数据湖技术之Hudi 集成 Spark
Posted 潘小磊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖技术之Hudi 集成 Spark相关的知识,希望对你有一定的参考价值。
数据湖技术之Hudi 集成 Spark
数据湖框架Hudi,从诞生之初支持Spark进行操作,后期支持Flink,接下来先看看与Spark整合使用,并且在0.9.0版本中,提供SparkSQL支持,编写DDL和DML操作数据。
文章目录
- 数据湖技术之Hudi 集成 Spark
- 4.1 环境准备
4.1 环境准备
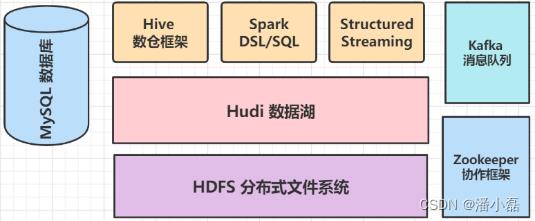
Hudi数据湖框架,开始与Spark分析引擎框架整合,通过Spark保存数据到Hudi表,使用Spark加载Hudi表数据进行分析,不仅支持批处理和流计算,还可以集成Hive进行数据分析,安装大数据其他框架:mysql、Hive、Zookeeper及Kafka,便于案例集成整合使用。
4.1.1 安装MySQL 5.7.31
采用tar方式安装MySQL数据库,具体命令和相关说明如下
1. 检查系统是否安装过mysql
rpm -qa|grep mysql
2. 卸载CentOS7系统自带mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs.xxxxxxx
3. 删除etc目录下的my.cnf ,一定要删掉,等下再重新建
rm /etc/my.cnf
4. 创建mysql 用户组和用户
groupadd mysql
useradd -r -g mysql mysql
5. 下载安装,从官网安装下载,位置在/usr/local/
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
6. 解压安装mysql
tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
cd /usr/local/
mv mysql-5.7.31-linux-glibc2.12-x86_64 mysql
7. 进入mysql/bin/目录,编译安装并初始化mysql,务必记住数据库管理员临时密码
cd mysql/bin/
./mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data --basedir=/usr/local/mysql
8. 编写配置文件 my.cnf ,并添加配置
vi /etc/my.cnf
[mysqld]
datadir=/usr/local/mysql/data
port = 3306
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
symbolic-links=0
max_connections=400
innodb_file_per_table=1
lower_case_table_names=1
9. 启动mysql 服务器
/usr/local/mysql/support-files/mysql.server start
10. 添加软连接,并重启mysql 服务
ln -s /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
service mysql restart
11. 登录mysql ,密码就是初始化时生成的临时密码 X_j&N*wy1q7<
mysql -u root -p
12、修改密码,因为生成的初始化密码难记
set password for root@localhost = password('123456');
13、开放远程连接
use mysql;
update user set user.Host='%' where user.User='root';
flush privileges;
14. 设置开机自启
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --list
最后使用MySQL数据库客户端远程链接数据库,测试是否成功。
4.1.2 安装Hive 2.1
直接解压Hive框架tar包,配置HDFS依赖及元数据存储MySQL数据库信息,最后启动元数据服务Hive MetaStore和HiveServer2服务。
1. 上传,解压
[root@node1 ~]# cd /export/software/
[root@node1 server]# rz
[root@node1 server]# chmod u+x apache-hive-2.1.0-bin.tar.gz
[root@node1 server]# tar -zxf apache-hive-2.1.0-bin.tar.gz -C /export/server
[root@node1 server]# cd /export/server
[root@node1 server]# mv apache-hive-2.1.0-bin hive-2.1.0-bin
[root@node1 server]# ln -s hive-2.1.0-bin hive
2. 配置环境变量
[root@node1 server]# cd hive/conf/
[root@node1 conf]# mv hive-env.sh.template hive-env.sh
[root@node1 conf]# vim hive-env.sh
HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
3. 创建HDFS目录
[root@node1 ~]# hadoop-daemon.sh start namenode
[root@node1 ~]# hadoop-daemon.sh start datanode
[root@node1 ~]# hdfs dfs -mkdir -p /tmp
[root@node1 ~]# hdfs dfs -mkdir -p /usr/hive/warehouse
[root@node1 ~]# hdfs dfs -chmod g+w /tmp
[root@node1 ~]# hdfs dfs -chmod g+w /usr/hive/warehouse
4. 配置文件hive-site.xml
[root@node1 ~]# cd /export/server/hive/conf
[root@node1 conf]# vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1.itcast.cn:3306/hive_metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.itcast.cn:9083</value>
</property>
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
</property>
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>123456</value>
</property>
</configuration>
5. 添加用户权限配置
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop
[root@node1 hadoop] vim core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
6. 初始化数据库
[root@node1 ~]# cd /export/server/hive/lib
[root@node1 lib]# rz
mysql-connector-java-5.1.48.jar
[root@node1 ~]# cd /export/server/hive/bin
[root@node1 bin]# ./schematool -dbType mysql -initSchema
7. 启动HiveMetaStore服务
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# nohup bin/hive --service metastore >/dev/null &
8. 启动HiveServer2服务
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# bin/hive --service hiveserver2 >/dev/null &
9. 启动beeline命令行
[root@node1 ~]# cd /export/server/hive
[root@node1 hive]# bin/beeline -u jdbc:hive2://node1.itcast.cn:10000 -n root -p 123456
服务启动成功后,使用beeline客户端连接,创建数据库和表,导入数据与查询测试。
4.1.3 安装Zookeeper 3.4.6
上传Zookeeper软件至安装目录,解压和配置环境,命令如下所示:
上传软件
[root@node1 ~]# cd /export/software
[root@node1 software]# rz
zookeeper-3.4.6.tar.gz
给以执行权限
[root@node1 software]# chmod u+x zookeeper-3.4.6.tar.gz
解压tar包
[root@node1 software]# tar -zxf zookeeper-3.4.6.tar.gz -C /export/server
创建软链接
[root@node1 ~]# cd /export/server
[root@node1 server]# ln -s zookeeper-3.4.6 zookeeper
配置zookeeper
[root@node1 ~]# cd /export/server/zookeeper/conf
[root@node1 conf]# mv zoo_sample.cfg zoo.cfg
[root@node1 conf]# vim zoo.cfg
修改内容:
dataDir=/export/server/zookeeper/datas
[root@node1 conf]# mkdir -p /export/server/zookeeper/datas
设置环境变量
[root@node1 ~]# vim /etc/profile
添加内容:
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@node1 ~]# source /etc/profile
启动Zookeeper服务,查看状态,命令如下:
启动服务
[root@node1 ~]# cd /export/server/zookeeper/
[root@node1 zookeeper]# bin/zkServer.sh start
JMX enabled by default
Using config: /export/server/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /export/server/zookeeper/bin/../conf/zoo.cfg
Mode: standalone
4.1.4 安装Kafka 2.4.1
上传Kafka软件至安装目录,解压和配置环境,命令如下所示:
上传软件
[root@node1 ~]# cd /export/software
[root@node1 software~]# rz
kafka_2.12-2.4.1.tgz
[root@node1 software]# chmod u+x kafka_2.12-2.4.1.tgz
解压tar包
[root@node1 software]# tar -zxf kafka_2.12-2.4.1.tgz -C /export/server
[root@node1 ~]# cd /export/server
[root@node1 server]# ln -s kafka_2.12-2.4.1 kafka
配置kafka
[root@node1 ~]# cd /export/server/kafka/config
[root@node1 conf]# vim server.properties
修改内容:
listeners=PLAINTEXT://node1.itcast.cn:9092 log.dirs=/export/server/kafka/kafka-logs
zookeeper.connect=node1.itcast.cn:2181/kafka
创建存储目录
[root@node1 ~]# mkdir -p /export/server/kafka/kafka-logs
设置环境变量
[root@node1 ~]# vim /etc/profile
添加内容:
export KAFKA_HOME=/export/server/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@node1 ~]# source /etc/profile
启动Kafka服务,查看状态,命令如下:
启动服务
[root@node1 ~]# cd /export/server/kafka
[root@node1 kafka]# bin/kafka-server-start.sh -daemon config/server.properties
[root@node1 kafka]# jps
2188 QuorumPeerMain
2639 Kafka
4.2 滴滴运营分析
以滴滴为首的互联网叫车平台的出现,在重构线下叫车市场的同时,也为市场其他闲置资源提供了更多盈利的可能性。自与快的合并和并购Uber中国以后,滴滴牢牢占据着国内出行市场第一的位置,在飞速发展的同时也不断向广大用户提供多元化的服务,不断优化社会汽车出行方面的资源配置问题。本次样本为随机抽取2017年5月至10月海口市每天的滴滴订单数据,共14160162条。
海口市是南方的旅游大城,滴滴公司在此的业务发展由来已久,积累了大量的业务订单数据,在此利用其2017年下半年的订单数据,做一些简单的统计分析,来看在那段时间内滴滴公司在海口市的业务发展情况并尝试揭示海口市用户的部分出行特征。
快车出行为滴滴运营过程中的主流订单类型;
滴滴出行订单中,预约用车市占率极低,仍以实时预约为主;
接送机订单仅占总订单量的4%;
绝大多数订单距离集中在0-15公里,价格集中在0-100元;
工作日期间,居民对网约车的出行需求降低,而在周末时较为旺盛;
4.2.1 需求说明
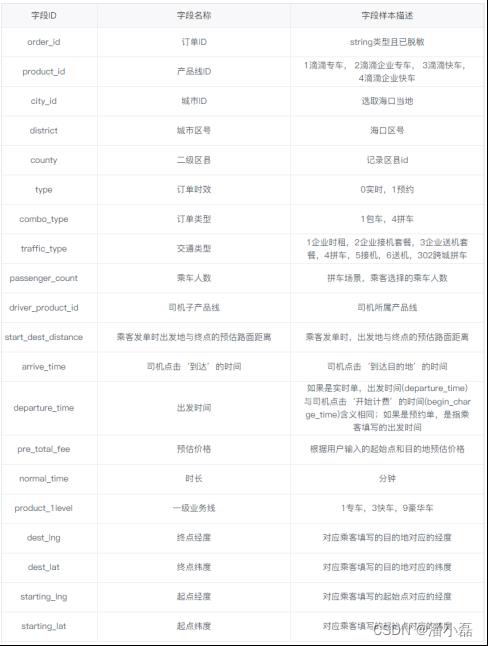
滴滴出行数据为2017年5月1日-10月31日(半年)海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。具体字段含义说明如下所示:
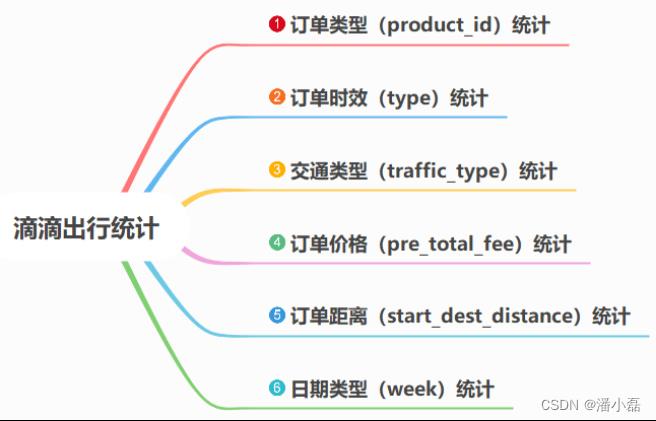
依据海口滴滴出行数据,按照如下需求统计分析:
4.2.2 环境准备
基于前面Maven Project,创建相关目录和包,结构如下图所示:
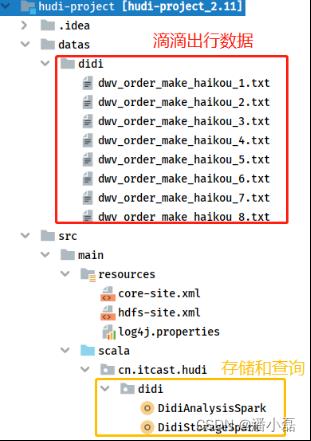
其中滴滴出行数据放在Maven Project工程【datas】本地文件系统目录下。对滴滴出行分析,程序分为两个部分:数据存储Hudi表【DidiStorageSpark】和指标计算统计分析【DidiAnalysisSpark】。
4.2.2.1 工具类SparkUtils
无论数据ETL保存,还是数据加载统计,都需要创建SparkSession实例对象,所以编写工具类SparkUtils,创建方法【createSparkSession】构建实例,代码如下:
package cn.itcast.hudi.didi
import org.apache.spark.sql.SparkSession
/**
* SparkSQL操作数据(加载读取和保存写入)时工具类,比如获取SparkSession实例对象等
*/
object SparkUtils
/**
* 构建SparkSession实例对象,默认情况下本地模式运行
*/
def createSparkSession(clazz: Class[_],
master: String = "local[4]", partitions: Int = 4): SparkSession =
SparkSession.builder()
.appName(clazz.getSimpleName.stripSuffix("$"))
.master(master)
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.shuffle.partitions", partitions)
.getOrCreate()
4.2.2.2 日期转换星期
查询分析指标中,需要将日期时间字段值,转换为星期,方便统计工作日和休息日滴滴出行情况,测试代码如下,传递日期时间字符串,转换为星期。
package cn.itcast.hudi.test
import java.util.Calendar, Date
import org.apache.commons.lang3.time.FastDateFormat
/**
* 将日期转换星期,例如输入:2021-06-24 -> 星期四
* https://www.cnblogs.com/syfw/p/14370793.html
*/
object DayWeekTest
def main(args: Array[String]): Unit =
val dateStr: String = "2021-06-24"
val format: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd")
val calendar: Calendar = Calendar.getInstance()
val date: Date = format.parse(dateStr)
calendar.setTime(date)
val dayWeek: String = calendar.get(Calendar.DAY_OF_WEEK) match
case 1 => "星期日"
case 2 => "星期一"
case 3 => "星期二"
case 4 => "星期三"
case 5 => "星期四"
case 6 => "星期五"
case 7 => "星期六"
println(dayWeek)
解析编写代码,本地文件系统加载滴滴出行数据,存储至Hudi表,最后按照指标统计分析。
4.2.3 数据ETL保存
从本地文件系统LocalFS加载海口市滴滴出行数据,进行相应ETL转换,最终存储Hudi表。
4.2.3.1 开发步骤
编写SparkSQL程序,实现数据ETL转换保存,分为如下5步:
step1. 构建SparkSession实例对象(集成Hudi和HDFS)
step2. 加载本地CSV文件格式滴滴出行数据
step3. 滴滴出行数据ETL处理
stpe4. 保存转换后数据至Hudi表
step5. 应用结束关闭资源
数据ETL转换保存程序:DidiStorageSpark,其中MAIN方法代码如下:
package cn.itcast.hudi.didi
import org.apache.spark.sql.DataFrame, SaveMode, SparkSession
import org.apache.spark.sql.functions._
/**
- 滴滴海口出行运营数据分析,使用SparkSQL操作数据,先读取CSV文件,保存至Hudi表。
- -1. 数据集说明
-
2017年5月1日-10月31日海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。 -
数据存储为CSV格式,首行为列名称 - -2. 开发主要步骤
-
step1. 构建SparkSession实例对象(集成Hudi和HDFS) -
step2. 加载本地CSV文件格式滴滴出行数据 -
step3. 滴滴出行数据ETL处理 -
stpe4. 保存转换后数据至Hudi表 -
step5. 应用结束关闭资源
*/
object DidiStorageSpark
// 滴滴数据路径
val datasPath: String = "datas/didi/dwv_order_make_haikou_2.txt"
// Hudi中表的属性
val hudiTableName: String = "tbl_didi_haikou"
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit =
// step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass)
import spark.implicits._
// step2. 加载本地CSV文件格式滴滴出行数据
val didiDF: DataFrame = readCsvFile(spark, datasPath)
// didiDF.printSchema()
// didiDF.show(10, truncate = false)
// step3. 滴滴出行数据ETL处理并保存至Hudi表
val etlDF: DataFrame = process(didiDF)
//etlDF.printSchema()
//etlDF.show(10, truncate = false)
// stpe4. 保存转换后数据至Hudi表
saveToHudi(etlDF, hudiTableName, hudiTablePath)
// stpe5. 应用结束,关闭资源
spark.stop()
分别实现MAIN中三个方法:加载csv数据、数据etl转换和保存数据。
4.2.3.2 加载CSV数据
编写方法,封装SparkSQL加载CSV格式滴滴出行数据,具体代码如下:
/**
* 读取CSV格式文本文件数据,封装到DataFrame数据集
*/
def readCsvFile(spark: SparkSession, path: String): DataFrame =
spark.read
// 设置分隔符为逗号
.option("sep", "\\\\t")
// 文件首行为列名称
.option("header", "true")
// 依据数值自动推断数据类型
.option("inferSchema", "true")
// 指定文件路径
.csv(path)
4.2.3.3 数据ETL转换
编写方法,对滴滴出行数据ETL转换,添加字段【ts】和【partitionpath】,方便保存数据至Hudi表时,指定字段名称。具体代码如下:
/**
* 对滴滴出行海口数据进行ETL转换操作:指定ts和partitionpath 列
*/
def process(dataframe: DataFrame): DataFrame =
dataframe
// 添加分区列:三级分区 -> yyyy/MM/dd
.withColumn(
"partitionpath", // 列名称
concat_ws("/", col("year"), col("month"), col("day")) //
)
// 删除列:year, month, day
.drop("year", "month", "day")
// 添加timestamp列,作为Hudi表记录数据与合并时字段,使用发车时间
.withColumn(
"ts",
unix_timestamp(col("departure_time"), "yyyy-MM-dd HH:mm:ss")
)
4.2.3.4 保存数据至Hudi
编写方法,将ETL转换后数据,保存到Hudi表中,采用COW模式,具体代码如下:
/**
* 将数据集DataFrame保存值Hudi表中,表的类型:COW
*/
def saveToHudi(dataframe: DataFrame, table: String, path: String): Unit =
// 导入包
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
// 保存数据
dataframe.write
.mode(SaveMode.Overwrite)
.format("hudi") // 指定数据源为Hudi
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性设置
.option(RECORDKEY_FIELD_OPT_KEY, "order_id")
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
// 表的名称和路径
.option(TABLE_NAME, table)
.save(path)
4.2.3.5 Hudi 表存储结构
运行Spark程序,读取CSV格式数据,ETL转换后,保存至Hudi表,查看HDFS目录结构如下:
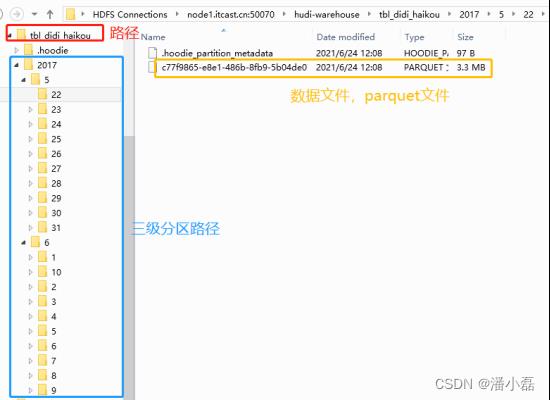
4.2.4 指标查询分析
按照查询分析指标,从Hudi表加载数据,进行分组聚合统计,分析结果,给出结论。
4.2.4.1 开发步骤
创建对象DidiAnalysisSpark,编写MAIN方法,先从Hudi表加载数据,再依据指标分组聚合。
package cn.itcast.hudi.didi
import java.util.Calendar, Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.DataFrame, SparkSession
import org.apache.spark.sql.functions._
/**
* 滴滴海口出行运营数据分析,使用SparkSQL操作数据,从加载Hudi表数据,按照业务需求统计。
* -1. 数据集说明
* 海口市每天的订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。
* 数据存储为CSV格式,首行为列名称
* -2. 开发主要步骤
* step1. 构建SparkSession实例对象(集成Hudi和HDFS)
* step2. 依据指定字段从Hudi表中加载数据
* step3. 按照业务指标进行数据统计分析
* step4. 应用结束关闭资源
*/
object DidiAnalysisSpark
// Hudi中表的属性
val hudiTablePath: String = "/hudi-warehouse/tbl_didi_haikou"
def main(args: Array[String]): Unit =
// step1. 构建SparkSession实例对象(集成Hudi和HDFS)
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass, partitions = 8)
import spark.implicits._
// step2. 依据指定字段从Hudi表中加载数据
val hudiDF: DataFrame = readFromHudi(spark, hudiTablePath)
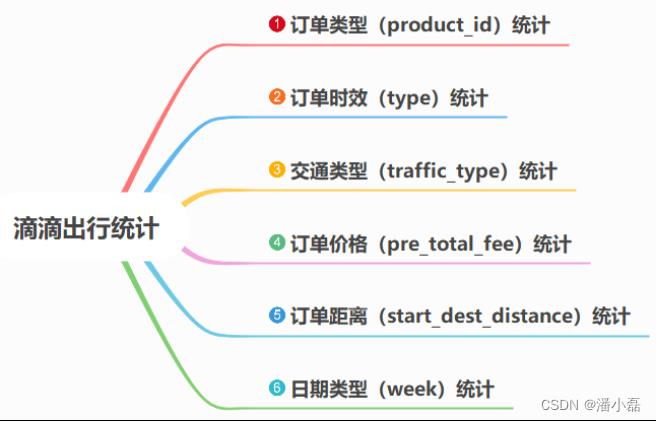
// step3. 按照业务指标进行数据统计分析
// 指标1:订单类型统计
// reportProduct(hudiDF)
// 指标2:订单时效统计
// reportType(hudiDF)
// 指标3:交通类型统计
//reportTraffic(hudiDF)
// 指标4:订单价格统计
//reportPrice(hudiDF)
// 指标5:订单距离统计
//reportDistance(hudiDF)
// 指标6:日期类型:星期,进行统计
//reportWeek(hudiDF)
// step4. 应用结束关闭资源
spark.stop()
其
以上是关于数据湖技术之Hudi 集成 Spark的主要内容,如果未能解决你的问题,请参考以下文章