AI PM应该懂的自然语言处理(NLP)知识
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI PM应该懂的自然语言处理(NLP)知识相关的知识,希望对你有一定的参考价值。
参考技术A NLP是人工智能的一个子领域,作为AI产品经理,我们至少要知道NLP是什么,它能做什么事,这样我们就能获得一种解决问题的思维,将遇到的问题和方法连接起来。接下来我从“NLP是什么、能做什么、目前遇到的难题”三个方面来简单介绍下NLP。一.什么是NLP
NLP,中文叫自然语言处理,简单来说,是一门让计算机理解、分析以及生成自然语言的学科,大概的研究过程是:研制出可以表示语言能力的模型——提出各种方法来不断提高语言模型的能力——根据语言模型来设计各种应用系统——不断地完善语言模型。
NLP理解自然语言目前有两种处理方式:
1.基于规则来理解自然语言,即通过制定一些系列的规则来设计一个程序,然后通过这个程序来解决自然语言问题。输入是规则,输出是程序;
2.基于统计机器学习来理解自然语言,即用大量的数据通过机器学习算法来训练一个模型,然后通过这个模型来解决自然语言问题。输入是数据和想要的结果,输出是模型。
接下来简单介绍NLP常见的任务或应用。
二.NLP能做什么:
1.分词
中文可以分为字、词、短语、句子、段落、文档这几个层面,如果要表达一个意思,很多时候通过一个字是无法表达的一个含义的,至少一个词才能更好表达一个含义,所以一般情况是以“词”为基本单位,用“词”组合来表示“短语、、句子、段落、文档”,至于计算机的输入是短语或句子或段落还是文档就要看具体的场景。由于中文不像英文那样词与词之间用空格隔开,计算机无法用区分一个文本有哪些词,所以要进行分词。目前分词常用的方法有两种:
(1)基于规则:Heuristic(启发式)、关键字表
(2)基于机器学习/统计方法:HMM(隐马尔科夫模型)、CRF(条件随机场)
(注:在这里就不具体介绍方法的原理和实现过程了,大家感兴趣,可以自行百度了解)
现状分词这项技术非常成熟了,分词的准确率已经达到了可用的程度,也有很多第三方的库供我们使用,比如jieba,所以一般在实际运用中我们会采用“jieba+自定义词典”的方式进行分词。
2.词编码
现在把“我喜欢你”这个文本通过分词分成“我”、“喜欢”、“你”三个词,此时把这三词作为计算机的输入,计算机是无法理解的,所以我们把这些词转换成计算机能理解的方式,即词编码,现在普遍是将词表示为词向量,来作为机器学习的输入和表示空间。目前有两种表示空间:
(1)离散表示:
A.One-hot表示
假设我们的语料库是:
我喜欢你你对我有感觉吗
词典“我”:1,“喜欢”:2,“你”:3,“对“:4,“有”:5,“感觉”:6,“吗”:7 。一共有七个维度。
所以用One-hot表示:
“我” :[1, 0, 0, 0, 0, 0, 0]
“喜欢”:[0, 1, 0, 0, 0, 0, 0]
········
“吗” :[0, 0, 0, 0, 0, 0, 1]
即一个词用一个维度表示
B.bag of word:即将所有词的向量直接加和作为一个文档的向量。
所以“我 喜欢 你”就表示为:“[1, 1, 1, 0, 0, 0, 0]”。
C. Bi-gram和N-gram(语言模型):考虑了词的顺序,用词组合表示一个词向量。
这三种方式背后的思想是:不同的词都代表着不同的维度,即一个“单位”(词或词组合等)为一个维度。
(2)分布式表示:word2vec,表示一个共现矩阵向量。其背后的思想是“一个词可以用其附近的词来表示”。
离散式或分布式的表示空间都有它们各自的优缺点,感兴趣的读者可以自行查资料了解,在这里不阐述了。这里有一个问题,当语料库越大时,包含的词就越多,那词向量的维度就越大,这样在空间储存和计算量都会指数增大,所以工程师在处理词向量时,一般都会进行降维,降维就意味着部分信息会丢失,从而影响最终的效果,所以作为产品经理,跟进项目开发时,也需要了解工程师降维的合理性。
3.自动文摘
自动文摘是指在原始文本中自动摘要出关键的文本或知识。为什么需要自动文摘?有两个主要的原因:(1)信息过载,我们需要在大量的文本中抽出最有用、最有价值的文本;(2)人工摘要的成本非常高。目前自动文摘有两种解决思路:第一种是extractive(抽取式),从原始文本中找到一些关键的句子,组成一篇摘要;另一种方式是abstractive(摘要式),计算机先理解原始文本的内容,再用自己的意思将其表达出来。自动文摘技术目前在新闻领域运用的最广,在信息过载的时代,用该技术帮助用户用最短的时间了解最多、最有价值的新闻。此外,如何在非结构的数据中提取结构化的知识也将是问答机器人的一大方向。
4.实体识别
实体识别是指在一个文本中,识别出具体特定类别的实体,例如人名、地名、数值、专有名词等。它在信息检索、自动问答、知识图谱等领域运用的比较多。实体识别的目的就是告诉计算机这个词是属于某类实体,有助于识别出用户意图。比如百度的知识图谱:
“周星驰多大了”识别出的实体是“周星驰”(明星实体),关系是“年龄”,搜索系统可以知道用户提问的是某个明星的年龄,然后结合数据“周星驰 出生时间 1962年6月22日”以及当前日期来推算出周星驰的年龄,并把结果直接把这个结果显示给用户,而不是显示候选答案的链接。
此外,NLP常见的任务还有:主题识别、机器翻译、文本分类、文本生成、情感分析、关键字提取、文本相似度等,以后有时间再为大家做简单介绍。
三.NLP目前存在的难点
1.语言不规范,灵活性高
自然语言并不规范,虽然可以找一些基本规则,但是自然语言太灵活了,同一个意思可以用多种方式来表达,不管是基于规则来理解自然语言还是通过机器学习来学习数据内在的特征都显得比较困难。
2.错别字
在处理文本时,我们会发现有大量的错别字,怎么样让计算机理解这些错别字想表达的真正含义,也是NLP的一大难点
3.新词
我们处在互联网高速发展的时代,网上每天都会产生大量的新词,我们如何快速地发现这些新词,并让计算机理解也是NLP的难点
4.用词向量来表示词依然存在不足
上述,我们讲到,我们是通过词向量来让计算机理解词,但是词向量所表示的空间,它是离散,而不是连续,比如表示一些正面的词:好,很好,棒,厉害等,在“好”到“很好”的词向量空间中,你是不能找到一些词,从“好”连续到“很好”,所以它是离散、不连续的,不连续最大的问题就是不可导.计算机是处理可导的函数非常容易,不可导的话,计算量就上来了。当然现在也有一些算法是计算词向量做了连续近似化,但这肯定伴随着信息的损失。总之,词向量并不是最好的表示词的方式,需要一种更好的数学语言来表示词,当然可能我们人类的自然语言本身就是不连续的,或者人类无法创建出“连续”的自然语言。
小结:通过上述的内容,我们已经大概知道了“NLP是什么、能做什么以及目前存在的难题”。作为人工智能产品经理,了解NLP技术能够提高我们自己的技术理解力,在理解行业需求、推进项目开展都有非常大的帮助,其实这可以让我们获得是一种连接能力,将需求与工程师连接起来,将问题与解决方案连接起来。虽然NLP等人工智能技术存在很多不足,但我们需要调整好自己的心态,人工智能应用化才刚刚开始,必然是不够完美的,不要成为批判者,而是成为人工智能时代的推进者。
nt-sizf@�2W��
「AI专题实训通知」自然语言处理与知识图谱构建
人工智能的认知、理解、生成等过程离不开自然语言处理(NLP)技术,其算法包括非监督学习、半监督学习、强化学习以及深度学习与深度强化学习等,是人工智能领域研究与应用的热点。同时,知识图谱(KG)是人工智能时代实现概念识别、实体发现、属性预测、协同推理、知识演化和关系挖掘等功能的底层关键技术,也是大知识与数据融合、数据认知与推理的核心技术。2018年行业知识图谱的有效落地带动了NLP、KG和算法人才需求的猛增,加剧了NLP和KG人才紧缺的局势。
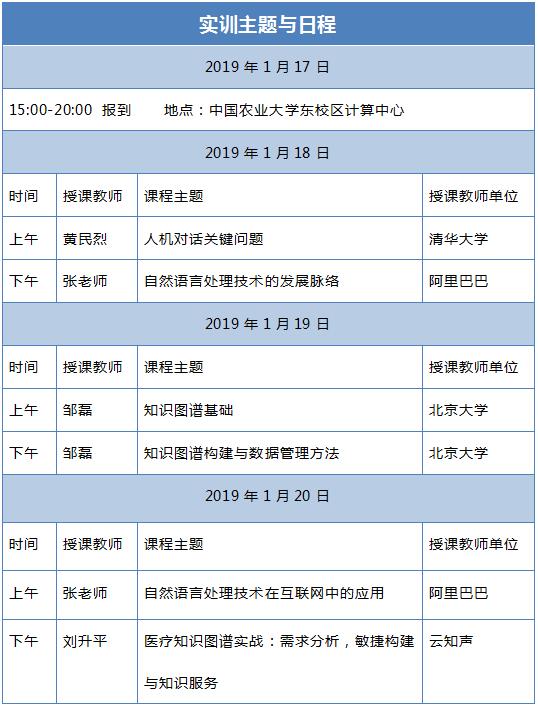
DataFun社区2019年1月18-20日在北京举办专题实训,欢迎自然语言处理与知识图谱技术相关领域的高校师生、科研人员与IT从业者参会。
1、实训价格
非学生2900元/人、学生1800元/人,含电子版资料费、发票费、场地费、会议注册费等。
银行转账信息:
开户名: 北京上善如水商业管理顾问有限公司
开户银行: 工行北京市六里桥支行
账号: 0200281009021400308
说明:委托会务公司“北京上善如水商业管理顾问有限公司”代收会务费并负责开具会务费发票,支持转账、公务卡、银联卡、微信、支付宝的缴费方式。
2、交通、食宿自理。请自行预订北京海淀区清华东路附近酒店。
3、会务联系
4、报名方式
识别下图二维码,或者点击文末阅读原文:

5、实训证书
实训学员可自愿申请工业和信息化部人才交流中心颁发的《工业和信息化领域急需紧缺人才培养工程证书》,需缴纳证书费RMB 300元/人(含审核费和工本费)、1张两寸电子版照片(电子版照片命名格式:姓名-身份证号码)。
说明:培训结束一个月内完成证书审核,由发证机关邮寄。
l 授课专家介绍
1 黄民烈

清华大学计算机系副教授,博士生导师。研究兴趣主要集中在人工智能、深度学习、强化学习,自然语言处理如自动问答、人机对话系统、情感与情绪智能等。已超过 50 篇 CCF A/B 类论文发表在 ACL、IJCAI、AAAI、EMNLP、KDD、ICDM、ACM TOIS、Bioinformatics、JAMIA 等国际顶级和主流会议及期刊上。曾担任多个国际顶级会议的领域主席或高级程序委员,如 IJCAI 2018、IJCAI 2017、ACL 2016、EMNLP 2014/2011,IJCNLP 2017 等,担任 ACM TOIS、TKDE、TPAMI、CL 等顶级期刊的审稿人。作为负责人或学术骨干,负责或参与多项国家 973、863 子课题、多项国家自然科学基金,并与国内外知名企业如谷歌、微软、三星、惠普、美孚石油、斯伦贝谢、阿里巴巴、腾讯、百度、搜狗、美团等建立了广泛的合作。获得专利授权近 10 项,其中 2 项专利技术授权给企业应用。
2 邹磊

北京大学计算机科学技术研究所教授、博士生导师。国家自然科学基金委优秀青年基金项目获得者,北京大学大数据科学研究中心主任助理。目前的主要研究领域包括图数据库,RDF知识图谱,尤其是基于图的RDF数据管理。邹磊及其团队构建了面向海量RDF知识图谱数据(超过100亿三元组规模)的开源图数据库系统。邹磊已经发表了50余篇国内外学术论文,包括数据库领域国际顶级期刊/会议论文(SIGMOD,VLDB等)近30余篇; 邹磊获得2009年中国计算机学会优秀博士学位论文提名奖和2014年中国计算机学会自然科学二等奖(排名第一); 2017年获得教育部自然科学二等奖(排名第一)。
3 刘升平
云知声AI Labs的资深技术专家。他是前IBM中国研究院资深研究员,中文信息学会语言与知识计算专委会医疗知识图谱工作组共同发起人,医疗健康与生物信息处理专委会委员。2005年获得北京大学数学学院信息科学系博士。曾在语义网,机器学习、信息检索,医学信息学等领域发表过20多篇论文。在IBM中国研究院信息与知识组工作期间,多次获得过IBM研究成就奖。目前在云知声领导NLP和智慧医疗团队,主要从事要从事自然语言理解和生成,人机对话系统,聊天机器人,知识图谱,临床辅助诊断系统等研发工作。
4 张老师
参会报名回执表
可复制后填写,或下载(复制到网页打开):https://pan.baidu.com/s/1eU3sC_mWKPpg9HyY1naMZQ
请发至会务邮箱1319050263@qq.com
参会 学员 信息 |
单位名称 |
||
姓名 |
|||
发票信息 |
发票抬头 |
注:请与单位财务确认此信息 |
|
纳税人识别号 |
注:请与单位财务确认此信息 |
||
注:请与单位财务确认此信息 |
|||
开户行及账号 |
注:请与单位财务确认此信息 |
||
发票种类 |
□ 增值税普通发票 □ 增值税专用发票 |
注:请与单位财务确认此信息 |
|
发票内容 |
1、□会议费 2、□培训费 |
||
银行 对公转账 信息 |
开户名: 北京上善如水商业管理顾问有限公司 开户银行: 工行北京市六里桥支行 账号: 0200281009021400308 |
||
会务 |
|||
l 注意事项
1.转账缴费:将报名回执和转账回执发送至会务组邮箱,银行转账务必备注:NLPKG-参会人姓名—参会人手机号码,报到时领取发票。
2.现场缴费:将报名回执发送至会务组邮箱,培训结束后邮寄发票。
3.会务组邮箱:1319050263@qq.com或pangjinhui1@126.com
4.学生需提供学生证明参会。
l 优惠方案
1月11号24点前转账缴费优惠(仅限享受其中一项优惠)
1.缴费成功者可享受课程减免100元。
2.团报缴费:3人团体缴费成功者每人减免150元;6人及以上团体缴费成功者每人减免300元。(仅限选一种团体方式)
3.推荐优惠:凡推荐朋友报名缴费成功者,推荐者与被推荐者各奖励50元。(此优惠可与第1款、第2款累加)
1月11号24点以后缴费(含会场缴费)仅半价享受团报优惠
1.团报缴费:3人团体缴费成功者每人减免80元;6人及以上团体缴费成功者每人减免150元。(仅限选一种团体方式)
2.推荐优惠:凡推荐朋友报名缴费成功者,推荐者与被推荐者各奖励30元。(此优惠可与第1款团报缴费优惠累加)
l 实训证书样例
以上是关于AI PM应该懂的自然语言处理(NLP)知识的主要内容,如果未能解决你的问题,请参考以下文章