Clickhouse一级索引优化方案
Posted 我永远信仰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Clickhouse一级索引优化方案相关的知识,希望对你有一定的参考价值。
文章目录
Clickhouse的应用场景
绝大多数是读请求
数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
已添加到数据库的数据不能修改。
对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
宽表,即每个表包含着大量的列
查询相对较少(通常每台服务器每秒查询数百次或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
事务不是必须的
对数据一致性要求低
每个查询有一个大表。除了他以外,其他的都很小。
查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
1、索引介绍
1.1、主要索引
通过按主键对数据进行物理排序,可以提取其特定值或值范围的数据,延迟低,小于几十毫秒。(也就是下文分析的内容)
- 改进数据压缩。
ClickHouse按主键对数据进行排序,因此一致性越高,压缩效果越好。
1.2、二级索引
与其他数据库管理系统不同,ClickHouse 中的二级索引不指向特定的行或行范围。相反,它们允许数据库提前知道某些数据部分中的所有行都与查询筛选条件不匹配,并且根本不读取它们,因此它们被称为数据跳过索引。
1.2.1、数据跳过索引
对于系列(**MergeTree)中的表,可以指定数据跳过索引。
这些索引聚合有关块上指定表达式的一些信息,块由粒状组成(粒度的大小是使用表引擎中的设置指定的)。然后,这些聚合用于查询,通过跳过查询无法满足的大块数据块来减少要从磁盘读取的数据量。
ck默认索引粒度:8192 = 1024 * 8
也就是查看表中自动生成的 SETTINGS index_granularity = 8192
2、一级索引优化
总结一下可以优化的地方:
- 一级索引
- 二级索引
- 可以根据现有字段直接分区 PARTITION BY 字段
- 可以根据函数分区 PARTITION BY toYYYYMM(EventDate) toYYYYMM是函数,(eventDate)属性需要是Data类型
目前业务中可优化的选项:
-
日期尽量都使用date类型,目前使用的是Int64(待研究)
按月分区的键仅允许读取那些包含适当范围的日期的数据块。在这种情况下,数据块可能包含许多日期(最多一整个月)的数据。在块中,数据按主键排序,主键可能不包含日期作为第一列。因此,使用仅具有未指定主键前缀的日期条件的查询将导致读取的数据多于单个日期的数据。 -
针对常查询的字段,使用ORDER BY(c1, c2, xxx) 创建索引,括号中从左到右的优先级会导致查询效率有别;
注意: -
有Nullable的字段,不能创建索引,一些查询字段不要设置Nullable()
2.1、CK的sql的优化方向
- 分区,原则是尽量把经常一起用到的数据放到相同区(也可以根据where条件来分区),如果一个区太大再放到多个区
大量分区是一种常见的误解。这将导致严重的负面性能影响,包括服务器启动速度慢、插入查询速度慢和选择查询速度慢。表的建议分区总数在1000以下。请注意,分区并不是为了加速SELECT查询(按键排序足以使范围查询变得快速)。分区用于数据操作(删除分区等)
-
主键(索引,即排序)order by字段选择: 就是把where 里面肯定有的字段加到里面,where 中一定有的字段放到第一位,注意字段的区分度适中即可 区分度太大太小都不好,因为ck的索引时稀疏索引,采用的是按照固定的粒度抽样作为实际的索引值,不是mysql的二叉树,所以不建议使用区分度特别高的字段。
-
- 值得一提的是,通常只有在使用
SummingMergeTree或AggregatingMergeTree的时候,才需要同时设置ORDER BY与PRIMARY KEY。显式的设置PRIMARY KEY,是为了将主键和排序键设置成不同的值,是进一步优化的体现。(PS:因为我们使用的引擎并不是上面几种,省略PRIMARY KEY。默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用ORDER BY代为指定主键。) - 创建索引尽量选择基数大的,也就是重复相对较多的(因为是稀疏索引) 在mysql中正好是相反的
- 值得一提的是,通常只有在使用
也就是说,业务中经常需要查询的字段需要放在order by靠前位置。
举个例子:统计了一下业务中的风险实际表的查询sql语句,按照优先级高到低整理出来的字段
create_time , score , vehicle_id,id
也就是说需要这么写:
order by(create_time , score , vehicle_id,id).
官网原话:长主键会对插入性能和内存消耗产生负面影响 , 但主键中的额外列不会影响查询期间的ClickHouse 性能。
2.2、验证过程
下面只取两个字段create_time,id来验证
创建4个表,插入相同的204w条数据。(开启trace log,查看查询从机器上面读取的条数,不会弄),暂时以执行时间来参考。
4个表的排序情况为:
表1: ORDER BY (id)
表2: ORDER BY (id,create_time)
表3: ORDER BY (create_time)
表6: ORDER BY (create_time,id) //推荐
CREATE TABLE hf_ai_hbs.t_base_data_record1
(
`id` Int64 COMMENT '事件ID',
`time` Int64 COMMENT '数据记录时间,单位毫秒',
...
省略了一些字段
...
`create_time` Int64 DEFAULT 0 COMMENT '创建时间,毫秒时间戳,设备事件时间'
)
ENGINE = ReplacingMergeTree
ORDER BY id
SETTINGS index_granularity = 8192
CREATE TABLE hf_ai_hbs.t_base_data_record2
(
`id` Int64 COMMENT '事件ID',
`time` Int64 COMMENT '数据记录时间,单位毫秒',
...
省略了一些字段
...
`create_time` Int64 DEFAULT 0 COMMENT '创建时间,毫秒时间戳,设备事件时间'
)
ENGINE = ReplacingMergeTree
ORDER BY (id,create_time)
SETTINGS index_granularity = 8192
其余两个字段、属性、数据相同,只是order by里面的内容不同。
-- 执行十次
-- SQL 1
SELECT * FROM t_risk_event_record1 trer WHERE id=171972290612035584; --执行十次,单位ms: 平均耗时:16.0
SELECT * FROM t_risk_event_record2 trer WHERE id=171972290612035584; -- 平均耗时:19.0
SELECT * FROM t_risk_event_record3 trer WHERE id=171972290612035584; -- 平均耗时:23
SELECT * FROM t_risk_event_record6 trer WHERE id=171972290612035584; -- 平均耗时:25.0
-- SQL 2
SELECT * from t_risk_event_record1 trer order by id DESC LIMIT 3; --平均耗时:35
SELECT * from t_risk_event_record2 trer order by id DESC LIMIT 3; --56,50,61,52,57,56,54,55,55,54 平均耗时:55
SELECT * from t_risk_event_record3 trer order by id DESC LIMIT 3; --平均耗时:138
SELECT * from t_risk_event_record6 trer order by id DESC LIMIT 3; --平均耗时:148
-- SQL 3
SELECT * from t_risk_event_record1 trer order by create_time DESC LIMIT 3; --执行十次,平均耗时:125.0 129,122,121,125,133,120,119,125,131,125
SELECT * from t_risk_event_record2 trer order by create_time DESC LIMIT 3; --执行十次,平均耗时:135.0 146,153,130,140,127,130,125,124,130,145
SELECT * from t_risk_event_record3 trer order by create_time DESC LIMIT 3; --执行十次,平均耗时:54.0 50,43,56,56,57,54,65,50,61,48
SELECT * from t_risk_event_record6 trer order by create_time DESC LIMIT 3; --执行十次,平均耗时:53.0 56,57,40,63,53,54,47,44,57,59
-- SQL 4
SELECT * from t_risk_event_record1 trer order by create_time,id DESC LIMIT 3; --执行十次,平均耗时:120
SELECT * from t_risk_event_record2 trer order by create_time,id DESC LIMIT 3; --执行十次,平均耗时:135
SELECT * from t_risk_event_record3 trer order by create_time,id DESC LIMIT 3; --执行十次,平均耗时:100
SELECT * from t_risk_event_record6 trer order by create_time,id DESC LIMIT 3; --执行十次,平均耗时:65
-- SQL 5
SELECT * from t_risk_event_record1 trer order by id,create_time DESC LIMIT 3; --执行十次,平均耗时:45
SELECT * from t_risk_event_record2 trer order by id,create_time DESC LIMIT 3; --执行十次,平均耗时:50
SELECT * from t_risk_event_record3 trer order by id,create_time DESC LIMIT 3; --执行十次,平均耗时:140
SELECT * from t_risk_event_record6 trer order by id,create_time DESC LIMIT 3; --执行十次,平均耗时:150
-- SQL 6
SELECT * from t_risk_event_record1 trer WHERE (create_time>=1649324393021) AND (create_time <=1649324595021); --执行十次,平均耗时:35
SELECT * from t_risk_event_record2 trer WHERE (create_time>=1649324393021) AND (create_time <=1649324595021); --执行十次,平均耗时:34
SELECT * from t_risk_event_record3 trer WHERE (create_time>=1649324393021) AND (create_time <=1649324595021); --执行十次,平均耗时:25
SELECT * from t_risk_event_record6 trer WHERE (create_time>=1649324393021) AND (create_time <=1649324595021); --执行十次,平均耗时:20

结论:
- sql1中,根据id查询,四种情况的查询效率相差不大
- sql2中,根据id排序,因为建表时候,表1和表2排序键前面都是id,所以查询效率明显比表3、6要好。sql3中情况刚好相反
- sql4中,表3、4的order by 排序键的
create_time比较靠前,所以,他们的查询效率相对表1、2快了两倍多,sql5中相反。 - sql6中,表3、4的order by 排序键的
create_time比较靠前 - 除了在sql2根据id排序的情况下,表6排序键的查询效率在这几个sql中都是比较快的
2.3、如何修改排序键
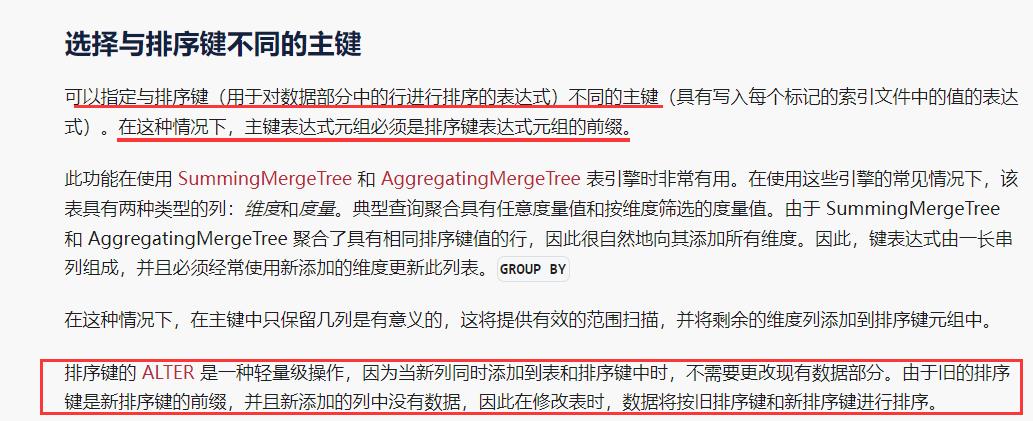 这里有几个问题
这里有几个问题
- 看这段话排序键的AlTER对象是新增的列才行,而不能像二级索引(跳数索引)一样可以随意更改成其他字段
排序键可以更新除了主键外的键。比如主键是id,可以从order by(id,name)更新成(id,age);但是更新的字段必须是新增的列
- 更改完排序键后索引文件应该没有任何变化,这时我们设置的新排序规则应该对查询没有任何作用?
- 如何才能根据新设置的排序键进行重建索引?
- ClickHouse 在什么情况下会自动重建索引?
修改排序键 sql 如下:
ALTER TABLE 数据库.表名
ADD COLUMN age Int16,
MODIFY ORDER BY (id, age)
总结:
- 针对常查询的字段,使用ORDER BY(c1, c2, xxx) 创建索引,而且业务中经常需要查询的字段需要放在order by靠前位置。
- 长主键会对插入性能和内存消耗产生负面影响 , 但主键中的额外列不会影响查询期间的ClickHouse 性能。
参考链接:
clickhouse使用经验总结:https://blog.csdn.net/TankRuning/article/details/111317090
clickhouse的索引结构和查询优化:https://blog.csdn.net/h2604396739/article/details/86172756
从Clickhouse执行计划看跳数/稀疏索引的效果:https://www.gbase8.cn/6596
Clickhouse orderby之谜:https://zhuanlan.zhihu.com/p/379848085
clickhouse 在order by非常慢的情况下优化:https://www.cnblogs.com/niutao/p/15313070.html
ClickHouse的执行计划以及优化策略:https://www.cnblogs.com/traditional/p/15264282.html
clickhouse分区操作实践:https://blog.csdn.net/m0_37813354/article/details/110847747
3、二级索引(跳数索引)
跳数索引:能够快速跳过无用的数据区间(跳跃粒度是我们设置的,默认8192)。有些区间可能不会被扫描到,提高我们查询的效率
类似布隆过滤器,所有跳数索引的原则都是“排除法”,即尽可能的排除那些一定不满足条件的索引粒度。
告诉我们某个数据一定不存在或者可能存在(注意:布隆过滤器是不能判断某条数据一定存在的,存在误报率 (false_positive) )。相比于传统的 List、Set、Map 等数据结构,布隆过滤器更高效、占用空间更少,因为不需要存储原始值,但是缺点是其返回的结果是概率性的,而不是确切的。
知识点
查看Clickhouse的执行计划
在前面加explain
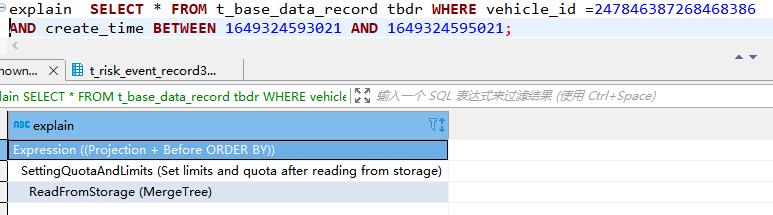
注意其中的数据读取位置,分别是从原始的存储(ReadFromStorage),和预处理的源(ReadFromPreparedSource)。
explain SYNTAX 加sql语句,会输出优化的sql,如果和我们写的一样,说明我们的sql已经是最优的了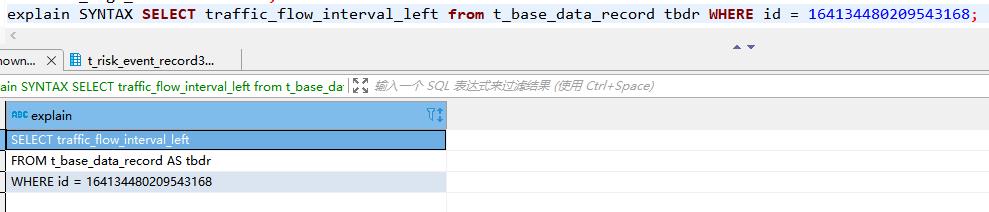
查询中的主键和索引
以主键为例。在这种情况下,排序和索引可以如下图示:(CounterID, Date)

如果数据查询指定:
CounterID in ('a', 'h')中,服务器读取标记和 范围内的数据。[0, 3)[6, 8)CounterID IN ('a', 'h') AND Date = 3中,服务器读取标记和 范围内的数据。[1, 3)``[7, 8)Date = 3中,服务器读取标记范围内的数据。[1, 10]取并集
上面的示例表明,使用索引始终比完全扫描更有效。
ClickHouse 不需要唯一的主键。可以使用相同的主键插入多行。
选择主键
主键中的列数没有显式限制。根据数据结构,您可以在主键中包含更多或更少的列。这可能:
- 提高索引的性能。
如果主键为,则在满足以下条件时,添加另一列将提高性能:(a,b)``c
-
- 有些查询在列上具有条件, 例如:
c。 - 具有相同值的长数据范围(比长几倍)很常见。换句话说,添加另一列时,可以跳过相当长的数据范围。
index_granularity (a,b)
- 有些查询在列上具有条件, 例如:
-
改进数据压缩。
ClickHouse按主键对数据进行排序,因此一致性越高,压缩效果越好。
- 在CollapseingMergeTree和SummingMergeTree 引擎中合并数据部分时提供其他逻辑。在这种情况下,指定与主键不同的排序建是有意义的。
值得一提的是,通常只有在使用SummingMergeTree或AggregatingMergeTree 的时候,才需要同时设置ORDER BY与PRIMARY KEY。
显式的设置**PRIMARY KEY,**是为了将主键和排序键设置成不同的值,是进一步优化的体现。
长主键会对插入性能和内存消耗产生负面影响 , 但主键中的额外列不会影响查询期间的ClickHouse 性能。
可以使用语法创建没有主键的表。在这种情况下,ClickHouse将按插入顺序存储数据。如果要在按查询插入数据时保存数据顺序,请设置max_insert_threads = 1。ORDER BY tuple() INSERT ... SELECT
若要按初始顺序选择数据,请使用单线程查询。SELECT
分区
单个插入块的分区太多(超过100个)。该限制由“每个插入块的最大分区数”设置控制。大量分区是一种常见的误解。这将导致严重的负面性能影响,包括服务器启动速度慢、插入查询速度慢和选择查询速度慢。表的建议分区总数在1000以下。。请注意,分区并不是为了加速SELECT查询(按键排序足以使范围查询变得快速)。分区用于数据操作(删除分区等)
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate) SETTINGS index_granularity=8192
SELECT count() FROM table WHERE EventDate = toDate(now()) AND CounterID = 34
SELECT count() FROM table WHERE EventDate = toDate(now()) AND (CounterID = 34 OR CounterID = 42)
SELECT count() FROM table WHERE ((EventDate >= toDate('2014-01-01') AND EventDate <= toDate('2014-01-31')) OR EventDate = toDate('2014-05-01')) AND CounterID IN (101500, 731962, 160656) AND (CounterID = 101500 OR EventDate != toDate('2014-05-01'))
ClickHouse 将使用主键索引来修剪不正确的数据,并使用每月分区键来修剪日期范围内的分区。
上面的查询表明,索引甚至用于复杂表达式。对从表中读取数据进行组织,以便使用索引的速度不会比完全扫描慢。
在下面的示例中,无法使用索引。
SELECT count() FROM table WHERE CounterID = 34 OR URL LIKE '%upyachka%'
要检查 ClickHouse 在运行查询时是否可以使用索引,请使用设置force_index_by_date和force_primary_key。
按月分区的键仅允许读取那些包含适当范围的日期的数据块。在这种情况下,数据块可能包含许多日期(最多一整个月)的数据。在块中,数据按主键排序,主键可能不包含日期作为第一列。因此,使用仅具有未指定主键前缀的日期条件的查询将导致读取的数据多于单个日期的数据。
- 创建分区
建表时使用关键字 PARTITION BY 【分区名称】
- 使用函数创建分区
比如根据toYYYYMM(date字段)会生成yyyyMM格式的年月日期分区
数据****PARTITION 在ClickHouse中主要有两方面应用:
- 在PARTITION KEY上进行分区裁剪,只查询必要的数据。灵活的PARTITION expression设置,使得可以根据SQL PARTITION 进行分区设置,最大化的贴合业务特点。
- 对PARTITION 进行TTL管理,淘汰过期的分区数据。
[
](https://blog.csdn.net/m0_37813354/article/details/110847747)
将索引用于部分单调的主键
例如,考虑一个月中的几天。它们在一个月内形成单调序列,但在更长的时间内不形成单调序列。这是一个部分单调的序列。如果用户使用部分单调的主键创建表,ClickHouse 将像往常一样创建稀疏索引。当用户从此类表中选择数据时,ClickHouse 会分析查询条件。如果用户想要获取索引的两个标记之间的数据,并且这两个标记都在一个月内,ClickHouse 可以在此特定情况下使用索引,因为它可以计算查询参数和索引标记之间的距离。
如果查询参数范围中的主键值不表示单调序列,则 ClickHouse 不能使用索引。在这种情况下,ClickHouse使用完全扫描方法。
ClickHouse 不仅将此逻辑用于月份序列中的天数,还对表示部分单调序列的任何主键使用此逻辑。
以上是关于Clickhouse一级索引优化方案的主要内容,如果未能解决你的问题,请参考以下文章