Android—以面试官要求手写HashMap
Posted bug樱樱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android—以面试官要求手写HashMap相关的知识,希望对你有一定的参考价值。
前言
上一篇提到:Android—以面试角度剖析HashMap源码,分析了HashMap源码。为了加深印象,因此这篇将会实现手写HashMap!
话不多说,直接开始!(结合上一篇一起看效果更佳哟)
1、初始化
从上一篇我们知道:HashMap初始化分为:无参构造器;有两个参数的构造器。因此我们照虎画猫也来搞两个构造器!
1.1 无参初始化
从上一篇我们得知:
- 初始化无参构造器,对应map长度默认为:1<<4,也就是16
- 初始化无参构造器,对应扩容因子默认为:0.75f
因此,有了如下代码
public class MyHashMap<K, V> implements Map<K, V>
// 扩冲
float loadFactor = 0.75f;
//16 1<<4
static int threshold = 0;
Node[] table = null;
// 2\\. 实际用到table 存储容量 大小
int size;
public MyHashMap()
threshold = 1 << 4;
很简单,直接下一个
1.2 有参初始化
从上一篇我们得知:
有参构造器对应两个参数分别为:
-
initialCapacity根据用户输入的数字,计算与其大于等于initialCapacity该变量的2的n次方,并且与initialCapacity最相近的值,该值就是对应map的默认初始长度。 -
loadFactor该变量为:对应map默认扩容因子
因此就有了如下代码:
public class MyHashMap<K, V> implements Map<K, V>
// 扩冲
float loadFactor = 0.75f;
//16 1<<4
static int threshold = 0;
Node[] table = null;
// 2\\. 实际用到table 存储容量 大小
int size;
public MyHashMap()
threshold = 1 << 4;
// 2 4 8 16 32
public MyHashMap(int initialCapacity, float loadFactor)
this.loadFactor = loadFactor;
threshold = tableSizeFor(initialCapacity);
// 数组容量的确定 hash
static final int tableSizeFor(int cap)
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return n + 1;
对应>>>在上一篇讲过,这里就不重复讲了。
OK!这个没啥难度,直接过!接下来就是本篇重点了:Put操作
2、对应Put操作
这是一个大骨头,因此这里我打算分批次讲解
2.1 hash算法计算key
在上一篇中,提到过:
-
通过hash算法计算出的key是具有散列性
-
为了使其具有散列性,我们将其与低16bit和高16bit做了一个异或
因此
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
2.2 扩容机制
从上一篇中我们得知:
- 当长度达到一定扩容条件时,将会进行扩容!
- 对应条件为:当前长度是否大于等于 当前数组长度*扩容因子
- 扩容成功时,将会根据新的长度创建出新的数组,并将原数组的所有链表复制剪切至新数组中
因此就有了
@Override
public V put(K key, V value)
synchronized (MyHashMap.class)
if (table == null)
table = new Node[threshold];
if (size >= (threshold * loadFactor))
//进行扩容
resize();
private void resize()
System.out.println("扩容前长度为:"+threshold);
//
threshold = threshold << 1;
System.out.println("扩容后长度为:"+threshold);
Node<K, V>[] newtable = new Node[threshold];
// 遍历之前的旧数据
for (int i = 0; i < table.length; i++)
//1.重新计算index 获取扩容后的下标值
Node<K, V> oldNode = table[i];
// // 如果 oldNode 为红黑树结构,那么在这,那么这里该按红黑树规则替换保存值
// if (oldNode instanceof TreeNode)
// // 此处需要根据红黑树规则 覆盖对应值
// table[i] = null;
// continue;
//
// 单向链表的遍历
while (oldNode != null)
//2.保存 下个节点
Node oldnext = oldNode.next;
int index = hash(oldNode.getKey()) & (newtable.length - 1);
oldNode.next = newtable[index];
//4.将重新链接好的链表 覆盖到 数组index对应的位置
newtable[index] = oldNode;
oldNode = oldnext;
// table
table[i] = null;
//执行完后,将newtable覆盖到原table,减少内存的占用
table = newtable;
threshold = newtable.length;
newtable = null;// 将 对象变为不可达对象 垃圾回收
原计划是想加入红黑树代码,但那个讲起来,可能比分析HashMap源码还多,真讲起来感觉重心往红黑树偏移了。读者如是想要进一步完善HashMap,可以先了解红黑树后自行添加。(对应添加位置已经备注好了)
2.3 对应Put完整代码
从上一篇我们得知:(忽略红黑树操作)
PUT操作对应的相关逻辑有:
- 首次put操作以及数组为空时需要初始化数组
- 根据hash算法计算出对应key
- 根据对应key计算出需要操作的数组下标
- 通过对应数组下标找到对应链表,如果不存在则创建新链表,并且计量长度自增1
- 如果存在对应链表,则与该链表进行key值碰撞,如果含有对应key,则直接替换对应value,计量单位不自增
- 如果找不到对应key,那么创建新的节点,将对应key-value保存至该节点,并与上一个节点next相互关联,最终计量长度自增1
- 如果长度达到了扩容因子所需要的条件,那么需要扩容
因此对应代码为:
public class MyHashMap<K, V> implements Map<K, V>
// 扩冲
float loadFactor = 0.75f;
//16 1<<4
static int threshold = 0;
Node[] table = null;
// 2\\. 实际用到table 存储容量 大小
int size;
public MyHashMap()
threshold = 1 << 4;
// 5 %3 效果差
// 位运算 15
// 2 4 8 16 32
// 14 hashmap 查找速度是最有
public MyHashMap(int initialCapacity, float loadFactor)
this.loadFactor = loadFactor;
threshold = tableSizeFor(initialCapacity);
// 数组容量的确定 hash
static final int tableSizeFor(int cap)
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return n + 1;
@Override
public V put(K key, V value)
synchronized (MyHashMap.class)
if (table == null)
table = new Node[threshold];
if (size >= (threshold * loadFactor))
//进行扩容
resize();
// 应该存放的索引值 索引 异或 与 下标
int index = hash(key) & (threshold - 1);
Node<K, V> node = table[index];
if (node == null)
node = new Node<K, V>(key, value, null);
size++;
else
// //如果要加红黑树,在这判断该 node 是否为 红黑树结构,如果真则用红黑树规则存储值
// if (node instanceof TreeNode)
//
// return 存储值或者替换值后红黑树对应节点
//
Node<K, V> newNode = node;
while (newNode != null)
// node key 单向链表
if (newNode.getKey().equals(key))
return newNode.setValue(value);
else
//若该到了链表最后的节点为空,则将新的节点添加到链表的头部
if (newNode.next == null)
// 新node river node david
node = new Node<K, V>(key, value, node);
size++;
newNode = newNode.next;
//将该节点存放到index下标位置
table[index] = node;
return null;
private void resize()
System.out.println("扩容前长度为:"+threshold);
//
threshold = threshold << 1;
System.out.println("扩容后长度为:"+threshold);
Node<K, V>[] newtable = new Node[threshold];
// 遍历之前的旧数据
for (int i = 0; i < table.length; i++)
//1.重新计算index 获取扩容后的下标值
Node<K, V> oldNode = table[i];
// // 如果 oldNode 为红黑树结构,那么在这,那么这里该按红黑树规则替换保存值
// if (oldNode instanceof TreeNode)
// // 此处需要根据红黑树规则 覆盖对应值
// table[i] = null;
// continue;
//
// 单向链表的遍历
while (oldNode != null)
//2.保存 下个节点
Node oldnext = oldNode.next;
int index = hash(oldNode.getKey()) & (newtable.length - 1);
oldNode.next = newtable[index];
//4.将重新链接好的链表 覆盖到 数组index对应的位置
newtable[index] = oldNode;
oldNode = oldnext;
// table
table[i] = null;
//执行完后,将newtable覆盖到原table,减少内存的占用
table = newtable;
threshold = newtable.length;
newtable = null;// 将 对象变为不可达对象 垃圾回收
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
结合前面分析,阅读这代码应该没啥难度,继续下一步!
3、对应Get操作以及完整代码
这个没有可讲的,就是直接通过传入的key计算下标,接着碰撞链表,如果找到了返回对应节点,没找到则返回空
上代码:
@Override
public V get(K key)
// 遍历
Node<K, V> e;
return (e = getNode(table[hash(key.hashCode()) & (threshold - 1)], key)) == null ? null : e.value;
public Node<K, V> getNode(Node<K, V> node, K k)
// // 如果 node 为红黑树结构,那么则按红黑树规则取值
// if (node instanceof TreeNode)
//
// return 红黑树规则取值
//
// 遍历单向链表
while (node != null)
if (node.getKey().equals(k) || node.getKey() == k)
return node;
node = node.next;
return null;
到这,该篇文章就快进入尾声了!贴一份完整的代码:
4、完整代码
public class MyHashMap<K, V> implements Map<K, V>
// 扩冲
float loadFactor = 0.75f;
//16 1<<4
static int threshold = 0;
Node[] table = null;
// 2\\. 实际用到table 存储容量 大小
int size;
public MyHashMap()
threshold = 1 << 4;
// 5 %3 效果差
// 位运算 15
// 2 4 8 16 32
// 14 hashmap 查找速度是最有
public MyHashMap(int initialCapacity, float loadFactor)
this.loadFactor = loadFactor;
threshold = tableSizeFor(initialCapacity);
// 数组容量的确定 hash
static final int tableSizeFor(int cap)
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return n + 1;
@Override
public V put(K key, V value)
synchronized (MyHashMap.class)
if (table == null)
table = new Node[threshold];
if (size >= (threshold * loadFactor))
//进行扩容
resize();
// 应该存放的索引值 索引 异或 与 下标
int index = hash(key) & (threshold - 1);
Node<K, V> node = table[index];
if (node == null)
node = new Node<K, V>(key, value, null);
size++;
else
// //如果要加红黑树,在这判断该 node 是否为 红黑树结构,如果真则用红黑树规则存储值
// if (node instanceof TreeNode)
//
// return 存储值或者替换值后红黑树对应节点
//
Node<K, V> newNode = node;
while (newNode != null)
// node key 单向链表
if (newNode.getKey().equals(key))
return newNode.setValue(value);
else
//若该到了链表最后的节点为空,则将新的节点添加到链表的头部
if (newNode.next == null)
// 新node river node david
node = new Node<K, V>(key, value, node);
size++;
newNode = newNode.next;
//将该节点存放到index下标位置
table[index] = node;
return null;
// 什么时候扩容 扩容的机制是怎么
private void resize()
System.out.println("扩容前长度为:"+threshold);
//
threshold = threshold << 1;
System.out.println("扩容后长度为:"+threshold);
Node<K, V>[] newtable = new Node[threshold];
// 遍历之前的旧数据
for (int i = 0; i < table.length; i++)
//1.重新计算index 获取扩容后的下标值
Node<K, V> oldNode = table[i];
// // 如果 oldNode 为红黑树结构,那么在这,那么这里该按红黑树规则替换保存值
// if (oldNode instanceof TreeNode)
// // 此处需要增加红黑树 替换 保存规则
// table[i] = null;
// continue;
//
// 单向链表的遍历
while (oldNode != null)
//2.保存 下个节点
Node oldnext = oldNode.next;
int index = hash(oldNode.getKey()) & (newtable.length - 1);
oldNode.next = newtable[index];
//4.将重新链接好的链表 覆盖到 数组index对应的位置
newtable[index] = oldNode;
oldNode = oldnext;
// table
table[i] = null;
//执行完后,将newtable覆盖到原table,减少内存的占用
table = newtable;
threshold = newtable.length;
newtable = null;// 将 对象变为不可达对象 垃圾回收
@Override
public V get(K key)
// 遍历
Node<K, V> e;
return (e = getNode(table[hash(key.hashCode()) & (threshold - 1)], key)) == null ? null : e.value;
public Node<K, V> getNode(Node<K, V> node, K k)
// // 如果 node 为红黑树结构,那么则按红黑树规则取值
// if (node instanceof TreeNode)
//
// return 红黑树规则取值
//
// 遍历单向链表
while (node != null)
if (node.getKey().equals(k) || node.getKey() == k)
return node;
node = node.next;
return null;
@Override
public int size()
return 0;
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
public void print()
for (int i = 0; i < table.length; i++)
Node<K, V> node = table[i];
System.out.print("下标=[" + i + "]");
while (node != null)
System.out.print("[ key:" + node.getKey() + ",value:" + node.getValue() + "]");
node = node.next;
System.out.println();
// 查找 和插入速度最优
//节点
class Node<K, V> implements Entry<K, V>
private K key;
private V value;
// 单项链表
private Node<K, V> next;
public Node(K key, V value, Node<K, V> next)
super();
this.key = key;
this.value = value;
this.next = next;
@Override
public K getKey()
return key;
@Override
public V getValue()
return value;
@Override
public V setValue(V value)
// 复写
V oldVlue = this.value;
this.value = value;
return oldVlue;
如果需要加入红黑树,在对应标注位置加入对应逻辑即可
5、验证结果
最后写个测试用例试一下效果
public class MyClass
public static void main(String[] args)
MyHashMap myHashMap = new MyHashMap<String, String>(14, 0.75f);
for (int i = 0; i < 30; i++)
myHashMap.put("HASH_KEY_" + i, "HASH_VALUE_" + i);
myHashMap.print();
运行效果
扩容前长度为:16
扩容后长度为:32
扩容前长度为:32
扩容后长度为:64
下标=[0]
下标=[1]
下标=[2]
下标=[3]
下标=[4]
下标=[5]
下标=[6][ key:HASH_KEY_29,value:HASH_VALUE_29]
下标=[7]
下标=[8][ key:HASH_KEY_27,value:HASH_VALUE_27]
下标=[9][ key:HASH_KEY_28,value:HASH_VALUE_28]
下标=[10][ key:HASH_KEY_25,value:HASH_VALUE_25]
下标=[11][ key:HASH_KEY_26,value:HASH_VALUE_26]
下标=[12][ key:HASH_KEY_23,value:HASH_VALUE_23]
下标=[13][ key:HASH_KEY_24,value:HASH_VALUE_24]
下标=[14][ key:HASH_KEY_21,value:HASH_VALUE_21]
下标=[15][ key:HASH_KEY_22,value:HASH_VALUE_22]
下标=[16]
下标=[17][ key:HASH_KEY_20,value:HASH_VALUE_20]
下标=[18]
下标=[19]
下标=[20]
下标=[21]
下标=[22]
下标=[23][ key:HASH_KEY_0,value:HASH_VALUE_0]
下标=[24]
下标=[25]
下标=[26]
下标=[27]
下标=[28]
下标=[29]
下标=[30]
下标=[31]
下标=[32][ key:HASH_KEY_9,value:HASH_VALUE_9]
下标=[33]
下标=[34]
下标=[35]
下标=[36]
下标=[37]
下标=[38][ key:HASH_KEY_18,value:HASH_VALUE_18]
下标=[39][ key:HASH_KEY_19,value:HASH_VALUE_19]
下标=[40][ key:HASH_KEY_1,value:HASH_VALUE_1][ key:HASH_KEY_16,value:HASH_VALUE_16]
下标=[41][ key:HASH_KEY_2,value:HASH_VALUE_2][ key:HASH_KEY_17,value:HASH_VALUE_17]
下标=[42][ key:HASH_KEY_3,value:HASH_VALUE_3][ key:HASH_KEY_14,value:HASH_VALUE_14]
下标=[43][ key:HASH_KEY_4,value:HASH_VALUE_4][ key:HASH_KEY_15,value:HASH_VALUE_15]
下标=[44][ key:HASH_KEY_5,value:HASH_VALUE_5][ key:HASH_KEY_12,value:HASH_VALUE_12]
下标=[45][ key:HASH_KEY_6,value:HASH_VALUE_6][ key:HASH_KEY_13,value:HASH_VALUE_13]
下标=[46][ key:HASH_KEY_10,value:HASH_VALUE_10][ key:HASH_KEY_7,value:HASH_VALUE_7]
下标=[47][ key:HASH_KEY_11,value:HASH_VALUE_11][ key:HASH_KEY_8,value:HASH_VALUE_8]
下标=[48]
下标=[49]
下标=[50]
下标=[51]
下标=[52]
下标=[53]
下标=[54]
下标=[55]
下标=[56]
下标=[57]
下标=[58]
下标=[59]
下标=[60]
下标=[61]
下标=[62]
下标=[63]
结果解析
从那个for循环可以看出
-
该map有效值长度为 30
-
30的长度已经超过了 320.75=24的长度,并且30<640.75f因此最终扩容至64
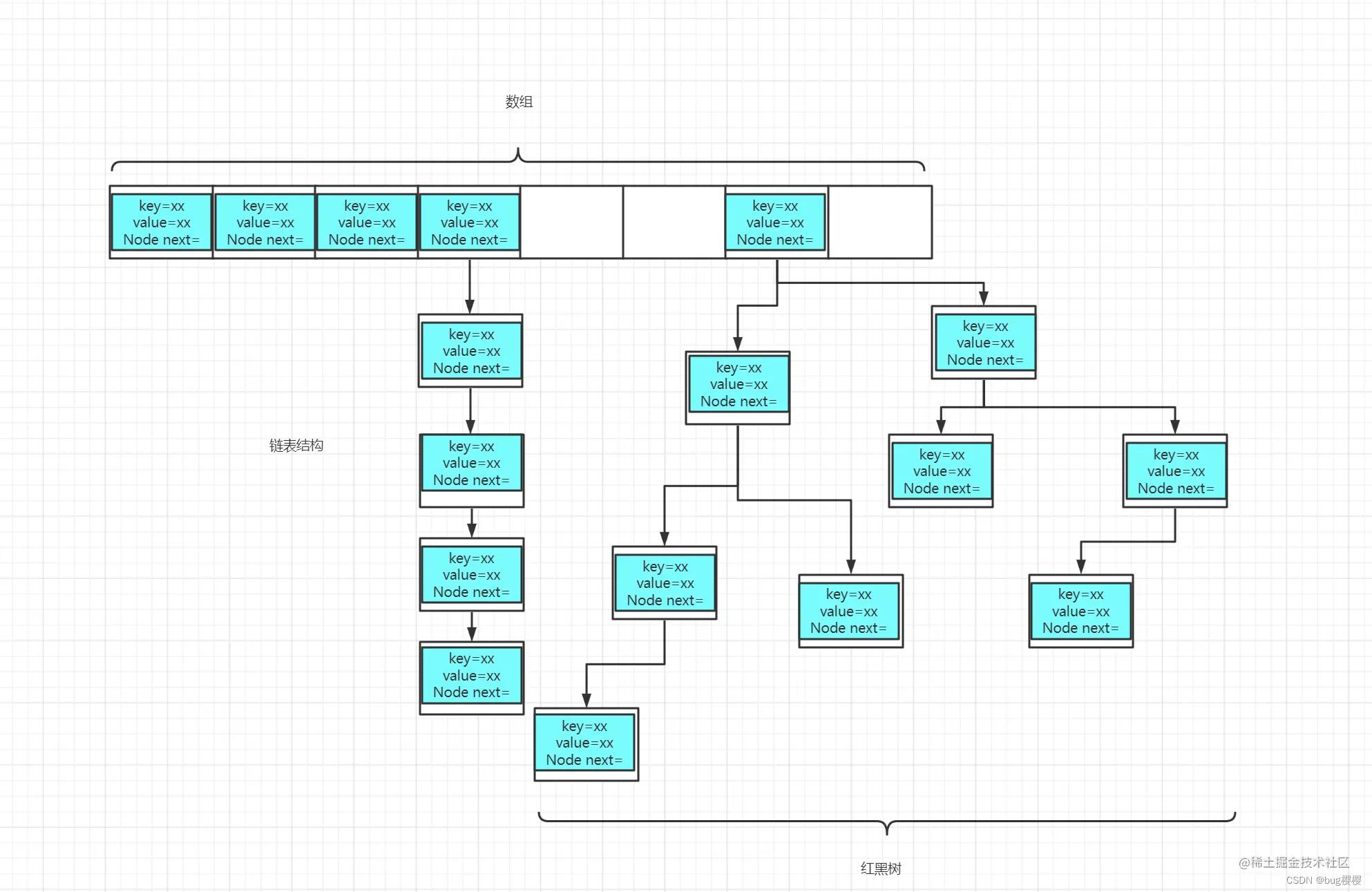
-
如图所示,通过这个结果,进一步验证了该图的结构
到这!该篇已经进入尾声了!结合上一篇,相信看到这的小伙伴,对HashMap有了完整的认知!
作者:hqk
链接:https://juejin.cn/post/7133122126374469639
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。

相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
一、架构师筑基必备技能
1、深入理解Java泛型
2、注解深入浅出
3、并发编程
4、数据传输与序列化
5、Java虚拟机原理
6、高效IO
……

二、Android百大框架源码解析
1.Retrofit 2.0源码解析
2.Okhttp3源码解析
3.ButterKnife源码解析
4.MPAndroidChart 源码解析
5.Glide源码解析
6.Leakcanary 源码解析
7.Universal-lmage-Loader源码解析
8.EventBus 3.0源码解析
9.zxing源码分析
10.Picasso源码解析
11.LottieAndroid使用详解及源码解析
12.Fresco 源码分析——图片加载流程

三、Android性能优化实战解析
- 腾讯Bugly:对字符串匹配算法的一点理解
- 爱奇艺:安卓APP崩溃捕获方案——xCrash
- 字节跳动:深入理解Gradle框架之一:Plugin, Extension, buildSrc
- 百度APP技术:Android H5首屏优化实践
- 支付宝客户端架构解析:Android 客户端启动速度优化之「垃圾回收」
- 携程:从智行 Android 项目看组件化架构实践
- 网易新闻构建优化:如何让你的构建速度“势如闪电”?
- …
四、高级kotlin强化实战
1、Kotlin入门教程
2、Kotlin 实战避坑指南
3、项目实战《Kotlin Jetpack 实战》
-
从一个膜拜大神的 Demo 开始
-
Kotlin 写 Gradle 脚本是一种什么体验?
-
Kotlin 编程的三重境界
-
Kotlin 高阶函数
-
Kotlin 泛型
-
Kotlin 扩展
-
Kotlin 委托
-
协程“不为人知”的调试技巧
-
图解协程:suspend
五、Android高级UI开源框架进阶解密
1.SmartRefreshLayout的使用
2.Android之PullToRefresh控件源码解析
3.Android-PullToRefresh下拉刷新库基本用法
4.LoadSir-高效易用的加载反馈页管理框架
5.Android通用LoadingView加载框架详解
6.MPAndroidChart实现LineChart(折线图)
7.hellocharts-android使用指南
8.SmartTable使用指南
9.开源项目android-uitableview介绍
10.ExcelPanel 使用指南
11.Android开源项目SlidingMenu深切解析
12.MaterialDrawer使用指南

六、NDK模块开发
1、NDK 模块开发
2、JNI 模块
3、Native 开发工具
4、Linux 编程
5、底层图片处理
6、音视频开发
7、机器学习

七、Flutter技术进阶
1、Flutter跨平台开发概述
2、Windows中Flutter开发环境搭建
3、编写你的第一个Flutter APP
4、Flutter开发环境搭建和调试
5、Dart语法篇之基础语法(一)
6、Dart语法篇之集合的使用与源码解析(二)
7、Dart语法篇之集合操作符函数与源码分析(三)
…

八、微信小程序开发
1、小程序概述及入门
2、小程序UI开发
3、API操作
4、购物商场项目实战……
全套视频资料:
一、面试合集

二、源码解析合集

三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓
以上是关于Android—以面试官要求手写HashMap的主要内容,如果未能解决你的问题,请参考以下文章