初识ElasticSearch -批量操作之bulk | 条件查询 | 其它查询
Posted 做猪呢,最重要的是开森啦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识ElasticSearch -批量操作之bulk | 条件查询 | 其它查询相关的知识,希望对你有一定的参考价值。
1. bulk:
可以批量进行增删改,并且某一个操作失败,不会影响其他文档的操作,会在返回结果中告诉你失败的详细的原因
1.1. bulk语法:
- POST /_bulk或POST /<index>/_bulk
- 请求体要使用NDJSON(新行分隔的JSON)结构:JSON串只能放一行,相邻的JOSN串要换行
- 现有行为actions ,再有请求体
1.2. bulk行为-增删改:
- create 如果文档不存在就创建,但如果文档存在就返回错误
- index 如果文档不存在就创建,如果文档存在就更新
- update 更新一个文档,如果文档不存在就返回错误
- delete 删除一个文档,如果要删除的文档id不存在,就返回错误
2. bulk-index批量插入:
【HTTP请求】:往user_term索引批量插入数据,指定文档id分别是1和2
·
【说明】:二者的结果是一样的,_index为索引名,_id为文档id,如果索引不存在会新建索引
·
【API请求】:save或bulkIndex,实体类使用@id,userId的值就是文档id
·


3. bulk-update批量修改:
批量更新update行为时,有以下几种模式
- doc :更新部分文档
- upsert:于script一起使用,文档存在时根据script脚本更新_source,不存在时使用upsert内容进行添加文档
- doc_as_upsert:与upsert类似,文档存在时更新,不存在时将doc的内容作为_source添加文档
- script:按脚本进行更新
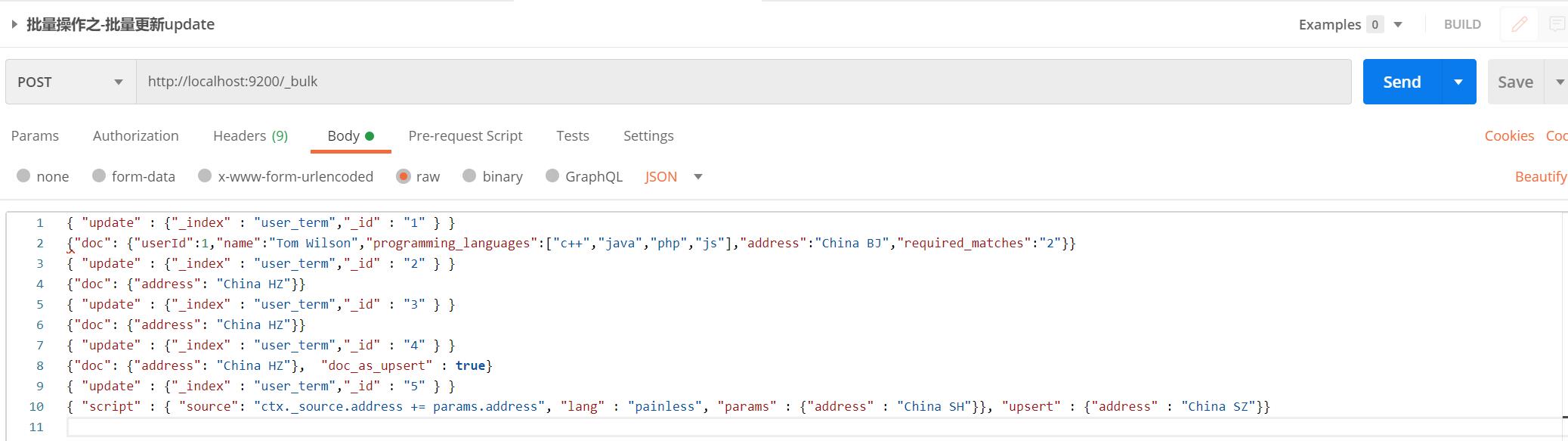
【HTTP请求】:
·
【栗子说明】:
- 将文档id=1的文档,进行多字段局部更新
- 将文档id=2的文档,进行单字段局部更新
- 文档id=3的文档不存在,更新失败404
- 将文档id=4的文档,进行单字段局部更新,由于文档不存在,“address”: “China HZ”作为_source插入新文档
- 将文档id=5的文档,根据script脚本进行单字段局部更新,由于文档不存在,根据upsert内容进行插入新文档
·
【题外】:失败原因会在response显示,也可以使用?filter_path=items.*.error只显示失败内容·
【API请求】:bulkUpdate - 其中一个失败不影响其他操作,但会抛异常
·


4. bulk-delete批量删除:
批量删除文档
·
【HTTP请求】:
·
【API请求】:可以使用terms进行条件删除
·


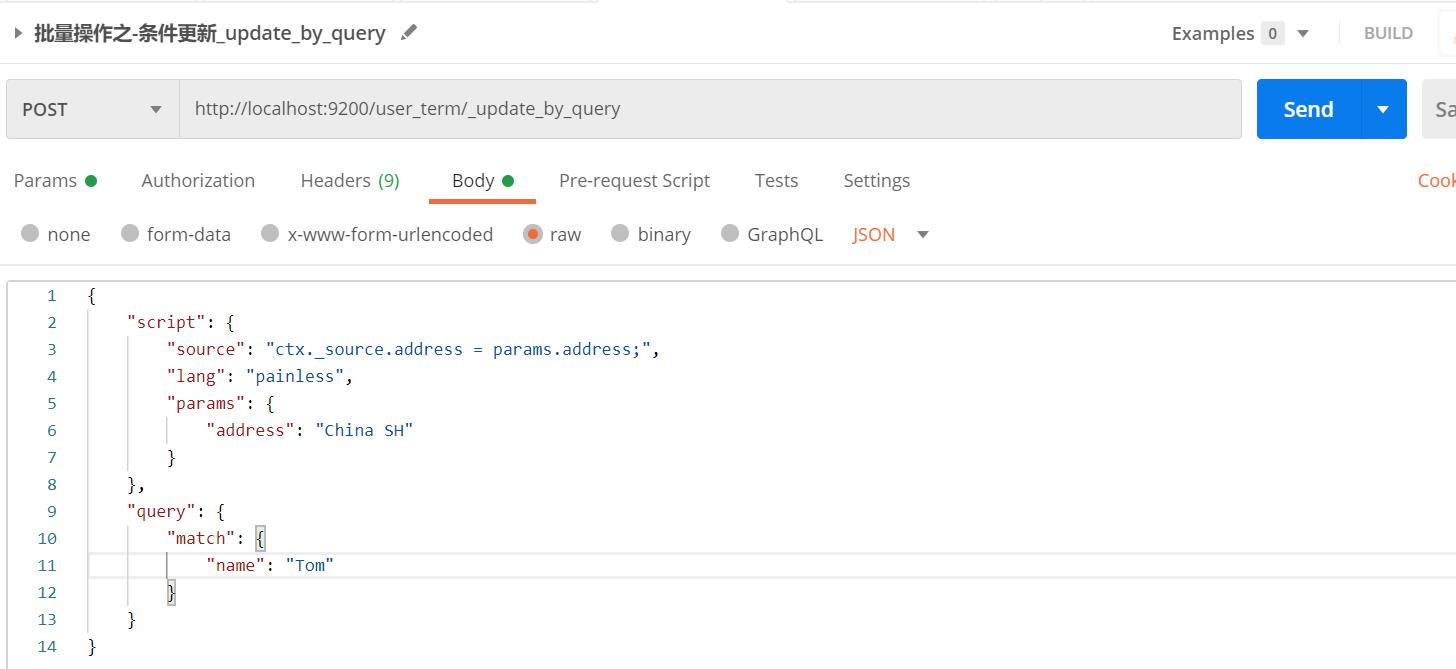
5. _update_by_query条件更新:
根据条件进行更新文档,而非通过文档id进行更新,条件可以使用term、match、bool等匹配方式
【栗子】:匹配修改name包含Tom的文档,批量修改文档地址为BJ
·
【HTTP请求】:
·
【API】:updateByQuery
·

6. _delete_by_query条件删除:
根据条件进行删除文档,而非通过文档id进行删除,条件可以使用term、match、bool等匹配方式
【栗子】:匹配删除name包含Tom的文档
·
【HTTP请求】:
·
【API请求】:
·


7. _mget多文档查询:
根据文档id,从一个索引或者多个索引获取多个文档
- 格式:GET /_mget 或 GET /<index>/_mget
【HTTP请求】:
·
【说明】:
- 可以对结果_source中的字段进行指定显示,比如_source只显示include的字段
- 并不是只有mget可以这样,其它的查询也可以这么指定显示
·
【ids查询】:对于同一个索引根据id进行查询多个文档,可以直接使用ids查询
·
【API请求】:multiGet:同一个索引的mget
·



8. 其它查询:
一些常见的查询,比如范围查询range、分页查询等
8.1. range范围查询:
返回匹配范围区间的文档数据
- gt - 大于;gte - 大于等于;lt - 小于;lte - 小于等于;format - 日期格式化
【HTTP请求】:插入四条文档,查询 2<userId<=4的文档数据
·
【API请求】:rangeQuery构建QueryBuilders
·


8.2. fuzzy模糊/相似查询:
基于term的相似模糊查询,返回与搜索词相似匹配的文档,主要有如下4个参数
- value:搜索词
- fuzziness:允许容错的词数/偏移量,默认是AUTO
- prefix_length:不能被 “模糊化” 的初始字符数,前n个字符与搜索词相同;默认0
- max_expansions: 默认50,该值不宜设置太大,具体含义不太清楚
【数据准备】:插入三条文档,name分别是李嘉图、李嘉欣、王嘉欣
·
【HTTP请求】:搜索李嘉欣
·
【说明】:
- fuzziness为0时,说明不允许容错,那么只能搜索到李嘉欣的文档
- fuzziness为0时,可以容错一个词,那么可以搜索到李嘉欣、李嘉图的文档;如果附加prefix_length为3,那么只能搜索到李嘉欣
- prefix_length为0时,3个文档都可以搜索到
·
【API请求】:fuzzyQuery构建QueryBuilders
·
【match.fuzzy】:match中也支持fuzzy模糊查询,如下:
·
【API】:
·




8.3. exists文档是否存在查询:
如果exists匹配的字段不为null或[],就能搜索出文档
【数据准备】:插入4条文档,programming_languages分别是[]、[“”]、null、[“java”]
·
【HTTP请求】:
·
【API请求】:existsQuery构建QueryBuilders
·


8.4. from/size分页查询:
根据from和size进行数据结果分页;其中from= (页码-1) * size
【数据准备】:插入4条文档,userId为1,2,3,4
·
【HTTP请求】:查询第2页数据,每页2条,按userId降序
·
【说明】:
- sort、from、size和query同一层级,会先排序再分页
·
·【API请求】:withPageable
·
【说明】:
- 这里的page和HTTP请求的from不一样,这里的是页码,是从第0页开始的,也就是第一页其实page=0


8.5. wildcard通配符查询:
支持*通配符查询,如下匹配name为李 开头的文档
·
【HTTP请求】:
·
【API请求】:wildcardQuery构建QueryBuilders
·


8.6. 聚合查询:
另起文章,链接后续再补
以上是关于初识ElasticSearch -批量操作之bulk | 条件查询 | 其它查询的主要内容,如果未能解决你的问题,请参考以下文章