Hadoop3 - 基本介绍与使用
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop3 - 基本介绍与使用相关的知识,希望对你有一定的参考价值。
一、Hadoop介绍
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
广义上来说,Hadoop 通常是指Hadoop生态圈,狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
-
HDFS(分布式文件系统):解决海量数据存储
-
YARN(作业调度和集群资源管理的框架):解决资源任务调度
-
MAPREDUCE(分布式运算编程框架):解决海量数据计算
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。
| 框架 | 简介 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式运算程序开发框架 |
| ZooKeeper | 分布式协调服务基础组件 |
| HIVE | 基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作 |
| FLUME | 日志数据采集框架 |
| oozie | 工作流调度框架 |
| Sqoop | 数据导入导出工具(比如用于mysql和HDFS之间) |
| Impala | 基于hive的实时sql查询分析 |
| Mahout | 基于mapreduce/spark/flink等分布式运算框架的机器学习算法库 |
Hadoop生态圈:
Hadoop特性优点
-
扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
-
成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
-
高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
-
可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
二、Hadoop历史版本与版本类型
历史版本间的变化:
-
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰 -
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。 -
3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
版本类型:
Hadoop 发行版本分为开源社区版和商业版。
-
社区版是指由 Apache 软件基金会维护的版本,是官方维护的版本体系。
-
商业版Hadoop是指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH、mapR、hortonWorks等。
三、Hadoop3 的新特性
通用性:
- 精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现。
- Classpath isolation:以防止不同版本jar包冲突
- Shell脚本重构: Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性。
HDFS:
Hadoop3.x中Hdfs在可靠性和支持能力上作出很大改观:
-
HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。
-
多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。
HDFS纠删码:
在Hadoop3.X中,HDFS实现了Erasure Coding这个新功能。Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术。它通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性。在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复。
hadoop-3.0之前,HDFS存储方式为每一份数据存储3份,这也使得存储利用率仅为1/3,hadoop-3.0引入纠删码技术(EC技术),实现1份数据+0.5份冗余校验数据存储方式。与副本相比纠删码是一种更节省空间的数据持久化存储方法。标准编码(比如Reed-Solomon(10,4))会有1.4 倍的空间开销;然而HDFS副本则会有3倍的空间开销。
支持多个NameNodes:
最初的HDFS NameNode high-availability实现仅仅提供了一个active NameNode和一个Standby NameNode;并且通过将编辑日志复制到三个JournalNodes上,这种架构能够容忍系统中的任何一个节点的失败。然而,一些部署需要更高的容错度。我们可以通过这个新特性来实现,其允许用户运行多个Standby NameNode。比如通过配置三个NameNode和五个JournalNodes,这个系统可以容忍2个节点的故障,而不是仅仅一个节点。
MapReduce:
Hadoop3.X中的MapReduce较之前的版本作出以下更改:
-
Tasknative优化:为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。
-
MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,一旦设置不合理,则会使得内存资源浪费严重,在Hadoop3.0中避免了这种情况。
Hadoop3.x中的MapReduce添加了Map输出collector的本地实现,对于shuffle密集型的作业来说,这将会有30%以上的性能提升。
四、Hadoop HDFS 主要角色
NameNode
NameNode 是HDFS中存储元数据(元数据就是文件名称,大小和在电脑中的位置)的地方,它将所有文件和文件夹的元素据保存在一个文件系统目录树中,任何元数据的改变,NameNode都会记录。HDFS中的每个文件都会拆分为多个数据块存放,这种文件与数据块的对应关系也存储在文件系统目录树中,由NameNode维护。
NameNode还存储数据块到DataNode的映射信息,这种映射信息包括:数据块存放在哪个DataNode中、每个DataNode保存了哪些数据块。
NameNode会监听DataNode的“心跳”和“块报告”,通过心跳和NameNode保持通讯。
DataNode
HDFS中真正存储数据的地方。客户端可以向DataNode请求写入或读取数据块,DataNode还在来自NameNode的指令下执行块的创建、删除和复制,并且周期性的向NameNode汇报数据块的信息。
SecondaryNameNode
一个辅助工具,它用于帮助NameNode管理元数据,从而使NameNode能够快速、高效的工作。
五、Hadoop HDFS 单机模式搭建
首先准备一台 Linux 服务器,关闭防火墙,由于 Hadoop 是基于 Java 实现的,所以还需要安装好 Java 环境。

下载 Hadoop 安装包,这里我使用的是 3.1.4 版本:
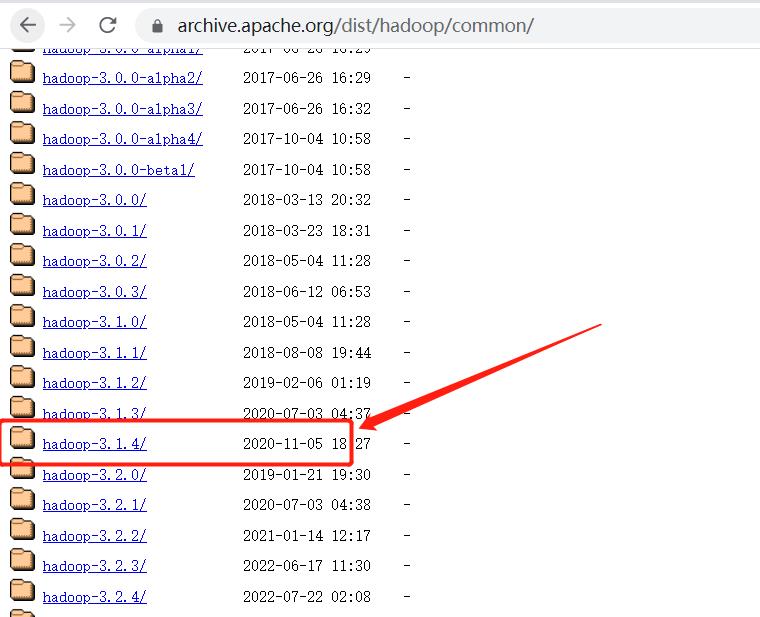
将下载的安装包上传至服务器,并解压。
Hadoop安装包目录结构介绍
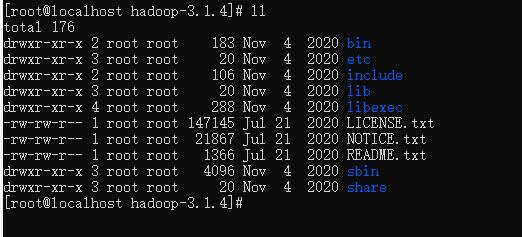
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
配置 Hadoop 环境变量:
vi /etc/profile
在文件最后添加如下两行,注意路径地址为你解压后的目录:
export HADOOP_HOME=/export/software/hadoop-3.1.4
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使配置文件生效
source /etc/profile
查看 Hadoop 的版本:
hadoop version

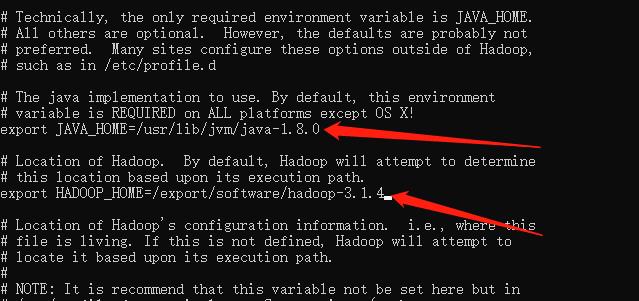
修改解压目录下 etc/hadoop/hadoop-env.sh 文件,指定 Java 安装地址和 hadoop 安装地址:
vi etc/hadoop/hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
# Location of Hadoop.
export HADOOP_HOME=/export/software/hadoop-3.1.4
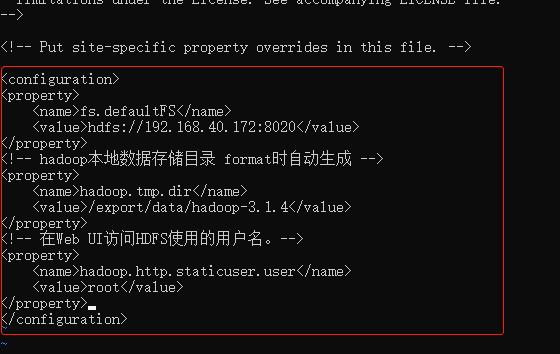
修改解压目录下 etc/hadoop/core-site.xml 文件:
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.40.172:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
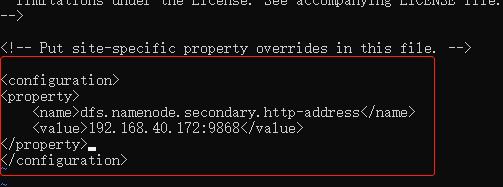
修改解压目录下 etc/hadoop/hdfs-site.xml 文件:
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.40.172:9868</value>
</property>
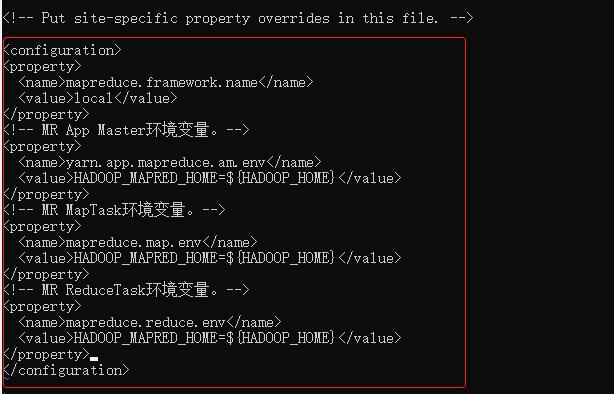
修改解压目录下 etc/hadoop/mapred-site.xml 文件:
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>local</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
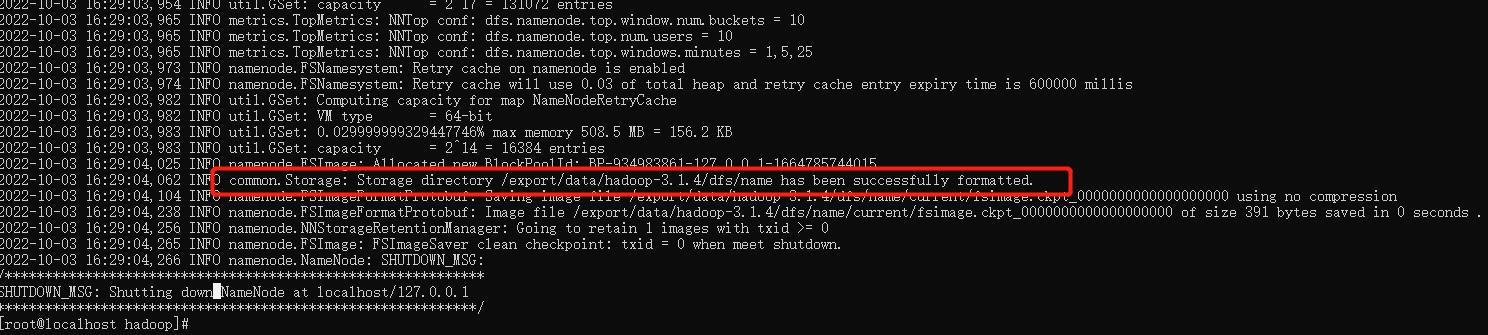
格式化 NameNode,首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
hdfs namenode -format
出现以下提示则格式化成功
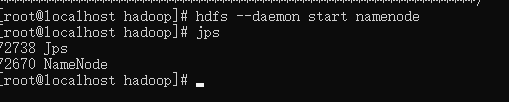
启动 NameNode:
hdfs --daemon start namenode
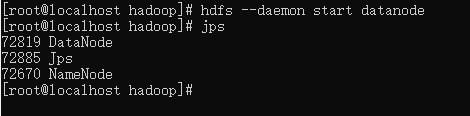
启动 DataNode:
hdfs --daemon start datanode
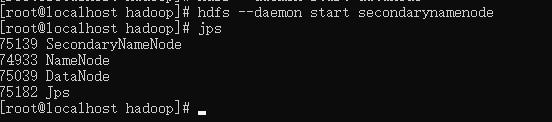
启动Secondary NameNode
hdfs --daemon start secondarynamenode
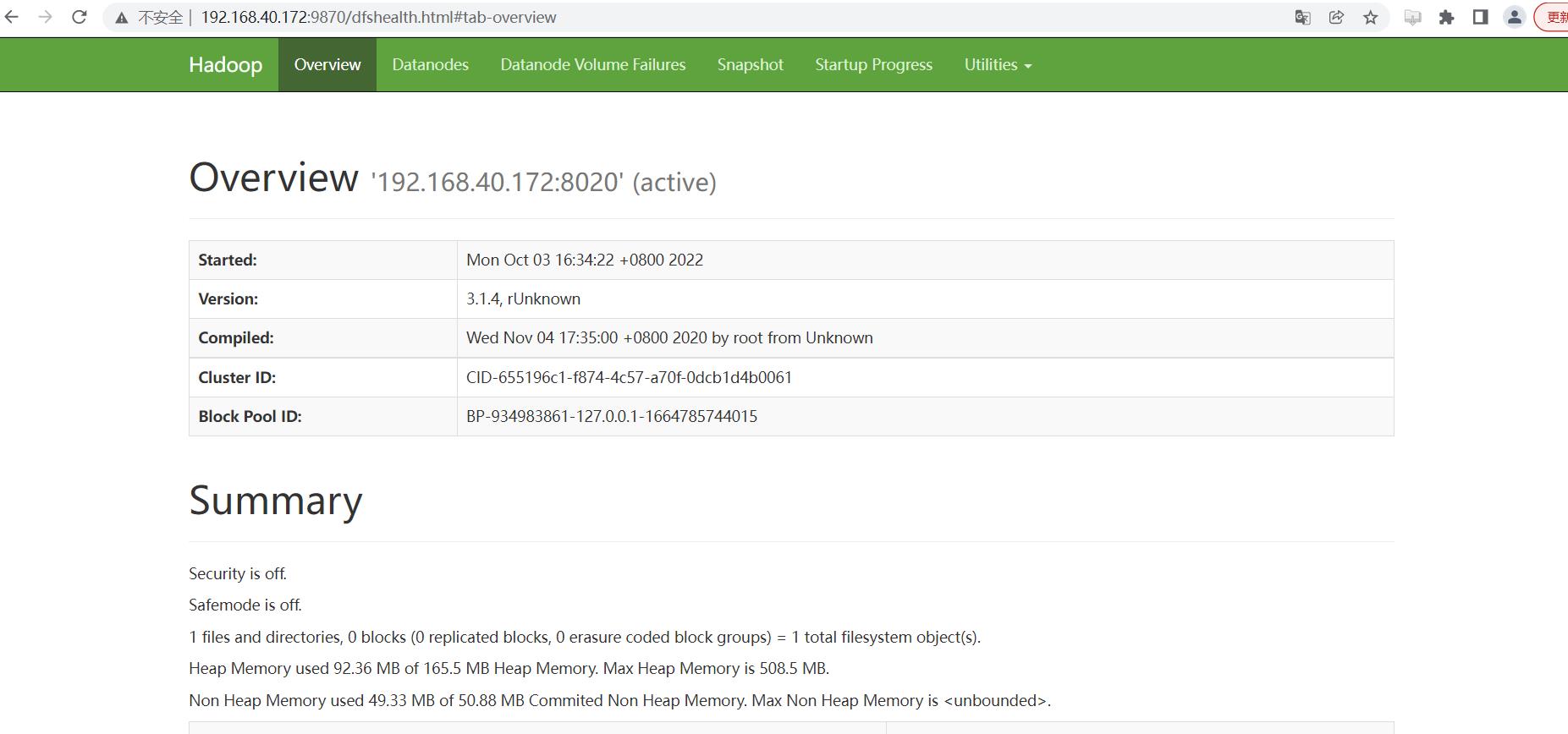
浏览器访问 HDFS 的管理界面:http://192.168.40.172:9870/ :
六、文件测试
创建一个 txt 文件,将其上传至 HDFS 中:
echo "hello" > a.txt
上传 a.txt
hadoop fs -put a.txt /
去可视化页面查看该文件是否上传:
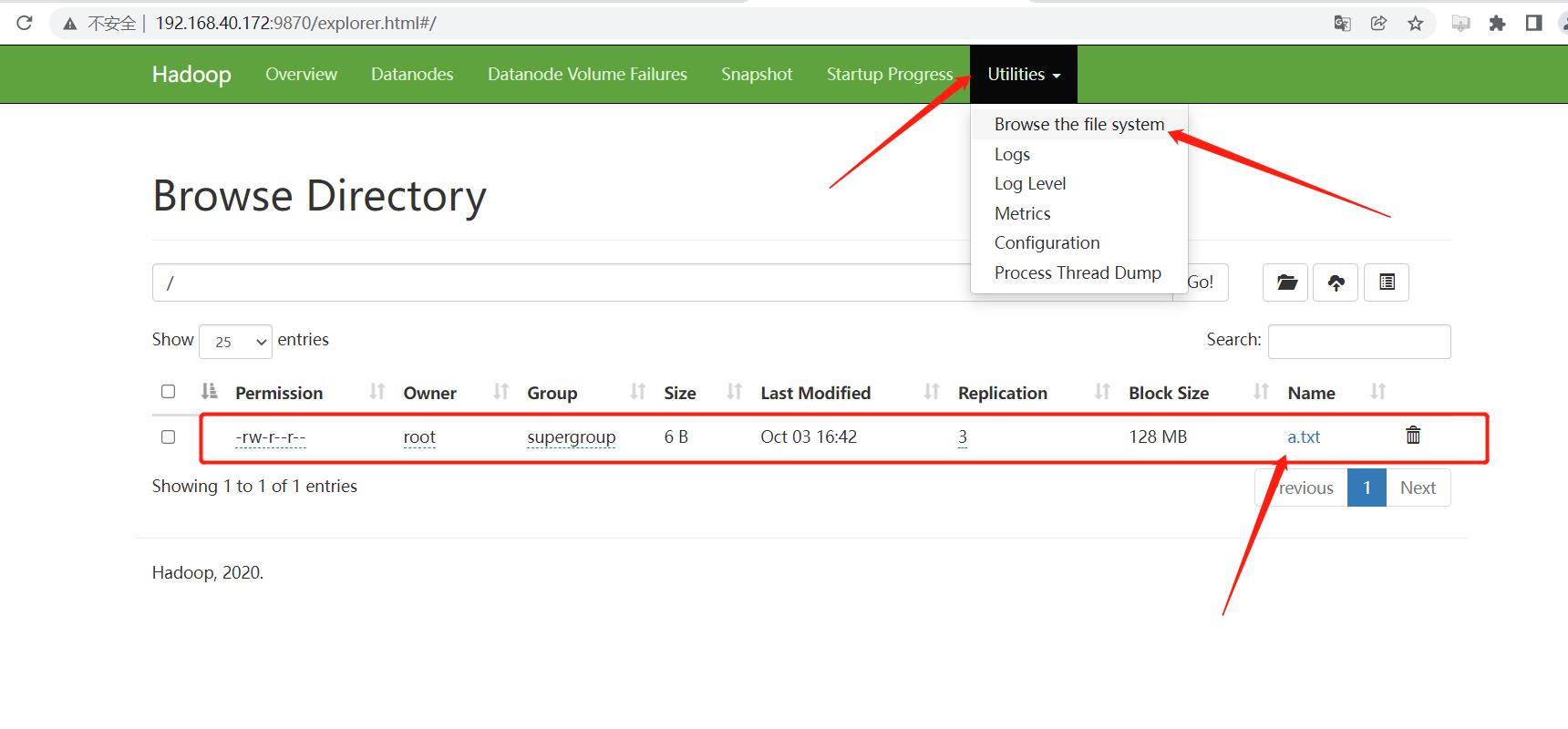
已经上传成功!
以上是关于Hadoop3 - 基本介绍与使用的主要内容,如果未能解决你的问题,请参考以下文章