N_k $ 表示第 $ k $ 层的神经元个数。当 $ k=1 $ 时即为输入层,即 $ a_i^{(1)} = x_i $ ,而 $ x_0 = 1 与 a_0^{(2)} =1 $ 为偏置项。
??为了求最后的输出值 $ h_ heta(x)=a_1^{(3)} $,我们需要计算隐藏层中每个神经元的激活值 $ a_{ji}^{(k)} (k=2,3) $。而隐藏层/输出层的每一个神经元,都是由上一层神经元经过类似逻辑回归计算而来。我们可以使用下图进行理解:
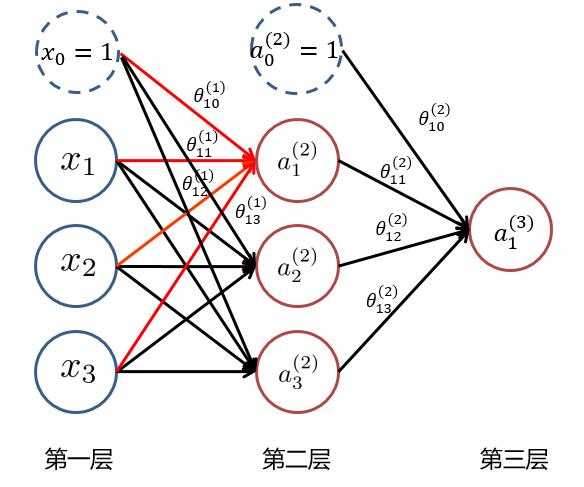
??我们使用 $ heta_{ji}^{(k)} $ 来表示第 $ k $ 层的参数(边权),其中下标 $ j $ 表示第 $ k+1 $ 层的第 $ j $ 个神经元,$ i $ 表示第 $ k $ 层的第 $ i $ 个神经元。于是我们可以计算出隐藏层的三个激活值:
[ a_1^{(2)} = g( heta_{10}^{(1)} x_0 + heta_{11}^{(1)} x_1 + heta_{12}^{(1)} x_2 + heta_{13}^{(1)} x_3) ]
[ a_2^{(2)} = g( heta_{20}^{(1)} x_0 + heta_{21}^{(1)} x_1 + heta_{22}^{(1)} x_2 + heta_{23}^{(1)} x_3) ]
[ a_3^{(2)} = g( heta_{30}^{(1)} x_0 + heta_{31}^{(1)} x_1 + heta_{32}^{(1)} x_2 + heta_{33}^{(1)} x_3) ]
??再将隐藏层的三个激活值以及偏置项( $ a_0^{(2)},a_1^{(2)},a_2^{(2)},a_3^{(2)} $ )用来计算出输出层神经元的激活值即为该神经网络的输出:
[ a_1^{(3)} = g( heta_{10}^{(2)} a_0^{(2)} + heta_{11}^{(2)} a_1^{(2)} + heta_{12}^{(2)} a_2^{(2)} + heta_{13}^{(2)} a_3^{(2)}) ]
??其中 $ g(z) $ 为非线性变换函数(激活函数)。
??到此,我们就大致了解了什么是神经网络了。
1.3 为什么要使用神经网络
??首先,神经网络应用在分类问题中效果很好。 工业界中分类问题居多。LR或者linear SVM更适用线性分类。如果数据非线性可分(现实生活中多是非线性的),LR通常需要靠特征工程做特征映射,增加高斯项或者组合项;SVM需要选择核。 而增加高斯项、组合项会产生很多没有用的维度,增加计算量。GBDT可以使用弱的线性分类器组合成强分类器,但维度很高时效果可能并不好。而神经网络在三层及以上时,能够很好地进行非线性可分。现在我们使用下面的例子进行一下解释。
??有这样一组样本,如下图:
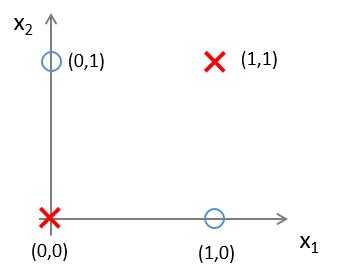

??若我们需要对上图中的样本进行分类,直观来看,很难找到一条线性分类边界对其进行分类,而观察上表中的输入输出值,我们可以看出分类结果与输入值是异或关系。而逻辑回归可以通过改变参数,来实现“与”、“或”、“非”简单操作。
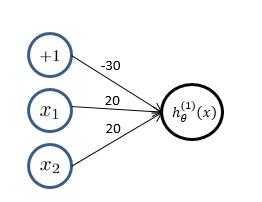
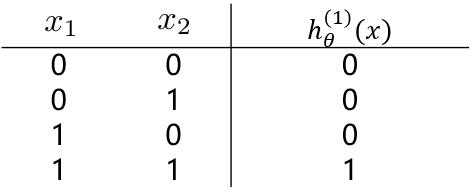
??(1)我们先来观察一下逻辑回归实现逻辑“与”操作,假设模型函数如下: [ h_ heta^{(1)}(x) = g(-30 + 20x_1+20x_2) = frac{1}{1+e^{-(-30 + 20x_1+20x_2)}} ]
????对应结构与结果为:
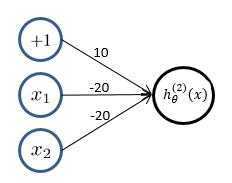
??(2)逻辑回归实现逻辑“或非”操作,假设模型函数如下: [ h_ heta^{(1)}(x) = g(-10 - 20x_1- 20x_2) = frac{1}{1+e^{-(10 - 20x_1 - 20x_2)}} ]
????对应结果为:
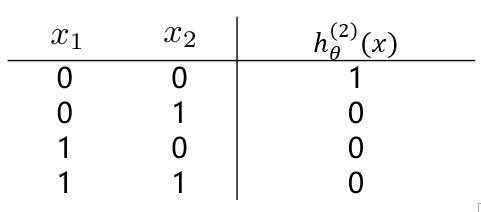
??(3)逻辑回归实现逻辑“或”操作,假设模型函数如下: [ h_ heta^{(1)}(x) = g(-10 + 20x_1 + 20x_2) = frac{1}{1+e^{-(10 + 20x_1 + 20x_2)}} ]
????对应结果为:
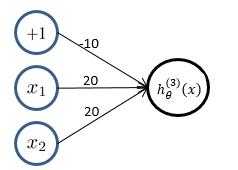
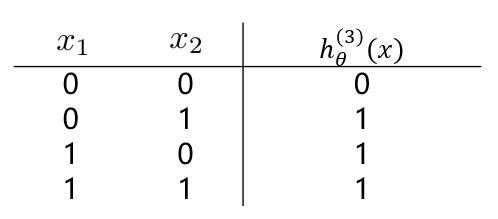
??观察(1)(2)中的 $ h_ heta^{(1)}(x) 与 h_ heta^{(2)}(x) $ 的值,通过“或”操作,便能够得到“异或”操作的结果。
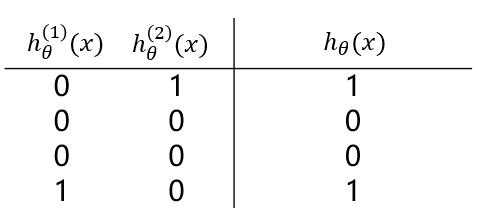
??也就是说,若将三个逻辑回归操作进行叠加,便能够对上述例子进行非线性分类。大致结构图可理解为下:
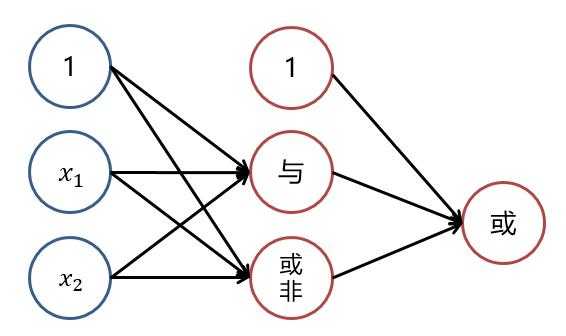
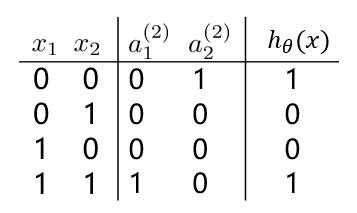
??而对线性分类器的逻辑与和逻辑或的组合可以完美的对平面样本进行分类。
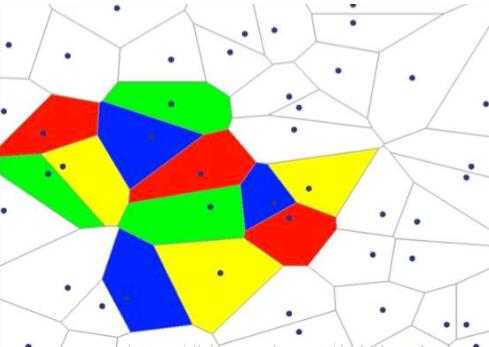
??隐层决定了最终的分类效果 :
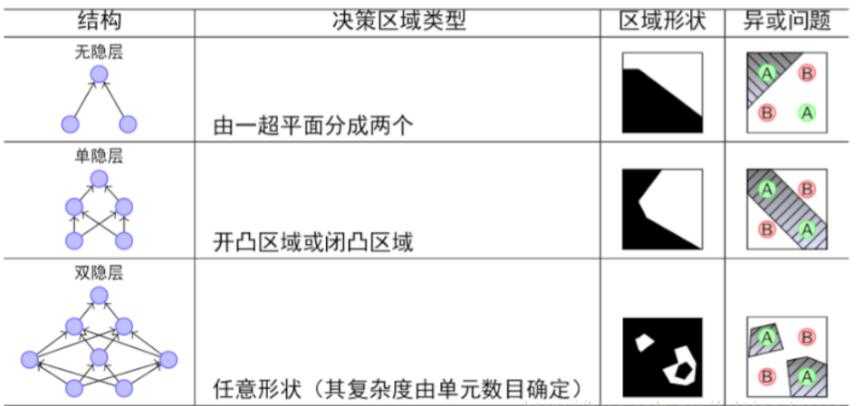
??由上图可以看出,随着隐层层数的增多,凸域将可以形成任意的形状,因此可以解决任何复杂的分类问题。实际上,Kolmogorov理论指出:双隐层感知器就足以解决任何复杂的分类问题。
??于是我们可以得出这样的结论:神经网络通过将线性分类器进行组合叠加,能够较好地进行非线性分类。
2.神经网络目标函数
??同样的,对于神经网络我们也需要知道其目标函数,才能够对目标函数进行优化从而学习到参数。
??假设神经网络的输出层只有一个神经元,该网络有 $ K $ 层,则其目标函数为(若不止一个神经元,每个输出神经元的目标函数类似,仅仅是参数矩阵的不同):
[ J( heta) = - frac{1}{m} [ sum_{i=1}^m y^{(i)} log(h_ heta(a^{(K-1)})) + (1-y^{(i)}) log(1-h_ heta(a^{(K-1)}))] + frac{lambda}{2m} sum_{k=1}^{K-1} sum_{i=1}^{N_k} sum_{j=1}^{N_{k+1}} ( heta_{ji}^{(k)})^2 ]
??其中 $ a^{(i)} $ 倒数第2层的激活值,作为输出层的输入值。而其值为 $ a^{(k)} = g(a^{(k-1)}) $ , $ y^{(i)} $ 为实际分类结果 $ 0/1 $ , $ m $ 为样本数,$ N_k $ 为第 $ k $ 层的神经元个数。
3.神经网络优化算法
??神经网络与普通的分类器不同,其是一个巨大的网络,最后一层的输出与每一层的神经元都有关系。而神经网络的每一层,与下一层之间,都存在一个参数矩阵。我们需要通过优化算法求出每一层的参数矩阵,对于一个有 $ K $ 层的神经网络,我们共需要求解出 $ K-1 $ 个参数矩阵。因此我们无法直接对目标函数进行梯度的计算来求解参数矩阵。
??对于神经网络的优化算法,主要需要两步:前向传播(Forward Propagation)与反向传播(Back Propagation)
3.1 前向传播
??前向传播就是从输入层到输出层,计算每一层每一个神经元的激活值。也就是先随机初始化每一层的参数矩阵,然后从输入层开始,依次计算下一层每个神经元的激活值,一直到最后计算输出层神经元的激活值。
??以下面这个例子来看:
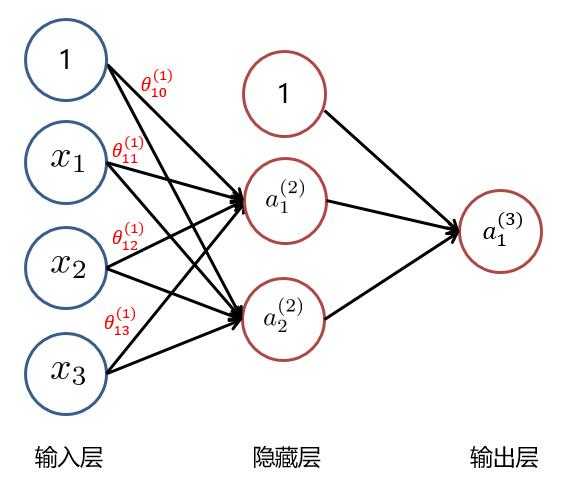
????(1)随机初始化参数矩阵 $ Theta^{(1)} 与 Theta^{(2)} $ :
[ Theta^{(1)} = egin{bmatrix} heta_{10}^{(1)} & heta_{11}^{(1)} & heta_{12}^{(1)} & heta_{13}^{(1)} \\ heta_{20}^{(1)} & heta_{21}^{(1)} & heta_{22}^{(1)} & heta_{23}^{(1)} \\ end{bmatrix}
Theta^{(2)} = egin{bmatrix} heta_{10}^{(2)} & heta_{11}^{(2)} & heta_{12}^{(2)} \\ end{bmatrix} ]
????(2)计算隐藏层的每个神经元激活值:
[ a_1^{(2)} = g( heta_{10}^{(1)} x_0 + heta_{11}^{(1)} x_1 + heta_{12}^{(1)} x_2 + heta_{13}^{(1)} x_3) ]
[ a_2^{(2)} = g( heta_{20}^{(1)} x_0 + heta_{21}^{(1)} x_1 + heta_{22}^{(1)} x_2 + heta_{23}^{(1)} x_3) ]
??????即:
[ a^{(2)} = g(Theta^{(1)} x) ,其中 a^{(2)} = egin{bmatrix} a_1^{(2)} \\ a_2^{(2)} \\ end{bmatrix} , x = egin{bmatrix} x_0 \\ x_1 \\ x_2 \\ x_3 \\ end{bmatrix} ]
????(3)计算隐藏层的每个神经元激活值:
[ a_1^{(3)} = g( heta_{10}^{(2)} a_0^{(2)} + heta_{11}^{(2)} a_1^{(2)} + heta_{12}^{(2)} a_2^{(2)} ) ]
??????即:
[ a^{(3)} = g(Theta^{(2)} a^{(2)}) ,其中 a^{(2)} = egin{bmatrix} a_0^{(2)} \\ a_1^{(2)} \\ a_2^{(2)} \\ end{bmatrix} ]
??以上便是前向传播计算激活值的过程。
3.2 反向传播
??反向传播总的来说就是根据前向传播计算出来的激活值,来计算每一层参数的梯度,并从后往前进行参数的更新。
??在介绍反向传播的计算步骤之前,我们先引入一个概念---除输入层外每个神经元节点的“损失” ,$ delta_j^{k} $ 表示第 $ k $ 层第 $ j $ 个神经元的损失。
??于是我们可以计算求得(除输入层)每一层神经元的损失(以上一个例子来解释):
[ delta_1^{(3)} = a_1^{(3)} - y_1 ]
??其中 $ y_1 $ 为实际值。向量化表示如下:
[ delta^{(3)} = a^{(3)} - y ]
[ delta^{(2)} = (Theta^T) delta^{(3)} cdot ast g'(z^{(2)}) ]
??其中 $ cdot ast $ 表示两个矩阵对应位置上元素相乘 $ g‘(z^{(3)}) $ 是对函数求导。而 [ z^{(2)} = egin{bmatrix} heta_{10}^{(1)} x_0 + heta_{11}^{(1)} x_1 + heta_{12}^{(1)} x_2 + heta_{13}^{(1)} x_3 \\ heta_{20}^{(1)} x_0 + heta_{21}^{(1)} x_1 + heta_{22}^{(1)} x_2 + heta_{23}^{(1)} x_3 \\ end{bmatrix}]
??由上可看出,第二层的损失 $ delta^{(2)} $ 是基于第三层的损失 $ delta^{(3)} $ 计算而来。也就是说,我们可以先计算第三层的损失并对第二层的参数矩阵进行更新,再利用第三层的损失计算第二层的损失以及更新第一层的参数矩阵(至于为何可以这样进行,将在后面进行证明)。
??于是,基于反向传播算法的梯度更新步骤如下:
????(1)计算每一层的损失:$ delta^{k} $(见上面所示)。
????(2)计算每一层的 $ Delta $ (初始化为0):$ Delta^{(k)} = Delta^{(k)} + delta^{(k+1)} (a^{(k)})^T $
????(3)计算每一个参数的梯度: [ D_{ji}^{(k)} = frac{1}{m} Delta_{ji}^{(k)} + lambda Theta_{(ji)}^{(k)} , 如果 i
eq 0 ] [ D_{ji}^{(k)} = frac{1}{m} Delta_{ji}^{(k)} , 如果 i = 0 ]
??也就是说 $ frac{delta J(Theta)}{delta Theta_{ji}^{k}} = D_{ji}^{(k)} $。于是就可以使用梯度下降来进行参数的求解了。
3.3 反向传播的推导
??大家可能都会有疑问,为什么求梯度时,要先对后一层进行计算,并利用其结果来求前一层的梯度?我们将针对如下例子进行推导证明:
??第一层的参数为:
[ Theta^{(1)} = egin{bmatrix} heta_{10}^{(1)} & heta_{11}^{(1)} & heta_{12}^{(1)} & heta_{13}^{(1)} \\ heta_{20}^{(1)} & heta_{21}^{(1)} & heta_{22}^{(1)} & heta_{23}^{(1)} \\ end{bmatrix} ]
??第二层的参数为:
[ Theta^{(2)} = egin{bmatrix} heta_{10}^{(2)} & heta_{11}^{(2)} & heta_{12}^{(2)} \\ end{bmatrix} ]
??我们先来对第二层的参数求梯度 $ frac{delta J(Theta)}{delta heta^{(2)}} $ :
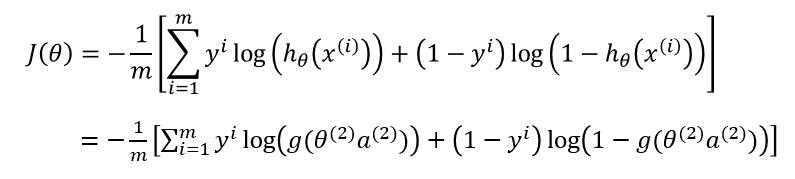
??其中 $ y^i $ 为实际值, $ g( heta^{(2)} a^{(2)}) = a^{(3)} $ 。
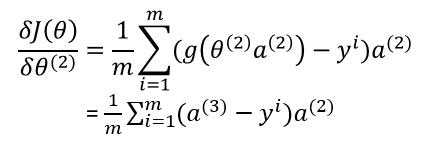
??这一步的推导过程与逻辑回归一样,详细可参考逻辑回归梯度求导过程。
??现在我们来对第一层的参数求梯度 $ frac{delta J(Theta)}{delta heta^{(1)}} $ :
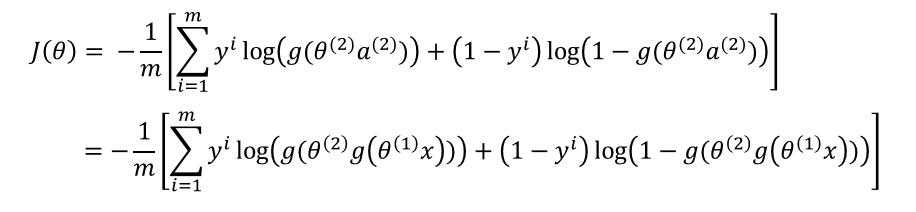
??先对中括号内的求导:
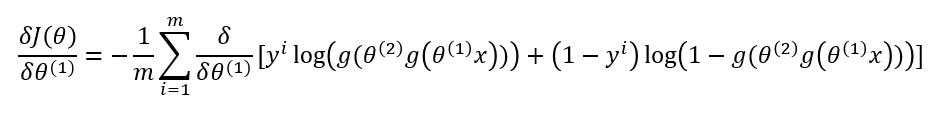

??故:
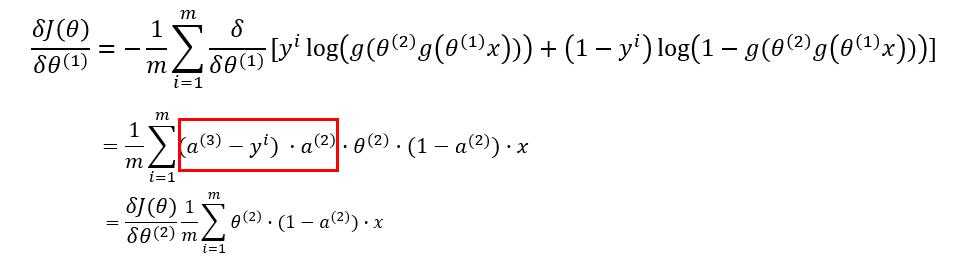
??对比着3.2中的公式,我们可以看出,第 $ k $ 层的梯度可以根据第 $ k+1 $ 层的损失来计算:
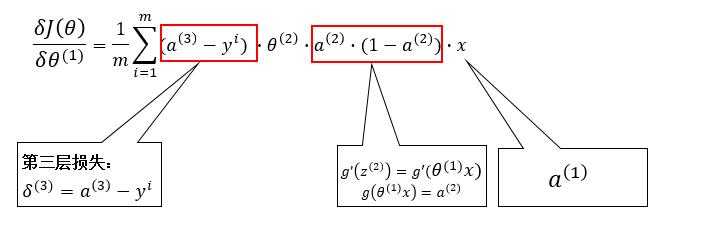
??到此,反向传播的推导过程就完成了。如果对式子还有不理解的,可以自己动手多试试。
4.神经网络算法分析
??该部分参考博文[3]
??(1)理论上,单隐层神经网络可以逼近任何连续函数(只要隐层的神经元个数足够)
??(2)对于一些分类数据(比如CTR预估),3层神经网络效果优于2层神经网络,但如果把层数不断增加(4,5,6层),对最后的结果的帮助没有那么大的跳变。
??(3)提升隐层数量或者隐层神经元个数,神经网络的“容量”会变大,空间表达能力会变强。
??(4)过多的隐层和神经元结点会带来过拟合问题。
??(5)不要试图降低神经网络参数量来减缓过拟合,用正则化或者dropout层。
??注意:在代码中对参数的初始化并不是使用0来初始化,还是在范围 $ [-epsilon,epsilon] $ 间随机初始化。对应代码为:
Theta = np.random.rand(nextUnit, Unit+1) * 2 * epsilon - epsilon
引用及参考:
[1] 《Machine Learning》Andrew Ng
[2] https://www.jianshu.com/p/a3b89d79f325
[3] https://blog.csdn.net/leiting_imecas/article/details/60463897
[4] https://blog.csdn.net/a819825294/article/details/53393837
写在最后:本文参考以上资料进行整合与总结,属于原创,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!
若需转载请注明:https://www.cnblogs.com/lliuye/p/9183914.html
以上是关于FastSpeech2代码理解之模型实现的主要内容,如果未能解决你的问题,请参考以下文章