论文笔记系列:主干网络-- VGG
Posted GoAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记系列:主干网络-- VGG相关的知识,希望对你有一定的参考价值。
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
深度卷积神经网络VGG
Very Deep Convolutional Networks for Large-scale
Image Recognition
论文地址:https://arxiv.org/abs/1409.1556

论文结构
摘要: 介绍网络深度与精度之间的联系,提出深度卷积模型
1. Introduction: Convnet的成功得益于大量数据及高性能GPU;介绍本论文主要贡献
2. ConvNet Configurations: 讲解11-19层的VGG网络结构;3*3卷积与5*5/7*7卷积的感受野等价
3. Classification Framework: VGG网络的分类实验,训练及测试详细步骤;Multi-scale训练,Multi crop/Dense 测试
4. Classification Experiments: 多种设置下的分类结果对比;单尺度评估,多尺度评估,多次裁剪评估,模型融合,最优模型对比
5. Conclusion: 强调深度对convnet是有益的,本文提出的VGG模型获得优异结果
一、VGG模型结构(论文中2.1-2.2)
模型结构设计的特点
1 小卷积核
2 堆叠使用卷积核
3 分辨率减半,通道数翻倍
①体系结构(论文中的2.1)
输入的尺寸是固定的224×224;
预处理方式:每个像素分别减去 RGB三个通道均值,可以加速模型的训练;
卷积层:小卷积核3×3,也尝试了1×1卷积(借鉴了NIN)。卷积不改变分辨率,会用padding填充像素;
池化层:使用5个池化,每个池化用2×2的池化窗口,步长为2,分辨率降低了一半。224×224经过5次池化后,输出为7×7 (因为224/32=7),再拉成一个向量的形式接入FC层;
全连接层:前两个层各有4096个通道,第三层执行1000路分类;
在隐藏层配备了ReLU,没有使用LRN,是因为不能提升性能,哈辉导致内存消耗和计算时间的增加。
②配置(论文中的2.2)
从A->E,网络的深度从11个权值层(8个卷积层+3个全连接层)到19个权值层(16个卷积层+3个全连接层),卷积核数量从64-512。
每经过一次池化,卷积核数量就乘以2。(因为池化后减少了一半的分辨率,信息减少了,所以要用更多的卷积核 得到更多的特征图,把丢失的信息补充回来,不至于信息数据减少的太少了)
网络深度从11-19层,但参数并没有变得很多。
③结构特点的探讨(论文中的2.3)
堆叠使用3×3卷积的好处(每一段对应一个):
可以增大感受野。感受野等价,2个3×3堆叠等价于一个5×5;3个3×3堆叠等价于1个7×7。
减少训练参数。3个3×3比1个7×7节省81%参数,卷积参数计算公式 3(3²C²)=27C²;7²C²=49C²,(49-27)/27=81%,所以参数量增加81%
采用1×1卷积核的好处,增加了非线性的能力(特征提取的能力),可以增加特征抽象能力,提升模型效果。根据NIN借鉴的。
④表格分析

(1)对于表1的理解–以A网络为例:
进行第一组卷积操作时,输入是3×224×224,
经过64个卷积核,
经过2×2、步长为2的最大池化,分辨率减少一半,变成112×112;
进行第二组卷积操作,
经过64×2=128个卷积核,
经过池化之后,分辨率再减少一半,变成56×56;
第三组卷积操作,
经过128×2=256个卷积核,
经过池化之后,分辨率变为28×28;
第四组卷积操作,
卷积核达到512,
池化之后,得到分辨率为14×14的特征图;
第五组卷积操作,
使用2个3×3的卷积核堆叠,
再池化,分辨率变为7×7。
将7×7的特征图拉成一个向量,得到49×512个神经元(512个特征图),进入三个全连接层(神经元个数分别 4096 4096 100)
(2)A-E模型变换 演变过程:
A:11层卷积
A-LRN:第一组卷积操作结束的时候加了LRN
B:加深了网络模型,在第一组和第二组卷积操作中分别加一个3×3的卷积
C:在3.4.5组卷积的地方做了1×1卷积的尝试,(借鉴NIN,从激活函数考虑,1×1卷积就是做了一个线性变换),C增加了模型非线性的映射能力,精度有所提升。
D:vgg16,在C的基础上,把1×1卷积全部换成3×3卷积,可以获取更大的感受野,看看有没有更大的提升
E:vgg19,在3.4.5组卷积再增加一个3×3的卷积
(3)A-E的共性:
(1) 5个maxpool降低分辨率
(2) 池化后,特征图通道数要翻倍,直至512
(3) 3个FC层进行分类输出
(4) 池化之间采用多个卷积层堆叠,对特征进行提取和抽象
(4)A-E的对比:
A-B只针对1,2靠前的两组卷积操作增加卷积核,后面C-E只在后面三组增加卷积层。
是否越靠后的特征图 要利用的更多、抽象的 需要非线性更强的映射能力的卷积核操作 去完成? 可能堆叠更多的卷积层,使用更多的非线性激活函数,非线性映射能力比较强。
1 参数量对比
虽然网络层增加了8层,但参数量并没有增加太多(优点)。
原因:AlexNet在全连接层占了一半的参数,所以增加小的3×3卷积层,参数不会增加太多的。
2 每组卷积操作中,卷积层堆叠的个数不同
二、分类框架(论文中的3)
①训练技巧(论文中的3.1 训练阶段)
设置S的两种方法:
固定值:256/384;
随机值:每个batch的S在[256,512]随机采样,实现尺度扰动
(1)数据增强——尺度扰动
针对位置/尺寸———尺寸扰动 scale jittering
训练阶段的尺寸扰动:按比例缩放图片至最小边为s;随机位置裁剪出224×224;随机进行水平翻转。
(2)预训练模型初始化 :加速模型训练
利用浅层模型初始化深度的模型——BCDE使用A模型初始化
训练过程中尺度不同的时候,用小尺度上训练好的模型去初始化即将要训练的大尺度的模型——
S=384时,用S=256进行模型初始化;S=[256,512]时,用S=384模型初始化。
3.1第一段:
具体训练超参数的设置:batch size=256、momentum=0.9、L2=5*10^-4、学习率=0.01
学习率下降策略:每次下降×0.1,当验证集准确率不再上升的时候,就下降学习率。在pytorch中有对应的函数实现 reduce on Plateau
训练了74轮,迭代了370K次
3.1第二段:
网络初始化的设置:
深层网络初训练时,会用浅层网络的权重进行初始化。
先训练最浅的A模型。随机初始化。往后训练时,利用A模型前面的卷积层 以及相应的FC层 参数对应初始化到后面的模型。如果没有对应的层,就随机初始化。0均值,偏置=0。
Xavier初始化:直接全部采用Xavier,不要借鉴浅层的参数
3.1第三段:关于训练图片尺寸的设置:
(1) 超参数s:训练图片经过等比例缩放之后的最短边。卷积网络输入在缩放的图片上进行裁剪224×224。S不能小于224,不然图像会丢失。
(2) 设置S的两种方法:
固定值:256/384;
随机值:每个batch的S在[256,512]随机采样,实现尺度扰动
(3) 训练阶段的尺度扰动:
每个batch的s在[256,512]随机采样一个尺寸,按照s裁剪,实现尺度扰动;
多尺度multi-scale training用单尺度模型初始化.
②测试技巧——多尺度测试(论文中的3.2 测试阶段)
设置Q:
图片等比例缩放至最短边为Q
设置3个Q,对图片进行预测,取平均
1 当S为固定值时 Q=[S-32, S , S+32]
2 当S为随机值时,Q=(S_min,0.5*(S_min+S_max), S_max)
(1)Dense稠密测试
将FC层转换为卷积操作,变为全卷积网络,实现任意尺寸图片输入。
1.FC层的权重数量是固定的,若训练和测试的size不一样,size不匹配的话会报错 。
CONV层,根据输入的大小在3个conv层进行计算,得到与输入数据相关的尺寸的feature map,再在h和w两个维度取平均,变成所要的1×1×1000
2.FC替换成CONV
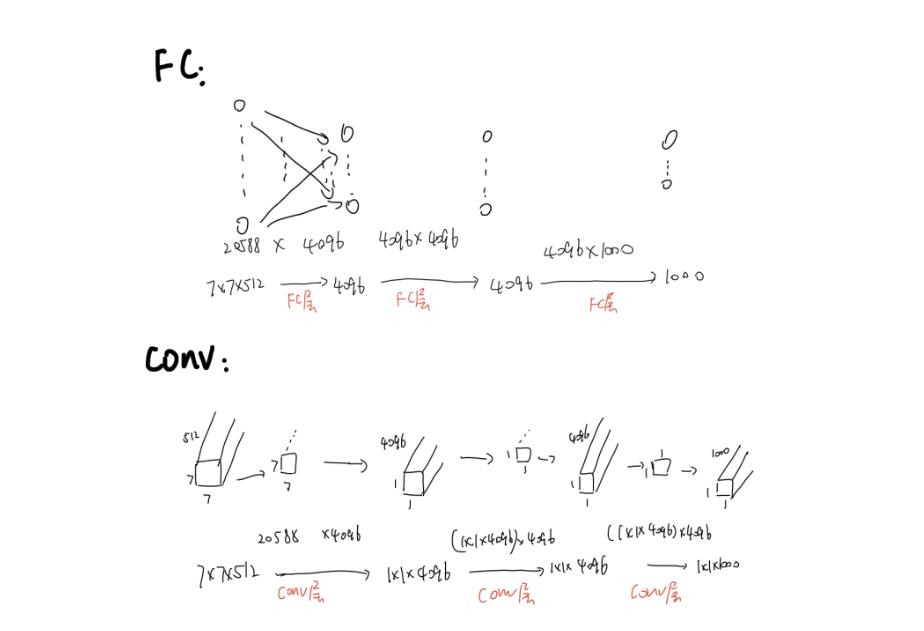
(2)Multi-crop测试
step1 等比例缩放至三种尺寸Q1,Q2,Q3
step2
方法一 Dense 全卷积
方法二 multi-crop 多个位置裁剪224*224区域
方法三 multi-crop&Dense 综合取平均
Q:256,384,512
若Q=256,先截取224,256-224=32,还要截取4下,所以移动步长为32/4=8
3.2第一段:
稠密测试的过程,实现任意尺寸图片输入
图片等比例缩放至Q,Q可以≠S,将整张图片输入到模型中
稠密测试法:FC替换成1×1的卷积层,可以接受任意尺度的输入图片,输出特征图大小会根据输入的尺寸有所变化。
得到类分数特征图,进行平均池化,(与multi-crop得到的值做平均本质一样的,但稠密测试是整张图输入进去,可以高效地实现这个过程,避免了一系列的重复的卷积运算)
水平翻转的图片再进行一次稠密测试,之后再与原始图片的softmax的posteriors 取平均,得到最终值。
3.2第二段:
alexnet的tencrop有重复计算
multi-crop与dense互为补充
multi-crop:一张图片最终得到150张。
一个尺度用5×5的网格裁剪,得到25张图片,水平翻转后得到25×2=50张图片,有三个尺度,所以一共得到50×3=150张图片
三、实验结果及分析(论文中的4)
① single scale 单尺度(论文中4.1)
S为固定值时,Q=S,S为随机值时,Q=0.5(S_min+S_max)

- 误差随深度加深而降低,当模型到达19层时,误差饱和不再下降;
- 增加1×1有助于性能提升
- 训练时加入尺度扰动,有助于性能提升
② multi-scale 多尺度(论文中4.2)

- 测试时采用尺度扰动有助于性能提升
③ multi-crop 多次裁剪(论文中4.3)

等步长的滑动224×224的窗口进行裁剪,1张图片得到150张图片输入到模型中。
- multi-crop优于dense
- multi-crop结合dense,可以形成互补,达到最优结果
互补:3.2中解释到,multi crop 卷积边界用padding是0去填充,缺少边界信息,Dense的边界有原始图片的信息
④ convnet fusion 模型融合(论文中4.4)
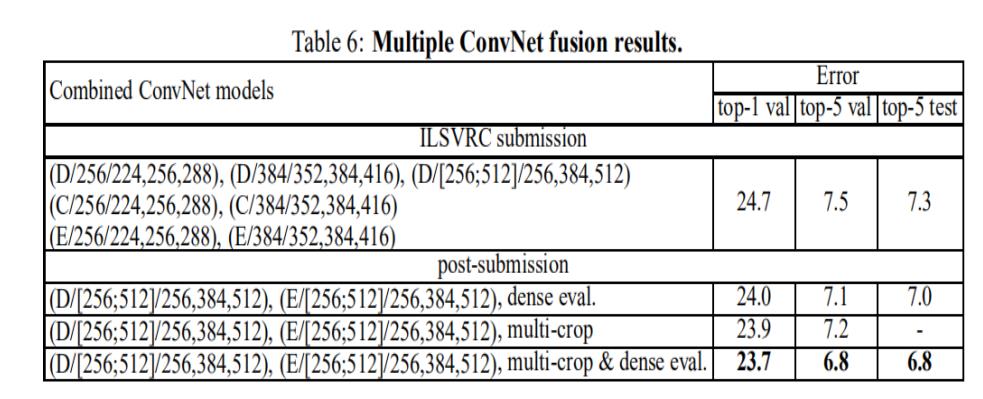
- DE模型比较深,dense, multi crop 结合,得到最优结果。
⑤ comparison with the state of art 对比当前最优模型(论文中4.5)
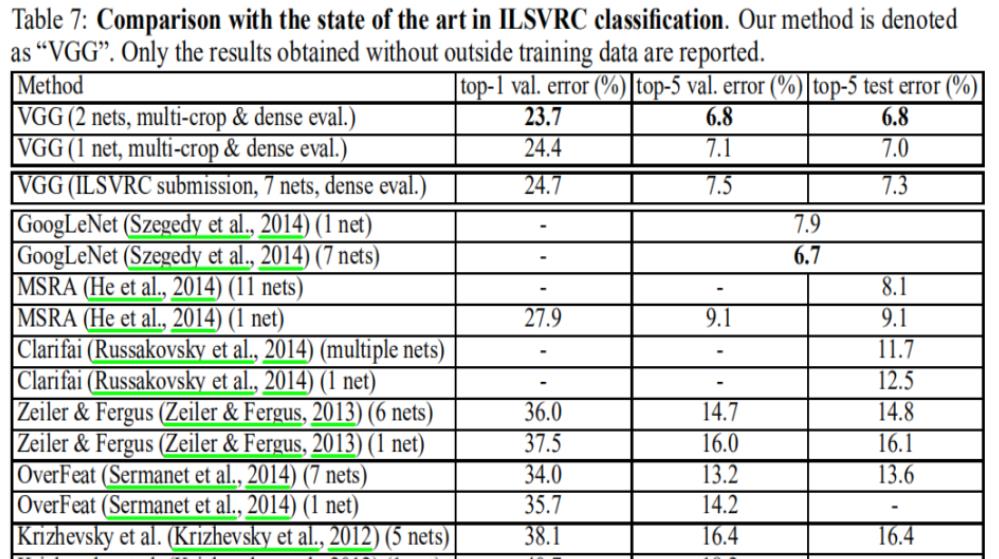
- 单模型时,vgg优于GoogleNet,并且vgg结构简单。
四、论文总结
1.关键点和创新点:
(1)最大的特点是,堆叠小的卷积层,并且从11-19层加深了网络。
(2)关于尺度扰动:
物体在原始图片中占的面积差异很大,根据具体任务提出的尺度扰动训练技巧。若任务中物体在图片中占的尺度都是稳固的,就没必要借鉴。
训练阶段,使用的尺度扰动。S=[256, 512],每个batch随机的采样一个尺寸,resize图片。
测试阶段,多尺度(Q1,Q2,Q3),都经过稠密测试,或者multi crop测试,或二者结合。
2.备用参考文献知识点:
(1)填充大小准则:保持卷积后特征图分辨率不变。(比如vgg16,分辨率只在max pool下降五次,下降32倍,别的地方不改变分辨率,所以很好计算每个地方的特征图大小,224/2的x次方)
the spatial padding of conv. layer input is such that the spatial resolution is preserved after convolution. (论文2.1的第一段)
(2)multi crop存在重复计算,低效,要用dense的稠密的计算方法
there is no need to sample multiple crops at test time (Krizhevsky et al., 2012), which is less efficient as it requires network re-computation for each crop.(论文3.2的第二段)
(3)multi crop可以看成dense的补充,因为边界处理不同。multi crop用padding来填充,dense有原始图片信息
Also, multi-crop evaluation is complementary to dense evaluation due to different convolution boundary conditions.(论文3.2的第二段)
(4)小而深的卷积网络优于大而浅的卷积网络
which confirms that a deep net with small filters outperforms a shallow net with larger filters.(论文4.1的第三段)
(5)尺度扰动对训练和测试阶段有帮助
界处理不同。multi crop用padding来填充,dense有原始图片信息
Also, multi-crop evaluation is complementary to dense evaluation due to different convolution boundary conditions.(论文3.2的第二段)
(4)小而深的卷积网络优于大而浅的卷积网络
which confirms that a deep net with small filters outperforms a shallow net with larger filters.(论文4.1的第三段)
(5)尺度扰动对训练和测试阶段有帮助
The results, presented in Table 4, indicate that scale jittering at test time leads to better performance.(论文4.2的第二段)
资料推荐:
以上是关于论文笔记系列:主干网络-- VGG的主要内容,如果未能解决你的问题,请参考以下文章