|云原生时代下微服务架构进阶之路 - Snap-E
Posted VMware中国研发中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了|云原生时代下微服务架构进阶之路 - Snap-E相关的知识,希望对你有一定的参考价值。
通过本篇文章您可以了解到以下内容:
- 回顾
- Snap-E 简介
- Snap-E 具体实施流程
- Snap-E 的具体例子
- 总结
回顾
首先让我们做一个简单的回顾:
在上一篇文章中我们谈到了 Boris,我们了解到,Boris 是一个动手实践的过程,这个过程需要我们的领域专家以及技术人员一同参与,使用简单的工具(例如贴纸、白板、笔等)
通过对微服务彼此以及微服务与外部系统交互的梳理,我们可以很清晰的了解到每个微服务彼此是怎样交互的,以及交互方式。
至此,进一步思考,我们可能会面临以下问题:
- 怎么展现每个微服务的具体信息呢?(例如有多少个 APIs,数据实体又是怎样的?)
- 针对于第一点,这些信息又是怎么获取的呢?
那么带着这些问题让我们来开始今天的主题 Snap-E。
Snap-E 简介
Snap-E 是英文的缩写,全称为: Snap Not Analysis Paralysis - Enhanced.
简单的理解,我们可以通过 Snap-E 清楚的了解某个具体微服务内部结构信息,比如这个微服务内部包含多少个 APIs、数据实体,是否存在 UI 界面,是否与外部系统交互等。

Snap-E 具体实施流程
WHEN
什么时候才会进入 Snap-E 阶段?
通过 Boris 我们将微服务之间的交互进行建模和梳理。在 Boris 过程中,我们可以同时进行 Snap-E,从而实时的记录下微服务的元素。
WHY
为什么要进行 Snap-E?
Boris 只是从微服务这个层面进行系统梳理分析,那么针对于每一个微服务内部的构造我们需要进行剖析,通过 Snap-E 可以使我们很清晰的看到每一个微服务内部的构造。
WHAT
想要完成 Snap-E,我们需要进行哪些准备?

- 在进行 Boris 的同时,SNAP-E 模版被实时的进行填写。
- 会议室(较大的开放空间),用于技术人员、领域专家等成员之间的充分讨论。
- 便签纸(各种颜色,用于代表不同意义,例如 API、DATA 等)。
- 笔 (最好每个人一支),用于在便签纸上书写。
- 白板 用于贴便签纸。
整个 Snap-E 阶段就是根据 Boris 结果进行对每一个微服务分析,在 Snap-E 模版中包含了若干元素,那么这些元素又代表了什么意思呢?接下会和大家详细说明下, 如下图所示:

ServiceA
对应的是 Boris 中微服务的名字,此例子可以理解为,有一个 serviceA 的微服务,通常针对每一个微服务我们使用一页 Snap-E 进行表示。
API
根据 Boris 中的约定,例如使用 REST Call 方式进行交互,此时 APIs 代表的是该服务对外暴露出的服务接口。
DATA
顾名思义,代表的是该服务所涉及到的数据实体 Entity。
PUB/SUB
顾名思义,某些微服务可能会存在使用异步消息的情况,这里面分别指的是接收亦或发送消息。
EXT
代表该微服务是否存在与外围系统联系,这里我们可以标注外围系统的名字。
STORIES
来源于 Boris 中的命令(这个命令可以理解为 GET、UPDATE、DELETE 等操作), 这里将命令进行简单的描述封装。
UI
代表该服务是否存在 UI 界面。
RISK
代表可以遇见的一些风险。
至此,我们已经知晓了完成 Snap-E 需要的准备,以及 Snap-E 模版中元素具体的含义,那么接下来我需要知道的是模版元素的来源,答案就是 Boris。
换而言之,在进行 Boris 过程中,会对微服务之间的调用关系,命令越来越清晰,在这个过程中,我们可以实时的快速记录所需要的元素并将这些元素填充到 Snap-E 的模版当中。如下图所示:

Snap-E 的具体例子
通过上一章节的介绍,相信大家对 Snap-E 中的概念,以及实施流程有了较为清晰的理解。接下来我们以用户注册为例子,再次来回顾下整个流程。此处会结合之前文章 Event Storming 以及 Boris 中提及的部分内容。
第一步,我们需要进行 Event Storming,也就是对于有关用户的 Event 进行聚合,并形成了对应的微服务,我们称之为 USER。另外将所有关于订单的 Event 进行聚合,形成另一个微服务 ORDER。
第二步,我们利用 Boris 对 USER 和 ORDER 这两个微服务之间的调用关系进行分析,建模。同时这里面会涉及到外部系统。结合业务流程,比如 USER 可能会发起一些验证消息,用于客户注册时的验证、订单服务获取用户信息等。从而进一步我们会逐步发现若干个命令(此处的命令可以理解为服务之间的 GET、UPDATE、DELETE 等操作)。

第三步,Snap-E 模版的填写,以 USER 微服务为例,此时我们根据上一步骤 Boris 产出的结果作为输入,我们知道的是 ORDER 微服务会向 USER 微服务发起一个 REST Call,所以此时 USER 微服务应该对外提供一个服务,也就是暴露出一个 API,另外,ORDER 需要从 USER 中获取用户信息,那么 USER 服务中应该保存一个关于用户数据的实体。映射到 Snap-E 中就是 API 以及 DATA 元素。
第四步,另一方面,我们可以看到,USER 服务在完成用户信息注册的业务流程中,需要和外部系统进行交互,这里面指的分别是身份校验系统以及短信通知系统。所以映射到 Snap-E 中就是 Ext 元素。
第五步,结合第四步,我们知道 USER 服务与两个外部系统进行了交互,而且与短信通知服务采用的是异步操作,即可以理解为 USER 向外部系统发送了一个注册成功的短信通知消息,与身份校验服务采用的是同步调用,即获取身份信息校验结果。而对于异步发送消息的操作映射到 Snap-E 中就是 PUB 元素。
第六步, 在上面 Boris 中存在三个命令,分别是获取用户信息、身份信息获取验证结果、注册成功发送短信。我们可以将这三个命令进行相对较为详细的描述,例如,针对于获取用户信息,我们可以描述成,USER 服务接收到了一个获取 User 信息的请求,来自于 ORDER 服务。而对于这种命令的描述封装,就是 STORIES 元素。
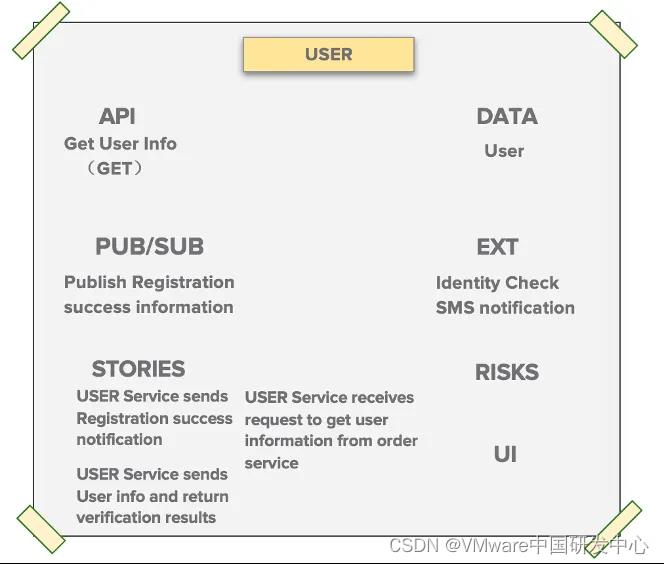
以此类推我们用这种方式,就可以完成整个系统微服务的 Snap-E 建模。
总结
回顾全篇内容,整体包括以下内容:
- 首先在开篇我们了解到了 Snap-E 的含义。
- 其次介绍了 Snap-E 的整个实施流程,在实施流程的章节中,阐述了为什么要进行 Snap-E、Snap-E 的准备工作等内容,同时宏观的阐述了整个 Snap-E 的流程。
- 最后结合例子进行再次说明 Snap-E整个实施过程。
至此微服务拆分的三把利器 Event Storming、Boris、Snap-E 已经全部向大家介绍完了,我们可以看出,Event Storming 是将现有的业务流程进行梳理,也可以说它的输入就是业务流程,输出是微服务;Boris 是将微服务之间的交互进行建模,形成全局的拓扑图,这里的输入是 Event Storming 的输出即微服务,而 Boris 的输出是全局系统交互方式,微服务彼此交互(这里的交互指的是 Boris 中的 command)。Snap-E 则更进一步,是将每一个微服务具体化(包括哪些 API、DATA、UI 等),它的输入正是 Boris 的输出。
虽然我们使用了这三把拆分的利器完成微服务的拆分,但是接下来我们需要的是有一个强有力的、高效并且开箱即用的技术框架支持我们开发落地工作,作为 JAVA 世界最受欢迎的 Spring 这时候登场了,在下期的文章中我会继续和大家就 Spring 进行交流分享,敬请期待!
参考链接:https://tanzu.vmware.com/developer/practices/swift-method//swift-method/
内容来源|公众号:VMwareTanzu 云原生
金融云原生漫谈|云原生时代:从传统运维到智能运维的进阶之路
在金融行业数字化转型的驱动下,国有银行、股份制银行和各级商业银行也纷纷步入容器化的进程。
如果以容器云上生产为目标,那么整个容器云平台的设计、建设和优化对于银行来说是一个巨大的挑战。如何更好地利用云原生技术,帮助银行实现敏捷、轻量、快速、高效地进行开发、测试、交付和运维一体化,从而重构业务,推动金融科技的发展,是个长期课题。
本期金融云原生漫谈,将和您共同探索,云原生时代智能运维的进阶之路。

随着金融业务的快速发展,支撑业务的IT基础设施的变化节奏也大大加快。
金融IT运维团队对IT基础设施运维的任务,比以往任何时候都要更加艰巨。核心是保障生产安全运营,并提高软硬件环境的交付质量。然而在今天的金融IT 3.0时代,IT需求变得越来越强,变化越来越快,服务器等数量爆增,管理起来日益繁杂。同时,运维管理规模的不断扩大,运维人员的不断扩充,使得日常运维工作面临着双重的压力与风险。
以容器、微服务为代表的云原生技术催生了新一代云原生运维技术体系,可以帮助金融企业最大化释放运维效能。基于多年来的实践经验,我们对于来自金融行业一线的运维问题进行了回答:
- 相较于虚拟机,容器的运维和监控有什么优劣势?
- 为什么说基于K8s的容器是实现智能运维的必然选择?
- 高并发场景下,如何实现容器的自动扩缩容?
- 如何快、准、狠地排查容器中的应用问题?
- 容器的智能运维有无成功实践案例?
希望本篇文章能为您提供借鉴。
相较于虚拟机,容器的运维和监控有什么优劣势?
从运维的角度来看,容器的轻量化使得运维更加灵活高效,更方便应用自动化来提升运维效率。
相较于传统运维,容器可以实现:
- 更快速部署和交付:对于应用系统的部署可以极大地节省时间成本和人力成本;
- 更标准化交付物:容器的标准交付物为镜像,包含应用程序和依赖环境,一次构建多次使用,大大简化了应用交付模式;
- 更高效的资源利用:容器不需要虚拟机额外的管理程序,依赖内核运行,在运维资源开销上要低的多;
- 更加敏捷的迁移和扩展:容器可以跨操作系统、跨环境运行,实现无缝迁移的效果,以及高并发场景下的自动扩缩容。
从监控的角度来看,轻量化的容器也带来了监控的复杂度,特别是大量容器运行的平台如何排错和根因分析。
由于容器是黑盒运行,在运维中容器问题的诊断比较复杂;由于容器运行的密度比较大,需要面对的运维实体和对象数量会很庞大;由于容器的自身特性,容器的创建、销毁等生命周期过程,各类运维数据的采集是个挑战。另外容器启动后,监控系统怎么发现,同时需要对其做哪些数据采集,这些问题都是容器监控自动化过程需要解决的。
在监控这个领域,除了目前比较热门的纯软件层全链路监控以及混沌工程,建议应该结合硬件的监控和检测实现端到端的监控和测试,以提升平台的稳定性和效能。
为什么说基于K8s的容器是实现智能运维的必然选择?
随着容器的不断成熟,越来越多的金融企业选择利用容器来搭建业务系统。可是,大家在实际操作中发现,像 Docker 之类的容器引擎,更适合管理少量容器,而如今的云原生应用、机器学习任务或者大数据分析业务,动辄就要使用成百上千的容器, K8s就自然而然地成为了实现智能运维的必然选择。
首先是 K8s 采用声明式 API,让开发者可以专注于应用自身,而非系统执行细节。比如,在 Kubernetes 之上,提供了 Deployment、StatefulSet、Job 等不同类型应用负载的抽象。声明式 API 是云原生重要的设计理念,有助于将系统复杂性下沉,交给基础设施进行实现和持续优化。
此外,K8s 提供了可扩展性架构,所有 K8s 组件都是基于一致的、开放的 API 进行实现和交互。开发者也可通过 CRD(Custom Resource Definition)/ Operator等方式提供领域相关的扩展,极大拓宽了 K8s 的应用场景。
最后,K8s 提供平台无关的技术抽象:如 CNI 网络插件, CSI 存储插件等等,可以对上层业务应用屏蔽基础设施差异。
高并发场景下如何实现容器的自动扩缩容?
首先,建议先做好容器云平台配套的监控、日志的建设,再去建设自动扩缩容的自动化能力。
一般可以在高并发场景下使用 K8s 的Horizontal Pod Autoscaling(以下简称HPA), 通过HPA功能,可以实现容器的自动弹性扩缩容功能。对于K8s集群来说,在高并发场景下HPA可以实现多种纬度的自动化功能,例如当工作负载上升的时候,可以创建新的实例副本来保证业务系统稳定运行,当工作负载并发下降的时候,可以销毁副本实例来减少资源消耗。当前的自动伸缩的指标包括:CPU,内存,并发数,网络传输等。
此外,从整体实施的角度来看,建议聚焦于场景驱动,先从某个业务应用开始逐步试点和推广,运维团队逐步积累到各个场景下业务应用的扩缩容的触发指标、阀值和评估扩缩容成效,最终实现全面的自动扩缩容。
如何快、准、狠地排查容器中的应用问题?
建议可以从以下三个层面来排查容器中的应用问题:
- 业务层面
通常我们说的微服务链路追踪、流量追踪用来解决业务层的问题 说的微服务链路追踪、流量追踪用来解决业务层的问题,正常情况下会引入服务网格平台,好处是不会受开发语言限制(当然SpringCloud也是可以,只是局限在Java应用里),可实现链路追踪,发现业务API调用关系,对处理业务故障拍错很有帮助。
- 容器层面
容器层面的问题解决相当于传统情况下对包、配置、进程、OS等进行分析和调优,这点通过切入容器环境进行排障分析。值得一提的是在灵雀云的产品中,提供对容器debug的独特功能,可以通过临时添加debug容器到目标pod中的方式对目标容器进行各类测试,避免直接登录进入业务容器而导致风险或业务容器中没有需要的debug工具。
- 网络和数据包层面
可以通过trace、tcpdump、流量镜像等方式对数据包分析,这点通常需要CNI插件支持,一般的calico、flannel都无法做到,可以考虑采用开源的Kube-OVN插件作为容器CNI,可以有效帮助解决网络层排障的问题。
容器的智能运维有无成功实践案例?
我们以某大型车企的云原生容器应用为例,2018年,在高并发访问、高吞吐量以及车辆的车联网接入需求推动下,其智能网联应用做微服务的改造和应用容器化,“智能网联开发院”和“数字化部门”联合起来对整个平台架构进行了相应的设计,在平台建设中核心痛点就是需要引入一个微服务的治理平台,以及一个业务应用的管理平台,来支撑整个智能网联平台的开发需要。
项目依托于灵雀云ACP管理平台,配合微服务治理平台,实现了业务应用的运行以及业务应用治理的工作。项目一期实现部分服务器的纳管,形成计算资源池,为业务应用提供部署资源。同时,通过微服务治理功能,实现为业务应用的不同部门或者不同开发团队,适配相应的容器化集群。
当然,平台的落地并不能只是把工具提供给了客户,让客户更好地用起来,也是一个非常大的挑战,尤其对于微服务这样比较新的概念来说。灵雀云在项目当中也为客户提供了微服务治理咨询服务,对于微服务的拆分,微服务改造,以及如何更好地使用平台的各种功能都提供了有针对性的咨询服务。
经过几年的努力,该车企的营销数字化业务的不同业务系统都逐渐迁移到这个平台上来。这么大规模的平台和业务应用,运维人员可能只需要3~5个人。
对于他们来说,能得到的收益,首先就是统一业务系统的开发架构,第二是统一了业务系统的部署架构,第三是极大地减少了复杂的业务系统运维,少量的人员就可以支持大量的业务系统的运维工作,同时,通过平台的资源自动伸缩、微服务治理能力,实现了智能化的业务运行、运维和业务治理。
搭建云原生运维体系非一蹴而就,需要循序渐进,在安全可控的基础上逐步扩展。在技术层面,合适的云原生技术平台可以帮助企业释放运维的巨大压力,并保证安全稳定。我们相信,在数字化转型的大背景下,减少人力参与的智能运维势必会成为未来IT运维的发展方向。我们也期待着能够帮助更多企业实现云原生时代的智能运维进阶。
以上是关于|云原生时代下微服务架构进阶之路 - Snap-E的主要内容,如果未能解决你的问题,请参考以下文章