特征筛选还在用XGB的Feature Importance?试试Permutation Importance
Posted 我爱Python数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征筛选还在用XGB的Feature Importance?试试Permutation Importance相关的知识,希望对你有一定的参考价值。
特征筛选是建模过程中的重要一环。
基于决策树的算法,如 Random Forest,Lightgbm, Xgboost,都能返回模型默认的 Feature Importance,但诸多研究都表明该重要性是存在偏差的。
是否有更好的方法来筛选特征呢?Kaggle 上很多大师级的选手通常采用的一个方法是 Permutation Importance。这个想法最早是由 Breiman(2001)提出,后来由 Fisher,Rudin,and Dominici(2018)改进。
本文你将通过一个 Kaggle Amex 真实数据了解到,模型默认的 Feature Importance 存在什么问题,什么是 Permutation Importance,它的优劣势分别是什么,以及具体代码如何实现和使用。
本文目录
本文由技术群一位大佬的推荐与分享,想加入交流或者完整代码,按照如下方式
目前开通了技术交流群,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN+技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群+CSDN
模型默认的Feature Importance存在什么问题?
Strobl et al [3] 在 2007 年就提出模型默认的 Feature Importance 会偏好连续型变量或高基数(high cardinality)的类型型变量。这也很好理解,因为连续型变量或高基数的类型变量在树节点上更容易找到一个切分点,换言之更容易过拟合。
另外一个问题是,Feature Importance 的本质是训练好的模型对变量的依赖程度,它不代表变量在 unseen data(比如测试集)上的泛化能力。特别当训练集和测试集的分布发生偏移时,模型默认的 Feature Importance 的偏差会更严重。
举一个极端的例子,如果我们随机生成一些 X 和二分类标签 y,并用 XGB 不断迭代。随着迭代次数的增加,训练集的 AUC 将接近 1,但是验证集上的 AUC 仍然会在 0.5 附近徘徊。这时模型默认的 Feature Importance 仍然会有一些变量的重要性特别高。这些变量帮助模型过拟合,从而在训练集上实现了接近 1 的 AUC。但实际上这些变量还是无意义的。
什么是Permutation Importance?
Permutation Importance 是一种变量筛选的方法。它有效地解决了上述提到的两个问题。
Permutation Importance 将变量随机打乱来破坏变量和 y 原有的关系。如果打乱一个变量显著增加了模型在验证集上的loss,说明该变量很重要。如果打乱一个变量对模型在验证集上的 loss 没有影响,甚至还降低了 loss,那么说明该变量对模型不重要,甚至是有害的。
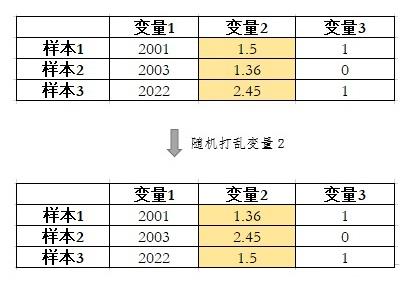
▲ 打乱变量示例
变量重要性的具体计算步骤如下:
-
1. 将数据分为 train 和 validation 两个数据集
-
2. 在 train 上训练模型,在 validation 上做预测,并评价模型(如计算 AUC)
-
3. 循环计算每个变量的重要性:
-
(3.1) 在 validation 上对单个变量随机打乱;
-
(3.2)使用第 2 步训练好的模型,重新在 validation 做预测,并评价模型;
-
(3.3)计算第 2 步和第 3.2 步 validation 上模型评价的差异,得到该变量的重要性指标
Python 代码步骤(model 表示已经训练好的模型):
def permutation_importances(model, X, y, metric):
baseline = metric(model, X, y)
imp = []
for col in X.columns:
save = X[col].copy()
X[col] = np.random.permutation(X[col])
m = metric(model, X, y)
X[col] = save
imp.append(baseline - m)
return np.array(imp)
Permutation Importance的优劣势是什么?
3.1 优势
-
可以在任何模型上使用。不只是在基于决策树的模型,在线性回归,神经网络,任何模型上都可以使用。
-
不存在对连续型变量或高基数类别型变量的偏好。
-
体现了变量的泛化能力,当数据发生偏移时会特别有价值。
-
相较于循环的增加或剔除变量,不需要对模型重新训练,极大地降低了成本。但是循环地对模型做预测仍然会花费不少时间。
3.2 劣势
-
对变量的打乱存在随机性。这就要求随机打乱需要重复多次,以保证统计的显著性。
-
对相关性高的变量会低估重要性,模型默认的 Feature Importance 同样存在该问题。
Amex数据实例验证

▲ Kaggle Amex逾期预测比赛
理论听起来可能有点头痛,我们直接以 Kaggle 的 Amex 数据作为实例,验证下 Permutation Importance 的效果。
考虑到 Permutation Importance 的随机性,我们将数据划分为 10 个 fold,并且每个变量随机打乱 10 次,所以每个变量总共打乱 100 次,再计算打乱后模型评价差异的平均值,以保证统计上的显著性。之后我们可以再谈谈如何更好地随机打乱以节省资源。
这里我们分别对比3种变量重要性的排序:
-
模型默认的 Feature Importance
-
Permutation Importance
-
标准化后的 Permutation Importance:Permutation Importance / 随机 100 次的标准差。这考虑到了随机性。如果在 Permutation Importance 差不多的情况下,标准差更小,说明该变量的重要性结果是更稳定的。
为了简化实验,这里随机筛选了总共 300 个变量。使用 300 个变量时,模型 10 fold AUC 为 0.9597。
下表是不同变化重要性排序下,模型 AUC 随着变量个数增加的变化情况:
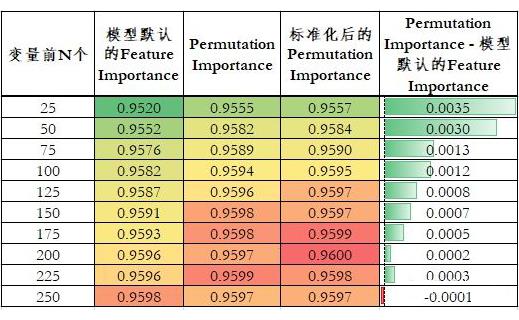
▲ 不同变量重要性排序下,模型效果的变化情况
由此我们可以得到如下结论:
-
Permutation Importance 相较于模型默认的 Feature Importance 具有更好的排序性。当变量个数小于 250 个时,使用 Permutation Importance 排序的变量模型效果都更好。
-
随着变量个数的增加,模型默认的 Feature Importance 和 Permutation Importance 两种排序的模型 AUC 差异逐渐减小。这也间接说明 Permutation Importance 的重要性排序更好。因为在变量个数少的时候,两种排序筛选的变量差异会更大。随着变量的增加,两种排序下变量的重合逐渐增加,差异逐渐减小。
-
标准化后的 Permutation Importance 效果仅略微好于 Permutation Importance,这在真实业务场景意义较低,在建模比赛中有一定价值。
以上是关于特征筛选还在用XGB的Feature Importance?试试Permutation Importance的主要内容,如果未能解决你的问题,请参考以下文章