SIMD 架构与 SVE2 的演进
Posted 代码改变世界ctw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SIMD 架构与 SVE2 的演进相关的知识,希望对你有一定的参考价值。
快速链接:
.
👉👉👉 个人博客笔记导读目录(全部) 👈👈👈

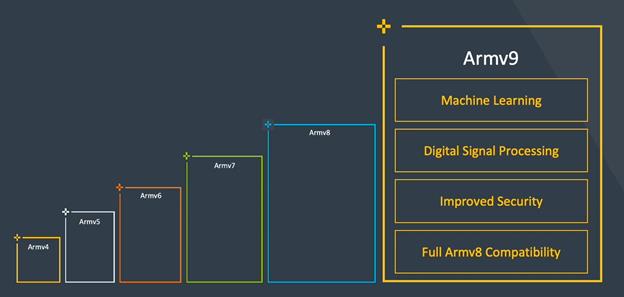
2021 年 3 月,Arm推出了具有日益强大的安全性和人工智能 (AI) 能力的下一代 Armv9 架构。紧随其后的是 5 月推出的全新 Arm Total Compute 解决方案,其中包括首款 Armv9 CPU。开发人员将立即看到的最大新功能是矢量处理的增强。它将在更广泛的应用中增强机器学习 (ML) 和数字信号处理 (DSP) 能力。在这篇博文中,我们将分享第二版可扩展矢量扩展(SVE2) 的优势和好处。
什么是 SVE 和 SVE2?
利用并行执行指令(称为 SIMD(单指令多数据)指令)可以加快处理大量数据的应用程序的速度。SVE最初是作为 Armv8.2 架构的可选扩展引入的,遵循现有的Neon 技术。SVE2作为 SVE 的功能扩展,为 Armv9 CPU 引入。SVE2和SVE的主要区别在于指令集的功能覆盖。SVE 专为高性能计算 (HPC) 和 ML 应用程序而设计。SVE2 扩展了 SVE 指令集,以支持 HPC 和 ML 之外的数据处理领域,例如计算机视觉、多媒体、游戏、LTE 基带处理和通用软件。我们将 SVE 和 SVE2 视为我们 SIMD 架构的演进,带来了 Neon 已经提供的功能之外的许多有用功能。
为什么使用 SVE2?
顾名思义,SVE2 设计理念使开发人员能够编写和构建软件一次,然后在具有各种 SVE2 矢量长度实现的不同 AArch64 硬件上运行相同的二进制文件。由于某些笔记本电脑和移动设备的向量长度不同,SVE2 可以通过共享代码来降低跨平台支持的成本。消除重新构建二进制文件的要求可以更轻松地移植软件。二进制文件的可扩展性和可移植性意味着开发人员不必了解和关心目标设备的向量长度。当软件跨平台共享或长时间使用时,SVE2 的这一特殊优势更为有效。
除此之外,SVE2 生成的汇编代码比 Neon 更简洁、更容易理解。这显着降低了生成代码的复杂性,使其更易于开发和维护。这提供了整体更好的开发人员体验。
如何使用 SVE2
那么,您如何才能充分利用 SVE2?有几种方法可以编写或生成 SVE2 代码:使用 SVE2 的库
(1)使用 SVE2 的库
已经有可用的 SVE2 高度优化的库,例如Arm Compute Library。Arm Compute Library 提供优于其他开源替代方案的卓越性能,并立即支持 SVE2。
(2)支持 SVE2 的编译器
C/C++ 编译器从 C/C++ 循环生成 SVE2 代码。要生成 SVE2 代码,请为 SVE2 功能选择适当的编译器选项。例如,对于 armclang,启用 SVE2 优化的一个选项是 March=armv8-a+sve2。
(3)C/C++ 中的 SVE2 内在函数
SVE2 内在函数是编译器用适当的 SVE2 指令替换的函数调用。SVE2 内在函数使您可以直接从 C/C++ 代码访问大部分 SVE2 指令集。您可以在此处通过内部函数搜索引擎搜索 SVE2 内部函数 。
#include <arm_sve.h>
void saxpy(const float x[], float y[], float a, int n)
for (int i = 0; i < n; i += svcntw())
svbool_t pg = svwhilelt_b32(i, n);
svfloat32_t vec_x = svld1(pg, &x[i]);
svfloat32_t vec_y = svld1(pg, &y[i]);
vy = svmla_x(pg, vy, vx, a);
svst1(pg, &y[i], vy);
(4)SVE2 组装
您可以使用 SVE2 指令编写汇编文件,也可以根据需要使用内联汇编。
ld1w z0.s , p0/z, [x1, x8, lsl #2]
ld1w z1.s , p0/z, [x2, x8, lsl #2]
sub z0.s, z0.s, z1.s
st1w z0.s , p0, [x0, x8, lsl #2]
incw x8
whilelo p0.s, x8, x9
b.mi .LBB0_1
如果有支持 SVE2 的库可以提供您需要的功能,那么使用它们可能是最简单的选择。汇编通常可以为某些应用程序提供令人印象深刻的性能,但由于寄存器管理和可读性,它更难以编写和维护。另一种替代方法是使用内在函数,它生成适当的 SVE2 指令并允许从 C/C++ 代码调用函数,从而提高可读性。除了库和内在函数之外,SVE2 还允许您让编译器自动矢量化代码,从而在保持高性能的同时提高易用性。有关如何为 SVE2 编程的更多信息,请访问此 Arm 开发人员页面。
SVE2 可能有效的示例
SVE2 不仅使向量长度可扩展,而且还具有许多其他特性。在本节中,我们将向您展示一些使用 SVE2 的好处的示例以及一些已添加的新说明。
收集负载和分散存储
非线性数据访问模式在各种应用程序中都很常见。许多现有的 SIMD 算法花费大量时间将数据结构重新排列为可矢量化的形式。SVE2 的收集加载和分散存储允许在非连续内存位置和 SVE2 寄存器之间直接传输数据。
FFT(快速傅立叶变换)是可以从中受益的一个过程示例。此操作在图像压缩和无线通信等许多领域都很有用。这种分散存储功能非常适合FFT 中使用的蝶形运算寻址。
计算能力更强的指令
SVE2 指令集实现复值整数运算。它们对于具有复杂计算的操作特别有用,例如用于表示游戏中对象的方向和旋转的四元数。例如,SVE2 汇编中带符号的 16 位复数向量的乘法可以比 Neon 汇编中快 62%。下面是向量乘法的 C 代码版本。类似地,发现使用复数计算 8x8 逆矩阵的速度提高了约 13%。
struct cplx_int16_t
int16_t re;
int16_t im;
;
int16_t Sat(int32_t a)
int16_t b = (int16_t) a ;
if (a > MAX_INT16) b = 0x7FFF; // MAX_INT16 = 0x00007FFF
if (a < MIN_INT16) b = 0x8000; // MIN_INT16 = 0xFFFF8000
return b ;
void vecmul(int64_t n, cplx_int16_t * a, cplx_int16_t * b, cplx_int16_t * c)
for (int64_t i=0; i<n; i++)
c[i].re = Sat((((int32_t)(a[i].re * b[i].re) +
(int32_t)0x4000)>>15) -
(((int32_t)(a[i].im * b[i].im) +
(int32_t)0x4000)>>15));
c[i].im = Sat((((int32_t)(a[i].re * b[i].im) +
(int32_t)0x4000)>>15) +
适用于各种应用的全新说明
SVE2 中还引入了一些新指令,例如按位置换、字符串处理和密码学。其中,我想重点介绍一下直方图加速说明。图像直方图广泛应用于计算机视觉和图像处理领域,例如,通过使用 OpenCV 等库。它可用于图像阈值处理和图像质量改进等技术。现代相机和智能手机利用此类信息来计算曝光控制和白平衡,以提供更好的图像质量。
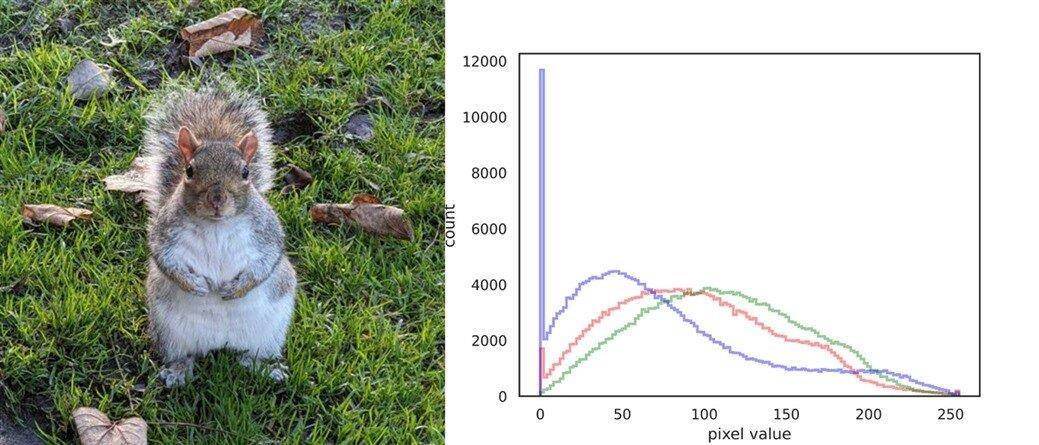
SVE2 中新引入的直方图加速指令提供了两个特定元素匹配的向量寄存器的计数。使用这些指令,可以用更少的指令和比以前更快的速度计算直方图。例如,直方图计算通常如下编码。在我检查 SVE2 功能的实验中,编译器还不够成熟,无法识别循环模式并获取最新指令。因此,我们准备了带有专门指令的汇编代码,以允许对该循环进行矢量化。结果是使用 SVE2 优化的程序集比编译的 C 代码快约 29%。Neon 不提供矢量化这种过程的方法。本节用于衡量性能的汇编代码,以及编译器版本和选项.
void calc_histogram(unsigned int * histogram, uint8_t * records, unsigned int nb_records)
for (unsigned int i = 0; i < nb_records; i++)
histogram[records[i]] += 1;
结论
SVE2 是用于计算机视觉、游戏及其他领域的出色指令集。还有许多其他功能我们没有在这里提到,所以如果您想了解更多关于 SVE2 的信息,请查看此页面。此外,可以在此处找到有关 SVE2 编程示例的更多详细信息。未来,将有更多使用 SVE2 的有效用例和应用示例,而不仅仅是突出原始操作的差异。此外,随着时间的推移,编译器优化应该会变得更好。
第一个支持 SVE2 的硬件版本将于 2022 年初推出。我们非常高兴 SVE2 将提供更好的程序员生产力,并在更广泛的设备和应用程序中实现增强的 ML 和 DSP 功能。我们非常期待 SVE2 的更广泛部署。
参考:
Evolution of SIMD architecture with SVE2
数据仓库的分层架构与演进
简介:分层架构很容易在各种书籍和文档中去理解,但是把建模方法和分层架构放在一起就会出现很多困惑了。接下来,我会从数据研发与建模的角度,演进一下分层架构的设计原因与层次的意义。
分层架构很容易在各种书籍和文档中去理解,但是把建模方法和分层架构放在一起就会出现很多困惑了。
一、分层的演进
之所以会有分层架构,最主要的原因还是要把复杂冗长的数据吹流程分拆成一些有明确目的意义的层次,这样复杂就被拆解为一些相对简单小的模块。那么分层架构中各层都是怎么产生的呢,我们可以简化看一下。
第一个数据加工任务

我要进行第一个数据加工任务,一切平台层次都没有,我只有一个MaxCompute。我该怎么做呢?
第一步,我需要自己做一下数据集成,把源系统的数据集成到MaxCompute。
第二步,我需要把增量合并全量生成ODS层,这样我就得到了与业务系统一样的表结构和全量的数据。
第三步,因为我对业务系统的数据表关联关系有了解,所以,我可以根据业务需求使用ODS的全量表做表关联,加工出我想要的数据结果。
第一个数据应用

如果我不只是做一个业务需求,我是有很多业务需求,这样我就形成了我的第一个数据应用。所以,我会集成更多的数据,做更多的数据合并全量的工作,并且我的全量ODS的表可以在多个业务场景复用。
但是试想一下,如果不是一个人在开发,那么团队内部是不是要协调一下,对工作进行一下分工。做集成的和做合并的是不是可以分给一部分人,然后把后面业务需求开发再分给另外一部分人。这样就避免了重复工作,和便于工作的专业性。
于是就可以拆分出来上图中的第一个方块“集成”(STG)和第二个方块 “全量”(ODS),这部分是纯技术性的工作,还没有涉及到业务需求。对于实际业务需求计算部分,就是我们的应用层集市层(ADM)。
第二个数据应用
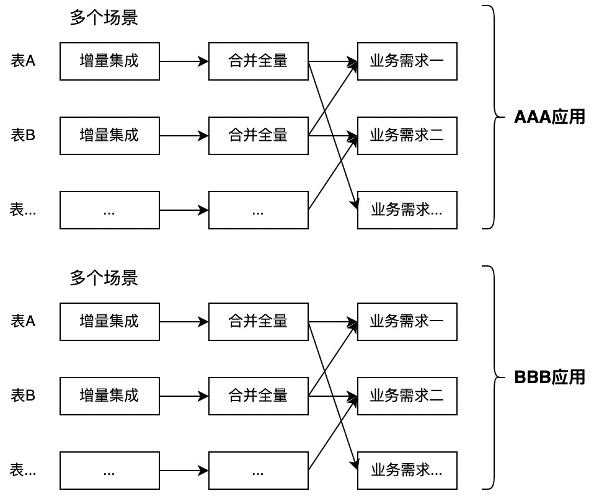
随着第二个数据应用的出现,各自做集成合并已经是非常不适合的做法了,于是就有个独立的STG和ODS层。
很多时候,做完ODS就可以做业务数据加工了。并且这种情况从数据处理技术发展之初,数据仓库概念提出之前就存在了,现在依然很普遍。集市各自依赖ODS会遇到的多源加工指标不一致的问题逐渐遭人诟病,而造成指标不一致的主要原因重复加工。不同的人对同一业务的理解都很难保障一致性,更何况不同的部门的应用。对于这个问题,可以在各个大型企业早期的数据场景都会遇到,所以,在阿里对外宣传大数据平台的时候也会提到这个早期各个业务部门数据口径不一致的问题。这个问题在ODS的层面无法解决,必须要独立出一个团队来做公共的这部分数据,让各个应用集市去做各自独立的部分,这也是公共层(CDM)的由来。
二、分层与建模
通过上面的内容,我们终于知道了数据加工过程为什么要分层。那么数据建模应该如何来做呢?因为在数据仓库领域,在数据建模一直有两种争锋相对的观点,就是范式建模还是维度建模。我们在目前大数据这个场景,一般就只提一种方法了,就是维度建模。
维度建模的经典方法与教程中没有中间层的概念,也没有主题域划分的概念。维度建模一般用在数据集市场景,也就是ODS+ADM场景,各个业务通过一致性维度实现企业级的数据一致性。在传统的被IOE统治的时代,Teradata、IBM、Oracle都有基于关系型数据库(包括MPP数据库),在某些重要的行业,例如金融这些企业都会构建大型的企业级的维度模型来给集市提供公共数据服务,这就是公共层。因为范式模型导致实体都比较窄,跟实际的分析型业务需求(维度模型)差异太大,所以需要做一层中间层(相对范式模型更宽的表,这也是宽表说法的由来)来做为应用集市层共性加工工作的层次,这就是现在我们在架构中提到的ODS+CDM+ADM的架构。
那么问题就在这里出来了,我们全部使用维度模型建模,如何使用范式模型的架构与概念。这也是我们在分层架构设计中目前最难以讲清楚的问题,也是我们实际在项目里面做的很别扭的原因:缺乏理论与实践支撑。
维度模型的构建是以实际业务需求为导向,模型是不断的需求累积出来的,适应快速的业务变化。而且维度模型不是一个建议一开始就进行企业级的思考设计的模型设计方法,是由局部业务逐渐扩张构建的。所以,我认为维度模型的架构不太适宜一开始做太重的太业务化公共层。反而应该强调在公共层构建共性加工的集合,去协调同步多个应用集市的计算,从而实现全局性的一致性维度和一致性事实。因为维度建模的建设也不是简单一蹴而就的,也是需要多次和多种数据处理以后才能最终变成符合业务需求的结果。多个不同的应用集市有大量的共性的加工需求,这些需求就是我们公共层的收集的建模需求。把这些共性需求在公共层使用维度建模的方法实现才是建设公共层的合理方法,而不是越俎代庖的去建设面向具体某个业务场景的指标标签(就是虽然实际是做了指标和标签的计算,但是我只是一个中间加工过程)。
接下来,我们继续利用上面讲解分层的方法来讲解公共层与集市层的关系。
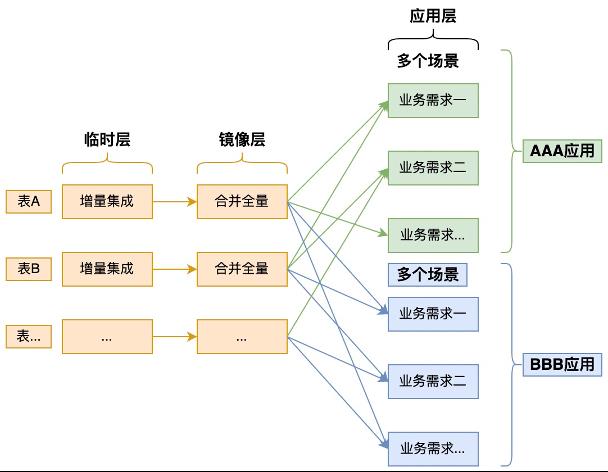
第一个应用
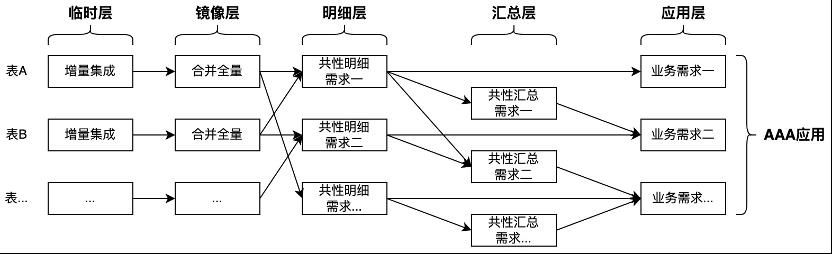
随着第一个应用出现,就可以基于部分的需求构建第一个公共层了。共性加工需求在一个中型的应用集市就很明显了。一、数据清洗。一个表的数据清洗后,会有多个数据加工任务都会使用这个清洗后的表,这就是最简单的共性加工的理解。二、多表关联。多张表的关联也是多个数据加工任务中可以提炼出来的,一次把需要关联使用的字段都关联合并到一张新表,后续的任务就可以直接用这个新表。三、共性汇总。对于数据从明细到汇总的group by,统一根据多个常用条件进行汇总,生成一张新表,后续的任务就可以直接用这个新表。一致性维度是维度建模中最关键的部分,直接影响到各个应用集市的数据标准与一致性问题,是公共层最重要的工作。
第二个应用
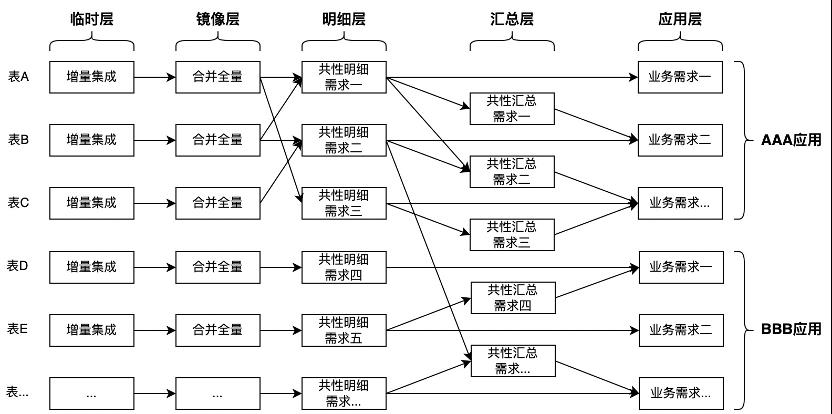
随着应用的增加,需求也在不断的扩充,临时层和镜像层集成的表更多了。在公共层的明细和汇总也出现了多个应用集市都在共用的数据需求,会扩展补充到公共层。并且随着时间的变化,公共层的逻辑的正确性和公共性也需要在多个应用进入后整体考虑。
公共层与应用关系
通过上面两步演进,我们已经看到了公共层与应用层的关系了,是一体的。并不是各做各的,而是一件事情从专业化分工上做了切分。公共层与应用层只有一个共同目标,就是为满足业务需求而做数据加工。不同侧重的是应用层只需要关注自己部门的最终业务目标,公共层则需要从企业级的全局一致性、资源经济性上全盘考虑。
公共层与应用层的关系就是后勤部队与前方作战部队的关系,一个负责基础的材料准备工作,一个负责利用这些输出投入到真实战场。公共层是高效的数据复用和综合更低的资源代价,应用层则就是实际的业务需求。所以,最终的业务模型在应用层才有完整的针对性业务场景,在公共层是模型是多种场景业务需求的一个复合,代表了平台最基础和最通用的模型。

从层次上来说,公共层向下是一块整体,负责跟上游多个交易型业务系统对接,对应用集市屏蔽了上游变化带来的影响,使得应用层能只关注于利用公共层的模型解决自己的业务需求。
本文为阿里云原创内容,未经允许不得转载。
以上是关于SIMD 架构与 SVE2 的演进的主要内容,如果未能解决你的问题,请参考以下文章