AI绘画(以后也叫AI视频)
Posted 天府云创
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI绘画(以后也叫AI视频)相关的知识,希望对你有一定的参考价值。
大概半年前,AI 绘画工具 Disco Diffusion 从 Text-to-Image 开发社区和设计行业,火到了普通用户的视野中。即便它界面简陋,满屏英文和代码,也“劝退”不了人们。因为对那些没有任何美术功底的他们来说,往输入框写一小段字,就能指导 AI 生成画面足够惊艳的画作。[一夜之间,四家科技巨头接连公布AIGC最新进展,加上前不久刚刚发布的GPT-4、微软365 Copilot以及百度文心一言等产品,今天谷歌也高调宣布Bard,这场“AI战争”已经进入了白热化阶段。除了聊天机器人以外,AIGC另一个大热方向便是AI绘画。这也便是本文需要阐述的内容。]
人工智能绘画,神秘、绚丽、深沉、复杂、时代感强,体现出了非凡的想象力。象征未来绘画的发展方向。(图文也是传播重要的途径,所以图片生成显得尤为重要)
在国内的一些平台中,也有AI作画的网站,只要画上几块钱,就能得到一副AI绘画作品。不过作品的质量良莠不齐,有的惟妙惟肖,也有的画的很抽象。但这仍然不妨碍大家对AI作画的喜爱。
AI作画其实并不是新兴的产业,早在计算机诞生之后就已经有艺术家在研究这项技术了,而且随着科技的不断发展和人工智能的进一步升级,AI作画的准入门槛也变得更低,受众人群也有了更广泛的基础。
目前市场上AI作画产品层出不穷,百家争鸣,也有套壳,可圈可点。比较出名的有:
【国内的】
- 抖音AI头像和图文一键生成工具
- 百度文心一格的根据条件自动生成图画
- 百家号根据图文一键输出短视频
【国外的】
- Adobe公司推出的Adobe Firefly (深度和Adobe Photoshop等产品进行集成和捆绑)
- INValid英伟达退出的get3D、canvas等图像生成工具
- AI绘画工具Midjourney V5正式上线
本文关键词:canvas、firefly、bard、chatgpt、bing、文心一言、AIGC、get3D
AI绘画是现在非常火热的 AI领域。而说到 AI的绘画,可能很多人还不太了解。本文将从 AI的绘画原理、 AI绘画模型三个方面来介绍当前 AI最热门的几个绘画领域的知识。在今天这篇文章中,我们将详细介绍 AI绘画的原理、画质、使用场景等知识。
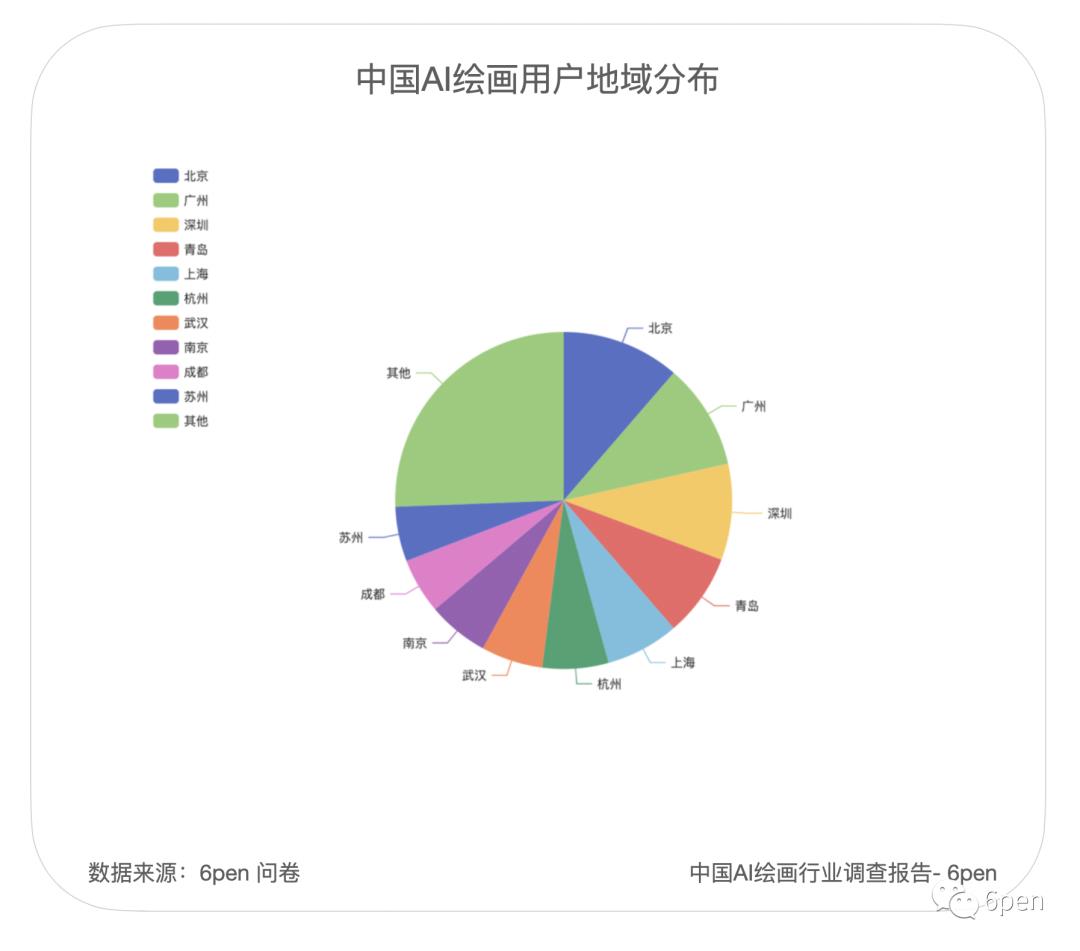
从城市分布上,绝大多数用户还是分布在一二线城市,其中北京占8.7%,深圳占7.8%,但青岛出人意料的排在了第四,占到了6.1%。南方城市占绝大多数,北方城市较少。
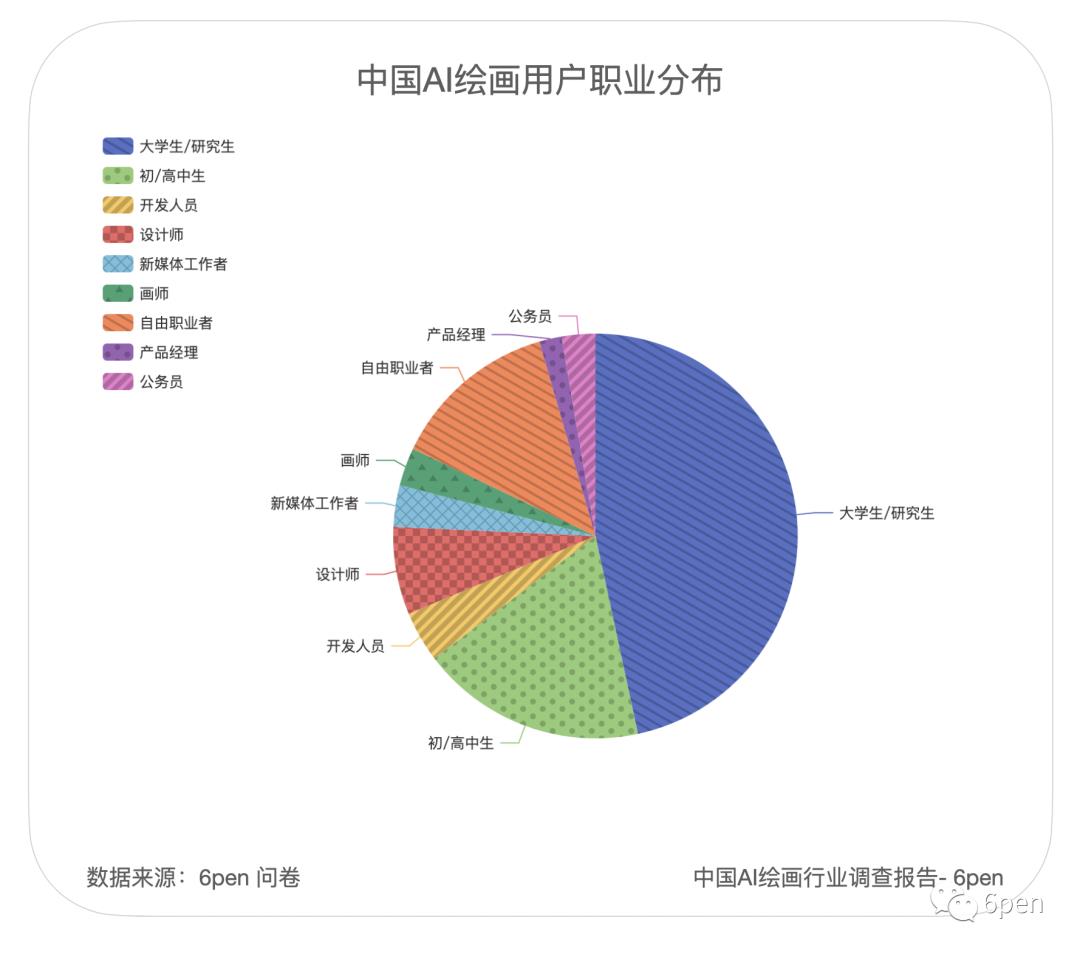
在受众用户的行业分布上,调查结果和我们预期差异较大,美术和设计工作者仅仅只占 24.2%(排名第二),排名第一的行业是线下行业(26%),排名第三的是互联网行业(24%)。

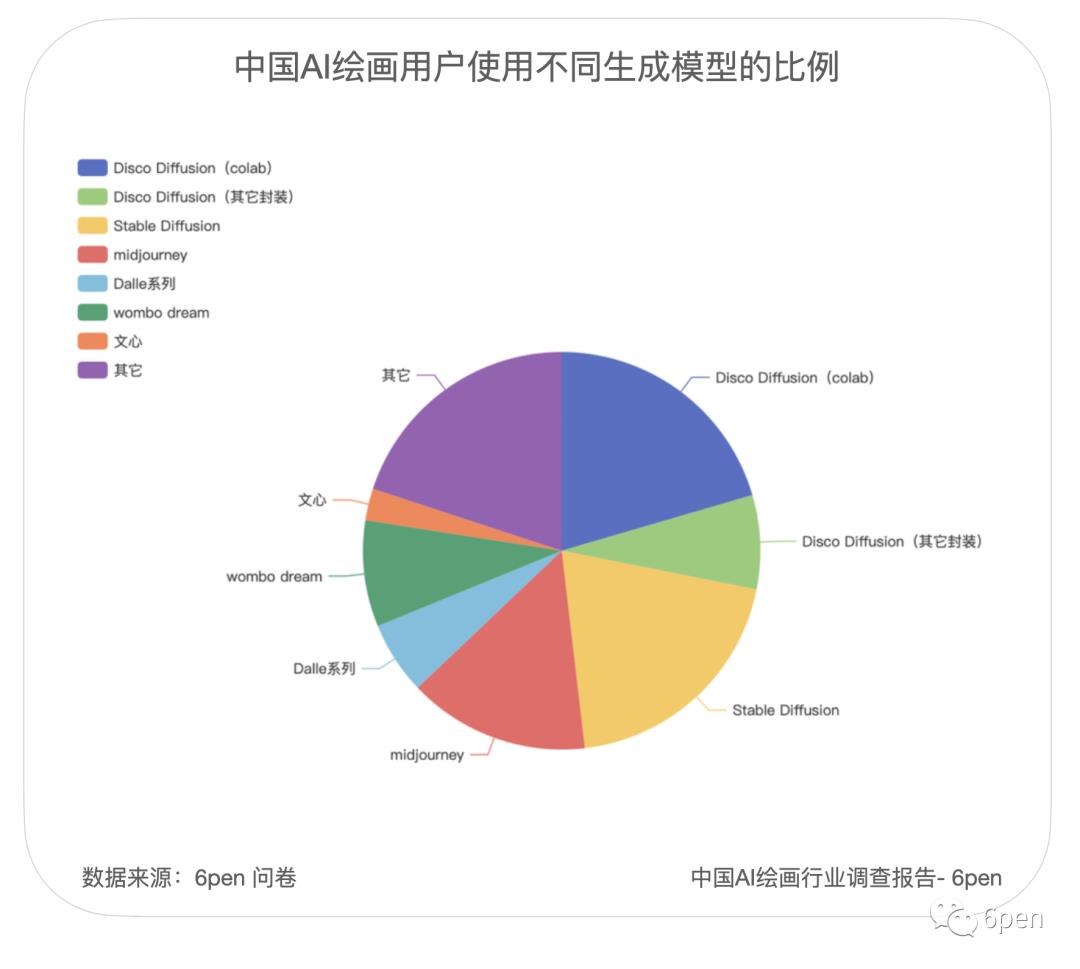
在使用AI绘画的具体方式上,38% 的用户只使用在线服务,使用自己显卡的用户占到16%,即便如此,依然有21%的用户表示,虽然目前自己使用在线服务,但未来希望使用自己的显卡,与之相反,现在使用显卡,并表示未来会使用在线服务的用户,只占 4%。

绘画原理
在很多人眼里, AI的绘画原理是类似于人类的写生,不过这里所说的“AI”不是普通的 AI,而是“AI+ CAD”。在传统的 CAD软件中, CAD是用来绘画的,在 CAD软件中,模型首先被输入到电脑中,在电脑中通过投影功能将模型投影到空间中,再经过多维空间分析后,将得到模型想要的图案和形状。CAD可以通过生成与真实物体相似或不同的物体来表示其形状。
绘画模型
在 AI方面, AI模型(Intelligent Machine)的含义是 AI的自动建模, AI自动建模指的是人工智能系统中的绘画模型的模拟,即人工智能系统在模拟绘画的时候,对各种图像进行训练,从而获得自己的所画的图片,并将这些图片进行合成处理,使之成为具有一定水平的绘画。目前, AI绘画主要分为两大类: AI自然语言理解模型和 AI自适应图像识别模型。自然语言理解模型(NLP)能够自动理解人的语言而不是计算机语言,它利用图像中的每个像素来描述所画的对象。而自适应图像识别模型(ALP)能够利用图像中识别出物体位置和角度的数据来对图像进行分类和修改。ALP和 ALL具有相同的优点,即能够根据数据中颜色或像素不同而改变其颜色或角度。ALP识别了图像中每个物体的位置和角度变化对于图像的影响并进行自动优化。
AI绘画技术发展的简要脉络—算法模型演变:
GAN时代—>CLIP 跨模态的图文模型(VQGAN+CLIP 或StyleCLIP)—>Diffusion 崛起—>Stable Diffusion(latent diffusion模型) —>6pen—>GPT时代
使用场景
当前 AI技术应用在不同的领域中,能够运用到的使用场景也不尽相同。比如在传统的绘画领域中,我们常常需要对物体进行各种处理才能让整个画面呈现在眼前,所以需要通过绘画模型进行优化,然后再对画面进行调整。而在 AI绘画领域,其应用场景更加广泛,比如在 AI图像识别方面,我们可以利用其深度学习的特性来处理人脸等物体的3D模型识别。
使用效果
AI的绘画主要包括两个部分,一个是对图像的分析与判断,另一个是图像的处理与还原。人工智能中的图像分析与处理技术就是利用计算机视觉去提取物体的纹理信息,然后通过神经网络对其进行深度的图像分类和处理。而在 AI绘画方面,人工智能也主要应用在图像的识别与还原。
根据使用者的输入条件(文字/语音)+ 调用大模型已训练的参数(语言语义语法) + 根据图形图像渲染库中已有的画风模型(预先设置的水墨画/卡通形象/抽象派/写实风)+通过对CV算法的整体调优以及修编图 = 最终输出一副具有AI色彩的图画 <如果不满意还可以多生成一次,选择使用者最满意的那张,同时也增加了一次机器学习真实数据的机会>
发展现状
目前,通过深度学习和图像处理技术, AI已经在图像识别、图像合成、人脸识别、视频分析、语音识别等多个领域都取得了巨大进步。随着深度学习技术的快速应用,将给人工智能带来更大的想象空间,尤其是在图像识别、视频分析等领域,将会有巨大的进步。但在 AI绘画方面, AI还需要不断的探索,提升效率,从而满足更多领域的需求。
怎么玩转
博主就市场一些软件工具"根据文本提示生成图像,并提供数百种样式供设计师调整",简单列举一些基本玩法和简单自评:
- Midjourney虽好,但使用起来还是有些门槛,包括硬件支持、调教数值等等,另外还需要用户有一定的美术素养。(该工具和文心一格一样需要用户自己去调参)
-
对于普通用户来说,想体验简单的AI创作怎么办,Adobe公司官方表示;“咱直接集成到PS里(最新付费版)!” 据可靠消息,该系列的AI工具统称为Firefly(Express已经上线)。
-
从演示来看,Firefly虽然不如Midjourney来得惊艳,但实用性拉满。对于普通用户来说,如果熟练掌握这套工具,足以应付日常需求。Adobe也表示,AI并不会取代创意人才,而是提升他们的竞争力和创造力。
-
英伟达宣布与多家云服务供应商合作,推出英伟达DGX Cloud,使得企业不需采购或拥有服务器,只需通过云服务供应商合作托管的DGX Cloud基础设施,通过浏览器,即可取得超算计算机级的AI运算效能。
-
AI 绘画工具进化的速度,在这半年远超人们想象。Disco Diffusion 之后,搭在 Discord 群聊上的 Midjourney、OpenAI 擅长写实的 DALL·E 2、开源的 Stable Diffusion 等工具涌现,它们更强大,更用户友好,生成一张图的时间甚至压缩到了数秒。
AI 绘画的热度被一步步推高。在国内一些电商平台,你甚至可以看到有零散商家在卖教程。
今天,我们整理了 3 个对普通用户来说最容易上手的工具:它们中一个专于生成二次元画作;一个社区氛围浓厚,生成图艺术感极强;一个是国内团队的产品,这回给力,你用中文对就是咱们的母语中文(非英文)尽情挥洒创意!
Stable Diffusion
Stable Diffusion 开源的潘多拉魔盒 在 Stable Diffusion 之前,开源方案里最好的AI绘画实现毫无疑问是 Disco Diffusion
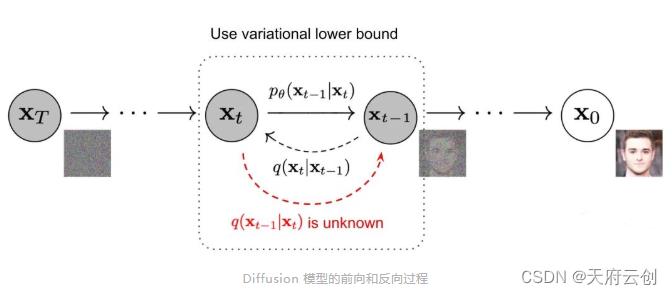
特点:被认为是最强的 AI 绘画工具,已完全开源,市面上还有很多”魔改版“,比如专用来生成二次元人像的 Waifu Diffusion;
事前准备:以下介绍的是 Stable Diffusion 的在线版本 DreamStudio,这种方案对设备没有要求,只要用浏览器打开 https://beta.dreamstudio.ai/dream 即可。
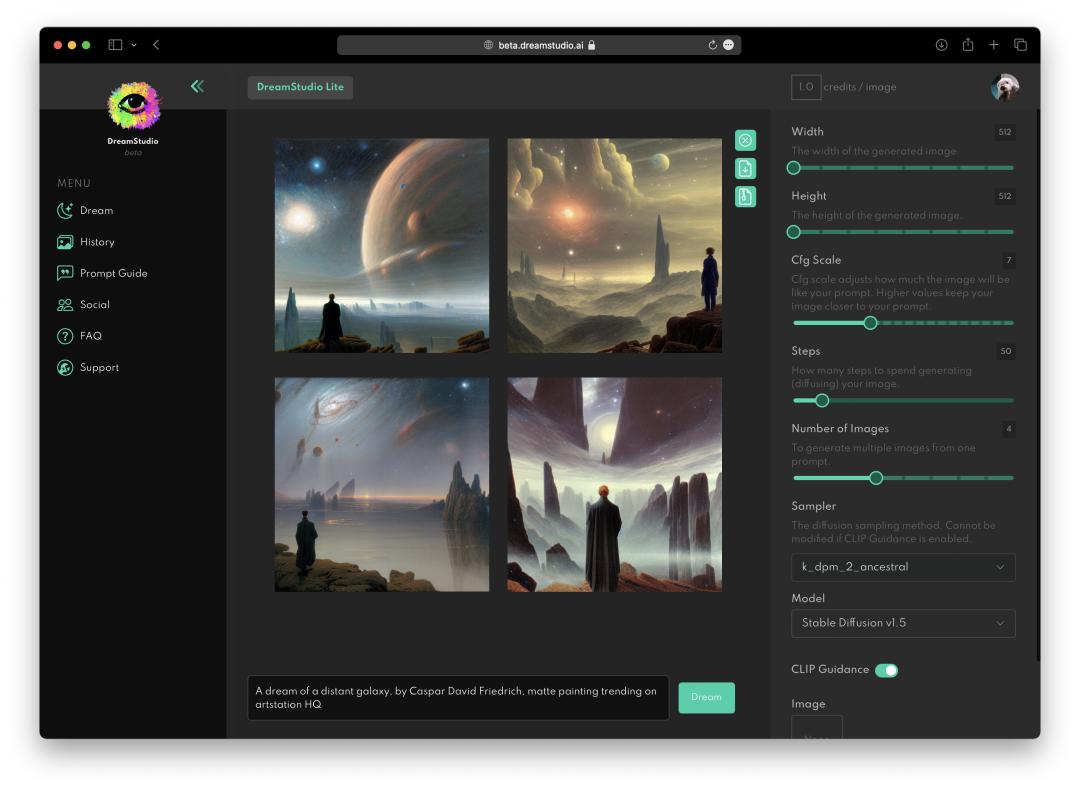
相比 Disco Diffusion,Stable Diffusion 这个在线工具的界面非常简洁、友好,你打开网站后注册,然后在底下的输入框写好描述语句,点击“Dream”就能一键生成,等待时间仅为数秒。
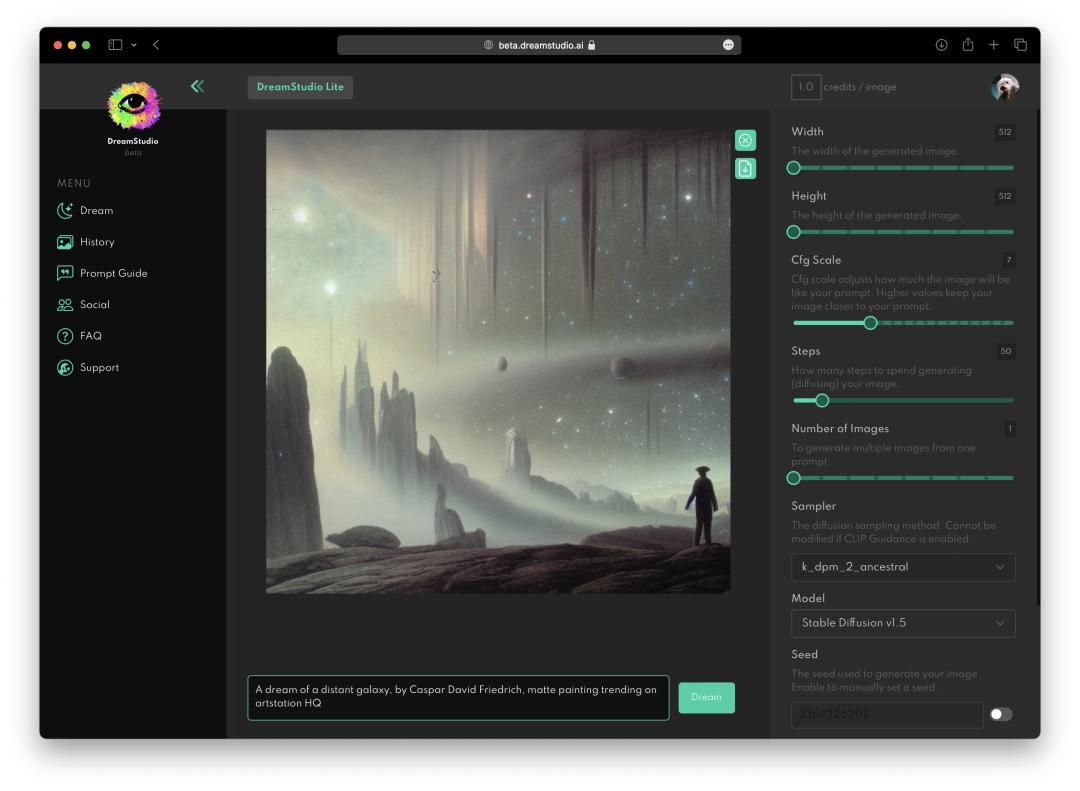
描述词为 A dream of a distant galaxy(图像主体), by Caspar David Friedrich(艺术家), matte painting trending on artstation HQ(绘画风格)丨界面截图
界面右侧还有一系列的调节选项,从上到下分别是:
Width、Height:生成图的长宽尺寸;
Cfg Scale:大概可以理解为是图像和描述词(prompt)的匹配程度,高于 20 容易有失真效果;
Steps:模型生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去比对描述词和当前结果,默认值为 50;
Number of images:生成图的数量;
Sampler:扩散去噪算法的采样模式;
Seed:随机种子,系统每次产生的随机种子都不同,所以即使你原封不动搬来了艺术家给的描述词,也无法生成相同的图片,但如果他给了你特定的随机种子码,就能生成。
基本的配置搞定后,开始做画作生成中最关键的一步——写描述词。该怎么写呢?官方提供了一份入门教程:
先输入你图像的对象、主体,比如一只熊猫、一个持剑的战士,如果只是如此简单的描述,生成的风格会非常随机,所以需要描述风格来加以限定;
常被使用的风格有写实、油画、铅笔画、概念艺术等,你可以指定你要的是一幅画(a painting of + raw prompt)还是一张照片(a photograph of + raw prompt);
加上风格鲜明的艺术家关键词,来进一步明确和加强生成图的风,比如加上达芬奇、米开朗基罗、莫奈等,另外,官方还建议尝试混合多个艺术家,这或许可以融合成更让人惊叹的效果;
还可以加上一些特定的描述词,来完成最后的润色。比如,你如果让画面有更逼真的光照,可以带上“Unreal Engine”,建议的关键词还有 surrealism(超现实主义)、sharp focus(有锐利的对焦)、8k,甚至是“the most beautiful image ever seen”。
在线版本目前调教功能偏弱,比如无法批量生成图像等,如果你想有更好的生成体验,可以将已开源的 Stable Diffusion 部署到自己的电脑上,配置要求 RTX 2060 显卡等 6GB 显存(及以上)显卡等。这里不展开了。
自 Stable Diffusion 开源以来,市面上迅速出现了它的各种“魔改版”,其中近期热度最高的要数 Waifu Diffusion。Waifu 指漫画、动画、游戏中的一些女性角色,有些玩家、观众喜欢这类角色到了会将她们当成妻子。可见,这是一个专于生成“纸片人”的模型。
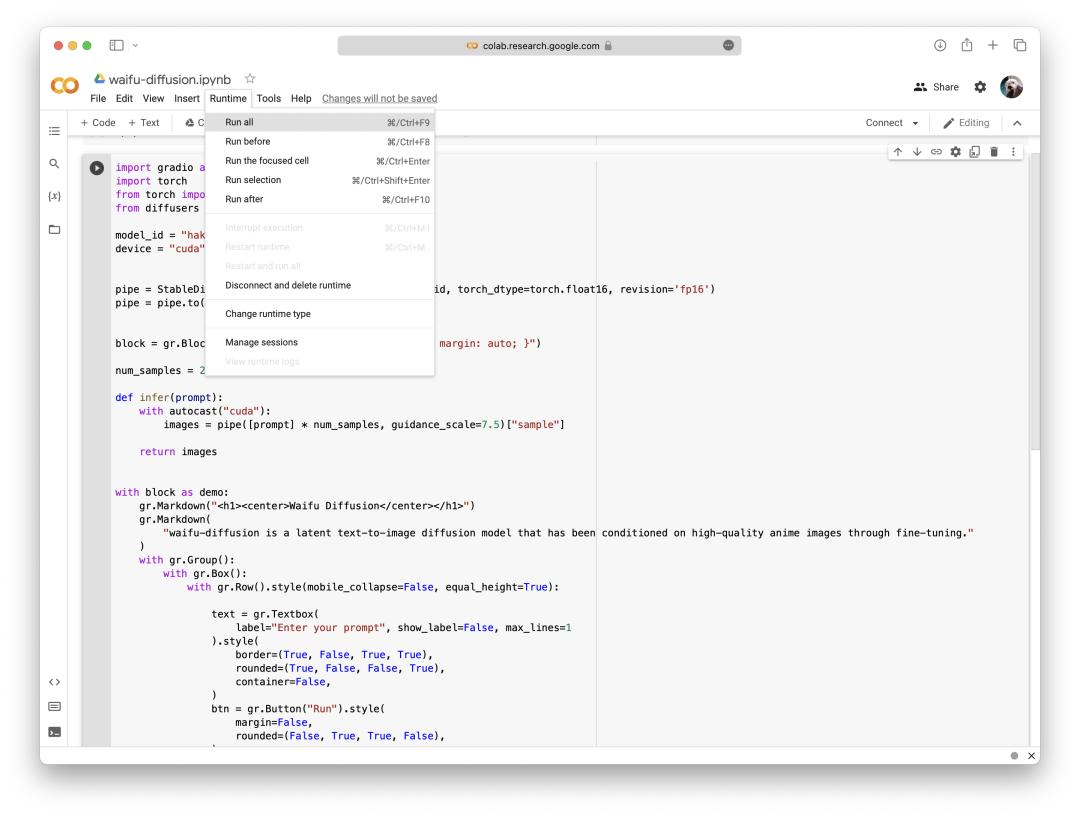
只要打开 https://colab.research.google.com/drive/1_8wPN7dJO746QXsFnB09Uq2VGgSRFuYE#scrollTo=1HaCauSq546O,然后点击上方的“全部运行”,等几分钟就能看到描述词的输入框。

界面截图
至于描述词参考,可以在 Twitter 上搜索“waifudiffusion ALT”,之后你就会看到玩家们的图像,图像上如果有 ALT 标识,点开即可找到生成图的描述词。

界面截图
在 Stable Diffusion 上试验 AI 作画的人太多了,各渠道累计日活用户超过 1000 万。创始人 Emad Mostaque 说,“我们迟早会到达每天生成 10 亿张图片的阶段,尤其是当动画生成的功能被解锁后。”
现在,甚至有人建起了 AI 作画关键词相关的搜索引擎,比如 KERA。

界面截图
目前,KERA 已经收录了百万条关键词,比如搜索“Elon Musk”就能得到以上结果,如果对某一个结果感兴趣,还可以点进去看看对应的描述语句。
收费标准:有大概 200 张的免费生成额度,之后需要付费购买点数(生成越复杂,尺寸越大,消耗的点数越多)
版权要求:可以商用自己创作的图像,但图像如果是通过 DreamStudio 生成的,就自动变成了 CC0 1.0 授权,这样,服务提供商 Stability.ai 也能处理你的图像,无需付费甚至不会经过你同意,也会一并成为通用公共领域 royalty-free 的图片资源。如果是你自己部署了开源的 Stable Diffusion,消耗的是你自己的 GPU 资源,那著作权都归你所有。
Midjourney
特点:可以边聊天边生成,社区氛围浓重,画作艺术感强;
事前准备:备好电脑,以及注册一个通讯软件 Discord 的账号,打开 https://discord.gg/midjourney。
点击上方链接进入官方服务器后,你在左侧频道列表中找到任意一个 #newbies 频道进入,然后在对话框输入/imagine,在其后出现的填空框里输入描述词,按下回车。Midjourney bot 会在 60 秒内生成 4 张图像。
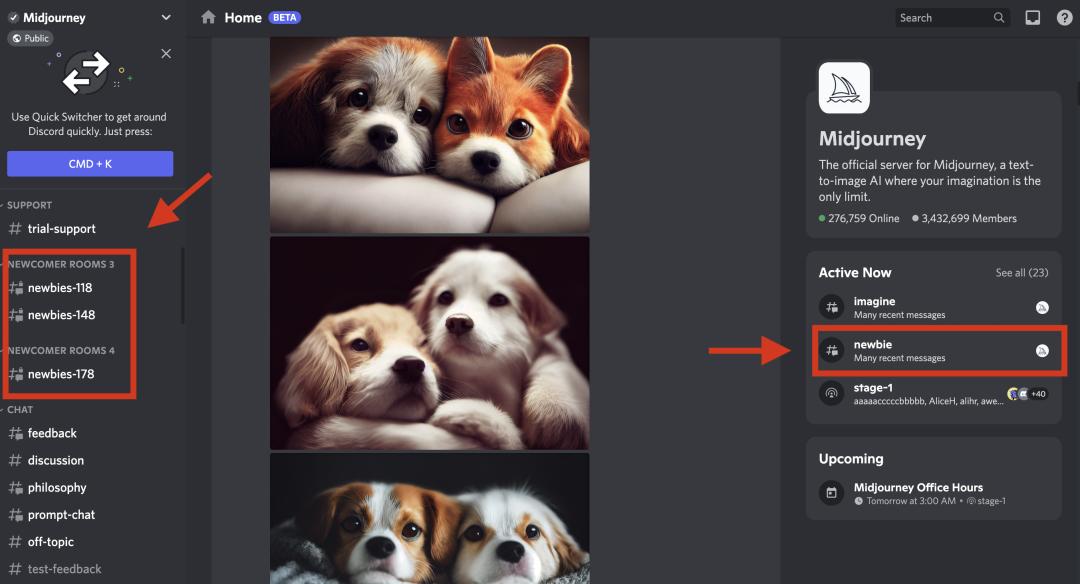
如图所示的红框内,是属于我们 #newbies 的频道 | Midjourney 页面截图
图像生成后,下方会附带 4 个“U”和 4 个“V”选项,U 代表 upscaling(提升清晰度),V 代表 variations(基于已生成图像的风格再生成四张不同的图像)。你可以点击它们进一步优化图像。

描述词为埃德加·艾伦·坡的塔罗牌,新艺术风格,安妮·麦卡弗里 --s 1250 | Midjourney 页面截图
Midjourney 设在一个人声鼎沸的聊天室,初次接触 Discord 的人或许会有些晕头转向,这里有几点需要注意:首先,你在公开的频道里试用时,生成结果是所有人可见的!同时,你的请求可能会混入快速变化的信息流,不要走开!如果真的找不到了,不要慌张,点击右上角的收件箱找回你的请求。

任意时间点进去,都有很多人在跟你一起玩 | Midjourney 页面截图
对于描述词,官方给出了一些建议:
使用已经存在大量视觉图像的物体,比如 Wizard(巫师)、Angel(天使)、Rocket(火箭)等;
使用风格、艺术家、绘画媒介作为提示词,比如赛博朋克、达利、吉卜力、水墨画、雕塑等;
避免否定句,因为模型通常会无视它,比如当你输入“一顶不是红色的帽子”,模型看到的更可能是“帽子”、“红色”;
使用单数或具体数字,而非“一堆”、“很多”、“一些”;
避免空泛概念,你知道的,就是老板开会时经常会说的那些,以及甲方的需求。

火龙,但是建筑草图风格
真正的“高玩”还可以加入一些“黑话”,也就是一系列以“--”为前缀的提示词为图片设定条件。比如,输入--ar 16:9”,图片比例会变成 16 乘 9;输入“--s”加一个数值,你可以决定 AI 要在风格化这条路上走多远,数字越大越离谱,--s 60000,天知道会发生什么!”
实在写不动描述词了,或者某张图片符合你想要的感觉,也可以直接把图片链接写进描述词里。
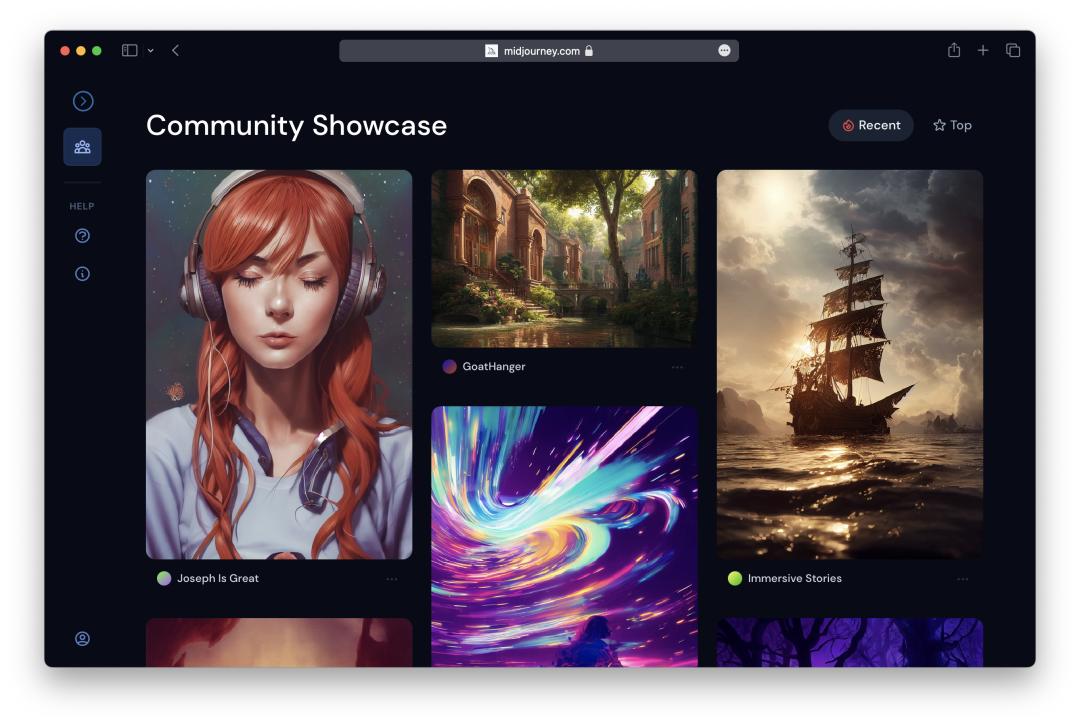
看看别人是怎么写的是个很好的学习渠道。当然,你也可以随时在 #prompt-chat 频道礼貌请教:我想生成特定样式的图像,该用怎样的提示词呢?或者常在官方画廊(https://www.midjourney.com/showcase/)那里逛逛,可以参考自己与别人生成的作品。
与别的模型相比,Midjourney 以其艺术性闻名。有人如此评价,“Midjourney 就像一个有它自己风格的艺术生。”身上附着着成百上千艺术家先辈的魂灵。
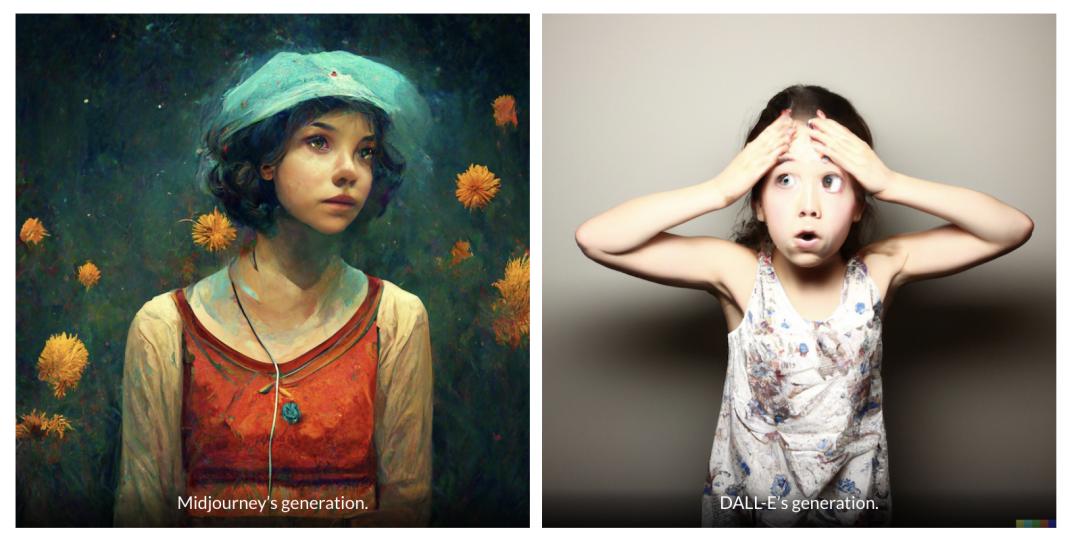
从生成结果也能看出,不管你输入什么,Midjourney 都更倾向于给你输出一幅绘画一样的图像,而不是假照片。比如,同样是面对描述词“女孩发现生命的意义”,Midjourney 和 DALL-E 得到的分别是以上的样子|https://dallery.gallery/midjourney-guide-ai-art-explained/
这也让它备受美术领域青睐,此前广受争议的在数字艺术比赛上获奖的作品《太空歌剧院》就是由 Midjourney 生成(后用 Photoshop 润色)。

《太空歌剧院》|Jason Allen
新平台层出不穷的情况下,让 Midjourney 仍能保持吸引力的是它的超级社群——目前人数已经超三百万,远超原本占据头部的 Minecraft 和《堡垒之夜》。在红杉总结的当前 AIGC 创业图谱中,只有 Midjourney 同时具备了图像生成和消费者 / 社交两项特性。
社群里,人们会自发地为新手答疑解惑,互相称赞,大方分享自己使用的描述词。官方也会定期发起主题创作,举行 Office Hour。用创始人的话说,他想让人们体验“一起做一件事”的快乐:你“画”出一只“狗”,有人会添一笔把它变成“太空狗”,紧接着有人把它变成“阿兹特克太空狗”……
你能不能在 Midjourney 里用中文呢?也不是不可以,但它似乎不是很懂。
收费标准:任何人都可以免费在公共频道生成 25 张图片,之后继续使用需要会员订阅。基础会员价格为每月 10 美元,可生成 200 张图片;标准会员为每月 30 美元,生成次数不限。
版权要求:公共频道里生成的作品默认为 CC BY-NC 4.0 版权,意味着他人可任意使用或改动你的这些作品。付费用户可以任意商用生成的图片,但有一个例外,如果是一家年收入超 100 万的公司在使用,就需转而订阅企业会员。
6pen
特点:支持用中文描述,还列出了很多艺术家和风格限定词供参考;
事前准备:在 ios 平台下载 app,或者打开 https://6pen.art/ 直接在网页生成。
Disco Diffusion 大火之后,国内一些团队开始尝试降低其使用门槛,将它产品化,比如说重整 UI、提供云端算力、对模型做 finetune(微调)等。6pen 就是其中一支团队。
6pen 基于市面上已有的开源模型 Latent Diffusion 和 Disco Diffusion,做了自研模型,还根据生成速度和体量,分别研发了擅长小体量、简单场景的南瓜模型,和擅长复杂场景,但响应速度较慢的西瓜模型。官方表示,相比原版,自研模型比较重要的优化部分,是提高分辨率和支持中文。
6pen 很自信,在合适的文本描述和风格修饰下,他们相信 6pen 可以实现不输于 Midjourney 甚至 DALL·E 2 的效果。

界面简洁,引导细致,还列出了很多艺术家和风格限定词供参考丨app 界面截图
官方自己有一份非常详细的使用教程,手把手教,亲切地像生怕你学不会的老母亲。
我们整理了这样一些建议:
你可以直接使用中文描述!
描述词要具体,讲出你要的物体和它的特征,但物体不要太多,两到三个就好;
放弃描述情绪和事件,模型不会懂什么是“她爱不爱我”并画下来;
视角、细节和纹理、物体占据画面的大小、色调、画面特点、年代、渲染 / 建模工具,这些是模型可以处理的信息;
如果点选的参考艺术家画过很多裸体,会有概率出现纯黑的图片(系统判定你在“搞黄色”);
描述词之外,可以加入画面类型、艺术家、尺寸等信息,他们有点像滤镜,能让你的画看起来更像那么回事儿;
如果你有绘画基础,可以自己画底稿,再由 AI 在你的基础上描绘具体场景,底稿建议使用色块和形状而非纯线稿,因为 AI 不会自动填色。

官方给的描述词案例丨界面截图
此外,6pen 还会返回每个生成过程的迭代图,Loss 曲线,甚至电量消耗等数据,让用户更好了解生产过程,帮助改进。

在等待生成期间,6pen 会让你为一些生成作品投票,看看哪张作品效果更好。这时你会觉得自己像一个给 AI 的打工者,帮助模型升级进步。
6pen 的创始人王登科指出过 AI 绘画技术目前的不足,比如人的肢体(主要是手指)和眼球效果较差,多主体对象生成效果差,也无法进行有逻辑延续的故事性生成。
收费标准:可以免费排队生成,也可以付费快速生成,价格为 0.1 元起;
版权要求:6pen 的自研模型都采用 MIT 协议开源,生成出来的图片版权完全授权给生成者本人。6pen 也支持采用 CC0 协议的 Stable Diffusion,这时产生的作品版权就不由生成者独享了。生成者如果使用了还在世的艺术家作为画面参考,且生成作品的风格与艺术家相似,也可能存在版权争议。同理,如果使用了参考图,且参考图并非原创 (如摄影、绘画),那么生成的结果也存在版权争议。【这个也是一种隐患和争议,AI生成的文章、图片和视频等内容的版权未来应该怎么划分法律边界怎么定义是一个亟待解决的问题】
目前,绝大多数产品化的 AI 绘画服务几乎都通过按照生成收费的方式获得收入,如下:
-
Stable Diffusion
-
模型开源免费
-
Dream Studio 及 API :0.01 欧元 / 基础调用
-
据统计,2022 年 9 月后国内涌现的AI绘画产品,95% 都使用了 Stable Diffusion,但是按照 Stability License 展示必要信息的,只有不到 10 %
-
-
Midjourney
-
10 美元 / 月:200次快速生成+不限量的排队生成
-
30 美元 / 月:900次快速生成+不限量的排队生成
-
4 美元 / GPU小时
-
600 美元 / 年 企业套餐
-
-
Dalle
-
0.13 美元 / 生成
-
-
6pen
-
不限量的免费排队生成
-
付费快速生成:0.1人民币起
-
-
文心一格 目前需要金币有免费额度,详见官网文心一格 - AI艺术和创意辅助平台
可以看出,商业化的 AI绘画的服务目前几乎不区分 ToB 或 ToC ,更多是提供按量或按需付费的服务,无论是企业还是个人用户都可以使用。这种收费模式是因为这些原因:
-
AI生成使用显卡服务器,维持免费使用需要付出巨大成本
-
缺乏生成图之后的闭环,无法从免费用户获得其他方面的收入
-
受限于尚处在争议中的版权及其它道德因素,其它商业化手段还有待探索
ToB 的可能性
AI绘画在 ToB 领域天然拥有更多可能性,但受限于模型质量,版权争议,以及目前较早期的技术阶段,还很少有公开落地的案例,但我们认为在下列方向,可能会在未来涌现出更多 ToB 的成功案例:
-
广告行业
-
ToB 素材库
-
设计师/美术工作者辅助工具
-
营销定制服务
-
线下实体结合服务
-
元宇宙等线上虚拟空间
【四件套组合】ChatGPT + Midjourney + Clipchamp + Voicemaker.in
最后如果机器生成的还不满意,那么则需要剪辑软件(人工介入)进行调优
无论chatgpt还是midjourney,他们有多强大完全取决于我们的使用方法,就像屠龙刀,不懂武林秘籍的初学者可以拿刀很方便的切菜,但高手却能发挥屠龙刀更大的威力。比如初学者使用midjourney可能就输入一些简单的词生成一些图片,但有经验的开发者就可以通过增加一些特定参数,来生成非常具有艺术风格的图片,midjourney也展示了一些受欢迎的图片。
【写在最后】
AI 绘画还在狂奔路上,现在这些工具解决的是“写写字就能画画”,未来可能会进一步解决“写写字就能画多好”的问题。随着这些工具的基础功能,以及背后的模型逐步完善,我们要争的,就是如何写 prompt (提示词)了。(说白了还是搜素引擎+推荐算法+关键词输出内容)
人工智能绘画,是突破了人类自身的极限,从而让绘画分析进入到一个更为广泛的视野中以人文精神为出发点和落脚点。通过人工智能,打开绘画艺术的新领域,人工智能绘画通常神秘、绚丽、深沉、复杂、时代感强,体现出非凡的想象力。象征未来绘画的发展方向。
新的AI内容创作时代已来临,新事务的诞生,必然有陈旧的要被淘汰。替换您的从来不是AI人工智能技术本身,而是学会使用AI软件工具的人!!!
【参考文献资料】
1、中国AI绘画行业调查报告——技术,用户,争议与未来 https://mp.weixin.qq.com/s/CSdAfew2wPbt2yhsNWav8g
2、AI作画火了,插画师们快坐不住了? https://baijiahao.baidu.com/s?id=1751336391248386862
3、【AI 绘画】 MidJourney 入门、参数解析、进阶玩法、变现指南、资料包|ai绘画|参数解析|变现指南 https://m.163.com/dy/article/HT9KSLJ10519EA27.html
4、AI 会讲话!真人影片一键生成 Midjourney + ChatGPT + D-ID 乐趣玩法 https://haokan.baidu.com/v?pd=wisenatural&vid=8217118155277645324
5、ChatGPT + Midjourney + Clipchamp AI实现故事文案配乐动画等全自动高品质动画制作_哔哩哔哩 https://www.bilibili.com/video/BV1dc411j7Cc/
6、简单了解Midjourney-百家号 https://baijiahao.baidu.com/s?id=1759608325861527308
7、ChatGPT+MidJourney 3分钟生成你的动画故事_走神的阿圆的博客-CSDN博客 https://blog.csdn.net/yhan_shen/article/details/129358429
8、造梦日记 - AI一下,妙笔生画 https://printidea.art/
科技云报道:AI写小说绘画剪视频,生成式AI更火了!
科技云报道原创。
近日,生成式AI又火了!一个叫做「盗梦师」的微信小程序,上线一鸣惊人,达成了日增5万新用户的纪录。
盗梦师是一个能根据输入文本生成图片的AI平台,属于AIGC(AI-Generated Content,即人工智能生成内容)的分支。
在用户发挥想象,输入文字描述后,盗梦师便可生成1:1、9:16和16:9三种比例的图片,还有24种绘画风格可以选择——除了基础的油画、水彩、素描等绘画种类,还包括赛博朋克、蒸汽波、像素艺术、吉卜力和 CG 渲染等特别风格。

图:科技云报道编辑用「盗梦师」微信小程序生成
事实上,这并不是第一款“以文生图”的AI软件。从Midjourney到Stable Diffusion,生成式AI一直是近两年最炙手可热的话题。
作为AI发展的一个重要方向,生成式AI具有非常大的发展潜力。
据Gartner上半年的数据,预计到 2025 年,生成式AI将占所有生成数据的10%,当前这一比例不到1%。
有观点认为,2022年将是生成式AI从技术成熟到深入社会基本面的元年。
生成式AI爆发式增长:从图片到视频
最近几年,AI技术在视觉领域的发展可谓是“神速”。
去年1月,致力于“用通用人工智能造福全人类”的OpenAI公司,基于GPT-3模型发布了划时代的DALL-E,实现了从文本生成图像。
今年4月份,OpenAI发布的第二代DALL-E 2模型,再次为图像生成领域树立了全新标杆。
用户可以通过简短的文本描述(prompt)来生成相应的图像,使得不会画画的人也可以将自己的想象力变为艺术创作,例如“羊驼打篮球”这句话生成的四张图片,看起来就非常符合大家预期的想象。

DALL-E 2模型生成图片示例
不仅如此,随着文字描述的颗粒度不断细化,生成的图像也会越来越精准,效果在非专业人士看来已经相当震撼。
但DALL-E 2这样的模型仍然停留在二维创作即图片生成领域,无法生成360度无死角的3D模型。
不过这依旧难不住极具创意的算法研究员,Google Research的一项最新成果——DreamFusion模型,即可通过输入简单的文本提示生成3D模型,不仅能够在不同的光照条件下进行渲染,而且生成的3D模型还具有密度、颜色等特性,甚至可以把生成的多个3D模型融合到一个场景里。
在生成3D图片之后,Meta的算法人员将思路进一步打开,向更高难度发起挑战,开始探索用文字提示来直接生成视频。
虽然本质上来说,视频就是一系列图像的叠加,但相比于生成图像,用文字来生成视频时,不仅需要生成相同场景下的多个帧,还要保证相邻帧之间的连贯性。由于训练模型时可用的高质量视频数据非常少,但计算量却很大,大大增加了视频生成任务的复杂性。
今年9月,来自Meta的研究人员发布了Make-A-Video,这是一个基于人工智能的高质量短视频生成模型,相当于视频版的DALL-E,也被戏称为“用嘴做视频”,即可以通过文本提示创建新的视频内容,其背后使用的关键技术,也同样来自DALL-E等图像生成器所使用的“文本-图像”合成技术。
仅1周之后,谷歌CEO皮查伊就接连官宣了两个模型,来正面挑战Meta的Make-A-Video,分别是Imagen Video与Phenaki。
与Make-A-Video相比,Imagen Video更加突出视频的高清特性,能生成1280*768分辨率、每秒24帧的视频片段,还能理解并生成不同艺术风格的作品;
理解物体的3D结构,在旋转展示中不会变形;
甚至还继承了Imagen准确描绘文字的能力,在此基础上仅靠简单描述产生各种创意动画。
而Phenaki则能根据200个词左右的提示语生成2分钟以上的较低分辨率长镜头,讲述一个相对完整的故事
目前,国内也有不少生成式AI的应用。
例如,字节跳动旗下的剪映APP提供AI生成视频功能,并可以免费使用。
剪映的图文成片功能和谷歌类似,创作者可以通过几个关键词或一小段文字,生成一段创意小视频。
剪映还可以根据文字描述智能匹配视频素材,将视频包装为更垂直的内容作品,包括财经、历史、人文等类别。
2022年1月,网易推出一站式AI音乐创作平台“网易天音”,将用户编辑的新年祝福AI生成为歌曲,并在上半年推出了web端专业版。
2021年9月,彩云小梦APP上线,能够进行各种类型文本创作,用户只需要给出一个1-1000字的开头,彩云小梦就能续写出后面的故事。
事实上,AI创作还有多种形式。当生成式AI技术应用于写稿,可以诞生机器版的记者、小说家、诗人、编剧等,而当它应用于绘画、音乐和舞蹈领域时,则可以“培养”出画家、作曲家和编舞人员。
生成式AI爆发的背后
过去一年里,生成式AI发展得更好了。谷歌、微软、Meta等AI领域的软件巨头们已在内部推进该技术,让生成式AI融合到自己的产品里。
为什么生成式AI突然就火了?
其实生成式AI技术一直在快速发展中,只不过之前因过高的技术门槛,多囿于科技界的小圈层。
回顾AI技术的发展历程,会发现生成式AI的爆发离不开三个因素:更好的模型、更多的数据,和更多的计算。
2015年以前,小模型被认为是理解语言的“最先进技术”。这些小模型,擅长分析任务,并被部署在从预测交付时间到欺诈分类的工作中。
然而,对于通用的生成任务,它们的表达能力还不够强。生成人类水平的写作或者代码,仍只是一个梦想。
2017年,谷歌研究院发布了一篇里程碑式的论文(Attention is All You Need),描述了一种用于自然语言理解的新神经网络架构,称为 transformers,可以生成质量上乘的语言模型,同时,具有更高的可并行性,需要的训练时间也大大减少。
当然,随着模型越来越大,它们开始显现出超越人类的水平。从2015年到2020年,用于训练这些模型的计算量增加了6个数量级,其结果在手写、语音和图像识别、阅读理解以及语言理解方面,超过了人类性能的基准。
其中,OpenAI的GPT-3脱颖而出,该模型的性能比GPT-2有了巨大飞跃,从代码生成到冷笑话写作,显示了更优秀的能力。
尽管有所有基础研究领域的进展,这些模型并不普遍。
它们体积大、运行困难(需要GPU协调),不能广泛使用(不可用或仅有封闭的测试版),而且作为云服务使用的费用昂贵。
但是尽管有这些限制,最早的生成性AI应用开始进入战场。
之后,随着计算变得更便宜,业界继续开发更好的算法和更大的模型。
开发者的权限从封闭测试版扩大到了开放测试版,或者在某些情况下,开放源代码。
如今,平台层的稳固,加上模型继续变得更好、更快、更便宜,以及模型的访问趋向于免费和开源,AI应用层的创造力爆发时机已经成熟。
比如,今年8月,文本-图像生成模型Stable Diffusion开源,后继者能更好地借助这一开源工具,挖掘出更丰富的内容生态,为向更广泛的C端用户普及起到至关重要的作用。
Stable Diffusion的火爆,本质上就是开源释放了创造力。
生成式AI面临现实挑战
风投机构红杉资本在官网上的一篇博客文章中提到:“生成式AI有潜力产生数万亿美元的经济价值。
”据红杉资本预测,生成式AI可以改变每个需要人类创造原创作品的行业,从游戏到广告再到法律。
具体而言,未来生成式AI的应用场景非常广阔,除了文创、新闻等内容生产行业外,生成式AI在医疗保健、数字商业、制造业、农业等多个行业都有丰富的应用前景,如帮助医生检测X射线、CT等设备扫描中的病变、创建商品的数字孪生体、辅助检测产品质量等。
在XR、数字孪生、自动驾驶汽车等热门技术上也有丰富的应用空间。
但值得注意的是,当前生成式AI仍有很多问题需要解决。
如在文娱领域,不少人采用生成式AI进行创作的一个原因,就是可以避免版权问题,但这并不代表没有隐患。
一方面,AI的创作也是将学习到数据按照要求重新组合起来,虽然颗粒度越来越细,但难免还是有眼尖的人会看出可能是参考了哪些作品,甚至有网友在社交平台上表示曾在某AI生成图片上隐约看到疑似签名的痕迹。
另一方面,当前大部分AI生成平台多不主张版权或明确表示可以进行商用,但随着生成式AI逐步商业化,这样的版权环境是否存在,是否会出现新的版权问题也是需要讨论的。
生成式AI的逻辑与安全性也有待提升。当前的生成式AI很容易犯一些常识性的错误,在一些需要长期记忆的地方也容易出现问题。
如在AI生成小说的过程中,经常会因为篇幅较长而出现前后矛盾的地方。
因此,即便生成式AI已经可以在很多领域得到应用,真要让生成式AI投入工作,还要通过大量的训练来避免因AI的“错误”造成的重大损失。
毕竟医疗、制造业这些应用场景没有文创行业那样的试错空间。
**
结语**
尽管生成式AI当前还离不开人工干预,但不可否认的是,生成式AI仍具有非常大的发展潜力。
生成式AI的出现,意味着AI开始在现实内容中,承担从“观察、预测”拓展到“直接生成、决策”的新角色。换句话说,生成式AI是在创造,而不仅仅是分析。
正如OpenAI CEO Sam Altman所说:“生成式AI提醒我们,很难做出有关于人工智能的预测。
十年前传统观点认为:人工智能首先会影响体力劳动;然后,是认知劳动;然后,也许有一天它可以做创造性的工作。现在看起来,它会以相反的顺序进行。”
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、全球云计算大会官方指定传播媒体之一。深入原创报道云计算、大数据、人工智能、区块链等领域。
以上是关于AI绘画(以后也叫AI视频)的主要内容,如果未能解决你的问题,请参考以下文章